
基于XGBoost的客户所在店铺WiFi定位技术研究
2019-07-25 09:21
计算机测量与控制 2019年7期
(1.上海交通大学 模具CAD国家工程研究中心,上海 200030;2.东莞市横沥模具科技产业发展有限公司,广东 东莞 523460)
0 引言
随着移动互联网计算平台的迅速普及,根据不同的场景实时精确地推送相关信息,已经成为一项增强用户体验友好度并提升商业信息服务水平的有效策略。此应用对面向移动大数据的推荐算法提出了精度更高且具可操作性的要求,在恰当的时间和地点向用户提供最具针对性的服务,是诸多通讯与互联网企业智能化拓展的新目标。
随着城市功能的发展,室内场景日趋复杂,商业场所对于定位及监控相关需求也逐渐深入。如大型超市可以基于客户定位信息提供引流导购营销服务。医疗机构可以快速调用相关医疗资源,同时对特殊病患进行定位监护,以提高患者就医及医务人员诊疗效率。在通讯技术覆盖日益全面的情况下,室内定位诸多行业均展现出了广阔的应用前景。目前,室内定位技术如WiFi、蓝牙、RFID、红外等得到了广泛的研究与开发,为众多室内定位应用提供了诸多行之有效的位置服务方案,成为智能城市的有效组成与标准配置。
1 基于WiFi信号的移动定位
通过手机等移动设备携带的信息精确定位用户位置信息是室内智能应用中关键的一环,WiFi信号获取、大数据分析以及数据挖掘是当前完成此项功能的有效途径之一。
在真实商业场景测试实验中,手机等移动端在室内复杂环境中经常存在定位信号模糊、环境信息不全、店铺数据缺失、不同店铺空间距离太近等诸多挑战[1],因此很难精准地确定移动中的用户所在商铺。随着WiFi在室内环境中的广泛部署,以及智能移动设备的普及,使得WiFi具有作为主要定位介质的技术成为可能[2]。
室内环境的复杂性导致信号被遮挡或者产生多径效应,引起的接受误差是影响定位效果的主要原因。另外信号接收端和发射端的硬件差异和稳定性也会造成定位误差。所以在进行室内定位的时候,必须考虑到上述因素的影响[3]。
基于WiFi的室内定位技术主要包括几何特征法、邻近信息法和场景分析法。几何特征法将信号强度转换为距离,再使用几何原理进行定位。当信号稳定,传播时不受到干扰时可以达到较好的定位效果,但室内应用环境的复杂和信号的波动影响了它的定位精度。邻近信息法利用信号作用范围来确定参考点,但只能判断定位点是否在参考点的附件,定位精度不高。场景分析法利用待测点的可测量特征来进行定位,有效利用了各类位置信息,可以在复杂室内环境中取得理想的定位精度,拥有较好的实用价值,因此被广泛的研究和应用[4]。场景分析法首先要收集大量的位置信息构建“指纹库”,在定位时系统会将测量所处位置的“指纹”和“指纹库”的数据进行信息匹配,即可获取待测点的位置[5]。现在较为主流的一类匹配方式是通过欧氏距离或马氏距离,在指纹库中选出距离最小的位置信息,被称为确定性方法。这种方法受信号稳定性影响大,定位精度低。另一种是通过在此类方法基础上加入一些先进的机器学习算法来改进这些问题,比如SVM[6]或模糊逻辑[7]等。
总体而言,由于实现难度适中、成本相对较低、定位精度较高及稳定性好等优点,基于位置指纹的WiFi室内定位技术已经成为目前研究的热点方法之一。本文针对位置指纹进行了深入的分析,提出了一种基于XGBoost算法的位置指纹法,通过XGBoost学习器对采集到的真实店铺和用户交易数据进行离线训练,建立位置指纹库,然后根据用户信息进行实时定位。实验证明,XGBoost算法具有较好的分类能力,相对传统的最近邻算法,本文提出的方法取得了较高的WiFi信号定位精度。
2 位置指纹法基本原理
2.1 定位基本阶段
位置指纹指的是某个位置与可测量物理刺激相关物理量之间的关系,把实际环境中的位置和某种“指纹”联系起来,一个位置对应一个独特的指纹。基于位置指纹法的定位可以分为离线训练和在线定位两个阶段[8]。
1)离线训练阶段建立位置指纹库,首先确定区域中一系列的测试参考点,然后在各个参考点采集足够数量的AP信号样本,对这些样本进行筛选加工(通常去除异常值后使用取均值)作为此参考点的AP信号特征参数,并且在位置指纹数据库中进行记录,即为位置指纹地图。
2)在线定位阶段在测得某处的信号特征参数后,依据实时测得的信号数据与位置指纹数据库中记录进行匹配,获得位置信息,进而实现定位。
2.2 最近邻算法
随着对于位置指纹法的定位技术研究的深入,匹配算法中最早在RADAR定位系统中提出最近邻算法(NN, Nearest Neighbor)[9]是一种最基本的确定性匹配算法。最近邻算法根据向量间的极大似然理论,它通过计算实测信号强度和含有信号强度以及位置信息的数据库中样本的相似度,来评估该接收信号强度可能的位置[10]。这种算法会在指纹数据库中搜索与实测信号信息最匹配的数据点,取该样本的位置作为定位估计值。
对于空间环境十分复杂的室内情况,并非所有的位置指纹都可靠,更复杂的指纹库可能还包括了RSSI (Received Signal Strength Index)的标准差信息,或者赋予每个AP不同的权值,这样需要使用加权的欧氏距离,如对整个指纹加一个权值,或者对指纹的系列特征分别加权值[11]。Brunato M和Battiti R提出了一个权值设计方式[12],可使加权K近邻算法的定位精度比K近邻算法有一定的性能提升。但这种匹配算法计算过程复杂,工作量大,不适用于实时精确定位。目前部分商用WiFi接收器可以提供信道相关信息,利用该信息建立指纹库进行定位,可以有效地提高定位精度。本文在前述特征研究的基础上,针对位置指纹法中学习及分类方案进行了深入分析比较,采用基于XGBoost算法的WiFi指纹定位法。
3 基于XGBoost的位置指纹法
3.1 XGBoost算法
Boosting分类器属于集成学习算法,它采用了加法模型,其基本思想是把成百上千个分类准确率较低的弱分类器组合形成一个准确率较高的强分类器。以决策树为基本分类器的Boosting方法称为提升树(Boosting Tree),该模型不断迭代,每次迭代生成一棵新的提升树,在每步生成合理的提升树是Boosting分类器的关键[13]。
提升树可以定义为一种使用前向分布算法的决策树加法模型。首先定义初始提升树f0(x)=0,而第m步的模型定义为:
fm(x)=fm-1(x)+T(x;Θm)
(1)
其中:fm-1(x)为当前模型,通过极小化风险来确定下一棵决策树的参数Θm:
(2)
若损失函数为平方或指数函数时,每步优化都较为简单,但对一般损失函数进行优化则比较困难。针对这一问题,Freidman提出了梯度提升(Gradient Boosting)算法[14]。
它用了当前模型损失函数负梯度的值作为提升树算法的残差近似值,使每一棵树的迭代都会降低整体的损失,T(x;Θm) 的拟合目标值如下:
(3)
通过损失函数负梯度的拟合来优化损失函数,朝着最小化给定目标函数的方向逼近。在参数合理设置下,需要生成一定数量的树才能达到预期准确率,另外在数据集庞大且较复杂的时候,Gradient Boosting算法的计算量巨大。
XGBoost[15]是Gradient Boosting算法的快速实现,能充分利用CPU的多线程进行并行计算,并通过使用损失函数的二阶泰勒展开对算法加以改进以提高精度。XGBoost的基础学习器包括常用的树模型或线性模型,可以进行分类和回归的预测,采用了深度学习中的dropout技术[16]在训练的过程中随机采用数据和特征防止过拟合,具有可扩展性、不易过拟合等特点,并能分布式处理高维稀疏特征。另外XGBoost算法在训练之前,预先对数据进行排序,然后保存为block结构,后面的迭代中重复地使用这个结构,从而极大减小了计算量。XGBoost有多种实现,本文采用XGBoost算法的Python版本进行分类建模与计算。
3.2 基于XGBoost的定位算法
改进的基于XGBoost算法的位置指纹法同样分为2个阶段,离线训练阶段和在线定位阶段。在训练阶段,首先将数据对象进行预处理使数据标准化,然后利用XGBoost算法对标准化数据进行分类,根据分类的结果调整XGBoost算法的输入参数,获得最优的多分类模型。在定位阶段,对每一个新测数据进行标准化,然后输入训练好的多分类模型,运用XGBoost算法进行分类。本方法详细的算法流程图包括三个阶段:数据采集,训练和定位结果显示,如图1所示。
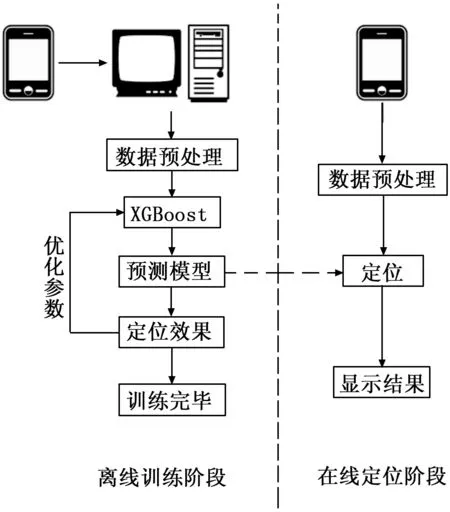
图1 基于XGBoost的定位算法
使用XGBoost算法作为位置指纹法的匹配算法,由于采用了Boosting的方法相比于KNN较大的提升了准确度,同时使用训练好的模型能进行即时精确定位。
通过XGBoost算法对位置和WiFi信号数据之间的映射关系进行离线学习,构建高精度指纹库。同时为了获取更好的定位效果,将位置离散化,对商场不同位置使用商铺ID作为唯一标识,指纹库如表1所示。
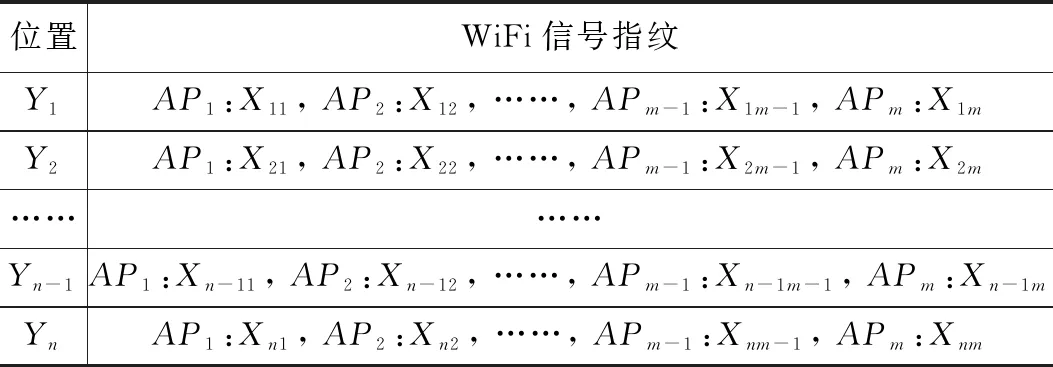
表1 WiFi信号指纹库
表1中Yi为第i个样本所在位置离散后的唯一标识ID,APj为整个定位区域内第j个AP,Xij为第i个样本所在位置接受到APj信号的强度值,无信号的AP用默认值填充。
XGBoost算法通过构建多棵决策树来构建指纹库,其思想是通过位置离散化将定位问题转化为多分类问题,每个位置对应一种类别。然后对样本进行训练,将每个决策树的结果融合得到最终的分类结果。利用XGBoost算法构建指纹库的步骤如下:
1)选取某一位置作为采样点,采集WiFi信号数据作为一个样本的全部特征。对特征进行列采样,利用贪婪算法根据“损失函数最小”原则来寻找最优分裂点,将使损失函数值最小的WiFi特征及该特征下的信号强度值作为本次分裂的分裂点。
2)为了防止构建的指纹库模型过于复杂,出现过拟合现象,即该模型对训练数据可以获得较高的定位准确率,而在线定位时准确率率低,需要对结点的每次分裂进行限制。只有当增益大于阈值的时候才进行分裂,同时当一棵树到达最大深度停止继续分裂。
3)在生成决策树时,使用Gradient Boosting算法促使预测结果不断逼近真实结果。通过多棵决策树的学习,完成离线训练。在定位阶段,首先对每一个新测WiFi数据进行标准化,然后输入训练好的多分类模型,应用XGBoost算法进行定位。
4 基于XGBoost的定位实验及分析
4.1 测试数据构成
本文所有数据均来自阿里天池比赛的商场中精确定位用户所在店铺赛题的真实采集数据集。当用户使用移动支付方式付费时,后台采集了此时手机的状态(用户ID、时间、GPS定位、WiFi信号强度及连接)和被扫码的商店的信息(商店ID、商场ID、商店消费水平、商店位置)。采集到的具体信息如下图表2和表3所示。

表2 用户在店铺内交易表
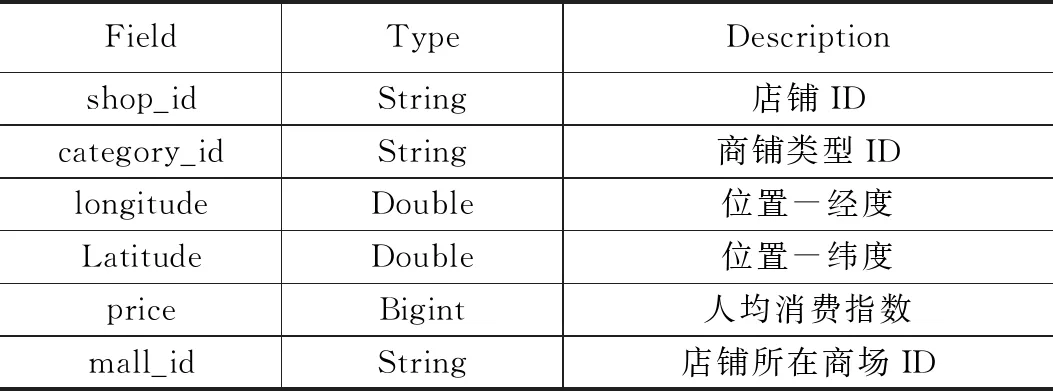
表3 店铺商场信息表
商场中精确定位用户所在店铺数据库提供的2017年8月份各类交易信息,一共包含1138015条数据。为了保证数据集在时间上可能出现的周期性,本文将8月1日至24日的数据作为训练集,剩余7天作为测试集验证算法效果,表4展示数据集的基本信息。

表4 数据量
选取用户在店铺内交易表和店铺商场信息表中商场ID为m_7168的部分数据的经纬度信息,使用QGIS桌面地理信息系统对数据进行可视化,可视化效果如图2。黑色三角形是不同店铺的真实经纬度定位,而彩色圆点为商场交易发生时收集到的手机定位的经纬度定位,相同颜色的圆点则为同一个店铺。
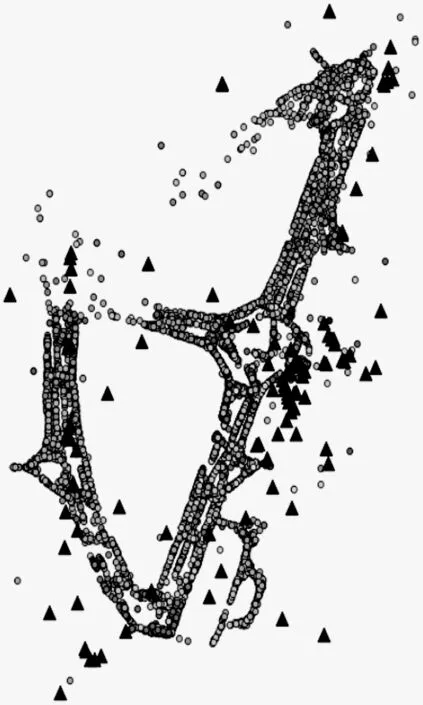
图2 商场m_7168的经纬度定位可视化
图2采用的是GPS经纬识别。虽然GPS在室外定位中取得了极大的成功,但由于室内环境复杂,存在各种遮挡信号的障碍物,导致GPS接收机难以接收到足够强度的卫星信号,引起较大的定位偏差。图2也反映了在商场内手机GPS定位结果与真实经纬度存在较大偏差。另外,GPS信号存在异常值,且不同商店的GPS重叠严重,呈现出聚集状态,其中有些聚集的数据甚至可以呈现出商场清晰轮廓。这说明在室内定位中,GPS定位只能作为辅助提供一些定位信息。
4.2 数据处理
首先对原始数据进行预处理以满足XGBoost算法的输入要求。此外为了避免临近商场的影响提高定位精度,减少预测模型的复杂度,我们分别对每个商场各自训练一个预测模型。数据处理主要分为几个步骤。
1)提取训练集中每个商场中所有WiFi的ID作为特征,为了避免个人移动热点的影响,剔除出现次数少于10的WiFi的ID。
2)提取训练集中每条数据的WiFi信息,将出现的WiFi强度作为对应的WiFi的特征值,一般WiFi的信号强度范围是[-90,-30]dBm,我们对特征向量中的缺失值使用-999来填充,为此确保搜到的WiFi的重要性。
3)以训练集中每条数据的shop_id作为类标签,优化目标是降低多分类错误率。
4.3 模型训练
将预处理后的数据输入到XGBoost模型中进行训练,为了既不影响模型的收敛速度,又有较好的定位准确率,采用的模型参数如表5所示。训练样本由WiFi强度值和shop_id标签组成,通过WiFi强度值去训练一棵决策树,将叶子节点的结果分类到样本的标签上。虽然参数对决策树的树深做了限制,存在分类错误的情况,但由于XGBoost模型采用了Boosting的集成学习方法,模型会将分类的误差作为下一轮决策树的拟合值。eta参数相当于学习速率,在进行完一次迭代后,会将叶子节点的权重乘上该系数,其目的主要是为了削弱每棵树的影响,让后面训练的决策树有更大的学习空间。通过多轮的迭代,XGBoost训练的目标函数的分类结果将始终逼近真实的标签,从而提高WiFi的定位精度。
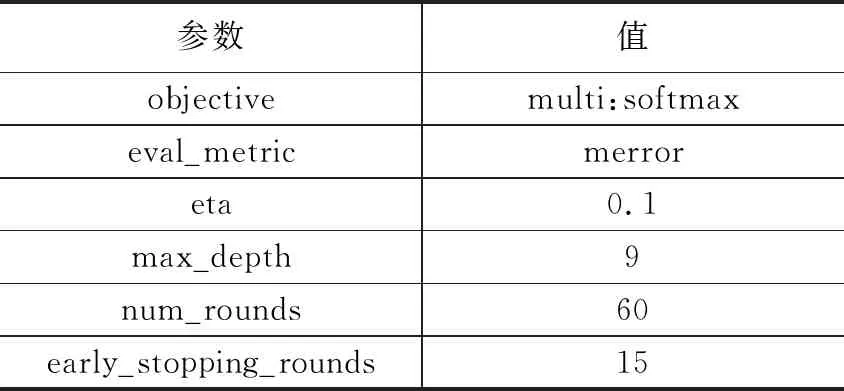
表5 XGBoost模型参数
4.4 实验结果
对比其他WiFi定位算法,定位的准确率是重要的性能指标,也就是预测的shop_id是否和标准答案的shop_id相等,准确率等于预测正确的样本总数除以总样本数。在本文中,总样本为测试集8月25日至8月31日的数据,其中的shop_id列为标准答案,其他列均可用于预测shop_id。
对基于KNN和基于XGBoost模型的位置指纹法的准确率进行比较可知,在相同的样本个数(288510)时,根据WiFi强度信息,基于XGBoost算法的定位准确率(87.82%)明显高于传统的基于KNN的算法(79.43%)。
XGBoost算法的优越性还体现在它的可扩展性,它能将其他含有较低信息量的特征利用起来,进一步组合提高定位的准确率,如表6所示。
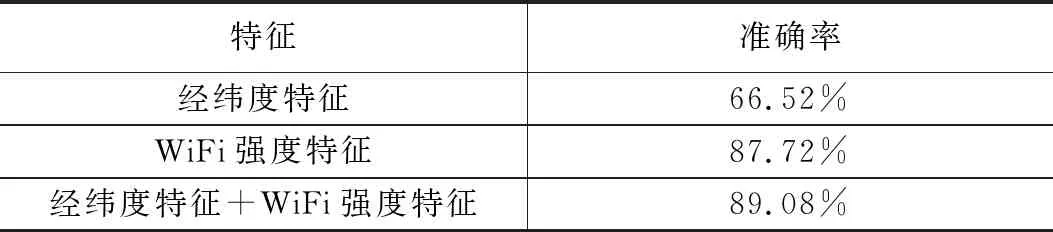
表6 使用经纬度和WiFi特征的预测结果
由表6可知,虽然仅使用经纬度特征定位存在较大偏差,准确率只有66.52%,但是可以在WiFi强度特征的基础上加入经纬度特征,进一步提高定位的准确性。
由以上结果可以看出,改进后的基于XGBoost算法的位置指纹法相比于传统的基于最近邻算法的位置指纹法有着巨大的提升。同时XGBoost算法还可通过特征工程进一步挖掘数据价值,提高定位的准确率。在离线训练阶段,XGBoost可以自动利用CPU的多线程进行并行,有着良好的训练速度。在线定位阶段,算法的时间复杂度为O(1),平均每条数据所需的预测时间为0.23 ms(Intel i5-6400 CPU),基本可以忽略,因此本文基于XGBoost算法的位置指纹法可以实现实时室内定位功能。
5 结束语
针对室内复杂环境和WiFi信号强度的变化特点,本文提出了一种基于XGBoost算法的位置指纹法。在离线学习阶段,我们训练集数据训练预测模型。在线定位阶段,我们将测试集的WiFi信息,输入预测模型,进行实时定位。实验结果表明,该方法相对传统的基于最近邻算法的位置指纹法,具有可靠性强、精度高等优点,可以应用于复杂室内环境的实时定位。
由于室内空间复杂的信道环境和空间拓扑关系,给室内定位带来很大的挑战,单一的定位源终究存在一定的局限。目前室内定位技术的发展趋势包含如下三个方面:探索新的定位源,形成高精度高可用定位技术;异源异构定位源的高效融合;基于GIS的语义约束定位和语义认知协同定位。这将是本文后续工作的重点研究方向。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小哥白尼(趣味科学)(2021年11期)2021-02-28
健康体检与管理(2021年10期)2021-01-03
小天使·一年级语数英综合(2020年10期)2020-12-16
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
儿童时代·快乐苗苗(2016年2期)2016-10-22
青少年科技博览(中学版)(2015年7期)2015-08-12
