
基于Word2Vec的微博文本分类研究①
2019-08-22 02:31牛雪莹赵恩莹
计算机系统应用 2019年8期
牛雪莹, 赵恩莹
(太原科技大学 计算机科学与技术学院,太原 030024)
移动互联网的高速发展让人们随时发表言论成为了可能. 以微博、微信等为代表的社交平台成为人们沟通交流的主要方式,同时积累了越来越多的文本数据,特别是短文本数据. 这些数据中蕴含着很多重要的信息,对这些信息的分类和挖掘吸引了很多学者关注.对短文本的分类研究是自然语言处理的一个重要分支,在搜索引擎、自动问答、情感分析和舆情分析等方面有重要意义[1].
传统的向量空间模型(vector space model)[2]对长文本的分类表现出很好的效果,但用于短文本分类却存在特征稀疏和维度灾难的问题,所以直接应用向量空间模型解决短文本分类问题效果并不理想. 面对这个问题,国内外研究者主要从特征扩展和抽象语义特征两方面给出了解决方案.
特征扩展包括利用主题模型扩展和借助外部知识库扩展特征. 由于主题是词语的高层次语义抽象,主题相对词语来说会少很多,这样就能很好的解决维度灾难问题. Phan XH等[3]通过分析文本的主题,并且结合TF-IDF来确定特征. 张志飞等[4]提出基于文档主题生成模型LDA的文本分类模型. 这些都是直接用主题分布来做文本特征.
很多学者[5-9]希望通过外部知识库(例如知网、维基百科、WordNet等)对词语进行扩展,以期解决特征稀疏的问题,但是这个方法受到所用知识库质量的影响. Bouaziz[10]提出先利用LDA模型学习维基百科数据上的主题以及主题在词语上的分布,然后用这些来扩展短文本,再使用语义随机森林对扩展特征进行选抽象高层语义的方法. 这是结合了主题模型和外部知识库来进行特征扩展的方法.
也有很多学者[11-15]希望抽象文本语义特征来进行文本分类研究. 近几年深度学习通过深层次的神经网络实现对特征的高层语义抽象在自然语言处理方面表现突出. 韩栋[16]、冯国明[17]分别采用深度学习的CNN和CapsNet网络进行中文文本分类研究都取得了较好的结果. 以Word2Vec为代表的词向量模型是通过神经概率语言模型学习到词语的向量表达,很多学者[16,17]在此基础上利用一定的权重组合方式得到文本的向量表达,进而进行分类研究.
本文采用的是基于Word2Vec的词向量模型,首先用Word2Vec在维基百科中进行学习得到词向量,然后用改进的TF-IDF设计权重进而得到文本向量,最后用SVM分类器进行文本分类训练,并且通过实验表明该方法与传统方法相比较分类效果有明显提高.
1 基于Word2Vec的短文本分类模型
短文本自动分类是一个有监督的机器学习模型. 让机器根据词语的特征学习模型然后预测文本所属的类别. 在自动文本分类领域常用的技术有朴素贝叶斯分类器、决策树、支持向量机、KNN等. 本文结合Word2Vec和TF-IDF提出短文本分类算法,并验证其有效性.
1.1 Word2Vec词向量模型
Word2Vec是2013年Google的研究员发布的一种基于神经网络的词向量生成模型. 模型是用深度学习网络对语料数据的词语及其上下文的语义关系进行建模,以求得到低维度的词向量. 该词向量一般在100-300维左右,能很好的解决传统向量空间模型高维稀疏的问题. 因为深度的神经网络模型能对特征的高层语义进行很好的抽象所以模型能很好的避免语义鸿沟. 所以Word2Vec是目前应用在自然语言处理方面表现较优秀的方法.
Word2Vec[18,19]主要有Continuous Bag-of-Words Model (CBOW)和Continuous Skip-gram Model (Skipgram)两种模型,CBOW模型是在己知上下文Context(t)的情况下预测当前词t,而Skip-gram模型则是在己知当前词t的情况下预测其上下文词Context(t). 这两个模型都包括输入层、隐藏层和输出层,如图1所示. CBOW模型的输入层是选定窗口个数w的上下文词one-hot编码的词向量,隐藏层向量是这些词向量、连接输入和隐含单元之间的权重矩阵计算得到的,输出层向量可以通过隐含层向量、连接隐含层与输出层之间的权重矩阵计算得到. 最后输出层向量应用SoftMax激活函数,可以计算出每个单词的生成概率. 但是由于SoftMax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢,可使用Hierarchical Softmax来提升速度.
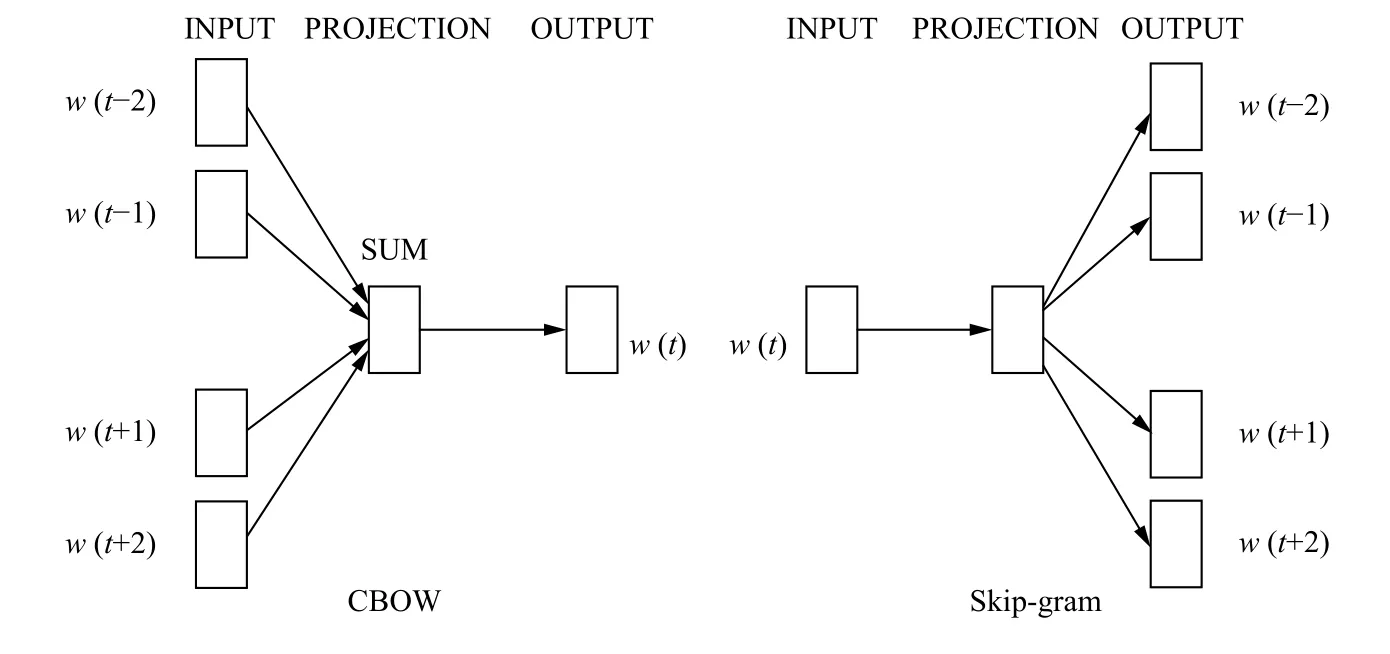
图1 Word2Vec模型
1.2 TF-IDF
TF-IDF[20](Term Frequency-Inverse Document Frequency)是组合了词频和逆文档频率是一种统计方法.
词频(Term Frequency,TF)是指某个给定的词ti在文档dj中出现的频率,频率越高对文档越重要,数学表达公式如式(1)所示:
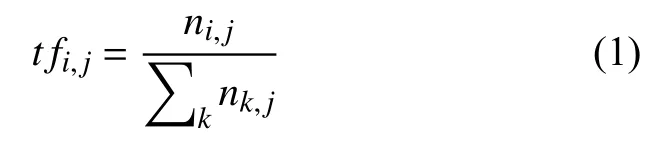
其中,ni,j表示词ti在文档dj中出现的次数,表示文档dj中所有k个词出现次数的总和.
逆文档频率 (Inverse Document Frequency,IDF)是指包含该词ti的文档占总文档D的比重的倒数. 逆文档频率的出现是为了避免一些类似“我”、“的”、“他”等出现频率很高但是对文档分类作用较小的词获得高权重. 数学表达公式如式(2)所示:

子宫内膜癌是一种严重影响女性健康的恶性肿瘤,根据肌层浸润分为无肌层浸润、浅肌层浸润和深肌层浸润[3]。对于子宫内膜癌浸润子宫肌层要早发现早治疗,因此准确诊断出该病是治疗的基础。传统对子宫内膜癌的诊断主要为彩超诊断,阴道诊断以及CT诊断等,但是对于浸润子宫肌层诊断准确率不高,容易发生误诊和漏诊。而分段诊刮和宫腔镜的方法虽然也是诊断子宫内膜癌的常用方法,但是该方法无法是否有肌层浸润及浸润深度等进行判断。实时超声弹性成像是1991年提出的新型诊断技术,具有精确性,可以形象的检测出肌层浸润的情况,浸润深度等。
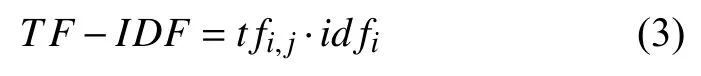
表示词语对于文本的重要性,随着词频的增加而增大,随着文档频率的增大而减小. 也就是说在当前文本中出现频率高且在其他文本中出现的少的词对文本的意义大,均匀出现在各个文本中的词对文本的意义小.
1.3 短文本向量模型
很多学者[21-25]提出基于词向量生成短文本向量的方法. Le[25]等人根据Word2Vec生成词向量的方法扩展到语句、段落、文档的层面上提出PV-DM和PVDBOW模型; 词向量组合法是将文本中所有词语的词向量加权求和的方法. 其中权重确定的方法包括:直接采用词语的TF-IDF值为权重[21]; 采用语法、词性标注结果设置权重[22]等.
对文本分类来说词语对类别的影响更重要,而TFIDF衡量词语对某个文本的重要性并没有考虑词语在类内和类间分布情况,所以本文考虑在TF-IDF的基础上加入类别因素c,提出新的权重确定方法CTF-IDF,数学表达式为式(4):
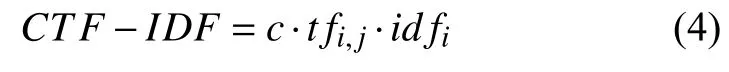
其中,
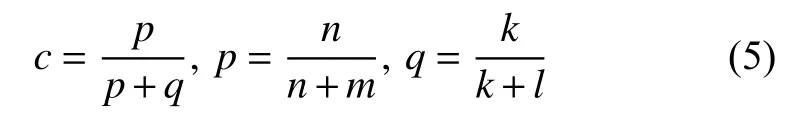
类别因素c,随着词语t在类r中出现频率p的增加而增加; 随着词语t在非r类别中出现频率q的增加而减小,理想情况下词语t都出现在某一个类别中,类别因素c=1. n表示出现词语t且属于类别r的短文本数量; m表示属于类别r,但没出现词语t的短文本数量; k表示出现词语t但不属于类别r的短文本数量;l表示没出现词语t也不属于类别r的短文本数量.
确定词向量权重算法CTF-IDF之后,采用加权求和的方法得到短文本的向量表示,数学表达式为(6).
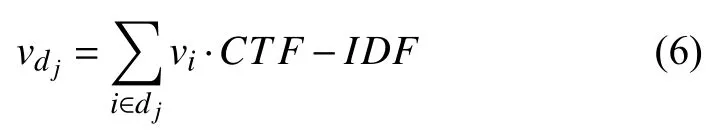
其中,vdj表示文本dj的向量,vi表示词语ti的词向量.
1.4 短文本分类流程
微博短文本的分类流程如图2所示. 首先对文本进行预处理,包括去停用词、分词. 然后用Word2Vec模型对维基百科进行训练,得到大量词语结合上下文和语义的词向量. 下一步是计算短文本的向量,需要把Word2Vec生成的与文本对应的词向量加权求和,权重通过词的词频和分类计算CTF-IDF得到. 最后进入分类器分类,很多研究表明,与其他分类系统相比,SVM在分类性能上和系统健壮性上表现出很大优势[26-28],因此选用SVM分类器作为分类工具,根据短文本向量及其对应的标签训练出分类器. 测试过程与训练过程相似,只是最后通过已训练好的分类器预测测试短文本的标签.
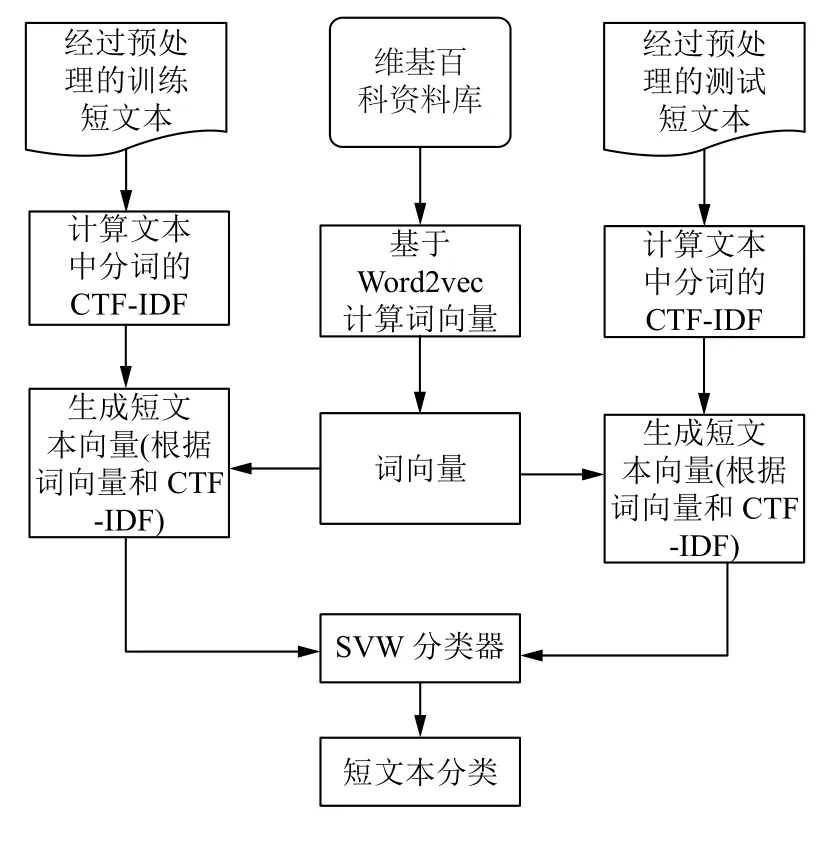
图2 短文本分类流程图
2 微博短文本分类实验
本文前面介绍了短文本分类的流程以及通过词向量生成短文本向量的方法,现通过实验验证本文提出的方法的有效性.
2.1 数据来源和预处理
本文收集了从新浪微博上用八爪鱼爬取到的微博数据29 000条分为以下10个类别,其中IT、财经、时尚、健康、母婴、体育各3500条,医疗、动漫、文学、教育各2000条. 所有类别80%的数据用于训练,20%的数据用于测试. 所有的数据都经过去停用词、去表情符号预处理,并用结巴分词对数据进行了分词处理.
2.2 实验评价指标
分类任务的常用评价标准有准确率(precision)、召回率(recall)和Fl评分[21]. 表1是两分类器混淆矩阵(confusion Matrix),其中TP表示实际是正类、预测也为正类的样本数量; FN表示实际为正类、预测为反类的样本数量; FP表示实际为反类、预测为正类的样本数量; TN表示实际为反类、预测也为反类的样本数量. 准确率是指分类结果中被正确分类的样本个数与所有分类样本数的比例,如式(7)所示.

召回率是指分类结果中被正确分类的样本个数与该类的实际文本数的比例,如式(8)所示.

Fl评分是综合考虑准确率与召回率的一种评价标准,如式(9)所示.


表1 两分类混淆矩阵
2.3 分类实验和分析结果
实验分别用TF-IDF模型、均值加权Word2vec模型、TF-IDF加权Word2vec模型、CTF-IDF加权Word2vec模型对微博数据进行分类实验,试图验证文章提出的CTF-IDF加权的有效性,并分析分类数量对模型的影响.
对于TF-IDF分类模型,使用Scikit-learn提供的TfidfVectorizer模块提取文本特征并将短文本向量化.剩余三种都是在Word2Vec模型的基础上,加权求和得到微博文本向量,只是各自的权重确定方式不同.
均值加权Word2Vec模型是取全部词语向量的平均值; TF-IDF加权Word2Vec模型是用对应词的TFIDF为权重; CTF-IDF加权Word2Vec模型是用本文提出的结合了类别因素的CTF-IDF为权重.
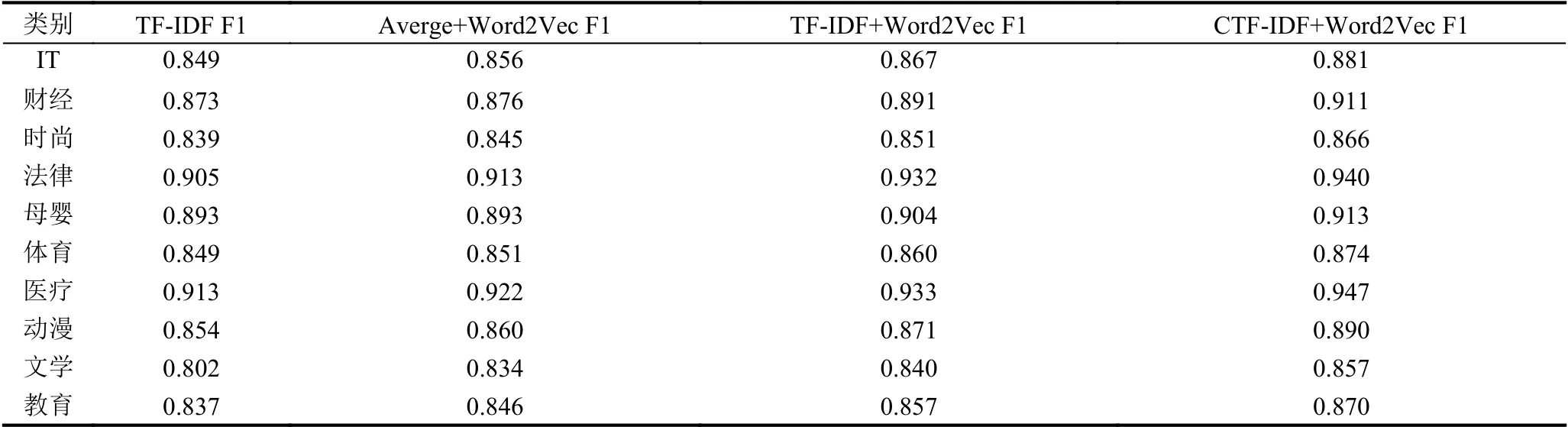
表2 SVM微博文本分类实验结果
从上表可以看出:均值加权的Word2Vec模型比TF-IDF模型在SVM分类器的表现稍好,F1值稍有提升,说明Word2Vec模型比传统的模型生成的词向量能更好的表示文本特征,更适应文本分类.
TF-IDF加权的Word2Vec模型的表现相比均值加权的Word2Vec又有所提高,这是因为相较于平均词向量,TF-IDF加权的方法更能准确的表现词语对于文档的重要性,所以其形成的文档向量在SVM分类器上表现更好. 本文提出的基于CTF-IDF加权的Word2Vec模型表现最好,这是因为虽然TF-IDF考虑了不同词语对文档重要性不一样,但是忽略了对类别的影响,当使用加入类别因素的CTF-IDF权重之后文本在SVM分类器上表现不错. 这说明本文所提出的CTF-IDF加权的Word2Vec模型在短文本分类上的有效性.
从图3可以看出,Word2Vec分类模型准确度与分类类别、类别数量等因素有关,类别数越少模型分类准确度越高.
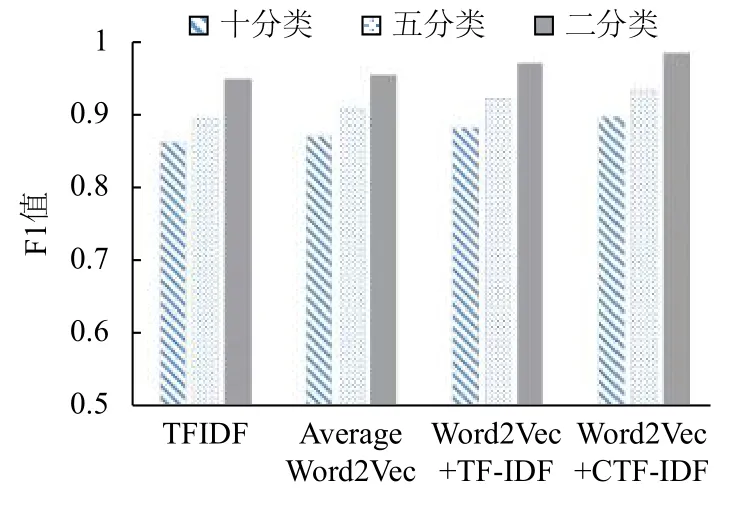
图3 多类别微博文本分类效果图
3 结论与展望
基于Word2Vec的微博文本分类模型与传统的向量空间模型相比在微博短文本分类上表现良好.Word2Vec在短文本分类问题上既可以解决高维稀疏问题又可以结合上下文语义,但是对于词语的权重问题无法解决. 本文在TD-IDF的基础上提出CTF-IDF加权的Word2Vec模型,既考虑了词频又考虑类别因素. 从实验结果可见相较于均值加权的Word2Vec模型、TF-IDF加权的Word2Vec模型,本文提出的CTF-IDF加权的Word2Vec模型在微博短文本分类问题上表现相对最好. 但文章也存在一些不足之处,算法中权重确定方法忽略了词语的位置信息,而词语的位置信息可能对于文档的语义有一定作用,有待后续研究和实验.
猜你喜欢
客联(2022年3期)2022-05-31
电子产品世界(2022年4期)2022-04-21
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
东方教育(2018年20期)2018-08-22
电脑爱好者(2017年7期)2017-05-06
