
基于自适应PSO的改进K-m eans算法及其在电子病历聚类分析应用*
2019-09-03 07:22沐燕舟丁卫平余利国
计算机与数字工程 2019年8期
沐燕舟 丁卫平 高 峰 余利国 张 琼
(南通大学计算机科学与技术学院 南通 226019)
1 引言
PSO是一种模拟自然界的生物活动以及群体智能的全局搜索算法,由Eberhart和Kennedy于1995年提出,该算法即具有进化算法的特点又与遗传算法有相似的搜索及优化能力[1]。由于其自身的原理简单、可调参数相对较少、编码易于实现且应用效果明显等特性,被广泛地用于各类非线性问题的优化。但是PSO对于离散问题的优化则表现的不尽人意,往往会陷入局部最优解。如:黄太安等[2]提出了一种蛙跳简化粒子群算法,将粒子群分多组同时收索,每组粒子进行多次迭代后在分组,从而保证了粒子间的差异性,避免了算法的早熟收敛问题。倪庆剑等[3]提出了动态可变拓扑策略来协调PSO的勘测能力,避免了算法陷入局部最优等。
聚类分析是将庞大的数据划分为有意义的组,而在聚类分析的众多方法中,K-means是最经典最常用的一种聚类算法[4]。K-means聚类是一种矢量量化的方法,最初来自信号处理,由于其处理数据相对简单、快速,已经成为数据挖掘中的聚类分析的流行方法。然而,由于K-means算法本身对初始聚类中心较为敏感往往很容易陷入局部最优解[5]。针对这类问题,符保龙等[6]提出了一种基于均值密度中心估计的K-means聚类算法,Bandyopadhyay S等[7]介绍了一种利用K-means算法原理的基于遗传算法的高效聚类技术,文献结合了K-means和遗传算法的优点,避免了陷入局部最优解。傅涛等[8]将PSO和K-means算法结合在一起用于网络入侵检测分析,其误报率大大降低。
综上所述,我们不难看出上述算法都在一定程度上缓和了原始PSO或K-means存在的一些问题,但是由于医疗病历数据具有明显的异构性、数字表征不明显、数据本身的多样性等特点[9],这两类算法并不能够很好地处理分析复杂多样的医疗数据。因此,本文提出了一种基于自适应PSO的K-means算法,该算法设计了一种自适应惯性权重函数对PSO进行动态调整,然后与K-means算法融合,使K-means的各个初始聚类中心能自适应生成,具有了更好的全局寻优能力。该算法融合了以上两种算法的优点具有更高的电子病历病症聚类准确率和执行效率。
2 改进的自适应PSO
2.1 标准PSO
算法中每个粒子的速度向量定义为vi=(v1i,v2i,…,viD),位置向量定义为 xi=(x1i,xi2,…,xD),将每个粒子在迭代中的历史最优pBest设为
i当前位置,群体中最优的个体作为当前的pBest。在每次迭代过程中,分别计算每个粒子的适应度函数值。若粒子当前适应度函数值优于历史最优值,则将历史最优pBest更新为当前位置。当该粒子的历史最优比全局要好,则该粒子的历史最优替代全局最优pBest。
粒子i的第d维的速度和位置更新公式[10]如下:

其中i代表粒子编号,d为求解问题维数,c1和c2代表非负常数学习因子,rand1d和rand2d表示区间[0,1]上的随机数,ω为惯性权重,一般初始化为0.9。
2.2 自适应PSO
本文提出了自适应惯性权重ω,更新公式如下:
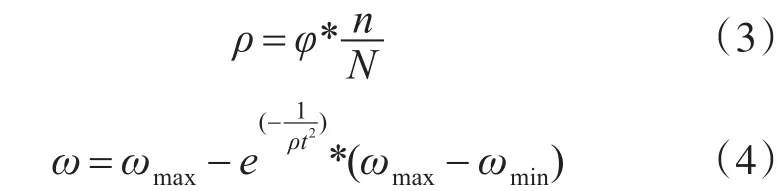
其中N表示粒子总数,n表示集合中粒子的个数,φ表示平衡系数,ρ表示粒子密度,表示最大惯性权重,表示最小惯性权重,t表示迭代次数。由式(4)可知,,则
,其中当迭代次数t(t>0)增加时,由数学关系可以推导出逐渐增大而ω逐渐减小,结合式(1)就实现了PSO快速收敛,但又不会陷入局部最优的目的。在实际操作的时候,粒子群可以依靠这种关系来实现对ω值的调整,使得惯性权重始终在一个范围内变化,更好地寻找全局最优解。即当粒子密度 ρ值大的时候,说明多数粒子靠近最优解,ρt2值随之增大,由式(4)可知,ω值在逐渐减小,再结合式(1)就可以得到更精确的解。反之,当粒子密度ρ值变小,ω值在逐渐增大,从而进一步避免了早熟收敛情况的发生。这样有效地调节v值的方式,让式(4)达到了一种自适应的状态,对于提高整个PSO算法的全局寻优能力有了很大的帮助。
3 基于自适应PSO的K-m eans算法
K-means算法的优点就在于它的简单,所以在处理大量数据集的时候就意味着它要比其他的聚类算法执行的更快更有效。但是K-means算法也由于其对初始聚类中心点选择的敏感性的问题,会造成聚类结果随着输入初始值的不同而波动,影响聚类的准确性。针对上述PSO算法和K-means算法的不足,本文设计了基于自适应PSO的K-means算法,其流程图如图1所示。
该算法具体子步骤描述如下:
输入:待聚类数据集N,聚类数目k,粒子群的种群规模m,最大迭代次数IterMax;
输出:聚类数据集的聚类中心不再变化的k个聚类划分。
Step 1:初始化PSO;
1)从数据集N中随机选择k个中心点,将其作为粒子位置xi的初始值;
2)初始化粒子速度vi、个体最优位置 pBesti以及对应的个体极值f(pBesti)、群体最优位置gBesti及其对应的全局极值f(gBesti);
3)Repeat m次;
Step 2:执行PSO;
1)按照适应度函数求得每个粒子的适应度值f(xi);
2)对于每个粒子,如果粒子的适应度值f(xi)小于个体极值f(pBesti),则更新粒子的个体极值f(pBesti)以及个体最优位置pBesti;
3)如果所有粒子的个体极值f(pBesti)的最小值f(pBestimin)小于粒子群的全局极值f(gBesti),则更新粒子群的全局极值f(pBesti)以及群体最优位置gBesti;
4)根据式(4)动态调整惯性权重,并根据式(1)和式(2)分别进行更新每个粒子的速度和位置;
5)Until到达最大迭代次数IterMax;
Step 3:将Step2中得到的k个初始聚类中心作为K-means算法的初始值;
Step 4:将数据集中的点指派到距离最近的质点,更新每个簇的质心;
Step 5:重复Step4直到质心不在发生变化,算法结束。
通过对PSO惯性权重ω的自适应处理,有效地缓解了标准PSO算法中存在的早熟收敛及局部寻优能力较差的问题,提升了PSO算法全局寻优的能力,并将两种算法的优势进行互补以达到更好的聚类效果。
4 电子病历聚类分析应用
随着信息技术在各领域的广泛应用,医院也纷纷采取了电子病历的方式管理医疗数据,与传统的纸质病历相比,电子病历更以规范、方便、高效著称[11]。随着电子病历数据持续的海量增长,基于电子病历数据的聚类应用也应运而生。然而电子病历数据聚类时很难达到预期效果,一方面,是由于其数据的海量性和主观性,另一方面,更是异构性和数字表征不明显的特性所致,所以传统的聚类方法很难处理这类结构复杂的医学数据[12~15]。
为了进一步验证本文提出的基于自适应PSO的改进K-means算法在实际数据应用的效率,本文开展了电子病历数据聚类分析实验。实验的环境:操作系统 W indows 7,处理器 Intel(R)Core(TM)i7-6567U CPU@3.30GHz,电脑内存 10GB,编程语言 Java,编程软件 eclipse Mars.2Release(4.5.2),电子病历系统相关页面如图2所示。

图2 电子病历系统页面
该算法中的相关参数设置:学习因子 c1和c2取2.0,和取[0,1]区间的随机数,ω∈[0.2,1.0],聚类数目k初始化为16,粒子群的种群规模m为20,最大迭代次数IterMax设为100次。实验数据是南通某医院电子病历中肝功能检查数据,共有203254条的数据样本,为了方便算法实施,经过数据预处理去掉了一些脏数据后得到以下6个属性,具体数据格式如表1所示。

表1 电子病历实验数据表
实验将标准K-means算法、PSO-based K-means算法和基于自适应PSO的K-means算法进行对比,实验中采用将每种算法分别执行30次,并将测试的结果数据进行平均值运算(小数点后面取两位)的方法来尽可能降低非算法和数据因素所导致的人为误差。选取的部分数据集进行算法聚类准确率和执行时间对比结果如表2和表3所示。

表2 电子病历肝病病症的聚类准确率比较(%)
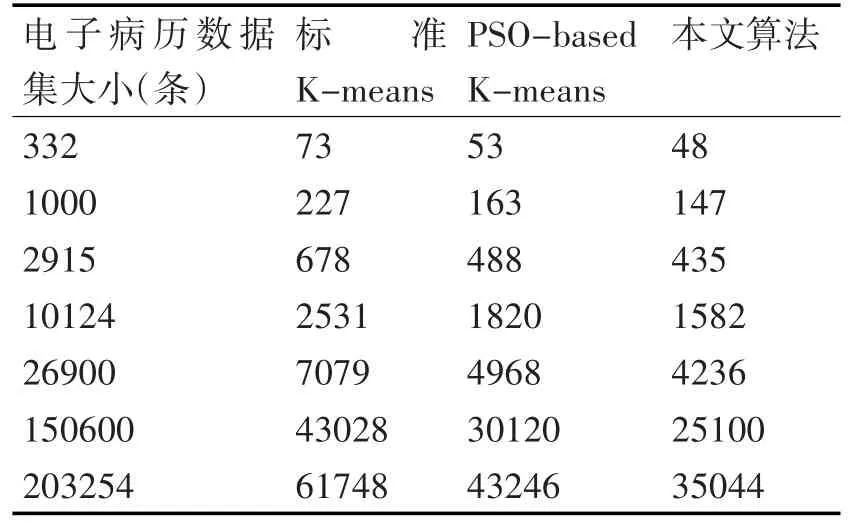
表3 电子病历肝病病症执行时间比较(ms)
由表2可以看出,针对4组不同规模的数据集,标准K-means算法和PSO-based K-means算法的聚类准确率都随着电子病历肝病数据量的增大逐渐下降,并且数据量越大下降幅度越大,原因就是K-means算法在初始聚类中心选取的敏感性问题上没有得到很好地处理,由于聚类中心初值的过于随机,影响了算法的执行准确率。而PSO-based K-means算法则是没有考虑到电子病历数据的特性,致使对肝病数据处理起来效率不高。本文算法在标准PSO算法的基础上,通过对原始公式中参数惯性权重v的调整,使其有效地减小了粒子的早熟收敛,从而充分利用了PSO的全局寻优能力,并针对电子病历数据的特点做了多模式数据源组合和数据变换的特殊处理,使其克服了电子病历数据的复杂特性,因此能筛选出更合理的初始聚类中心。由表3和图3可以看出,在数据量不大的时候,三种算法在处理数据的速度上差距不大,但是当数据量达到上万条时,本文算法表现出了更优越的处理能力,直观地反映在了处理数据消耗的时间上。

图3 电子病历肝病病症聚类分析速率比较图
5 结语
传统的K-means聚类结果不稳定主要是算法初始聚类中心的随机选择所致,聚类结果随着初始聚类中心的变化而变化,本文提出的基于自适应PSO的K-means算法,通过调整PSO的惯性权重v以求达到自适应,使得PSO充分的发挥了全局最优的特性,通过其优化生成K-means的初始聚类中心,从而避免了聚类结果陷入局部最优,最终训练出可靠健壮的模型。本文算法应用于电子病历数据的聚类分析,结果表明本文提出的基于自适应PSO的K-means算法在电子病历数据聚类分析上的聚类准确率和效率明显高于标准K-means算法和PSO-based K-means算法,这将有助于改善电子病历数据的聚类质量,提高聚类算法在大数据医疗方面的挖掘效率。
传统的数据挖掘算法如决策树算法、神经网络算法以及关联分析算法在面对数据复杂多样的电子病历医疗数据时常常出现数据过拟合影响模型预测性能,训练数据特征缺失影响模型训练等一系列问题。在今后的研究工作中我们进一步将本文提出改进的基于自适应PSO的K-means算法应用到电子病历其他病症数据分析中,对不同病例开展分类和预测研究,进一步提高算法在处理医疗数据时的应用效率和范围。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
数学学习与研究(2020年16期)2020-12-28
语数外学习·高中版中旬(2020年5期)2020-09-10
语数外学习·高中版中旬(2020年10期)2020-09-10
作文评点报·低幼版(2020年25期)2020-07-23
中国社区医师(2016年8期)2016-12-20
福建中学数学(2016年4期)2016-10-19
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
