
Spark环境下基于网格索引的轨迹k近邻查询方法
2019-09-05 10:32王瑞迪阮文亮
重庆邮电大学学报(自然科学版) 2019年4期
夏 英,王瑞迪,张 旭,阮文亮
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
近年来,随着移动互联网、云计算、大数据等技术的发展,交通、环境、社交网络等领域都汇聚了海量的轨迹数据。轨迹数据具有典型的时空特性,对轨迹数据进行有效管理和分析,有利于发现用户的移动模式,并在此基础上提供更加丰富的空间信息服务。移动对象轨迹的k近邻(k nearest neighbor trajectories,kNNT)查询是一种重要的空间信息服务,即由用户给定查询轨迹T,系统在轨迹集合S中检索与其最相邻的k条轨迹,并按照相邻程度排序返回给用户。轨迹k近邻查询广泛地应用于轨迹数据库中的分类、路线推荐以及智能交通管理[1]。
针对kNNT查询问题已经进行了很多相关的研究。S. Qi等[2]设计了一种混合近邻算法,基于空间范围的搜索方式,解决了独立运行多个近邻搜索带来的I/O成本和维持优先队列的CPU成本过高等问题。A. Akdogan等[3]和戴健等[4]在分布式环境中使用了基于Voronoi图的方法来对空间数据分区,在迭代的MapReduce任务中解决空间对象的kNN[3],kNN Join[4]查询问题。文献[5]提出了基于MapReduce框架下R-树索引的并行创建方法,首次实现了R-树索引的并行化。文献[6]通过线性扫描的方式划分数据,并提出了MapReduce框架下的k近邻查询算法,该算法在Map阶段过滤了大量与查询无关的数据以减少运算,然后在Reduce阶段生成候选集。对于时空轨迹数据,文献[7]充分利用了计算机集群的并行能力,提出了一种基于MapReduce的轨迹数据查询处理框架,解决了轨迹数据的范围查询问题。季长青等[8]提出了基于网格索引的kNN查询方法,利用了并行轮圈遍历查询算法(parallel circle trip,PCT)来对网格进行过滤,然后在验证阶段逐一对候选集进行验证。另外,A. Eldawy等[9]给出了一种新的空间大数据处理平台SpatialHadoop,并实现了基于其的k近邻查询(kNN query)、范围查询(range query)以及空间邻接查询(spatial join query)。但是,在面对大规模的轨迹数据时,由于资源的限制,传统集中式环境下的查询方法难以在独立的计算机上处理这些数据。此外,当前一些分布式环境下的kNN查询方法是针对k最近邻点的,忽略了轨迹的空间连续性和时间属性[10]。一些考虑了轨迹连续特征的方法,又仅支持一些普通轨迹查询,而不是基于时空距离的轨迹kNN查询。因此,对分布式环境下的移动轨迹k近邻查询的研究还有很大的提升空间。
为了提高轨迹k近邻查询方法的性能,有必要应用并行计算技术,设计分布式环境下的高效kNNT查询方法。Spark是一个实现了MapReduce编程范式的基于内存计算的分布式计算框架,应用了DAG计算模型,有效减少了Shuffle的次数,具有良好的容错性和伸缩性。本文将Spark技术应用于轨迹k近邻查询,考虑轨迹数据的空间和时间特性,提出针对轨迹数据的分布式网格索引及轨迹还原表的辅助结构,并基于此索引实现分布式的kNNT查询方法。
1 相关定义
结合移动对象的运动行为,对移动对象轨迹的相关概念做如下定义。
定义1(移动轨迹)轨迹数据是带有时间戳并按时间排序的点序列。轨迹Tr可以表示为Tr={p1,p2,…,pn},其中,pj是轨迹Tr中的第j个点。每个点可以表示为(x,y,t),其中,t是时间戳,(x,y)是移动对象在t时刻的坐标。
定义2(最短匹配距离)轨迹Tr={p1,p2,…,pn}和点q最短距离为dist(pj,q),且∀pk≠pj,dist(pj,q)≤dist(pk,q)。其中,
最近对距离经常用于衡量2条轨迹的距离[11],但是这种计算方式忽略了轨迹中其他点的贡献。另外,关于轨迹距离的测量还有其他研究,但侧重于轨迹形状[12]。然而本文方法更多考虑空间距离,定义3是轨迹距离测量方法。
定义3(轨迹距离)给定任意一条轨迹Tr={p1,p2,…,pn}和查询轨迹t={q1,q2,…,qm}。Tr和t中任一点q的距离是其最短匹配对
(1)
定义4(轨迹k近邻查询)给定轨迹数据集S和查询轨迹t,kNNT查询就是从S中检索出k条轨迹的集合K,其中,K={Tr1,Tr2,…,Trk},∀Tri∈K和∀Trj∈D-K,dist(Tri,t)≤dist(Trj,t)。
2 轨迹k近邻查询处理框架设计
kNNT查询处理框架如图1所示。整个轨迹k近邻查询的处理框架由存储模块、网格索引模块、查询模块组成。首先,预处理阶段会过滤轨迹数据中重复和无效的数据记录,并导入分布式文件系统HDFS以保证存储的可靠性;其次,大量的轨迹数据使得kNNT查询时的计算成本过高,因而,需要构建索引来加速查询过程。网格单元和Voronoi图都是基于空间感知的划分策略,可以将轨迹数据组织到不同区域,从而减少候选轨迹集的数量,降低计算成本。本文在Spark环境下针对移动轨迹数据采用网格索引。网格索引具有扁平化和易于并行化的特性,可以使用MapReduce模型中的分治策略来构建多个子网索引,大大提高了并行效率。此外,网格索引更适合处理动态数据集,而Voronoi图索引在处理动态数据集时需要对局部索引重建,效率较低。因此,使用网格划分策略将n维空间划分为多个网格单元。最后,网格索引构建完成后,借助于轨迹还原表的辅助结构,可以快速地获得kNNT的查询结果。

图1 kNNT查询处理框架Fig.1 Framework of kNNT query processing
3 分布式网格索引构建
不失一般性,可以假设空间是一个矩形。给定二维空间轨迹数据集S,其中,任意轨迹上的一点p坐标为(p.x,p.y)。对于点p,函数index(p)返回包含点p的网格,表示为
c[p.x/δ,p.y/δ]=index(p)
(2)
(2)式中:δ是网格边长;p.x是横坐标;p.y是纵坐标。
图2是轨迹的切分和映射过程。在使用边长为δ的网格将空间区域划分为多个规则网格单元后,所有轨迹数据都被分配到至少一个网格中。如果轨迹线段完全被一个网格覆盖,那么这条轨迹就完全属于这个网格。另外,如果轨迹跨越了空间网格边界,轨迹会在边界处被切分,再映射到2个相邻网格中。网格索引使用键值对进行存储,同一网格中的轨迹段存储在相同的网格键值中,如图2中的网格g<1,0>包含了{s(B34,B34′),s(A12,A12′)}2条轨迹数据段。

图2 轨迹切分和映射Fig.2 Trajectory split and mapping


图3 网格索引构建Fig.3 Process of building grid index
算法1网格构建算法Grid。
输入:轨迹数据;
输出:网格索引文件。
步骤如下。
1) procedure MAP(k1,v1)
2)trSegMap←SpatialPartition(v1); //切分轨迹到网格中
3) for eachtrSeg∈trSegMapdo
4)k2 ←trSeg.gridIdPair,v2 ←trSeg
5)cache(k2,v2)
6) end for
7) end procedure
8) procedure REDUCE(k2,v2)
9) gridRDD.partitionBy(gridPartitioner) //对GridId分区且排序
10) OUTPUT(k2,v2) //输出网格索引文件
11) end procedure
4 轨迹k近邻查询方法
4.1 轨迹还原表
为了在执行轨迹k近邻查询时能够检索和重建完整轨迹,需要在切分轨迹到网格的同时,保留子轨迹段间的联系。因此,提出了轨迹还原表(trajectory rebuild table,TRT)的辅助结构。它是一个倒排索引的数据结构,类似表格构造,使用键值对来组织管理数据。键值对中的键是轨迹Id,而值是一个包含了轨迹跨越的所有网格的Id列表。
在轨迹k近邻查询方法的预处理阶段,本文在Spark中将TRT加载到内存,以广播变量的形式来分发数据,避免了任务间变量的重复复制,从而减少了网络通信的开销。所有的Worker节点在准备检索候选轨迹时可以读取TRT来查找和重建整条完整轨迹。其具体的MapReduce处理过程如下:在Map阶段,每个节点将一条轨迹切分并映射到由轨迹标识符和该轨迹经过的网格组成的键值对中
4.2 基于Spark的轨迹k近邻查询方法
这部分主要介绍Spark环境下kNNT查询的处理过程。轮圈算法CircularTrip[13]通常是访问周围网格的有效方法,该算法以査询点为圆心,使用多次画圈的方式来访问周围的邻近网格及网格内包含的对象,然后,计算距离并排序得到查询点的邻近对象。但CircularTrip算法并不支持分布式和轨迹查询。因此,在此基础上提出了Spark环境下的基于网格索引的轨迹k近邻查询方法,并记为kNNT-Grid。
在进行轨迹k近邻搜索候选轨迹之前,本文在预处理阶段中将输入的查询轨迹定位到网格中,然后,确定这些网格的中心。围绕该中心,默认执行一次CircleSearch()算法来初始化候选网格集合candidateGridList。同时,将轨迹还原表TRT从HDFS缓存到Executer的内存当中,避免了每个Task节点的重复读取,减少了磁盘I/O。
在Map阶段,Task节点会在每个分区中加载网格索引文件,遍历其中的数据行,找到不重复的候选轨迹id集合,然后,继续执行CircleSearch()算法来查找更多的候选轨迹,直到候选集合大小大于要查询的k值。然后,搜索轨迹还原表rebuildTable来获取整个轨迹。在Reduce阶段,使用了TreeMap来存储轨迹段并排序还原为完整轨迹,以便可以计算完整候选轨迹与输入轨迹之间的距离。最后,将k个最近邻的轨迹进行排序,并保存到HDFS中。算法2是kNNT-Grid的伪码。
算法2轨迹k近邻查询算法kNNT-Grid。
输入:查询轨迹inputTr={p1,p2, … ,pn},网格索引文件,k值;
输出:k近邻轨迹。
步骤如下。
1) procedure MAP-INIT
2) inputGridSet←Φ; candidateGridList←Φ;
3) inputGridSet=locTraj2Grid(inputTr)
4)findCenter(inputGridSet,centerX,centerY) //找到中心网格
5) candidateGridList ++=CircularSearch(1) //默认轮圈一次
6)readRebuildTableFromHDFS(context)
7) end procedure
8) procedure MAP
9) candiNum=0;lineList=null;candiIdSet←Φ
10) // 读取每一个分区的所有轨迹数据
11) wholeCandidateSegRDD = sc.textFile.
12) (INPUT_PATH).mapPartitions(
13) lineList = it.toList.map(_._1)
14) //遍历找出不重复候选轨迹Id集合
15) candiIdSet=traverse(lineList,candiGridList)
16) while candiNum < K_NUM do
17) candiIdSet ++=traverse(lineList
18) ,CircularSearch(++cycle_num))
19) end while
20)findRebuildEntireTraj(candiIdSet,lineList))
21) end procedure
22) procedure REDUCE
23) tempMap←Φ
24) for each seg ∈ v2s do
25) tempMap.put(trId, seg) // 使用
TreeMap 还原完整轨迹
26) end for
27)calcuTraj2TrajDist(tempMap,inputTr)
28) end procedure
kNNT-Grid算法主要通过检索网格索引并结合轨迹还原表来获得最终的轨迹k近邻查询结果,而网格索引文件在集群中是被切分为多个分区存放在HDFS上的。假设一个分区中的轨迹数量为n,候选网格集合大小为m,候选轨迹片段数为k。Map任务主要用于查找候选轨迹集并还原完整轨迹片段,算法2中15-20行对分区中轨迹和候选网格的迭代遍历,其时间复杂度为O(mn)。同时,Reduce任务主要用于合并Map任务输出的候选轨迹片段,利用TreeMap存储并排序还原为完整候选轨迹,时间复杂度为O(klogk)。因而,kNNT-Grid算法整体的时间复杂度为O(mn)+O(klogk)。
5 实验分析
5.1 实验方案
针对提出的分布式网格索引以及基于此索引的轨迹k近邻查询方法,与同类方法在索引构建性能,查询性能和可扩展性等3个方面进行比较。
本文实验是在一个包含8个节点的Spark集群上进行,1个节点作为Master节点,另外7个节点作为Worker节点。所提及的算法均采用Scala语言实现。具体的实验环境如表1所示。

表1 实验环境
实验采用北京市出租车数据集和成都市出租车数据集。北京市出租车数据集为Microsoft GeoLife(DS1)[13]和DataTang(DS2)[14],分别是2G和30G。DS1总行程为1 251 654 km,时间为48 203 h。DS2是由12 000辆出租车在2012年10月至12月期间收集,采集间隔为50~55 s,大约有450万个轨迹。而成都市出租车数据集DataCastel(DS3)[15]包含了成都市1.4万辆出租车在2014年8月3日到30日中的行驶轨迹,超过14亿个GPS记录。它们都是出租车轨迹数据,具有相似的属性,如轨迹号、纬度、经度、时间戳、速度等。本文忽略了与实验无关的数据项如出租车载客状态。
5.2 实验结果分析
1)为了分析索引构建性能,本文选取Voronoi-Based[3]算法(VD)和MRTree[5]算法进行比较。VD是分布式环境下Voronoi图索引并行创建的实现,其在Map函数中读入Split分片后将数据按照x轴坐标递增排序,构建出局部Voronoi子图,然后,在Reduce函数中合并成完整Voronoi图;MRTree算法是基于分布式环境下R树索引的构建算法,其在Partition函数中将空间数据集切分为n个分片,然后,在每个分片上同时创建各自的R-树子索引,最后,将n个子树索引合并为完整的R-树索引。2种算法都是分布式索引的典型实现。在DS1数据集中随机选择50万个数据对象,取Spark集群节点个数分别为2,4,6和8,统计并比较2种索引的创建时间。从图4中可以看出,本文的分布式网格索引的构建性能都优于VD和MRTree,这是由于网格索引扁平化的结构更适用于分布式计算,能够灵活地通过MapReduce分治策略构建子网索引。但是,Voronoi图索引的构建需要复杂的多边形计算和局部索引重建操作,耗时较长。而MRTree索引结构由于树形结构的分层特征,在建立中需要反复迭代导致效率较低。此外,索引构建时间的下降率并不是线性的,这主要是因为节点个数的增加,节点间网络通信代价随之增大。

图4 索引构建性能Fig.4 Performance of Building Index
2)为了分析查询算法性能,本文实现了kNNT-Base[6]算法,并将其作为基准方法和kNNT-Grid进行对比。kNNT-Base提供了MapReduce框架下进行空间查询的过滤和集成思路,在过滤阶段剔除了大量与查询无关数据对象来生成候选集,因而拥有较好的性能。选取相等大小的不同区域的数据集DS1和DS3,取网格宽度0.01,如图5所示。由于kNNT-Grid只搜索候选集的一部分,而不是整个数据集,所以kNNT-Grid的效率总是优于kNNT-Base。对于kNNT-Grid,当k很小时,CircleSearch()首次查找到的候选轨迹的数量总是大于k,因而不需要执行更多的CircleSearch(),所以时间开销接近。然而,随着k增加,候选轨迹的数量变得小于k,执行更多的CircleSearch()会花费更多的时间。但是对于kNNT-Base,查询时间总是缓慢增长。
3)为了分析网格宽度对查询性能的影响,从2个数据集中随机选择具有相同大小(2G)的子数据集,并取k为20。在预处理阶段对数据集的采样发现,数据的采集范围集中在北京市经度116.2°至116.55°和纬度39.6°至40.4°的主要城区内。通过对网格边长的较大差异化取值,使得网格在上述范围内分别能够稀疏性分布和稠密性分布,从而直观地展示出网格宽度对查询性能的影响。因而在实验中,δ的取值为0.1,0.01,0.001和0.000 5。实验结果如图6所示,当单元格宽度为0.1时,网格太稀疏以至于每个网格单元存储了过多的轨迹,使得CircleSearch()算法一次扫描的候选轨迹数量过多,因而时间开销最多。然而,网格越小,索引文件越多。比如选择0.000 5,则群集会因为初始化太多Split分片导致性能下降。从图6中可以看到,网格宽度为0.01时单元格中的轨迹对象分布较为均衡,因而查询性能最好。
4)为了分析查询算法的可扩展性,本文使用数据集DS2,取δ为0.01,k为20,如图7所示。随着数据量的增加,2种方法的响应时间都逐渐增加,但kNNT-Grid的增长幅度相对较小。这主要是因为网格索引可以帮助定位和搜索候选集的一部分,而kNNT-Base需要搜索整个数据集。因而kNNT-Grid的可扩展性更好。
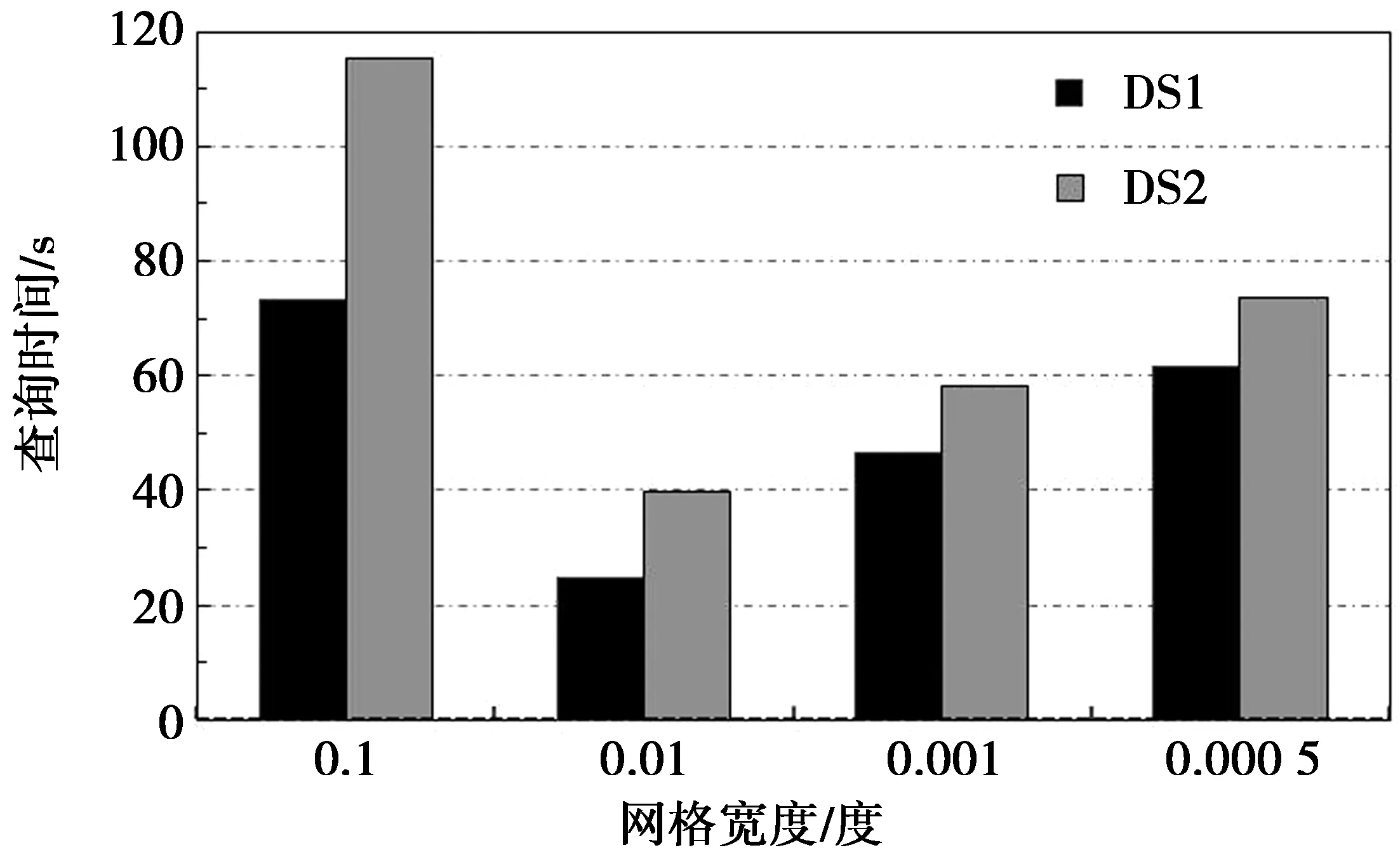
图6 网格宽度对查询性能的影响Fig.6 Effect of width of grid on the query efficiency

图7 查询算法可扩展性Fig.7 Query scalability
6 结束语
为了在分布式环境下高效地支持大规模轨迹数据的kNNT查询,本文设计了一种Spark环境下轨迹数据的分布式网格索引,将轨迹映射到空间网格中。此外,本文应用了轨迹还原表来检索和重建整个轨迹。最后,提出了Spark环境下基于网格索引的轨迹k近邻查询方法kNNT-Grid。该方法在Map阶段定位查询轨迹并执行CircleSearch()算法查找并还原候选轨迹集,并在Reduce阶段排序并输出k个最近邻轨迹。基于不同数据集的实验表明,kNNT-Grid可以提高查询性能,并具有良好的可扩展性。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
作文新天地(初中版)(2019年6期)2019-08-15
现代装饰(2018年5期)2018-05-26
能源(2017年10期)2017-12-20
北京航空航天大学学报(2017年6期)2017-11-23
能源(2017年5期)2017-07-06
中国三峡(2017年2期)2017-06-09
浙江大学学报(工学版)(2016年10期)2016-06-05
雷达与对抗(2015年3期)2015-12-09
