
高效的半监督多层次入侵检测算法
2019-09-04 10:14曹卫东许志香
计算机应用 2019年7期
曹卫东 许志香


摘 要:针对基于监督学习的入侵检测算法需要的大量有标签数据难以收集,无监督学习算法准确率不高,且对R2L及U2R两类攻击检测率低等问题,提出一种高效的半监督多层次入侵检测算法。首先,利用Kd-tree的索引结构,利用加权密度在高密度样本区选择K-means算法的初始聚类中心;然后,将聚类之后的数据分为三个类簇,将无标签类簇和混合类簇借助Tri-training采用加权投票规则扩充有标签数据集;最后,利用二叉树形结构设计层次化分类模型,在NSL-KDD数据集上进行了实验验证。结果表明半监督多层次入侵检测模型能够在利用少量有标签数据的情况下,对R2L及U2R的检测率分别达到49.38%、81.14%,有效提高R2L及U2R两类攻击的检测率,从而降低系统的漏报率。
关键词:入侵检测;Kd-tree;Tri-training;半监督;多层次
Abstract: An efficient semi-supervised multi-level intrusion detection algorithm was proposed to solve the problems existing in present intrusion detection algorithms such as difficulty of collecting a lot of tagged data for supervised learning-based algorithms, low accuracy of unsupervised learning-based algorithms and low detection rate on R2L (Remote to Local) and U2L (User to Root) of both types of algorithms. Firstly, according to Kd-tree (K-dimension tree) index structure, weighted density was used to select initial clustering centers of K-means algorithm in high-density sample region. Secondly, the data after clustering were divided into three clusters. Then, weighted voting rule was utilized to expand the labeled dataset by means of Tri-training from the unlabeled clusters and mixed clusters. Finally, a hierarchical classification model with binary tree structure was designed and experimental verification was performed on NSL-KDD dataset. The results show that the semi-supervised multi-level intrusion detection model can effectively improve detection rate of R2L and U2R attacks by using small amount of tagged data, the detection rates of R2L and U2R attacks reach 49.38% and 81.14% respectively, thus reducing the systems false negative rate.
Key words: intrusion detection; Kd-tree; Tri-training; semi-supervised; multi-level
0 引言
随着互联网技术的发展,计算机网络给我们带来巨大便利的同时也让人们面临一系列网络攻击事件,给个人、企业及国家带来巨大损失。入侵检测系统(Intrusion Detection System, IDS)自1978年Denning[1]提出至今一直备受关注,常用的检测技术分为误用和异常检测两类:误用检测假设所有网络攻击行为都具有一定的模式或特征,符合已知行为特征的活动就被称为入侵[2];异常检测是通过建立系统正常行为模式库,凡是不符合模式库中正常行为的活动就被称为入侵活动。误用检测仅能检测已知类型的攻击,而异常检测却又出现误报率与漏报率较高等问题。
近年来,机器学习与深度学习算法广泛应用于此领域,文献[3-6]利用深度学习中的深度信念网络、卷积神经网络等技術取得较高的检测率,但模型在训练过程中需要大量的有标签数据,忽略了有标签样本难获取的问题。文献[7-9]中提出采用无监督聚类算法识别网络中的异常行为,避免了标签数据难获取的问题,但检测效率与检测精度较低。文献[10-11]中提出采用半监督算法做入侵检测,取得一定成效;但模型训练时间长,误报率较高,尤其针对U2R(User to Root)和R2L(Remote to Local)两类攻击出现大量漏报情况,而这两种类型的攻击比拒绝服务(Denial of Service, DoS)和其他类型的攻击造成的破坏更严重。
针对上述问题,本文提出一种基于Kd-tree(K-dimension tree)选取初始聚类中心的半监督多层次入侵检测算法,首先根据少量有标签样本和大量无标签样本构建Kd-tree,K-means算法的初始聚类中心在Kd-tree中样本密度较高的区域选择[12],从而大幅度缩短K-means在聚类过程中所需时间,训练样本经过第一层聚类处理之后根据有无标签形成三类数据子集(全部为有标签,混合、全部为无标签);第二层,利用Tri-training方法[13]对混合和无标签数据子集作进一步处理,扩充有标签数据子集;第三层,将扩充后的有标签数据分层次划分,得到DoS、Probe、U2R、R2L、Normal每种类型的概率预测值作为第四层的输入;第四层综合利用所有类型概率预测值作出最终决策判断。经实验证明,此模型在利用少量有标签样本的情况下,大幅度提高了U2R及R2L的检测率,降低了系统的漏报率与误报率,且模型的训练时间相比其他半监督模型大幅度减少。
1 基于Kd-tree选取初始聚类中心
传统K-means算法随机选取K个样本点作为初始聚类中心,以所有样本到聚类中心各维度间距离的平方和作为目标函数,通过不断迭代使目标函数最小化,更新聚类中心,从而得到优化后的类簇;但这种方法得到的最终结果跟初始的聚类中心密切相关,且模型计算量在高纬度大样本时难以收敛,导致模型的训练时间很长。针对此问题,提出利用Kd-tree结构,在高密度样本区选择K-means的初始聚类中心,过滤掉异常样本点,因此又称K-means过滤算法。
1.1 Kd-tree概念
Kd-tree本质上是二叉查找树,是一种高维索引树形数据结构,实现对K维数据空间中数据对象存储并加快检索的功能[14]。Kd-tree中每个节点主要包含的数据结构如表1所示。
文献[15]首次提出基于Kd-tree选取K-means初始聚类中心,在高密度样本区选择样本作为初始种子聚类中心,该算法仅考虑具有高密度值的叶子节点,低密度值叶子节点直接舍弃,由此导致最终输出的候选聚类中心集聚在高密度区,类簇间很难区分。
文献[16]中提到K-means过滤算法在每一次迭代过程中访问节点所需时间复杂度为O(2dk log n+dn/ρ2),其中:d表示样本维度,k代表聚类中心数,n代表叶子节点数即样本总数, ρ代表类簇之间的分离度,这就表明K-means过滤算法迭代过程中所需时间与类簇之间的分离程度成反比,因此文献[15]中的算法并不能有效地缩短模型的训练时间。
1.2 基于Kd-tree的加权密度估计选取K-means初始聚类中心
针对上述问题,提出基于Kd-tree加权密度估计选择K-means初始聚类中心。首先根据已有数据集构建Kd-tree,则第i个叶子节点的体积表示为:
其中:ximax代表节点i在第j维上投影坐标最大值,ximin代表节点i在第j维上投影坐标最小值。另Ni表示第i个叶子节点内包含的样本点数,第i个叶子节点的密度估计δi=Ni/Vi。叶节点加权密度估计值为:
模型训练开始时,选密度权重最大的叶子节点的均值作为第一个种子中心[17],剩下的种子通过计算叶节点的距离估计来确定,叶节点距离估计值是与其相距最近的聚类中心的距离,并在每计算完一个新的聚类中心后更新,假设t个聚类中心已确定,在第t+1轮迭代时,第i个叶子的距离估计值为:
2 半监督多层次入侵检测模型
半监督分类方法是考虑到当有标签样本不足时,如何利用大量无标签样本辅助分类器训练。当前网络环境中,充斥大量无标签样数据,人工加标签费时费力,鉴于此提出采用半监督方法作入侵检测。
Tri-training算法利用Dlabeled训练三个不同的分类器,假设分别为H1,H2,H3,x是Dunlabeled內任意一个样本点,若H2(x)与H3(x)得到的结果相同,则可将x标记为H2(x),并将其并入H1的训练集。同理,相同的方法用于扩充H2和H3的训练集,三个训练器重新训练,不断迭代直至三个训练器都没有变化,由此实现有标签数据集的扩充。
2.2 Tri-training扩充有标签数据集
通过改进K-means对少量有标签样本和大量无标签数据集聚类,聚类之后的数据可分为三个类簇[18]:有标签、混合、无标签三种。每个类簇的类分布函数计算公式为:
则称这个类簇为原子类簇(atomic)[18],否则称之为非原子类簇(non-atomic),原子类簇保留其标签。针对全部为无标签样本的类簇,根据近邻规则找到距离其最近的有标签类簇合并,形成新的混合类簇。
混合类簇则通过Tri-training方法进行训练,通过不断迭代给无标签样本打标签,最终形成一个全部有标签的样本数据集。文献[13]中打标签时采用多数投票规则,这一规则在样本类别数大于2时,准确率会受到影响,因此提出一种加权的投票规则进行类别标记,三个分类器的权值分别由在初始有标签样本数据集上的分类准确率Ai(Dlabeled)确定,权值计算公式如下:
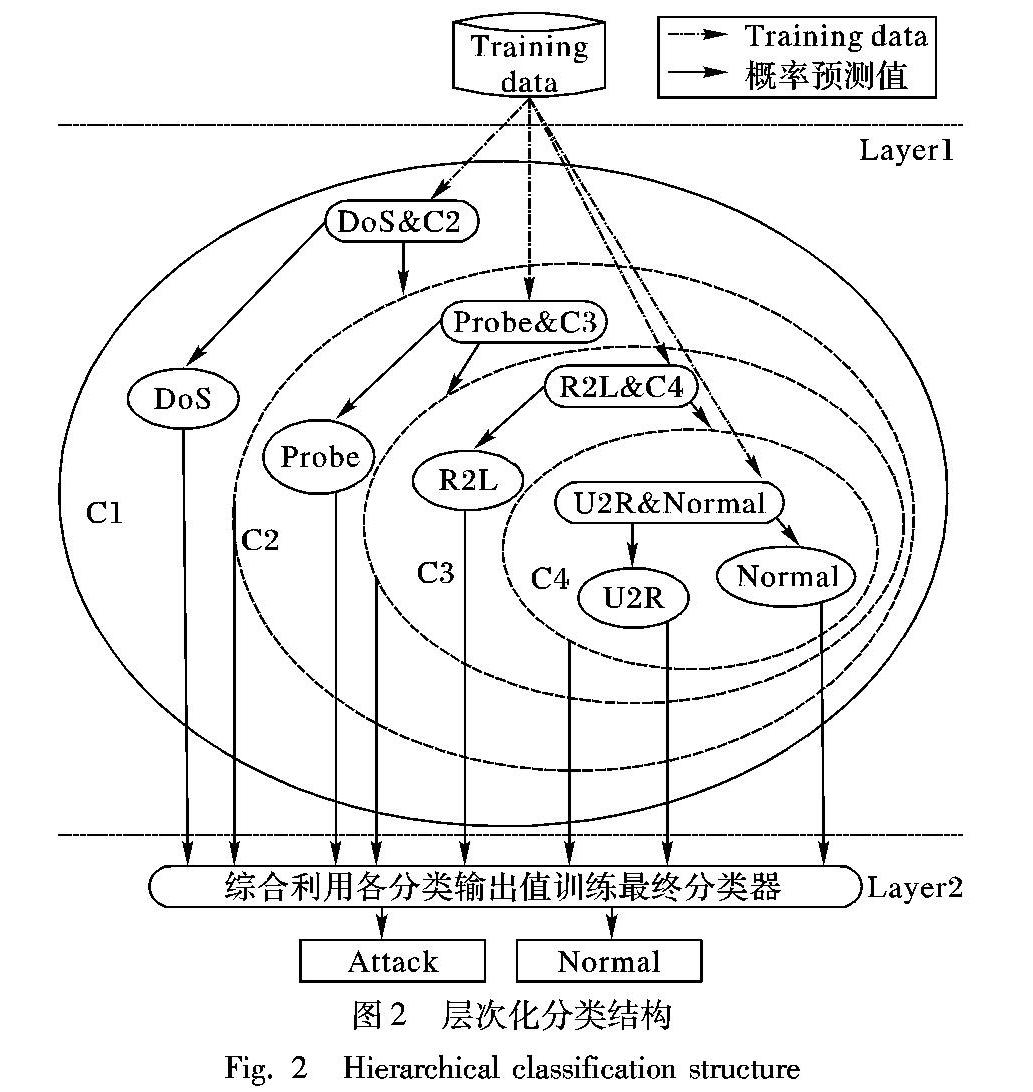
2.3 层次化分类设计
现有的入侵检测算法大多针对总样本检测准确率,忽略了U2R、R2L两种类型的检测,导致系统误报率和漏报率很高。原因是这两类攻击在原始数据集中数据量很小,且KDD99中有大量基于连接的统计数据淹没了这两类数据的特点,由此导致针对这两类攻击的检测率很低。
针对上述问题,提出一种层次化分类设计,第一层设计为具有二叉树形式的树形分类器,树形分类器分四级,为提高分类效率及准确率,每一级都设置为二分类器[19],每一个二分类器输出样本所属类别的概率:二分类器的输出值为每一个测试样本所属类别的概率预测值:此句不通顺
level1 原始数据集中DoS攻击类型最多,因此将扩充后的有标签数据集分在此分为DoS和C2两类因此将扩充后的有标签数据集在本层分为DOS和C2两类此句不通顺;
第二层同样采用二分类法,以第一层所有样本输出概率值probab()作为输入,为增强最终分类器的泛化能力,首先将各级分类器的输出值按照算法1[19]作进一步处理,层次化分类结构如图2所示。
算法1具体可表述为,第一层的二分类器处理最初训练数据集,若DoS的概率预测值大于C2,则将C2的概率预测值置为0,并将C2中的数据作为第二层分类器的输入数据;第二层的二分类器处理C2,若Probe的概率预测值大于C3,则将C3的概率预测值置为0,并将C3中的数据作为第三层分类器的输入数据,第三层及第四层同理。伪代码如下:
3 实验与结果分析
3.1 实验数据
入侵检测数据集采用NSL-KDD[20],它是对原KDDcup99数据集的改进,去掉了原数据集中大量重复记录。数据集有41个属性,其中有3个符号性变量,38个数值型变量,类标签分为5类:DoS、Probe、U2R、R2L、Normal。NSL-KDD的训练集和测试集各攻击类型详细信息如表2所示,表3则提供每种类型在训练集和测试集中的分布信息。
由表2及表3可知,U2R和R2L两种类型在测试集中出现一些新的攻击子类型,但是由于总数据量远小于其他攻击类型数据量,因此这两种攻击类型的特有属性常被“覆盖”,新出现的攻击类型容易被系统误判为正常数据,由此导致系统的漏报率很高。
由于DoS和Normal两种类型的数据量远大于其他类型,因此为了平衡各数据间的分布,将Training-dataset中Probe、R2L、U2R数据全部保留加入到训练集中,随机从DoS和Normal中选择若干数据构成训练集,将Test-dataset的全部样本作为测试集。本实验采用的训练集样本分布如表4所示。
3.2 数据预处理
NSL-KDD中属性“protocal_type”“service”“flag”为符号性变量,其他属性多为统计性数据,各个维度之间差异度较大难以聚类,因此在实验前要先对数据进行预处理以方便数据聚类。
1)数值化。
预处理的第一步就是对原训练集进行数值化处理。采用统计信息,将各属性中不同值出现的频次替代原属性值,这样做可以避免替换时同一属性不同值之间距离不均衡,从而导致错误聚类的问题[7]。
2)归一化。
NSL-KDD中23~31维属性是基于时间的统计属性,32~41维属性是基于连接的统计属性,这就导致各维数据间差异较大,因此要将数值化处理后的数据作归一化处理:
其中:x′代表归一化处理之后的数据,Mmax代表某一维中最大的数,Mmin代表某一维中最小的数。
3.3 实验分析
本实验在Intel CPU 1.70GHz、4GB内存、64b硬件环境和Windows 7操作系统,使用Python3.5作为编码工具。實验所用的评价指标为准确率(ACcuracy rate, AC)、检测率(Detection Rate, DR)、误报率(False Alarm Rate, FAR),定义如下:
其中:TP(True Positive)代表正确识别的Normal类数量,TN(True Negative)代表正确识别的攻击类数量,FP(False Positive)代表误判为Normal类的数据量,FN(False Negative)误判为攻击类型的数据量。
在实验1中为验证利用Kd-tree的加权密度估计对K-means聚类效率的影响,将传统K-means算法及文献[15]中基于Kd-tree的密度选择初始聚类中心算法作比较,比较模型运行时间及准确率,训练数据集为Training-dataset。实验结果如表5所示。
由表5可以得出,本文所提算法检测准确率比传统K-means算法提高1.86从表5中,未看出是2个百分点,而是1.86个百分点,此处是否应该改为这个数值个百分点,但模型的运行时间却大幅度缩短,这是由于传统K-means在邻近最终的聚类中心时,算法很难收敛,导致模型的训练时间过长。文献[15]的算法准确率虽与本文算法近似,但运行时间却较长,而网络中的入侵行为需被及时检测并给予响应。AN-SVM(请补充AN-SVM的英文全称)[6]采用的基于检测率虽高于本文算法,不通顺,且表5中没有这个算法?请作者调整因此综合考虑,本文算法更具实用性。
实验2中,为验证Tri-training中提出的加权投票规则对无标签样本打标签准确率的有效性,将传统Tri-training算法与本文算法对各类型数据检测率作比较,实验结果如图3所示。
由图4可知,随着有标签数据量的增加,各算法的准确率都有提升,本文所提算法相比其他模型在有标签数据量相同时,检测准确率较高,特别是当有标签数据量占据训练集一半时,检测准确率已达到94.07%,说明半监督思想能够应用于入侵检测模型中,由此可以避免人工打标签。
为进一步验证层次化分类模型对U2R和R2L两类攻击的检测率,特与其他算法作对比,有标签数据集占训练集的70%,实验结果如图5所示。
由图5得知,本文提出的半监督多层次分类模型与其他半监督算法总体检测率与准确率相差不大,但R2L及U2R两种类型的检测率却有较大提升,对R2L及U2R的检测率分别达到41.38%49.38%与81.14%,能够有效检测出这两种类型攻击,降低系统的漏报率。
为进一步验证本文所提半监督算法的有效性,与近年来基于半监督的入侵检测算法作对比,其中有标签数据集占训练样本的50%,对比实验结果如表6所示。
由表6可知,本文所提算法对所有样本点的检测率优于其他半监督算法,误报率确虽高于文献[22]中所提的算法,但针对入侵检测系统来说,更加关注系统对异常数据的检测率,因为漏检一条数据都可能对系统造成致命影响,因此本文所提算法比其他算法更具实用性。
4 结语
本文针对现有入侵检测算法多针对总体的检测率和准确率,而忽略R2L、U2R两种攻击类型检测率,导致系统误报率较高;且现实网络流量中多为无标签数据,采用有标签数据做训练集需要耗费大量人力物力的现状,提出一种基于Kd-tree选择初始聚类中心的半监督分层次入侵检测模型,首先利用Kd-tree结构,提出一种加权密度方法加快K-means的聚类过程;其次,利用改进的Tri-training方法扩充有标签数据集,充分利用大量无标签数据辅助模型进行学习作出判断;最后,利用分层次模型,采用二叉树形结构对每种类型作出判断,进而提高R2L及U2R两种攻击类型的检测率。
参考文献 (References)
[1] DENNING D E. An intrusion-detection model[J]. IEEE Transactions on Software Engineering, 2006, SE-13(2): 222-232.
[2] 孔令智.基于網络异常的入侵检测算法研究[D].北京:北京交通大学,2017:15-16.(KONG L Z. Research on intrusion detection algorithm based on network anomaly[D]. BeiJing: Beijing Jiaotong University, 2017: 15-16.)
[3] 沈学利,覃淑娟.基于SMOTE和深度信念网络的异常检测[J].计算机应用,2018,38(7):1941-1945.(SHEN X L, QIN S J. Anomaly detection based on synthetic minority oversampling technique and deep belief network[J]. Journal of Computer Applications, 2018, 38(7): 1941-1945.)
[4] YADAV S, SUBRAMANIAN S. Detection of application layer DDoS attack by feature learning using stacked autoencoder [C]// ICCTICT 2016: Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies. Piscataway, NJ: IEEE, 2016: 361-366.
[5] 方圆,李明,王萍,等.基于混合卷积神经网络和循环神经网络的入侵检测模型[J].计算机应用,2018,38(10):2903-2907.(FANG Y, LI M, WANG P, et al. Intrusion detection model based on hybrid convolutional neural network and recurrent neural network[J]. Journal of Computer Applications, 2018, 38(10): 2903-2907.)
[6] 高妮,高岭,贺毅岳,等.基于自编码网络特征降维的轻量级入侵检测模型[J].电子学报,2017,45(3):730-739.(GAO N, GAO L, HE Y Y, et al. A lightweight intrusion detection model based on autoencoder network with feature reduction[J]. Acta Electronica Sinica, 2017, 45(3): 730-739.)
[7] 贾凡,严妍,张家琪.基于K-means聚类特征消减的网络异常检测[J].清华大学学报(自然科学版),2018,58(2):137-142.(JIA F, YAN Y, ZHANG J Q. K-means based feature reduction for network anomaly detection[J]. Journal of Tsinghua University (Natural Science Edition), 2018, 58(2): 137-142.)
[8] PENG K, LEUNG V C M, HUANG Q. Clustering approach based on mini batch Kmeans for intrusion detection system over big data[J]. IEEE Access, 2018, 6(99): 11897-11906.
[9] PATHAK V, ANANTHANARAYANA V S. A novel multi-threaded K-means clustering approach for intrusion detection[C]// Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering. Piscataway, NJ: IEEE, 2012: 757-760.
[10] FITRIANI S, MANDALA S, MURTI M A. Review of semi-supervised method for intrusion detection system[C]// Proceedings of the 2016 Asia Pacific Conference on Multimedia and Broadcasting. Piscataway, NJ: IEEE, 2016: 36-41.
[11] HAWELIYA J, NIGAM B. Network intrusion detection using semi supervised support vector machine[J]. International Journal of Computer Applications, 2014, 85(9): 27-31.
[12] KUMAR K M, REDDY A R M. A fast DBSCAN clustering algorithm by accelerating neighbor searching using Groups method[J]. Pattern Recognition, 2016, 58: 39-48.
[13] ZHOU Z H, LI M. Tri-training: exploiting unlabeled data using three classifiers[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(11): 1529-1541.
[14] 劉开云.基于KD-Tree的KNN沙尘孤立点监测算法的研究与应用[D].开封:河南大学,2018:22-24.(LIU K Y. Research and application of KNN sand-dust isolated point monitoring algorithm based on KD-Tree[D]. Kaifeng: Henan University, 2018: 22-24.)
[15] REDMOND S J, HENEGHAN C. A method for initialising the K-means clustering algorithm using kd-trees [J]. Pattern Recognition Letters, 2007, 28(8): 965-973.
[16] KANUNGO T, MOUNT D M, NETANYAHU N S, et al. The analysis of a simple K-means clustering algorithm[C]// Proceedings of the Sixteenth Annual Symposium on Computational Geometry. New York: ACM, 2000: 100-109.
[17] KUMAR K M, REDDY A R M. An efficient K-means clustering filtering algorithm using density based initial cluster centers[J]. Information Sciences, 2017, 418/419: 286-301.
[18] AL-JARRAH O Y, AL-HAMMDI Y, YOO P D, et al. Semi-supervised multi-layered clustering model for intrusion detection[J]. Digital Communications and Networks, 2018, 4(4): 277-286.
[19] AHMIM A, DERDOUR M, FERRAG M A. An intrusion detection system based on combining probability predictions of a tree of classifiers[J]. International Journal of Communication Systems, 2018, 31(9): e3457.
[20] TAVALLAEE M, BAGHERI E, LU W, et al. A detailed analysis of the KDD CUP 99 data set[C]// Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications. Piscataway, NJ: IEEE, 2009: 1-6.
[21] ZHANG X F, ZHU P D, TIAN J W, et al. An effective semi-supervised model for intrusion detection using feature selection based LapSVM [C]// CITS 2017: Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems. Piscataway, NJ: IEEE, 2017: 283-286.
[22] ASHFAQ R A R, WANG X Z, HUANG J Z, et al. Fuzziness based semi-supervised learning approach for intrusion detection system[J]. Information Sciences, 2017, 378: 484-497.
[23] CATALTEPE Z, EKMEKI U, CATALTEPE T, et al. Online feature selected semi-supervised decision trees for network intrusion detection[C]// NOMS 2016: Proceedings of the 2016 IEEE/IFIP Network Operations and Management Symposium. Piscataway, NJ: IEEE, 2016: 1085-1088.
猜你喜欢
现代电子技术(2016年24期)2017-01-19
现代商贸工业(2016年28期)2016-12-27
电子技术与软件工程(2016年22期)2016-12-26
亚太教育(2016年33期)2016-12-19
科教导刊(2016年26期)2016-11-15
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年6期)2016-07-12
考试周刊(2016年26期)2016-05-26
科技视界(2016年9期)2016-04-26
