
基于稀疏自编码器与梯度方向直方图的手势识别∗
2019-07-31 09:55缑新科高庆东
计算机与数字工程 2019年7期
缑新科 高庆东
(兰州理工大学 兰州 730000)
1 引言
深度学习是近年来研究的热门课题,它有模拟人类大脑结构的功能,通过组合底层特征形成更加抽象有效的特征表达来完成对图像的整体描述,广泛应用在图像识别、语音识别、自然语言处理等领域。大量实验证明用深度学习的方法做图像处理优于传统的图像处理方法。自动编码器(Sparse Auto Encoder,SAE)是典型的深度学习网络,它在2006 年由 Hinton[3]提出,SAE 是一种较成熟无监督学习算法,在特征提取中有很好的表现,但是对数据集有过强的依赖,当训练数据集较小时提取的特征对样本的表达能力较差。梯度方向直方图算法(HOG)是在 2005 年由 Dalal[1]提出,该方法可以很好地提取单张样本图像的特征,该特征可以很好地描述图像的轮廓信息,但是HOG 特征不包括样本的类别信息。本文结合以上两种方法用HOG 特征减小SAE 对于样本集大小的依赖性,通过SAE 对HOG特征添加样本类别信息。使用该方法提取Jochen.Triesch 数据集上手势图像特征,可以很好地表达图像样本,并且作为分类器的训练数据。
2 基本理论
2.1 梯度方向直方图(HOG)
一副图像中局部目标的表象和形状能够被梯度或边缘的方向密度分布很好的表示,其本质是梯度的统计信息而梯度主要存在于边缘的地方通过计算图像局部区域内梯度的大小和方向来构造HOG 特征,该特征包含的是图像的轮廓信息,获取HOG特征具体分为4步。
1)标准化Gamma 空间和颜色空间:减少光照干扰和抑制噪声,标准化公式为式(1)。
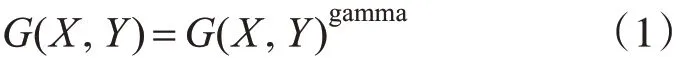
其中gamma=1/2,未经过标准化和标准化后对比如图1所示。

图1 原图(左)与标准化图(右)
2)图像梯度计算:将图像分成胞元分别计算胞元内像素点的梯度,梯度计算公式如式(2)、(3)。
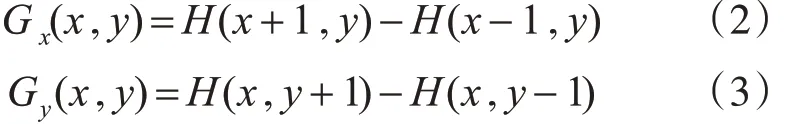
其中Gx(x,y),Gy(x,y)分别为X 方向上的梯度和Y方向上的梯度,胞元内像素点的梯度计算和方向计算如式(4)、(5)。
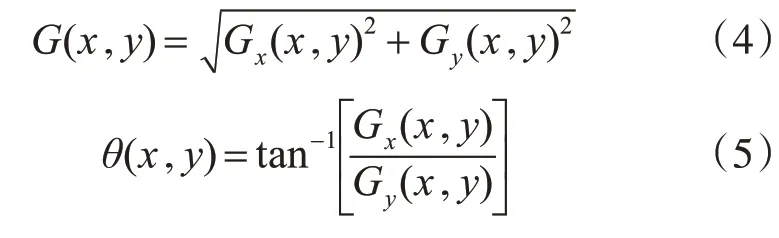
3)空间和方向上梯度统计:将胞元内的梯度进行统计每个像素点的梯度方向可能是范围0~180°之间的的任意值,经过Dalal 等的证明将方向角度分为9 等份(bin)时获得的识别效果最佳,bin 数越大意味着计算量越大对于实际的效果并没有明显改善,本文使用的图像为64×64 的灰度图,首先将图片分为16×16 的块再将块分为8×8 的胞元,块的移动步长为8×8,每个胞元内的梯度方向使用9 等份来做方向等分。最终的特征个数计算如下:
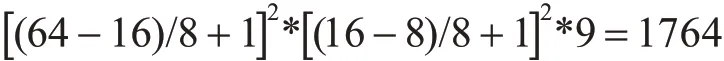
4)归一化处理:将得到的特征进行归一化处理可以增强特征的鲁棒性。将特征串行组成特征向量,归一化函数使用如式(6)( μ 为防止分母为0 选取较小的一个值本文取0.002):
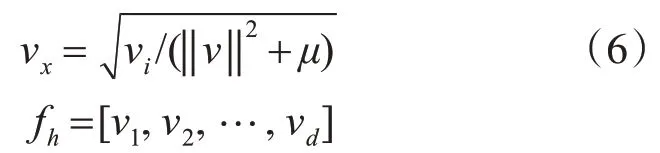
fh即为图像的HOG 特征,该特征可以有效地表示手势图像蕴含的信息。将HOG 特征扩展为图像信息时的效果如图2所示。

图2 原图(左)与梯度图(右)
2.2 稀疏自编码器(SAE)
自编码器是一种无监督学习的神经网络该结构,主要由输入层,隐藏层和输出层组成,层与层之间是全连接关系,输出层神经元个数等于输入层神经元个数,自编码网络如图3所示。

图3 自编码网络
对于输入数据 X=[x1,x2,…,xN]第j 个隐藏层神经元的输出计算如式(7)所示
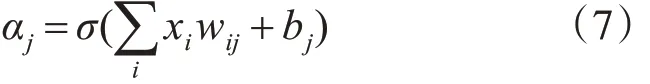
其中激活函数表示为式(8),wij为输入层与隐藏层的连接权值bj为隐藏层偏置。
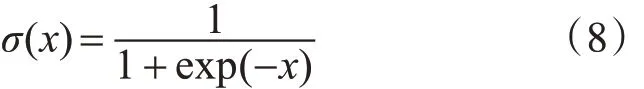
输出层的输出可以看做输入的重构其表达为式(9)。

自编码器的目标是让重构输出尽量接近实际输入,使用最小平方误差函数来描述这种关系其表达式为式(10)。
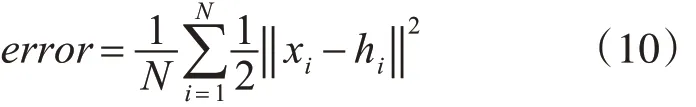
为防止网络过拟合问题在误差函数中增加权重衰减项对权值大小进行限制,误差函数的表达为式(11)。
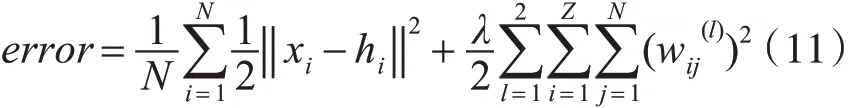
其中l 表示网络层间的权值分布,λ 表示正则项系数,物理含义表示正则化项对于整个网络误差的影响力大小。
稀疏自编码器(SAE)是根据自编码器改进而来。在图像处理中稀疏性约束能够使得编码表达更有实际意义,因此本文在特征提取中加入了稀疏性限制。通过对隐藏层响应添加约束条件使得隐藏层大部分神经元处于“抑制”状态,只有少数处于“兴奋”状态。对隐藏层的约束限制反映在数学表达上是通过代价函数添加隐藏层输出信息。在设置稀疏参数时首先计算隐藏层的平均活跃度也就是隐藏层神经元输出结果的均值,计算如式(12)。

设置稀疏性参数ρ,通常是一个接近0 的比较小的值(本文选取 ρ=0.1),当 ρ 与稀疏性参数相等时,隐藏层神经元的平均活跃度接近0,为实现这一限制选择一个有效的惩罚项因子函数,本文选择相对熵函数该函数如式(14)。

其中Z表示隐藏层神经元的个数:
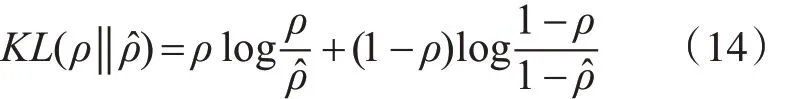
KL( ‖ρ ρˆ)是一个以ρ 为均值和一个以ρˆ为均值的两个伯努分布之间的相对熵。加入正则化项,加入稀疏因子项后SAE的最终损失函数为式(15)。

其中μ 为稀疏因子项对整体损失影响大小的比率一般选择3 附近的值,本文正则项系数为λ=3e-3,稀疏因子项系数为μ=3。
在训练SAE网络时使用BP算法和随机梯度下降算法,可以有效地减小损失函数,避免网络陷入局部最优解,每一个SAE 都是单独训练,训练完成后上一个网络隐藏层的输出作为下一个网络的输入,最终形成一个完整的可用的图像特征提取网络,用该网络提取的图像特征作为分类器的训练集用来训练分类器。
2.3 SVM分类器
SVM 分类器是一种应用广泛而且效果显著的分类器,一般用来解决线性可分的分类问题,其工作原理是将输入的特征向量映射到Hilbert 空间里,在这个高维空间里求得一个超平面,使得这个超平面对于样本具有最大分类间隔,其核心本质问题是求解拉格朗日条件极值下的对偶问题。
超平面函数h(x)=w ⋅x+b,样本之间的最大距离为2 ‖ ‖w2正确分类条件的数学表达如式(16)。
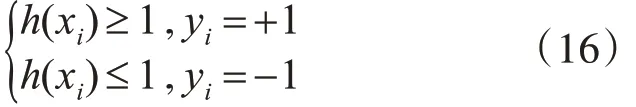
最终分类问题表达式为

通过求解该条件极值解得SVM的分类超平面。
对于线性不可分的问题用核函数的方法将特征映射到更高的空间维度去实现线性可分,核函数K(x,xj)使用时对原来的特征空间进行转化,使原来的特征空间经过核函数变化向高维空间拓展,在拓展后的特征空间上数据集是线性可分的,所以分类超平面可以找到,对于使用核函数的SVM 其本质仍然是拉格朗日条件极值的对偶问题,不同的是在原表达式的基础上将(xi⋅xj) 替换为 K(x,xi) 。由于SVM 分类器只对样本中的个别支持向量代表的样本比较敏感,所以对于训练集的大小没有依赖性,对噪声图片具有很强的鲁棒性,在使用核函数的情况下可以进行高维特征空间下的分类。常用的核函数有4 种:1)线性核函数;2)多项式核函数;3)径向基核函数;4)Sigmoid 核函数。经过试验对比几种核函数在分类结果上的表现,使用径向基核函数时准确率较高所以本文使用的核函数是径向基函数,表达式为

σ 的取值一般为0.001~0.006,本文取0.006。
2.4 算法步骤
首先将图像转化为固定格式的灰度图像,每张图像包含相同数目的像素特征,图像集为X=[x1,x2,…,xn],标签集为 L=[l1,l2,…,lx]。
Step 1:提取图像的HOG 特征每幅图像都具有相同特征维度,将提取的图像特征构成图像数据集。

Step 2:使用HOG 算法提取到的特征来训练SAE,将训练结果保存,训练过程中保证每个SAE网络隐藏层是下一个SAE网络的输入,最终的输出为最后一个SAE 网络隐藏层的输出。每个SAE 网络都是单独训练,将训练结果保存。
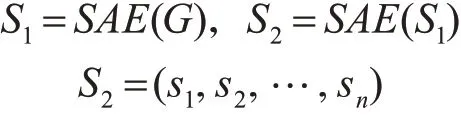
Step 3:用SAE 获得的图像特征集来训练SVM分类器获得分类模型:

Step 4:首先将测试图像经过HOG 做特征提取,再通过SAE 做特征提取压缩,最后输入到SVM分类器中获得最终结果。
SAE 在整个流程中的作用是提取HOG 特征中的有价值信息并做数据压缩。这样可以加快算法速度提高准确率。与目前的用于图像特征提取的卷积神经网络(CNN)相比虽然CNN 在应用中具有良好的表现,但是其性能的好坏取决于有标记训练样本的多少,对于样本集的大小有过强的依赖性而且收集有标签数据也是其中关键和艰难的一步,本文中使用的方法在体征提取部分无需标签数据,减少了数据收集的工作,在训练模型的过程中可以人工生成较多的数据。
3 实验分析
为验证本文设计算法的有效性,选择Jochen.Triesch手势库中的图像数据作为训练集和验证集,训练集数据通过HOG 提取特征,再通过SAE 提取和压缩特征,最后作为训练SVM 分类器的数据,完成训练后保存模型,在预测单张图像数据时直接调用模型即可。本文实验部分在vs2012软件上实现。
3.1 数据集介绍
Jochen.Triesch 手势库共包含10 种字母手势每种手势包含24 个人分别在亮,暗,复杂3 种不同背景下采集的样本,共计720 个手势样本大小从50×50到80×80不等,为了方便实验进行将图像进行分割裁剪缩放等处理,最终得到的是大小为64×64 的样本图像,本文实验用到其中部分手势且自定义标签如图4,训练集数目为240 验证集数目为120。实验之初已经对样本集进行了处理包括归一化和灰度化。

图4 从左至右以此为012345
3.2 实验结果与分析
实验中使用两个SAE分别训练,将训练完成的网络串联作为特征提取模块,并以识别正确率作为评判标准。实验1 在单独考虑HOG 算法下对手势图像进行分类,使用HOG 算法获得的手势特征为1764维,其中SVM分类器使用径向基核函数参数σ取0.006最终结果如表1。

表1 HOG算法下分类表现
从表1 看出单独使用HOG 算法在分类速度和准确率上表现较差,特征维度较大时训练SVM 花费资源较多。特征维度与分类速度有直接的关系。实验2 在单独考虑SAE 算法下对于手势图像进行分类,首先SAE 训练完成,其中SAE 网络为两个,第一个SAE 隐藏层神经元个数为2000,第二个SAE隐藏层神经元个数为1600,最终输入到分类器的特征维度为1600。在训练SAE 的过程中涉及到的超参数有正则项系数,稀疏性参数,稀疏项系数,随机梯度下降算法下学习率,网络迭代次数,根据经验与实际问题结合,选择超参数范围如表2。

表2 超参数范围
使用SVM分类器最终获得的分类结构如表3。
从表3 看出单独使用SEA 算法在小数据集下获得的分类效果较差,从分类速度和准确率来看并没有比传统的HOG 算法更好。实验3 使用HOG 做特征提取,将提取的特征再使用SAE做体征提取与压缩,最终的特征包含了单独样本的特征和类别特征。其中SAE 最终输出的特征维度为300。训练SVM分类器得到结果如表4。

表4 HOG-SAE算法下分类表现
从表1、3、4 结合准确率和分类速度可以看出HOG-SAE 要优于分别单独使用时的效果,SVM 最终所要处理的特征维度由原图的4096转化为300,大大缩短了SVM 的处理时间。在使用该特征训练SVM分类器时,模型也能相对较快的收敛到误差合理的程度。
4 结语
本文通过结合传统的图像特征提取算法(HOG)与深度学习算法(SAE)在小数据集下对手势图像识别,实验证明此方法可以加快分类速度提高分类准确率。无监督学习算法SAE 起到了关键作用,它为有监督学习算法提供了训练初始值,在实验中SAE 网络的层数对于特征提取的效果有不可忽略的影响。此外对于分类器整体网络训练而言通常情况下训练数据越多,最终获得的准确率越高对于噪声越具有鲁棒性,但是任何分类器都无法百分百正确分类,只能不断提高分类效果。接下来的研究方向是SAE 网络结构规模与样本集规模的关系和减小错分率的集成分类器。
猜你喜欢
中国设备工程(2022年19期)2022-10-12
九江学院学报(自然科学版)(2022年2期)2022-07-02
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
计算机测量与控制(2019年4期)2019-05-08
雷达学报(2018年5期)2018-12-05
