
基于语义检索模型的数字图书馆服务平台研究
2019-09-25 04:16左丽
微型电脑应用 2019年9期
左丽
(咸阳图书馆, 咸阳 712000)
0 引言
信息资源传播及发展以图书馆作为主要承载方式,不断发展的网络信息技术使人们对于信息资源的需求不断提高,从而促进了数字图书馆的研发和使用,在我国信息基础设备建设中数字图书馆成为主要内容,数字图书馆使信息获取突破了时空限制,成为知识经济的重要载体。同时快速完善的网络技术不断降低网络建设成本,使网络在日常生产和生活中得以广泛应用,为用户提供了高效的信息资源获取通道[1]。现代数字图书馆正是借助于网络通过数据完成信息的收集,进而实现将多样化的信息服务提供给用户,如何提高数字图书馆的智能化水平及信息资源共享程度,为用户提供有价值且有针对性的数据信息,更好的满足用户信息需求成为主要发展方向。
1 现状分析
针对数字图书馆的信息检索的关键在于组织及存储信息,在此基础上以实际用户需求为依据完成所需信息的查找与获取。现代的信息检索方法多以关键词、主题检索方式为主,已经实现了超文本属性及开放系统的创建。作为传播和获取信息重要途径的数字图书馆目前主要存在的问题包括:(1)多以关键字为依据进行匹配的信息查询方式难以满足对所需内容的精准和快速定位,语义性的匹配方式不足,图形界面有待进一步的完善;(2)在查找信息过程中,信息表达以读者作为主要对象,语义信息缺少计算机可读性。而语义技术可使上述数字图书馆弊端得以有效解决,在增强数字图书馆信息语义性的同时提升了检索效率。信息检索通常采用Z39.50协议,本文结合图书馆的具体应用功能,完成了数字图书馆检索模型的构建,该模型基于本体语义技术,在此基础上完成了检索系统原型的构建[1]。
2 基于语义检索模型的数字图书馆服务平台的构建
2.1 图书馆本体的构建
快速发展的网络技术为图书馆功能的优化提供了技术支撑,数字图书馆成为信息获取及传播的有效途径,作为衡量数字图书馆服务质量的有效途径,信息检索在数字图书馆发展过程中具有重要地位,传统信息检索多以关键词为依据已难以满足现代读者的多元化和精准化需求,本文重要研究了基于语义检索模型的数字图书馆服务平台,所创建的图书馆本体结构如图1所示。

图1 图书馆本体的创建结构
数字图书资源的专业数据库中的图书馆学科主要可划分为普通类、比较类、专门类、应用类及相关学科几种类型,为使信息的检索效果得以有效提高,部分概念在图书馆本体结构中需实现实例的扩展,图书馆学科分类存在穷举类型(如中国分类号中的图书馆)需在结构体系中扩充[2]。因此需通过实例实现扩展,无需使用子类,以满足不断变化的相关学科的检索需求。
2.2 图书元数据本体创建
构建领域本体需对本体库领域的相关信息(主要包括构建目的、领域范围、表示方法等)进行确定,并对其相关信息使用自然语言完成定义和表达过程,所构建的本体同领域范围呈正比。首先在概念化处理领域信息后完成领域本体框架的建立,在此基础上对各概念之间的关系及具体属性值进行定义,然后据此完成对属性的约束的定义,然后通过子领域本体定义类的划分完成实例的构建,最终完成领域本体模型的建立。对领域本体采通过Protégé 工具的使用完成编码过程,完成到机器语言的转化(即计算机可识别),在实际领域本体模型的创建过程中,需注意各概念、术语在本体库中的意义明确,各概念相互之间具有完整一致的关系,具有较强的可扩展性,通过对已构建好的本体库进行重复利用可有效避免重复建设[3]。
通过创建本体可实现学科判断和推理(以用户检索词为依据),通过语义性描述图书馆DC元数据以实现语义性,具有灵活简便优势的DC元可使检索结果的有效性得以有效提高, OWL及WEB 描述语言(包含多种语义)均有特定的 DC使用方式,将含有15个基本元素的DC元划分为3组,创建DC元数据时在本体中使用属性方式(以其对图书馆信息的描述为依据),DC属性命名空间通过本体的创建实现和使用,使 DC属性使用目的得以有效满足,只需为实例添加属性(能够被直接使用)即可完成描述图书的添加[4]。
具体的引用包括:
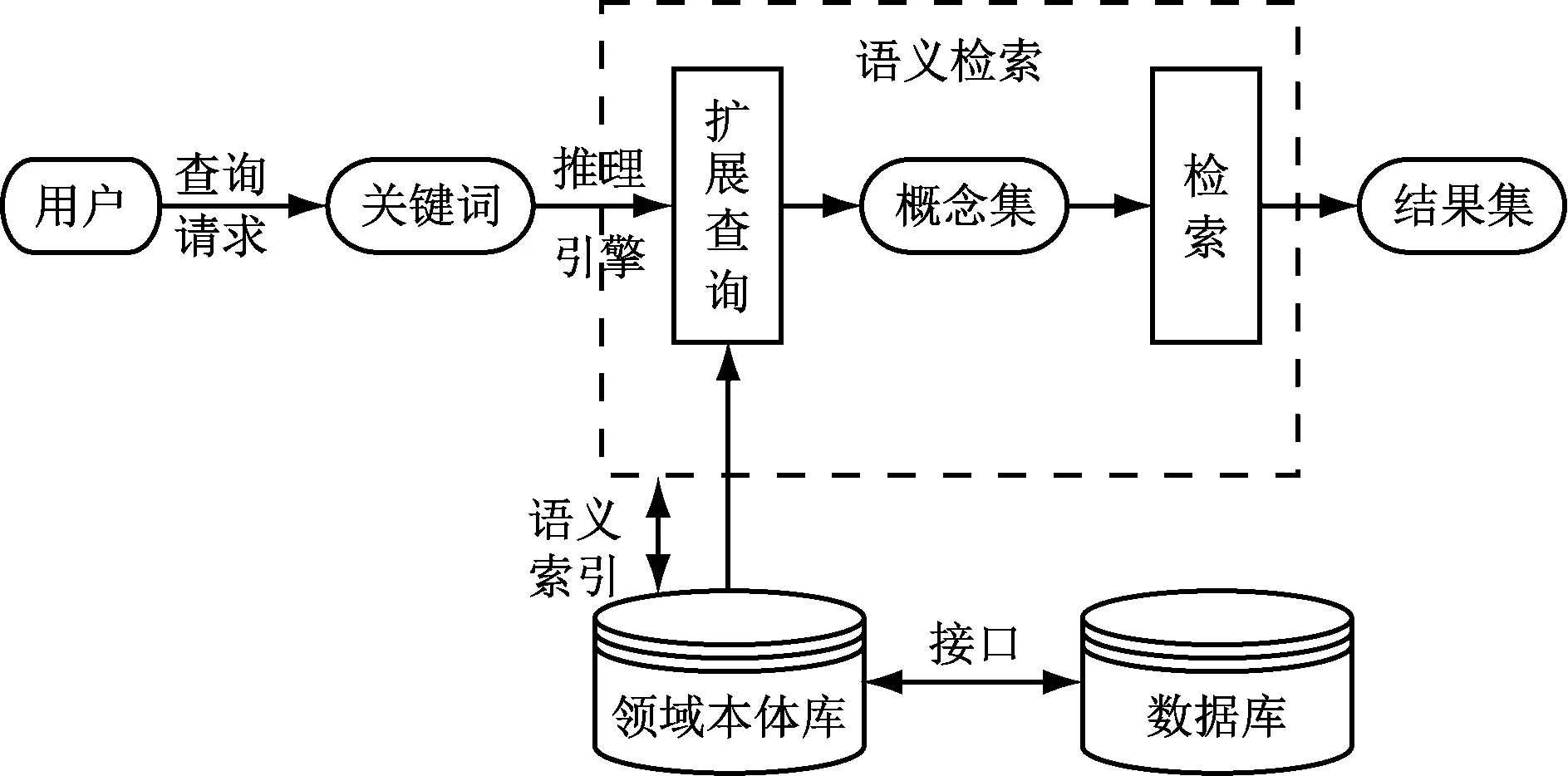
elements/1.1"/> 通过制定语言SGML(元标记功能强大),可有效提升交换web 信息的简便性,其较为复杂的语言规格难以适用动态发展的数据交换方式,SHOE 项目逐渐发展起来,基于语义信息的搜索通过将语义本体添加到web网页中实现,考虑到创建过程中语义 web知识的分散性,本文通过统一框架的创建确保应用过程中的分散性、通用性及安全性,具体的语义体系结构如图2所示。 图2 语义的体系结构 数字图书馆信息以索引、目录及关键词(需用户提供较高精度的关键词)为依据实现检索过程,用户将关键词输入到检索界面后,文本操作系统据此完成语法层次的初步整合,同数字图书馆资源进行匹配再将获取的检索结果返回给用户[5]。信息检索范围涵盖了互联网站点中存储于数据库的数字化知识资源。 为有效顺应数字图书馆的知识化和智能化发展趋势,本文通过语义网技术的运用使信息资源检索过程中检索服务的知识层次得到进一步优化,不断完善的语义技术使数字图书馆在提供通讯平台的同时,通过语义表达的规范化处理实现良好的人机交互过程,从而将优质的思想交流服务提供给用户[6]。对于数字图书馆,语义技术同信息检索间的相似性便于技术融合的实现,本文在现有数字图书馆检索模型的基础上,以信息管理、逻辑描述及人机交互等为依据,完成了基于语义的信息检索模型的构建,检索框架具体如图3所示。 图3 基于语义的数字图书馆信息检索框架 传统信息检索的不足得以有效完善,满足用户对语义及知识层次的多样化需求。 为使信息检索的效率得以有效提高需对信息资源进行科学的组织,具体通过使用语义对信息资源进行有效处理,再结合运用数字图书馆中的相应工具(包括语义字典、分类体系等)完成模型的创建(用于描述信息资源知识概念),并形成领域中的本体,相应领域中的词汇需根据领域专家知识及经验进行确定,自建词汇的关系以不同层次为依据确定。海量的数字化资源会增加统一元数据的难度,表现出半结构化现象,降低了部分信息资源的完整性和使用效率,为此本文通过XML组织文档的使用,对用户感兴趣的信息以传统图书馆信息检索标准为依据完成提取、整合和存储过程,提取文档中数据的流程如图4所示。在完成全部工作的基础上,运用元数据库中信息完成本体的创建后存储于知识库中[7]。 图4 数字化文档中数据的提取流程 3.3 数字图书馆检索系统功能的实现 基于本体语义技术的检索系统模型如图5所示。 图5 基于本体的语义检索模型 采用语义的知识检索模式有效弥补了关键词检索的不足,显著提高了查询结果的精准性。检索的工作流程为:检索系统收到用户的查询请求后,通过分词技术的使用将关键词从中提取出来,再结合语义索引及推理引擎技术完成扩展查询过程,实现到知识层面检索概念集的转换,领域本体库的扩充与拓展过程结合使用具备丰富层次结构的本体及其自主学习技术实现,在此基础上检索该概念集内容再向用户返回检索结果[8]。语义检索主要分为:(1)扩展查询模块,通过推理引擎与语义索引扩展查询关键词形成概念集后传送至检索模块(作为新的查询条件)。同时检索系统通过本体构建工具和分类法的调用对领域本体库进行完善;实现语义检索的基础在于领域本体中的概念同语义通过语义索引建立起索引关系,再将其存储到语义索引表中,包括语义、语义ID(主键)、本体概念、本体概念 ID(外键)。检索系统根据语义索引表完成关键词到本体库具体概念的快速定位及转换。推理引擎原理:领域本体库将概念化的关键词通过语义索引技术遍历本体库完成同义、父子、兄弟类概念的提取,在此基础上进行扩充[9]。并根据本体库中已有网络语义关系对概念间隐藏信息进行推理,然后作为新的概念集传送到检索模块使用户个性化需求得到有效满足。 (2)检索模块,使用BookManage公共类,读者通过下拉列表即可进入到有针对性的检索过程,如FindBookByName(BookManage,strin tb_name)、FindBookByAuthor(BookManage , strin tb_name),检索模块根据接收到的新概念集同数据库中的信息进行匹配,完成相关信息的查找和匹配,系统将分类处理的结果信息以用户实际需求和兴趣爱好为依据返回给用户,并及时更新用户兴趣库。领域本体库借助数据接口映射到数据库,本体中的类及实例分别对应数据库中的表和表记录,当两个类在本体中为父子关系需增加数据库中的主键。为适应专家知识及领域知识的动态更新需对领域本体库进行持续构建完善,数据库管理者为具备使用权限的用户提供访问信息资源的服务,实现数字图书馆信息资源的共享。数据库语义映射的实现使用户可在检索系统界面中根据语义输入并提交查询请求后,通过匹配检索及语义相似度计算,实现全面精准的检索结果的获取[10]。 为检测本文所设计的基于语义检索模型的数字图书馆检索系统的有效性,对系统进行初步测试,以包括基于关键词扩展、关键词普通在内的 2 种检索方式作为实验对象完成具体的检索过程,实验结果如表1和表2所示。 表1 题目图书宣传的结果对比 表2 工作人员的结果对比 测试结果表明本文所设计的系统降低了本体复杂度,实现了子类、实例的扩展过程,从而使搜索效率及准确率得以显著提升。 为弥补数字图书馆信息检索缺少语义的不足顺应数字图书馆今后的发展趋势,本文对基于语义的数字图书馆检索模型进行了设计,用户通过该模型可显著提高所需内容的查全率核准确率,良好的的人机交互过程便于计算机对用户查询需求及时有效的掌握,使数字图书馆检索效果得以有效提高,从而提高用户的满意度及体验度。3 语义检索模型的构建
3.1 语义体系结构

3.2 基于语义的数字图书馆框架


4 系统测试


5 总结
猜你喜欢
哈哈画报(2021年10期)2021-02-28
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
小型微型计算机系统(2019年6期)2019-06-06
科技与创新(2018年2期)2018-01-09
科学与财富(2017年28期)2017-10-14
湖北函授大学学报(2016年13期)2017-01-03
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
图书馆界(2013年5期)2013-03-11
