
面向机器学习的高性能SIMT处理器cache的设计与实现
2019-07-15 11:18许晓燕邢立冬
计算机应用与软件 2019年7期
许晓燕 李 涛 孙 哲 邢立冬
(西安邮电大学电子工程学院 陕西 西安 710121)
0 引 言
随着大数据时代的到来,机器学习已经应用到人类生活的各个方面。机器学习的本质是基于互联网的海量数据以及系统强大的并行运算能力,让机器自主模拟人类学习的过程,通过不断“学习”数据来做出智能决策行为[1]。为了解决机器学习中大数据、并行运算需求,本文基于SIMT架构进行设计。SIMT概念首先被GPU制造商NVIDIA在产品微架构中提出[2]。2006年11月,NVIDIA在其Tesla GPU架构中提出了一条指令同时驱动多个不相关线程的SIMT处理方式[3]。随后不久,ATI公司在2007年推出了采用类似处理架构的TeraScale引擎,及相关产品R600 GPU芯片[4]。SIMT架构具有多个执行流程[3],可以利用多线程隐藏存储延时,减少取指、取数开销,而且执行时不需要将数据凑成合适的矢量长度,便可以进行运算,更有利于适应机器学习处理大规模数据的要求。
本文基于自主研发的SIMT架构进行设计,为了解决SIMT处理器与主存速度不匹配问题[5],设计使用cache来改善它们之间的性能。目前cache设计有普林斯顿、哈佛两种结构。普林斯顿结构将指令cache与数据cache统一存放,哈佛结构将指令cache和数据cache分开存放[6]。哈佛结构相对普林斯顿结构有利于解决指令和数据冲突的问题,便于指令cache与数据cache的并行执行,方便对指令cache和数据cache的优化,因此cache设计中普遍使用哈佛结构。本设计采用哈佛结构,并根据指令cache、数据cache的局部性和连续性[7],为指令cache、数据cache设置不同的参数;根据设计需求为cache设计了可配置的替换算法,包括轮询、LFU(least frequently used)、LRU(Least Recently Used)和专用的伪LRU替换算法。本文重点介绍基于自主研发的SIMT架构的cache设计与实现。
1 SIMT处理器架构
该SIMT处理器最多可以包含4个区块,每个区块可以执行相同或不同的程序;每个区块包含8个warp,最多可以有8个warp都处于激活状态,但每次只有一个warp可以执行,同一个区块中的warp执行相同的程序;每个warp包含8个PE,可以通过线程真假控制PE的执行,每个PE执行相同的指令。运行程序可以通过配置区块个数、warp个数、初始pc、初始寄存器、替换算法有效地控制程序的执行。
该SIMT架构由8个PE(Processing element),1个VPU(Vector processing unit),1个MMU(Memory management unit)和1个AXI总线接口四部分组成。PE主要用于完成各类运算,VPU主要用于完成取指、译码、warp调度功能,MMU主要用于与处理器相关的指令、数据的存取,AXI总线接口用于实现AXI总线与MMU模块的交互。其中MMU包含分开的指令cache、数据cache、共享ram和mem_ctrl模块。icache模块主要满足流水线对指令访问的需求,dcache模块主要满足流水线对数据访问的需求,mem_ctrl模块主要负责SIMT处理器的访存请求,data_ram用于8个PE共享数据的访存。SIMT整体架构如图1所示。

图1 SIMT整体架构
2 基于SIMT处理器cache设计
2.1 指令cache结构设计
指令cache用于接收通过mem_ctrl模块透传过来的由取指单元传送的请求信号,用于观察所需的指令是否在对应的RAM中,若是,则将对应的指令输出给取指模块,否则向总线接口模块发出对应的请求信号,总线接口模块返回对应的指令时,填充对应的RAM,同时在填充完毕时,将对应的指令输出。指令cache分为cache的存储模块,控制模块、替换算法模块三部分。指令cache的整体结构如图2所示。

图2 指令cache整体结构
2.1.1存储模块
存储模块用于存储可供处理器运行的指令和标志。根据SIMT设计需求,指令cache大小设计为8 KW(32 KB),采用16路组相联,行大小为128字节。由于指令cache采用16路组相联,本设计将存储矩阵设计为16块指令存储体和16块指令TAG存储体,它们各自都具有相同的结构。其中,指令存储体每块大小为2 KB(分成4行,每行有512个字节),总共为32 KB。指令TAG存储体每块分成4行,每行有22位。根据给定指令cache的各个参数,可以确定地址的8~0为地址偏移位;地址的10~9为地址的索引位;地址的31~11为tag位。访问地址组成如图3所示。

图3 访问地址组成
inst_ram在实际存储时,将同一路的数据存储于同一个RAM中,并且将行内偏移地址与索引统一编址。用index位来选择cache的行索引,用offset位来选择行内的偏移。每行存储128条指令,共4行,每个inst_ram深度为512。
tag_ram中的tag位用来记录每行在主存中的位置,tag另一个作用就是与SIMT处理器发出的请求指令的地址进行比较,来确定当前cache行中的指令是不是处理器所需要的指令,使用tag存储体中的高21位表示。tag_ram中的第0位作为有效位用来记录当前cache行中的指令是否有效,每行都有一个有效信号,每个tag_ram深度为4。
2.1.2控制模块
icache控制模块用于控制整个icache的执行,实现cache的三级流水,同时接收取指模块的请求,最终输出对应的指令、对应指令的pc值、warp号码、sign标记(标记jump、call、retn指令)。
第一级流水线:根据mem_ctrl模块透传过来的块号,从对应的4个基地址中选择对应的值,然后将该值与对应pc值相加,即为所需指令的地址。同时根据控制信号(rd_en)和地址的2~10位,从16路inst_ram中分别取出对应地址的指令;根据控制信号(rd_en)和地址的9~10位,从16路tag_ram中分别取出对应地址的tag。判断新进来的指令与前一个指令是否在同一行(line),并将对应的地址寄存,用于下一级指令命中的判断。同时将对应的pc值、warp号码、sign标记寄存输出。
第二级流水线:当控制信号(en_tag)为1,首先判断第一级流水线传过来的line是否为1,若为1,则第二级流水线输出的miss(未命中)信号、hit(命中)信号以及命中的路数与寄存的结果相同;否则,根据第一级传过来的addr(地址)和16个tag,将addr中的tag位与16路tag中的tag位分别进行比较,同时判断tag中的valid位是否为1。若其中有一组比较结果相同并且对应的valid位为1,则hit,输出命中信号,命中的路数(set)。若上述比较结果都为0,则miss,向mem_ctrl模块输出miss信号,暂停指令请求,同时保存对应miss地址。当通过总线接口模块取回对应的128条指令时,将miss信号改为hit,继续流水线的执行;同时寄存第一级流水线输出的指令、pc值、warp号码、sign标记。
第三级流水线:根据第二级流水线输出的hit、set和miss信号。若miss则向总线接口模块发出请求信号和地址。miss时,当通过总线接口模块取回对应的指令时,将取回的第二级流水线寄存地址的对应位置的指令寄存,寄存信号为miss_inst;若line为1,同时将第一级流水线寄存地址的对应位置的指令寄存,寄存信号为line_miss_inst。同时将取回的指令填充到替换算法指定的对应路的inst_ram中,更新对应的tag_ram。若填充满,下一时刻将miss_inst输出;若line为1,将line_miss_inst输出;其他情况,hit为1时直接将命中路对应的指令输出。输出指令时,将对应指令的valid、pc值、warp号码、sign标记同时输出。图4为icache控制模块结构图。
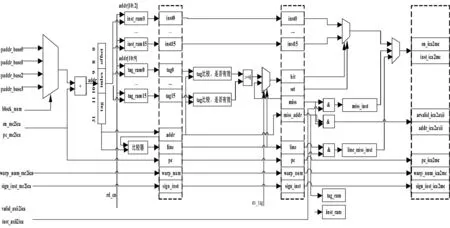
图4 icache控制模块结构图
2.1.3替换算法模块
轮询替换算法:算法为每一行设置一个4位的替换计数器,每次替换时选取替换计数器指定的cache行,替换后替换计数值加1,当计数器计到最大值时从0开始重新计数,命中时不改变计数器的值。
最不经常使用算法(LFU算法):算法需要为每行提供64位寄存器用来存放16路计数器的值,其中3~0位对应第0路计数器的值,7~4对应第1路计数器的值,依此类推,初始寄存器64位的值设置为64’h0123456789abcdef。当miss时找到计数器中值为0的值,即为所需替换的路数,同时将其他路计数器值减1,替换路计数器值变为15。命中时,将命中路计数器值变为15,其他路计数器比命中路计数器值小的不变,大的则将计数器的值减1。
最近最少使用算法(LRU算法):算法需要为每行提供64位寄存器用来存放16路计数器的值,其中3~0位对应第0路计数器的值,7~4对应第1路计数器的值,依此类推,初始寄存器64位的值设置为64’h0123456789abcdef。当miss时找到计数器中值为15的值,即为所需替换的路数,同时将其他路计数器值加1,替换路计数器值变为0。命中时,将命中路计数器值变为0,其他路计数器比命中路计数器值大的不变,小的则将计数器的值加1。
专用伪LRU替换算法:算法将局部性原理与LRU替换算法相结合,使用18位来存储标志位(lru_val)的值。因为采用16路组相联,设计时将对应的16路分为4组,0~3路为第一组,4~7路为第二组,8~b路为第三组,c~f路为第四组。将lru_val中的18位分为3部分,17~12位用于表示选择哪一组,11~8位表示选择对应组内的后两路还是前两路,7~0位用于选择16路中相邻两路中的哪一路。对应位为0表示前者相对后者最近最少使用。
(1) 12位表示第一组相对第二组是否最近最少使用,13位代表第一组相对第三组是否最近最少使用,14位代表第一组相对第四组是否最近最少使用,15位代表第二组相对第三组是否最近最少使用,16位代表第二组相对第四组是否最近最少使用,17位代表第三组相对第四组是否最近最少使用。
(2) 8位代表第一组中的后两路相对前两路是否最近最少使用,9位代表第二组中的后两路相对前两路是否最近最少使用,10位代表第三组中的后两路相对前两路是否最近最少使用,11位代表第四组中的后两路相对前两路是否最近最少使用。
(3) 0位代表0路相对1路是否最近最少使用,1位代表2路相对3路是否最近最少使用,2位代表4路相对5路是否最近最少使用,3位代表6路相对7路是否最近最少使用,4位代表8路相对9路是否最近最少使用,5位代表10路相对11路是否最近最少使用,6位代表12路相对13路是否最近最少使用,7位代表14路相对15路是否最近最少使用。
若命中,并且line为1,则不需要改变lru_val的值,若不在同一行,则根据命中的路数以及寄存的lru_val的值,更新lru_val。若miss,则根据当前lru_val的值判断需要替换的路数,同时更新lru_val的值。
2.2 数据cache结构设计
数据cache用于接收通过mem_ctrl模块透传由ldst模块传过来的请求信号,用于观察所需的数据是否在对应的RAM中,若是,则将对应的数据输出给ldst模块,否则,向总线接口模块发出对应的请求信号,待总线接口模块返回对应的数据时,填充对应的RAM。填充完毕时,将对应的数据输出。数据cache大小设计为32 KB,采用4路组相联,行大小为8字。因此地址的4~0位为偏移位,12~5位为索引位,31~13为tag位。
数据cache与指令cache采用相同的结构,使用3级流水线,实现数据cache功能,满足处理器取数请求。数据cache替换算法采用与指令cache类似的可配置的替换算法,轮询替换算法使用2位计数器;LFU、LRU使用8位寄存器的值;专用伪LRU替换算法在设计时只需要3位的标志位(lru_val)即可。第0位表示第0路相对第1路是否最近最少使用,第1位表示第2路相对第3路是否最近最少使用,第2位代表后两路相对前两路是否最近最少使用。若命中并且line为1不改变标志的值;若line不为1,改变标志位的值;若miss改变标志位的值,同时根据当前标志位的值,找到需要替换的路数。
3 实验结果及分析
3.1 功能验证
对于整体cache的验证,主要从下面几方面入手:
(1) 分析取指、ldst模块可能出现的各种情况,列举各种情况的不同组合,按照列举出来的不同情况,使用VCS工具对指令cache。数据cache分别进行功能验证,观察icache、dcache功能是否正确;
(2) 将指令cache、数据cache添加进MMU中,使用VCS工具进行仿真,观察整体MMU功能是否正确;
(3) 将MMU模块嵌进整体架构中,使用vivado工具,通过测试不同的程序,检查cache功能是否满足处理器的要求。
图5为使用8个warp、8个PE执行矩阵乘例子抓取的部分指令cache的仿真波形图。初始tag_ram中的值为0,则icache发出miss信号,等到接收到总线接口模块传输的128条指令时,将对应的指令输出。若对应请求的指令在同一行时,根据流水线思想,一拍即可以输出一个对应的指令、pc值、warp号码、sign标记。根据抓取的波形,显示指令cache满足设计需求。
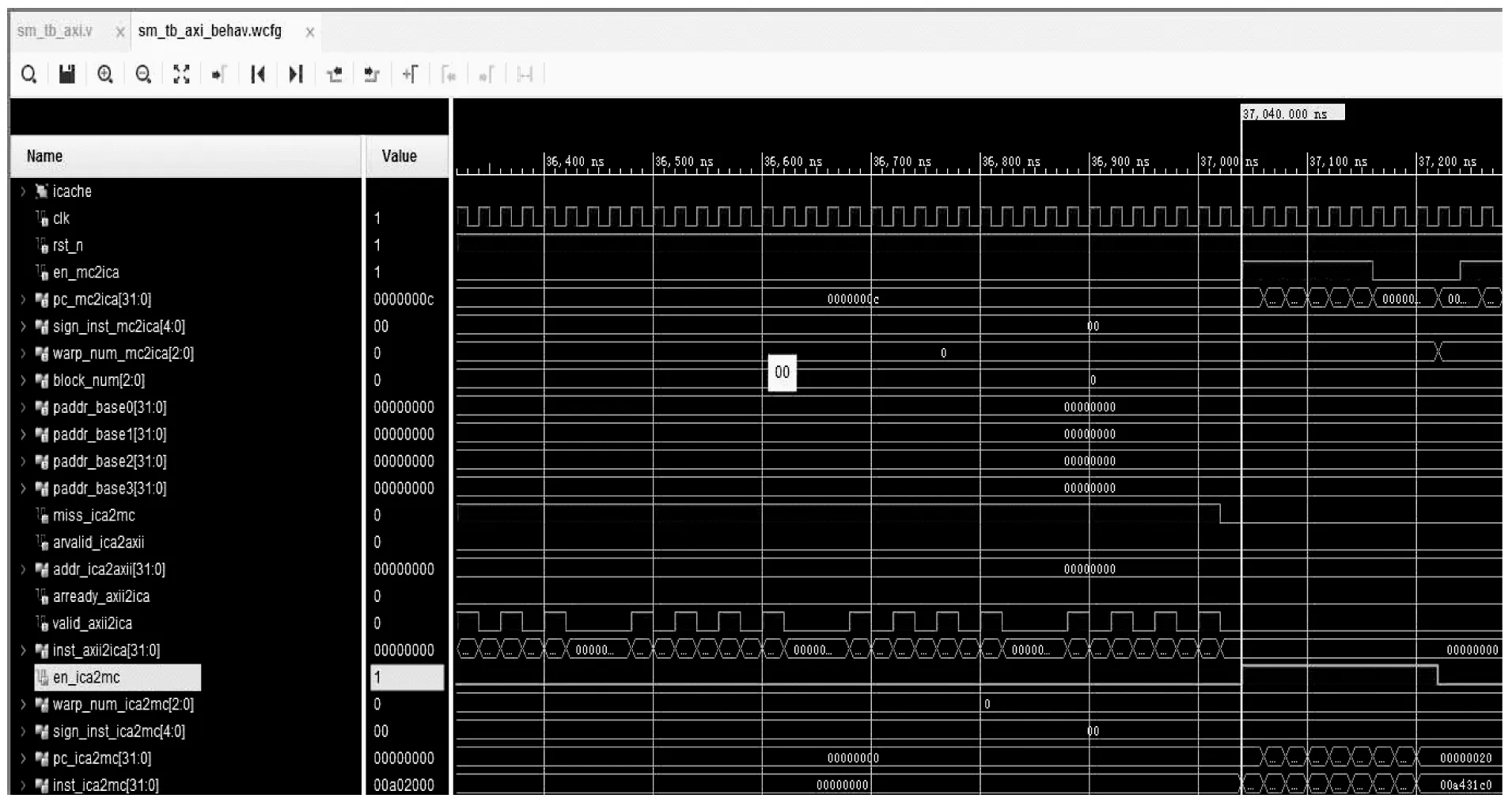
图5 指令cache仿真波形图
图6为使用8个warp、8个PE执行矩阵乘例子抓取的部分数据cache的仿真波形图。初始tag_ram中的值为0,则dcache发出miss信号,等到接收到总线接口模块传输的8个数据时,将对应的数据输出。若对应请求的数据在同一行时,根据流水线思想,一拍即可以输出一个对应的数据。根据抓取的波形,显示数据cache满足设计需求。
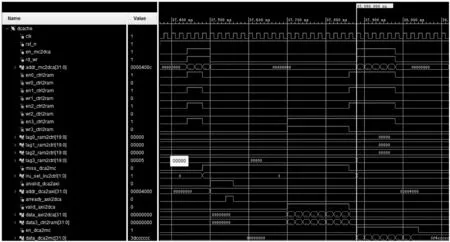
图6 数据cache仿真波形图
3.2 性能分析
该cache结构采用Xilinx公司virtex ultrascale系列的xcvu440-flga2892-2-e FPGA芯片对设计进行综合,该cache的最大工作速度可达307 MHz,满足处理器设计要求。指令cache最大时延为2.923 ns,数据cache最大时延为3.258 ns。整体cache具体器件占用情况如表1所示。

表1 cache具体器件占用情况
3.3 FPGA验证
该SIMT处理器使用Xilinx公司virtex ultrascale系列的Dual VU Prodigy Logic Module开发板进行测试。搭建FPGA验证平台时,将pcie2axi桥作为AXI总线的一个主机,连接到AXI总线的m1端口,SIMT处理器在进行信息配置时作为AXI总线的一个从机,连接到AXI总线的s2端口,SIMT处理器执行时作为AXI总线的一个主机,连接到AXI总线的m2端口,异步转换核(DW_axi_x2x)作为AXI总线的一个从机,连接到AXI总线的s1端口。
进行FPGA验证时,首先由PC机输出对应的指令、数据、配置信息,通过pcie2axi桥将对应的指令、数据、配置信息传输到AXI2to2总线上,SIMT处理器通过AXI2to2总线的s2端口,将对应的配置信息传输到SIMT处理器,异步转换核通过AXI2to2总线的s1端口将对应的指令、数据传输到ddr4,并且匹配ddr4与AXI总线的速率。将对应的指令、数据、配置信息传输完成后,启动SIMT处理器的执行。当SIMT处理器icache、dcache发生缺失时,通过AXI总线的m2端口,在读地址通道上输出对应的请求信号、地址、控制信息,读数据通道接收到对应的数据时,将对应的数据传输到SIMT处理器,继续缺失数据、指令的执行。对应的程序执行完成后,SIMT处理器将对应的结果通过m2的写地址通道、写数据通道传输到ddr4。最终通过控制PC机读取相应地址的值,在PC机上观察程序执行的最终结果,可以判断SIMT处理器执行是否正确。图7为搭建的FPGA验证平台。

图7 FPGA验证平台
通过在FPGA上测试排序、找最大值、矩阵乘、卷积、循环、解线性方程、画线、顶点染色、FFT等例子,并观察PC机上打印的结果,表明该cache设计正确,满足SIMT处理器设计要求。其中以矩阵乘为例,该程序使用4个warp、4个PE进行矩阵乘运算。图8为矩阵点积图。

图8 矩阵点积图
将计算的结果转换为16进制数据,分别为1e、46、32、3c、46、ae、72、8c、32、72、54、64、3c、8c、64、78,通过与PC机上打印结果相比较,表明该SIMT处理器设计正确,满足程序设计要求。图9为PC机上打印结果。

图9 PC机打印结果
4 结 语
为了进一步提高处理器性能,从而满足机器学习处理大数据、大吞吐量等要求,本文在基于自主研发的SIMT处理器的基础上设计了指令cache、数据cache,满足SIMT处理器的指令、数据读取要求。设计可配置的替换算法,使用VCS工具进行仿真,验证功能的正确性;并通过vivado综合,结果表明该cache整体性能达到307 MHz,指令cache最大时延为2.923 ns,数据cache最大时延为3.258 ns,满足SIMT处理器的性能要求,缓解了主存与处理器的差距。现已将该cache设计应用到SIMT处理器中,在FPGA上通过测试不同的程序对SIMT处理器进行验证,验证结果显示该cache设计正确,同时满足SIMT处理器要求。
猜你喜欢
煤气与热力(2022年2期)2022-03-09
科学家(2021年24期)2021-04-25
学校教育研究(2020年11期)2020-06-08
航空科学技术(2019年2期)2019-09-10
科技与创新(2019年2期)2019-02-14
科技风(2017年2期)2017-07-10
科技创新与应用(2016年7期)2016-10-21
小猕猴学习画刊(2016年6期)2016-05-14
微型计算机(2009年12期)2009-12-21
中华少年(2009年9期)2009-09-14
