
基于拓扑感知节点排序的虚拟网络嵌入
2019-07-25 09:39
计算机测量与控制 2019年7期
(陕西中医药大学 信息化建设管理处,陕西 咸阳 712046)
0 引言
共享虚拟化资源可以实现新的计算和网络模式,例如,基于云计算平台[1]和可切片的网络测试平台[2]。云平台或网络基础设施的用户请求共享资源,包括CPU容量、存储空间、网络带宽等,而基础设施提供商则尽最大努力为请求提供服务,也就是所谓的虚拟网络(VN)。在这种虚拟化环境中,Vn的资源分配对用户的计算需求和资源提供者的收益都至关重要。
在多租户网络虚拟化环境中,基础设施提供商(InP)(例如,云提供商)和服务提供商(SP)(如云用户/租户)扮演两个不同的角色,即InP管理物理基础设施,而SP创建VN并提供端到端服务[3]。将SP的VN请求映射到InP的底层网络上,也称为VN嵌入。因此,设计启发式方法已经成为VN嵌入的主要研究方向[4]。早期的算法通过一个节点的CPU容量和带宽来测量节点的资源,而不考虑VN和底层网络的拓扑结构。然而,节点的拓扑属性对映射结果的成功和效率具有显着影响。
本文设计了两种新的VN嵌入算法:RW-MaxMatch和RW-BFS。RW-MaxMatch算法根据节点的等级将虚拟节点映射到底层节点,然后通过找到具有不可分离路径的最短路径并利用可拆分路径解决多商品流问题,将虚拟链路嵌入到映射节点之间。RW-BFS算法是基于广度优先搜索的回溯VN嵌入算法,其利用节点等级在同一阶段嵌入虚拟节点和链路。
1 网络模型及问题描述
1.1 底层网络
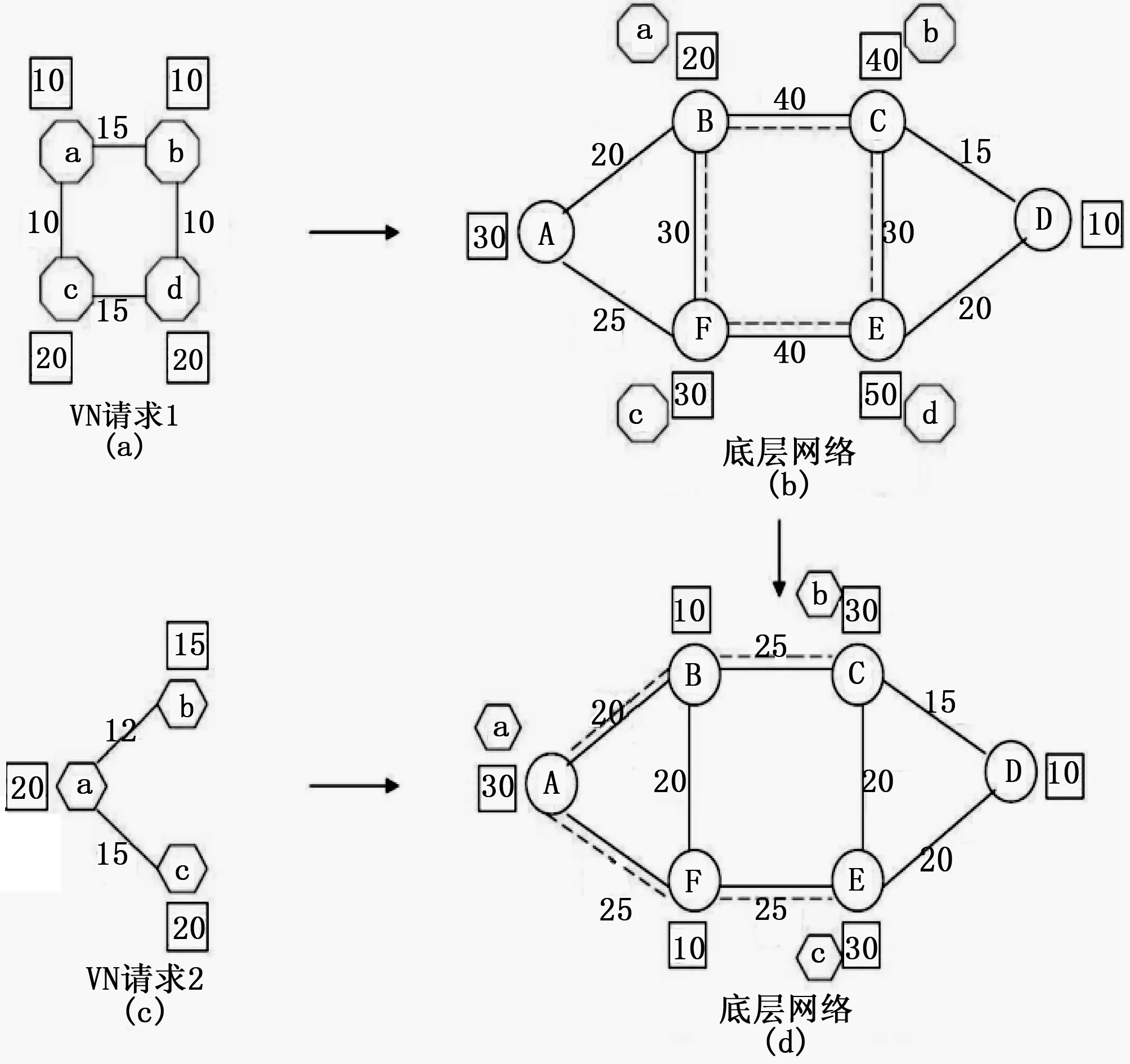
图1 VN嵌入的示例
图1给出了VN嵌入的示例,图1(b)给出了一个底层网络,其中矩形中的数字是节点处可用的CPU资源,而链路上的数字表示可用的带宽。
1.2 虚拟网络请求
1.3 VN嵌入问题描述
图1(a)和图1(b)给出了VNR 1的VN嵌入方案。图1(c)和图1(d)给出了VNR2的另一个VN嵌入解决方案,其中还显示了剩余资源。注意,不同VNR的虚拟节点可以映射到同一个底层节点上。
1.4 嵌入目标
VN嵌入的主要目标是在VN请求到达和离开时,将VN映射到底层网络以有效利用底层网络资源。与文献[5]类似,在t时接受VNR的收益可通过以下公式计算:
(1)
其中:CPU(dv)和BW(Lv)分别表示CPU的虚拟节点dv和链路Lv的带宽要求。
在t时接受VNR的成本定义为分配给该VN的底层总资源的总和:
(2)
从InPs的角度来看,一种高效且有效的在线VN嵌入算法可以最大限度地提高InPs的收益,并从长远来看提高底层网络的利用率,长期平均收益为:
(3)
底层网络的VNR接受率可表示为:
(4)
其中:VNRs是底层网络成功接受VN请求的数量。
本文还考虑了长期收益成本比,进而量化底层网络的资源利用效率:
(5)
如果VN嵌入解决方案的长期平均收益大致相同,则VN接受率和R/C比率越高越好。
2 拓扑感知节点排序
VN嵌入涉及到节点映射和链路映射。节点映射需要借助具有足够CPU资源的底层节点来实现,而链路映射需要在任意两个选定底层节点上以及路径上都有足够的链路资源来实现。文献[6]在将节点映射和链路映射分为两个不同执行阶段:节点映射阶段完成节点选择,链路映射阶段完成链路分配和路径选择。本文在节点映射阶段采用了不同的拓扑组合方法来提高链路映射的成功率和效率。通过对比具有相同CPU资源的节点n1和节点n2,如图2所示。

图2 拓扑感知节点示例
图2中,较大的节点表示具有更多CPU资源的节点,较宽的线表示具有更多资源的节点映射。节点n1比节点n2的具有更大的概率实现链路映射,这是由于节点n1的邻居节点拥有更多的资源。
本文定义了节点等级的概念来度量节点的资源可用性。即给定的节点u的等级由其CPU功率和其输出链路的总带宽决定。它还受到从u到达的节点等级的影响。使用其CPU和输出链路的总带宽进行第一个建模。通过将可到达的节点分为两个组来进行第2个建模,即从u到输出链路的节点和通过多跳从u到输出链路的节点。在本文中,定义了一个跳跃概率来模拟一个节点通过多跳从u到达的可能性,并定义一个正向概率来模拟来自u的正向链路中相邻节点的影响。令:
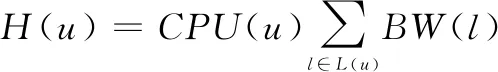
(6)
其中: 在底层网络上,L(u)是u的所有输出链路的集合,CPU(u)是u的剩余CPU资源,BW(l)是链路l的空闲带宽资源,在虚拟节点上,CPU(u)和BW(l)分别是节点u的容量约束。节点u的初始NodeRank值为:
(7)
假设u,v∈V是两个不同的节点。令:
(8)
(9)
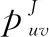
(10)
对于任何节点v∈V,令:
(11)
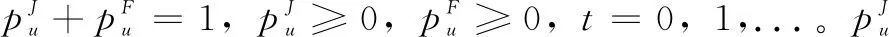
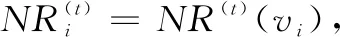
NR(t+1)=T·NR(t)
(12)
其中:T是由马尔可夫链定义的一步转移矩阵:
(13)


算法1:NodeRank计算方法1:给定一个正值ε,i←02:repeat3:NR(i+1)←T·NR(i)4:δ←‖NR(i+1)-NR(i)‖5:i++6:until δ<ε
3 NodeRank映射:RW-MaxMatch和RW-BFS算法
利用拓扑感知的节点资源等级NR(*),本文设计了两种新的VN嵌入算法,即RW-MaxMatch和RW-BFS,它们都将底层网络和虚拟网络作为输入。
3.1 RW-MaxMatch
3.1.1 描述和讨论

算法2:RW-MaxMatch节点映射阶段1:使用算法1计算Gs和Gv中所有节点的节点值,给定值为ε2:按照非递增顺序的NodeRank值对Gs中的节点进行排序3:按照非递增顺序的NodeRank值对Gv中的节点进行排序4:使用L2S2映射过程将虚拟节点映射到底层节点5:if 满足节点资源约束 then6:return NODE_MAPPING_SUCCESS7:else8:return NODE_MAPPING_FAILED9:end if
在第二阶段中,RW-MaxMatch将虚拟链路映射到底层链路(参见算法3)。链路嵌入阶段与文献[9]类似。即通过对k值进行二进制搜索来搜索k-最短路径,找到最恰当的最短路径,直到在底层网络上找到满足虚拟链路带宽要求的路径为止。如果底层网络支持路径分割,本文将使用多商品流算法[10]将虚拟链路嵌入到映射虚拟节点之间的底层链路。

算法3:RW-MaxMatch链路映射阶段1:if 路径不可分割 then2:使用k-最短路径算法映射虚拟链路3:else4:使用多商品流算法映射虚拟链路5:end if6:if 链路资源约束满足 then7:return LINK_MAPPING_SUCCESS8:else9:return LINK_MAPPING_FAILED10:end if
3.1.2 时间复杂性分析
迭代方案(即算法1)已被证明可以产生任何所需的精度ε,其迭代次数与max{1,-logε}成比例[10]。k-最短路径[11]链路映射算法和多商品流问题[10]都可以用多项式时间求解。因此,RW-MaxMatch是|Gs|,|Gv|和max{1,-logε}的多项式时间算法。
3.2 RW-BFS
3.2.1 描述和讨论

算法4:RW-BFS1:给定值ε使用算法1计算Gs和Gv中所有节点的NodeRank值2:构造Gv的广度优先搜索树3:在广度优先树的每个级别中根据其NodeRank值以非递增顺序对Gv中的所有节点进行排序4:backtrack_count=05:选择一个正整数6:for 每个节点Niv都属于Gv do7:构建Niv的候选底层节点列表8:if Match(Niv)==1 then9:Match(Ni+1v)10:else11:if backtrack_count<=Δ then12:Match(Ni-1v)13:backtrack_count++14:else15:return BFS_FAILED16:end if17:end if18:end for19:return BFS_SUCCESS
RW-BFS的主要框架由算法4给出,并且匹配函数的细节由算法5给出。与RW-MaxMatch不同,RW-BFS是基于广度优先搜索(bfs)的一阶段回溯VN嵌入算法,它在同一阶段嵌入虚拟节点和链路。该算法的目的是在不考虑链路映射阶段的影响情况下,先对所有虚拟节点进行两级嵌入,从而导致不必要的占用底层网络的带宽资源。例如,当虚拟网络中的虚拟节点彼此非常接近(例如,只有一个跳跃)时,底层网络中两个映射虚拟节点的距离可能相当长。因此,两个节点之间的虚拟链路必须映射到长路径,从而导致带宽资源的浪费。

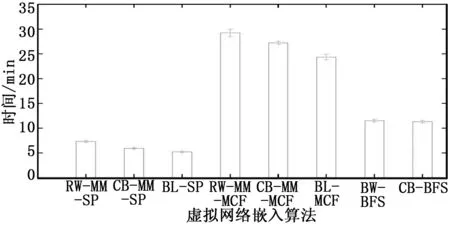
算法5:匹配函数的细节1:if Niv是根 then2:将Niv映射到具有最大NodeRank的底层节点上3:return MATCH SUCCESS4:end if5:k=16:while k 3.2.2 时间复杂性分析 由于回溯算法具有指数时间复杂性,为了避免指数爆炸,本文引入了一个上限θ来限制节点重新映射操作的次数(在算法4步骤11中)。 在本节中,首先描述了性能评估环境,然后介绍了本文的主要评估结果。实验主要研究了两种算法与现有算法的性能比较以及拓扑感知节点排序的优点。 本文实现了两个模拟器来评估算法的性能。RW-MaxMatch模拟器是在文献[12]中设计的VN嵌入模拟器的改进版本,RW-BFS模拟器是从零开始实现。两个模拟器都可以在文献[13]中公开使用。 底层网络拓扑结构配置为具有100个节点,约500个链路,对应于中型ISP。本文使用GT-ITM工具生成底层网络。底层节点、链路的CPU和带宽资源是实数,且均匀分布在50到100之间。假设VNR的到达遵循泊松过程,平均到达率为每100个时间单位5个VN,并且每个VNR具有指数分布的寿命,平均为500个时间单位。在每个VNR中,虚拟节点的数量由2到20之间的均匀分布决定。平均VN连接固定为50%,即n个节点VN平均具有n(n-1)/4个链路,与文献[14]相似。虚拟节点和链路的CPU和带宽要求是实数,均匀分布在0到50之间。本文对每个模拟运行大约50000个时间单位,这相当于在一个模拟实例中平均得到2500 个VNR。 本文的模拟实验评估了表1中列出的8种算法。对这8种算法运行10个不同的实例,并记录十次运行的算术平均值作为最终结果。在本文中,支持位置约束并不是研究的重点,因此没有将本文的算法与文献[15]中提出的考虑位置约束的算法进行比较。本文还考虑将本文的算法与文献[16]中提出的基于子图同构的虚拟网络嵌入算法进行比较。然而,在文献[16]中的算法仅限于由有向图建模的底层网络和虚拟网络,因此不适用于公平比较,因此我们将其排除在结果之外。 表1 算法描述比较 本文的评估结果量化了所提出的两种算法(如图3(a)、图3(b)和图3(c)所示)的效率,并揭示了使用RWmodel计算节点资源等级的优点(如图4(a)、图4(b)和图4(c)所示)。为了进行评估,使用了几个性能指标,包括方程式(3)定义的长期平均收益、方程式(4)定义的VNR接受率、方程式(5)定义的长期R/C比率以及这些算法的运行时间。本文将模拟得出的主要观察结果总结如下。 4.2.1 接受率和平均收益的提高 图3(a)和图3(b)表明,无论底层网络的路径可分割性如何,所提出的RW-MM-SP和RW-BFS都可以产生比基线算法更高的收益和接受率。这两个图表明,拓扑感知的节点排序在VN嵌入过程中起着重要作用。虽然RW-BFS产生了最高的接受率,但该算法的长期平均收益低于RW-MM-MCF,这是因为RW-BFS倾向于接受较小的VNR并拒绝许多较大的VNR,从而使底层网络上的剩余资源具有较大的碎片化。 4.2.2 RW-BFS产生最高的长期R/C比率 由于RW-BFS使用宽度优先搜索来映射虚拟节点,并且避免将虚拟链路映射到可能导致更多资源消耗的长底层路径上。图3(a)表明,在不可分割路径的情况下,RW-BFS产生的收益最高,这与其长期高R/C比率密切相关(如图3(c)所示)。较低的VN嵌入成本为未来的VNR节省了更多的空间。 4.2.3 NodeRank具有更好的节点资源度量 与简单地使用等式(6)作为节点资源的度量相比,计算NodeRank可得到更高的收益和接受率。对于两阶段VN嵌入算法,图4(a)和图4(b)表明,RWMM-SP和RW-MM-MCF比CB-MM-SP和CB-MM-MCF提供更大的收益和更好的接受率。NodeRank还有助于提高单级VN嵌入算法的收益和接受率。使用NodeRank,资源排名不仅由节点本身决定,而且还受其邻居节点的影响。具有较高NodeRank值的节点往往会有一组NodeRank值越高的良好邻居节点,这可以增加满足VN请求约束的概率,从而有利于VN嵌入过程。然而,如图4(c)所示,NodeRank对提高R/C比率没有显著贡献。 4.2.4 基于RW的算法运行时间与其他算法相当 图5给出了同一PC上运行的这些VN嵌入算法的平均执行时间。基于RW的算法与基于CB的算法消耗时间几乎相同,即使基于RM的算法需要计算每个VNR的底层网络和虚拟网络中的节点等级。对于具有100个节点和500个链路的底层网络,计算节点等级的迭代过程在大约7次迭代中收敛到合理的容差,即算法迭代计算合理。 图5 嵌入算法在95%置信区间的执行时间比较 本文基于马尔可夫随机游动计算了节点资源的拓扑感知等级。利用节点的资源等级作为资源度量,提出了RW-MaxMatch和RWBFS两种新的算法。仿真结果表明,本文的算法在长期平均收益和VNR接受率方面优于其他的方法。同时还证明了应用RW模型计算节点资源等级以获得更高的接受率和更高的收益的优点。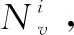
4 实验分析
4.1 评估设置
4.2 评估结果
5 结论
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年6期)2022-07-13
军民两用技术与产品(2022年2期)2022-06-01
移动通信(2021年5期)2021-10-25
今日农业(2020年20期)2020-12-15
海峡姐妹(2017年6期)2017-06-24
科技创新导报(2016年27期)2017-03-14
商业会计(2015年15期)2015-09-21
小说林(2014年5期)2014-02-28
电影新作(2014年5期)2014-02-27
