
改进K-Means聚类算法在停车用户价值分群中的应用∗
2019-07-31 09:54李向荣范福海孟向海
计算机与数字工程 2019年7期
李向荣 范福海 孟向海
(青岛科技大学 青岛 266061)
1 引言
伴随着互联网时代引发出激烈的市场竞争,现在很多企业将营销的焦点,从传统的以产品为中心转变为以用户为中心,而用户关系管理系统的关键问题就是用户的价值分类,企业通过将用户进行分类,可以针对不同价值的用户为用户制定个性化的服务方案,最大限度挖掘用户的潜藏价值,充分发挥营销策略,实现企业利润最大化、服务用户最优化的目标。K-Means 算法作为典型的基于距离的快速聚类算法,在企业进行用户价值分类中得到较广泛的应用。该算法最初是由Steinhaus、Lloyd、BallHall、McQueen 分别于 1955 年、1957 年、1965 年和1967 年在各自不同的科学领域独立提出来的,后来被广泛研究和应用,并在后续发展中不断的改进和优化[1~2]。
本文以现有停车业务后台数据为支撑,结合传统K-Means聚类算法,提出了一种确定样本数据最优聚类数的方法,用来评估该算法的聚类结果,并确定样本数据的最优聚类数,有效地解决了重复选择聚类数目导致的聚类效率低、迭代繁琐[3~5]。根据停车数据的内在需求,借鉴经典的客户关系管理RFM 模型,结合实际停车业务场景,通过建立合理的用户价值评估模型,对用户聚类分群,分析比较不同用户群的用户价值,给企业后续制定差异化的营销策略,针对不同的用户群提供个性化的用户服务提供了良好的参照。
2 K-Means聚类算法
2.1 K-Means算法原理
K-Means 算法是以距离作为相似性的评价指标,并在最小化误差函数的基础上将数据划分为预定的类别数据k 的一种典型的聚类算法。即认为两个对象的距离越近,其相似度就越大[6]。
设X={x1,x2…,xi,…,xn} 是一给定的包含n个m 维数据点的数据集合,其中 xi∊Rm,采用K-Means 聚类算法是将数据对象划分为k 个划分W={wi,k=1,2,…k },每一个划分称为一个类wk,每一个类均有一个类别中心μi,选取欧式距离作为类别间相似性和距离判断准则,计算各点到聚类中心的距离平方和:

通过K-Means 聚类算法实现数据分类的目标就是使各类的距离平方和J( )wi最小。K-Means聚类算法其实是一个反复迭代的过程,最终实现所有数据样本到各聚类中心距离的平方和J(W )最小。整个算法执行一次的流程包括图1 中4步。
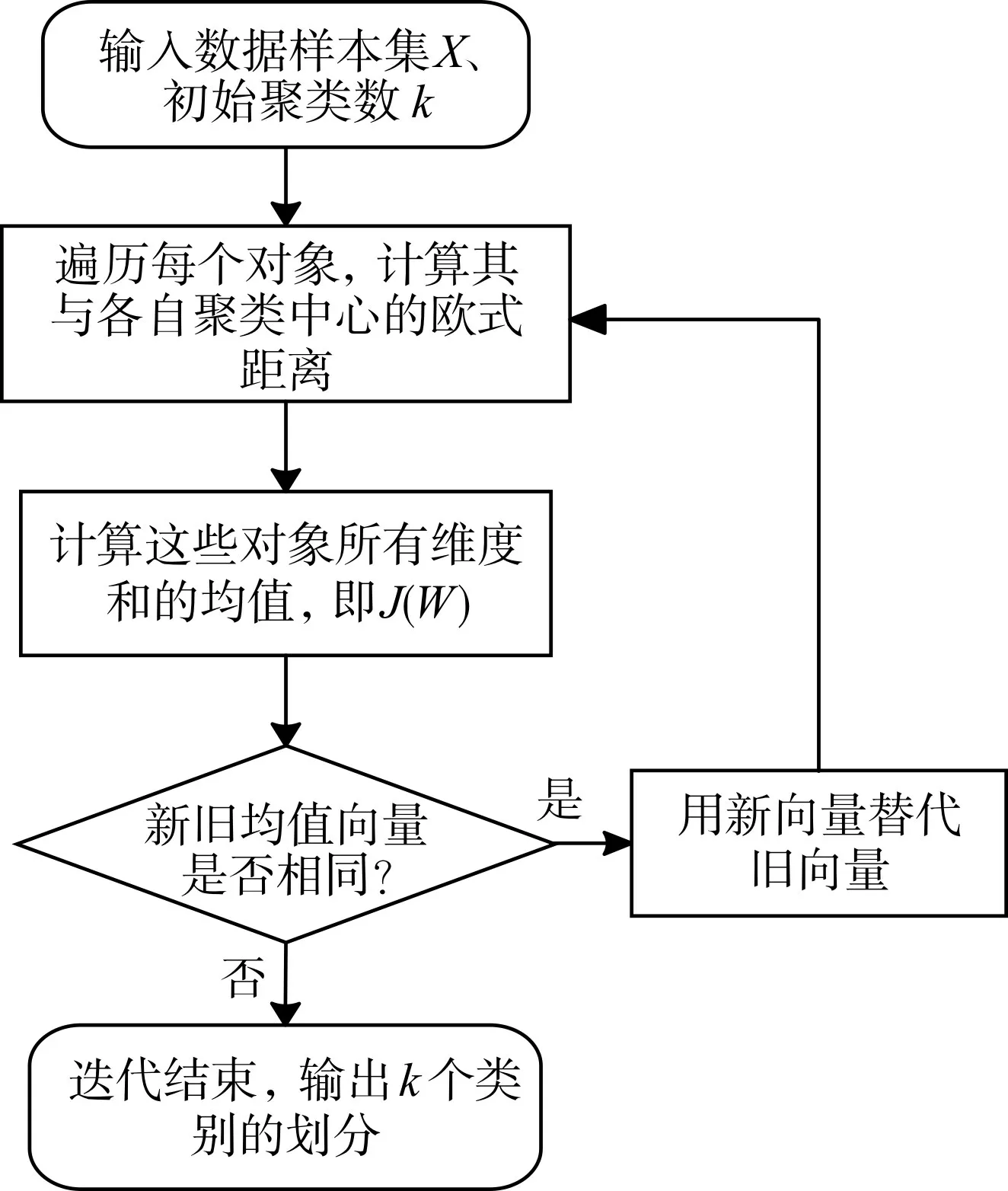
图1 传统K-Means聚类算法流程
由图1 得知,传统K-Means 聚类算法是在假设聚类数k 已知的前提下进行的,由于缺少严谨的数学准则,多年来学者们先后提出启发式和贪婪准则来确定类别数k ,较具有代表性的是根据经验准则2 ≤ kmax≤来选择不同的聚类类别,多次运行K-Means算法,从而选出理想效果情况下的最优聚类数[4~8]。因此,该算法明显的缺点是必须事先给定聚类数k 或多次迭代寻优,如果选择了不准确的k 值往往会使聚类质量下降,就失去聚类的意义。
2.2 改进K-Means聚类算法
鉴于此,为了更加有效地反映聚类结构类别间的分离性和类别内的紧密型[5],提出BWP 指标,来确定算法的最优聚类类别数k 。
假设 K=(X ,Y )为聚类空间,其中 X={x1,x2,…xn} ,n 个数据对象被聚成m 类,定义第i类的第 j 个样本的最小类别间的距离为a( i,j ),其最小类内距离为b( i,j ),定义BWP 指标为第 i 类的第 j 个样本的聚类距离与其聚类离差聚类的比值,其计算公式为
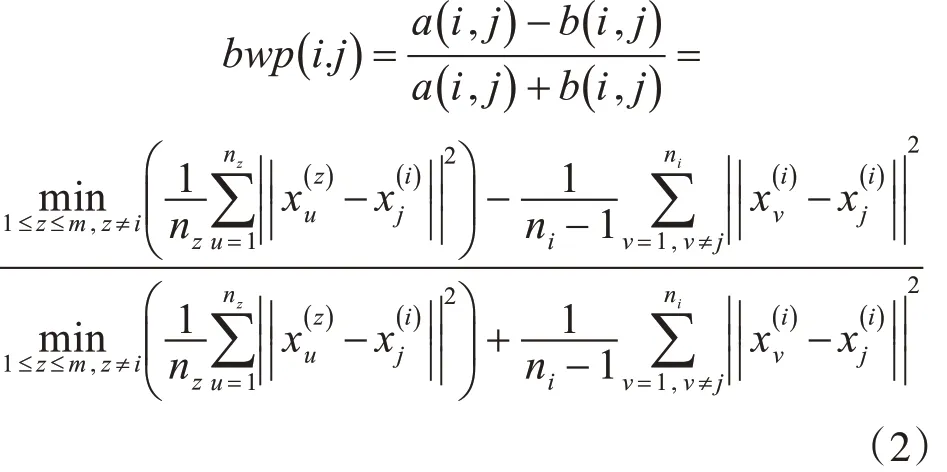
BWP 指标可以很好地正向反映单个样本聚类的有效性,对于整体数据集,可以通过计算所有样本数据聚成k 类时BWP 指标的平均值avgbwp( k ),来分析总体聚类效果,其对应的最大值就是所需的最优聚类数kσ。
其中:
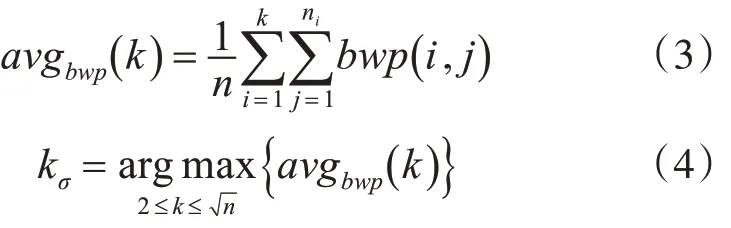
通过改进K-Means 聚类算法直接定位样本数据所要聚成的类别,省去了多次重复迭代的时间。该算法执行过程如下:
1)输入样本数据集,初选聚类类别范围2 ≤ k ≤ n ;
2)循环调用K-Means算法,并利用(2)式和(3)式分别计算出单个样本的BWP 指标值和数据集平均BWP指标值;
3)将式(3)结果代入式(4)计算并输出最优聚类数kσ;
4)利用该聚类数分析得出聚类结果。
3 改进K-Means 聚类算法在停车业务上的应用
3.1 数据准备与预处理
根据实际分析需求,提取江苏省常熟市停车项目以2017 年11 月30 日为截止时间,选取宽度为十个月的时间段作为观测窗口,并将该时间段内的所有停车订单记录数据进行探索、预处理后,重构数据字段作为分析模型参数,在进行变量标准化、归一化处理后[8~12],作为K-Means聚类分析的数据集。
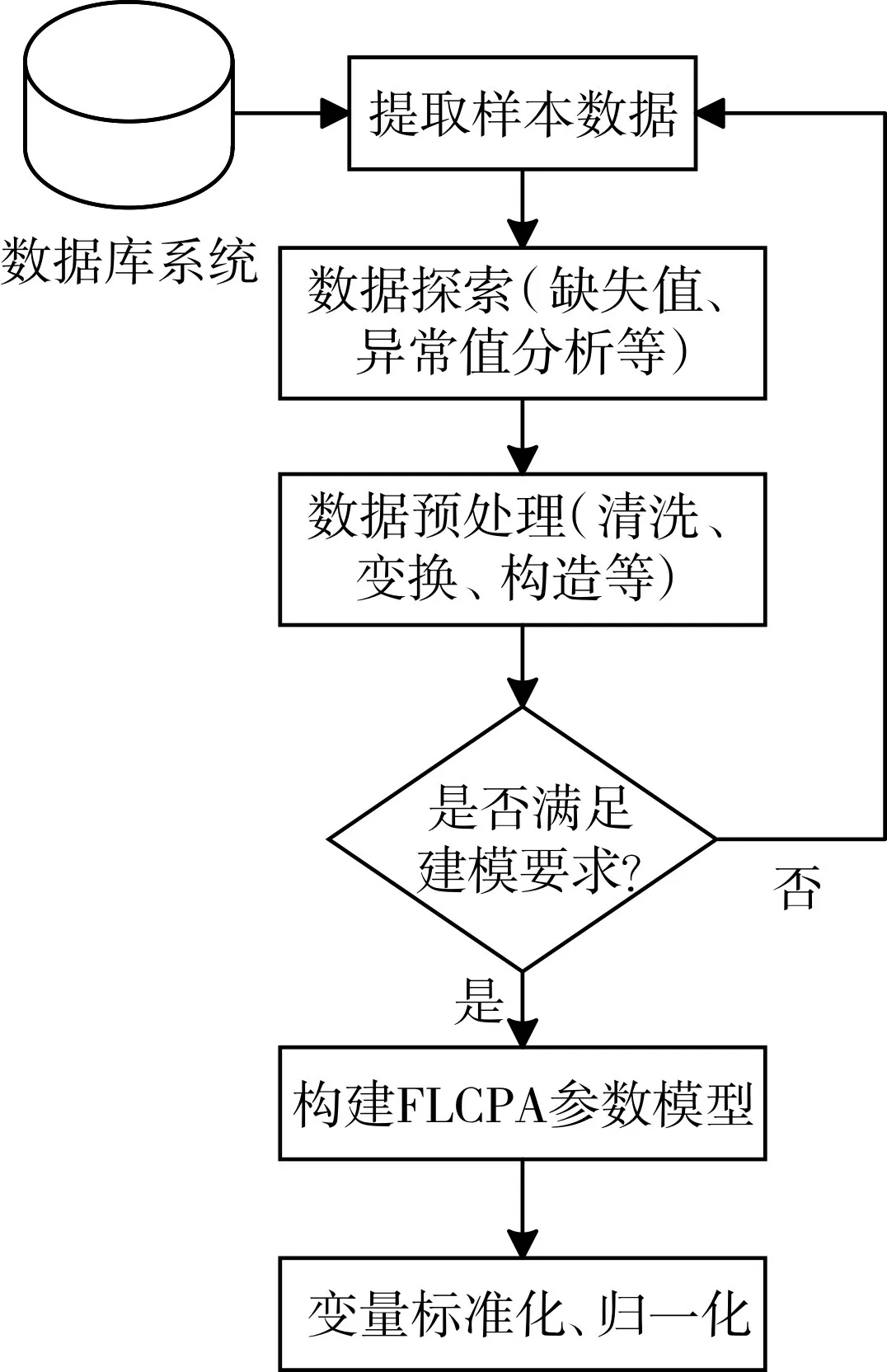
图2 FLCPA模型构建流程
特别的,在FLCPA 模型中:以车辆号牌作为唯一的ID 标识,F(Frequency)表示车辆累计停车次数;L(Length)表示车辆的平均停车时长;C(Cost)表示车辆停车后系统的平均计费;P(Pay)表示车主平均支付的费用;A(Arrears)表示车辆的累计欠费额度。
3.2 BWP指标确定与最优聚类数
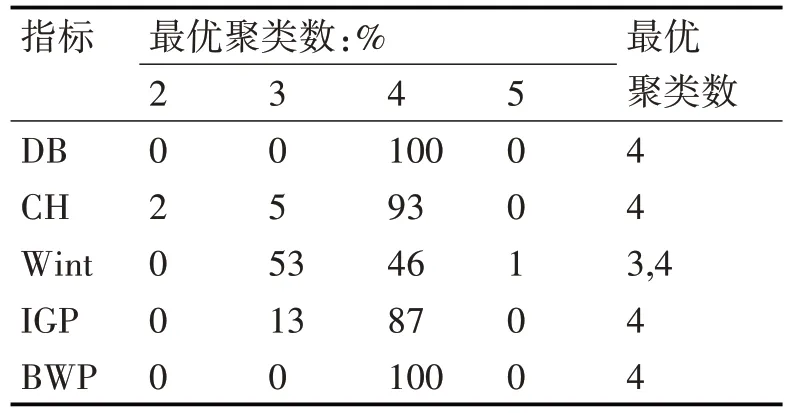
表1 几种有效性指标确定的停车数据集的最优聚类数
为了更加有效地检验BWP 指标确定最优聚类数 k 的性能,引入 DB 指标、CH 指标、Wint 指标和IGP 指标这四项指标作为参照[5,13]。停车数据集的结构分布和聚类结果如图3所示。

图3 k=4 时停车数据集的最优聚类结果
3.3 用户分群聚类结果
根据以上步骤最终确定,针对现有采集的停车订单数据集,采用改进K-Means聚类算法的最优聚类数为4。表2 是得出的最终聚类结果,表3 展示了各分类用户群的优势特征和劣势特征。
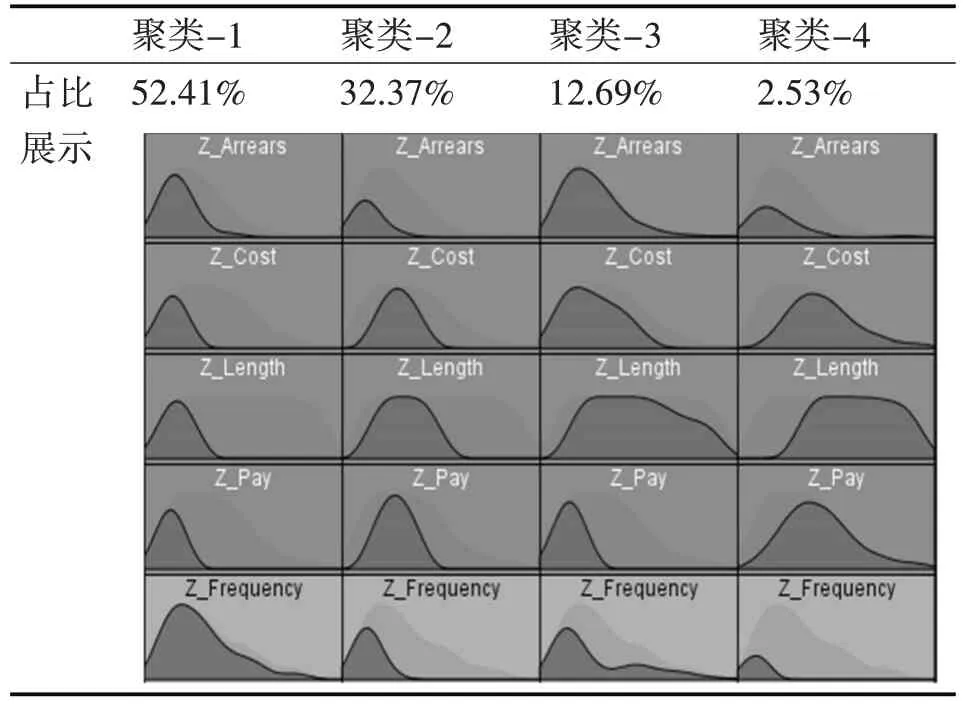
表2 停车数据集的最终聚类结果
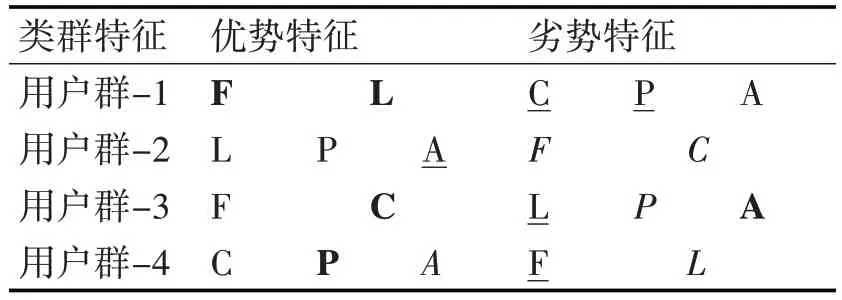
表3 用户分类群特征描述表
通过综合考虑实际停车业务,每个用户群都有各自显著的表现特征,基于该表现特征,可将以上类别定义成四个等级的用户类别:重要保持用户、重要发展用户、一般价值用户、一般挽留用户[14~17]。各类用户群的价值特征如下。
重要保持用户(用户群1):这类车主的显著特征是停车次数(F)多、单次停车时间(L)较长、且欠费额度(A)少,这类用户是停车业务链中最优质的会员,其贡献最大,是项目营收的主要成分。
重要发展用户(用户群2):这类用户是停车业务中的潜在用户,其平均停车时长(L)和平均支付金额(P)较好,且信用度最高,但由于这部分车主停车不固定,应尽可能积极引导用户。
一般价值用户(用户群3):这类用户存在明显的欠费行为,信用度较差,总体占比一般,可能大都在开展活动时选择收费停车泊位停车。
一般挽留用户(用户群4):这类用户停车频率(F)最少,且只占总体的2.53%,整体价值较低,较少活动在城市中心等繁华路段。
4 结语
本文通过改进传统K-Means 聚类算法聚类数不确定问题,采用BWP 有效性指标来确定最优聚类数,减少了重复迭代的繁琐,提高了算法运行的效率,并在此基础上将其应用于实际停车业务后台数据中,根据业务的需求,重新构建FLCPA 参数模型,理论与实践相结合,充分验证了改进K-Means聚类算法在用户价值分群中的必要性和良好性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
陶瓷学报(2021年4期)2021-10-14
消费电子(2021年6期)2021-07-17
少儿画王(3-6岁)(2020年4期)2020-09-13
求知导刊(2019年17期)2019-10-18
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
黑龙江史志(2014年12期)2014-11-24
微型计算机(2009年4期)2009-12-23
