
基于多任务学习的正逆向情绪分值回归方法
2020-02-08 08:39高晓雅李逸薇李寿山
郑州大学学报(理学版) 2020年1期
高晓雅, 李逸薇, 张 璐, 李寿山
(1. 苏州大学 计算机科学与技术学院 江苏 苏州 215006; 2. 香港理工大学 中文及双语系 香港 999077)
0 引言
随着互联网的高速发展,人们在网络平台上共享信息的同时,越来越习惯于在网络上发表自己的评论及看法。如何对大量包含情感的文本进行情绪分析,挖掘具有潜在价值的信息成为目前自然语言处理领域中的一个热点问题[1]。早期的情绪分析研究主要对评论进行粗粒度的情绪分类,即关注评论的情绪极性(正面、中性、负面)。随着相关研究的深入,文献[2-3]将注意力转移到细粒度情绪分类任务中,对文本进行了更细致的剖析。
与情绪分类不同,情绪回归注重于分析情绪的连续性。文献[4-5]从心理学角度将情绪映射到三维空间,坐标值范围均为1.0~5.0,3个维度分别为极性程度、唤醒度和可控度,其中极性程度表示情绪从消极到积极的程度,唤醒度表示情绪从冷静到激动的程度,可控度表示情绪的控制程度。传统的情绪回归方法,例如长短期记忆网络模型(LSTM)[6]和卷积神经网络(CNN)[7]均只对客观的情绪分值进行回归,回归结果偏差较大。例如,语句“Alonso would be happy to retire with three titles”中,极性程度分值受到词“happy”的影响,模型输出的分值为4.0,但是从词“would be”和词“retire”可以看出情绪有消极的部分。如果从消极的方向出发回归极性程度分值,结果仍可得到4.0,但是由于两种分值的总和始终为6.0。因此,如何利用从消极方向出发回归得到的极性程度分值修正客观的极性程度分值,使得客观的极性程度分值接近于实际的分值3.4,成为本文的挑战。基于此,本文提出一种基于多任务学习的情绪分值回归方法,针对每种分值设计正向和逆向两种打分方式,规定正向为情绪的积极、激动和受控,逆向为情绪的消极、冷静和失控,利用多任务学习方法联合正向打分的情绪回归主任务和逆向打分的情绪回归辅助任务,在多任务学习中通过3种不同的共享机制实现中间特征信息共享,改善了主任务的性能。
1 相关工作
情绪回归是一种情绪分析任务。与情绪分类相比,由于情绪回归缺乏大规模的语料库,因此出现了一些与情绪回归语料库构建相关的研究。文献[8]通过多个在线资源,构建了一个包含2 009个文本的中文情绪回归语料库。文献[9]从Facebook收集用户信息,建立了一个包含2 895个文本的英语情绪回归语料库。文献[1]构建了EmoBank大型情绪回归语料库,其中包含10 000多个英文文本。文献[10]提出一种基于区域卷积模型和LSTM的情绪回归方法RCL,对文本的极性程度分值和唤醒度分值进行了回归。文献[11]通过多任务学习实现了基于二维连续空间(极性程度分值和唤醒度分值)的情感识别。文献[12]在基于循环神经网络的多任务学习框架中,将情绪三元分类和五元分类视为相关任务,通过联合学习改善细粒度情绪分类问题。
与上述研究不同的是,本文从2个方向定义情绪分值,利用多任务学习方法联合正逆向情绪回归任务,并通过3种不同的共享机制提升正向情绪回归任务的性能。
2 多任务学习方法
本文提出一种基于多任务学习的正逆向情绪分值回归方法。为了便于理解,将回归任务抽象为4层:输入层、编码层、解码层、输出层。在编码层中将不同的学习模型抽象为不同的密钥,通过更换模型可以得到不同的回归方法。
2.1 基于编码层共享的多任务学习方法
共享编码层的多任务学习框架如图1所示。
输入数据X,分别经过主任务的编码层和辅助任务的共享编码层,得到中间特征信息hMain1、hMain2、hAux,可以表示为
hMain1=EncoderMain(X),
hMain2=EncoderAux(X),
hAux=EncoderAux(X)。
将中间特征信息hMain1和hMain2拼接后共同输入到主任务的解码层中,再通过解码层得到主任务回归的正向情绪分值rMain,可以表示为
h′Main=hMain1⊕hMain2,
rMain=DecoderMain(h′Main)。
定义一个代价函数来线性连接主任务和辅助任务,可以表示为
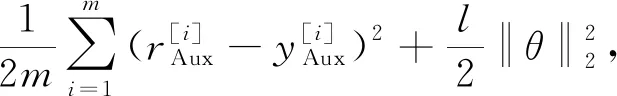
(1)
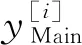
2.2 基于解码层共享的多任务学习方法
共享解码层的多任务学习框架如图2所示。
输入数据X,分别经过2个任务的编码层,得到中间特征信息hMain、hAux,可以表示为
hMain=EncoderMain(X),
hAux=EncoderAux(X)。
将中间特征信息hMain、hAux分别通过主任务解码层和辅助任务解码层,并将hMain共享到辅助任务的解码层,可以表示为
r′Main1=DecoderMain(hMain),
r′Main2=DecoderAux(hMain)。
将主任务解码层输出的r′Main1和辅助任务解码层输出的r′Main2,通过线性加权得到最终的正向情绪分值rMain,可以表示为
rMain=W′·[r′Main1,r′Main2]+b′。
共享解码层的多任务学习框架的loss函数如式(1)所示。
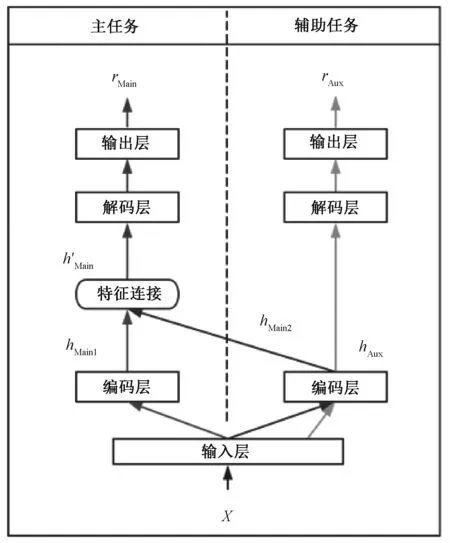
图1 共享编码层的多任务学习框架Figure 1 Multi-task learning framework of encoder-sharing layer
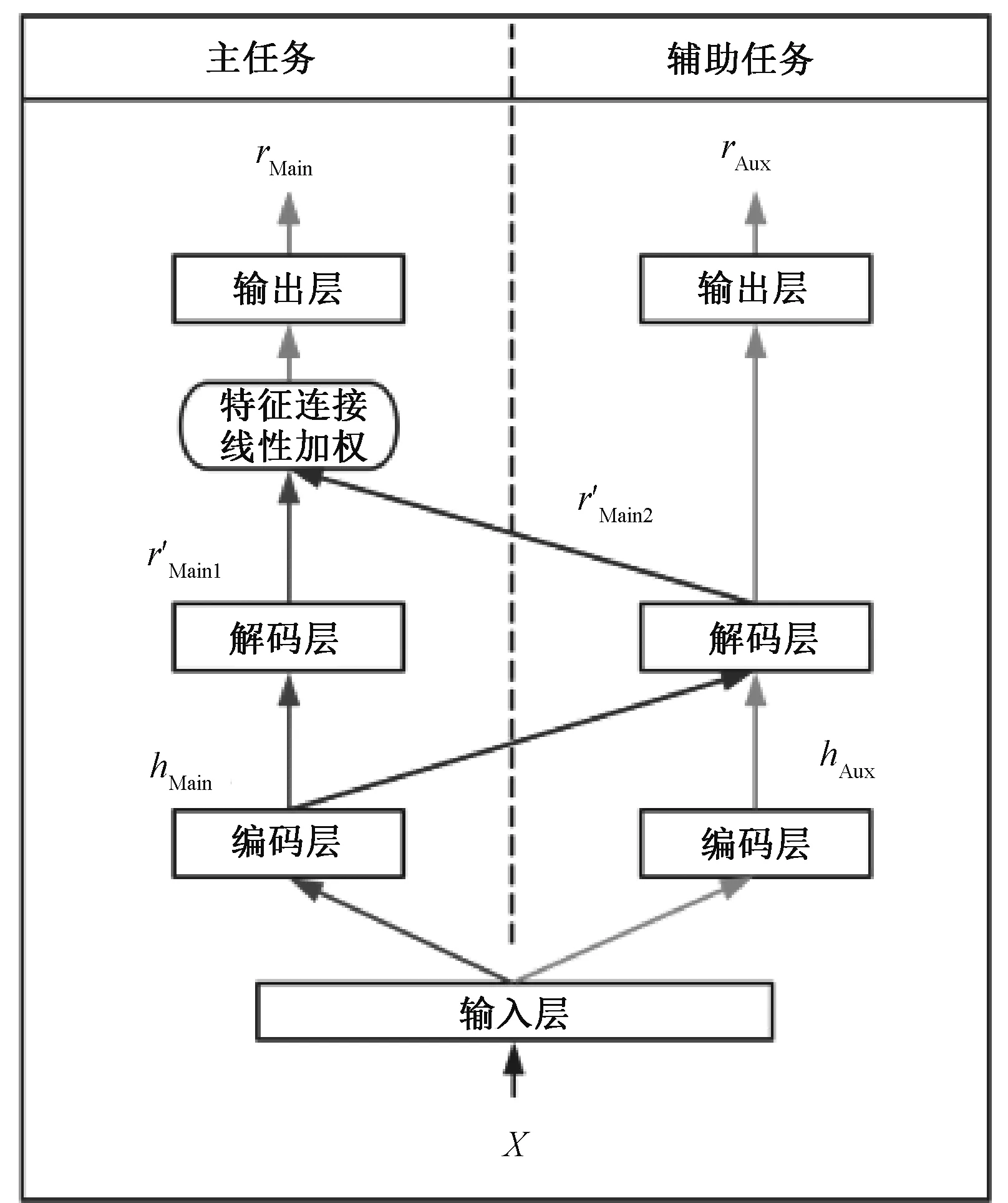
图2 共享解码层的多任务学习框架Figure 2 Multi-task learning framework of decoder-sharing layer
2.3 基于编、解码层同时共享的多任务学习方法
共享编、解码层的多任务学习框架如图3所示,此框架是由上述两种框架相结合产生的。

图3 共享编、解码层的多任务学习框架Figure 3 Multi-task learning framework of encoder-sharing and decoder-sharing layer
输入数据X,分别经过主任务的编码层和辅助任务的共享编码层,得到中间特征信息hMain1、hMain2、hAux,可以表示为
hMain1=EncoderMain(X),
hMain2=EncoderAux(X),
hAux=EncoderAux(X)。
将中间特征信息hMain1和hMain2拼接后得到h′Main,可以表示为
h′Main=hMain1⊕hMain2。
将中间特征信息h′Main、hAux分别通过主任务的解码层和辅助任务的解码层,并将h′Main共享到辅助任务的解码层,表示为
r′Main1=DecoderMain(h′Main),
r′Main2=DecoderAux(h′Main)。
将主任务解码层输出的r′Main1和辅助任务解码层输出的r′Main2,通过线性加权得到正向情绪分值rMain,可以表示为
rMain=W′·[r′Main1,r′Main2]+b′。
共享编、解码层的多任务学习框架的loss函数如式(1)所示。
3 实验部分
3.1 实验设置
3.1.1数据设置 使用文献[1]提供的EmoBank作为语料库,此语料库可以从贡献者的Github(https:∥github.com/JULIELab/EmoBank)中下载得到。语料共包含6个领域(News、Letters、Essays、Travel Guides、Blogs、Fictions),且细分为读者情绪标注和写者情绪标注。将数据集的70%设置为训练集,10%设置为验证集,20%设置为测试集,训练集用于训练构建模型,验证集用于调整模型的超参,测试集用于测试模型的回归性能。
使用斯坦福大学公开的词向量模型(下载网址为https:∥nlp.stanford.edu/projects/glove/)来表示每一条文本的词语。
3.1.2参数设置 在实验中使用LSTM模型作为多任务学习中的编码器和解码器,对拟合唤醒度分值、可控度分值、极性程度分值分别使用了不同的模型参数。词向量维度Embedding均为100维,编码层输出LSTM_output_dim分别为32维、16维、16维,解码层输出Dense_hidden_dim同编码层输出LSTM_output_dim一致。
在训练过程中,最大迭代轮数LSTM_epoch分别为100轮、100轮、300轮,均使用Adagrad优化器且学习率learning_rate为0.02。
3.1.3评估指标 使用均方误差(MSE)和相关系数(r)来衡量模型拟合的情绪分值和实际标注的情绪分值之间的差异,较低的MSE或较高的r表示更好的回归性能。
MSE和r的计算公式可以表示为
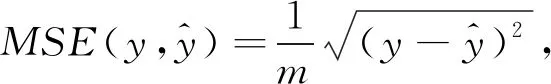
(2)
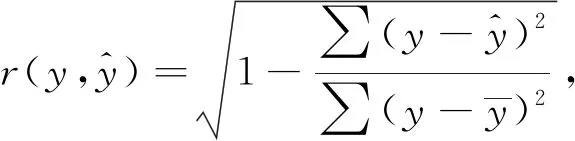
(3)

3.2 实验结果与分析
3.2.1基准方法 首先实现了单任务的正向情绪分值回归方法,分别使用了以下3种模型。
1) SVR模型。SVR模型即支持向量回归模型,是情绪回归任务中最常见的基准方法之一[13],本文实验中应用词袋(BoW)作为其输入特征。
2) LSTM模型[6]。LSTM模型通过引入“门”的机制来决定信息“遗忘”还是“保留”,以解决循环神经网络中的梯度爆炸或梯度消失的问题。LSTM模型具有强大的文本建模能力,广泛应用于自然语言处理领域中。
3) RCL模型[10]。RCL模型将文本按句子划分为多个区域,通过CNN模型提取区域特征,再由LSTM模型拟合出结果,是比较新颖的情绪回归任务的基准方法之一。
基于单任务学习的情绪分值回归方法的性能如表1所示。可以看出,神经网络方法即LSTM模型和RCL模型,通常优于机器学习方法SVR。由于本文使用的EmoBank语料库中的文本大多为单一短小的句子,RCL模型相较于LSTM模型无明显优势。因此,在下面的实验中,将使用单任务学习的LSTM模型作为本文的基准方法。

表1 基于单任务学习的情绪分值回归方法的性能Table 1 Performances of single-task learning approaches to emotion regression
3.2.2多任务学习方法 根据不同的共享机制,多任务学习方法可以细分为基于编码层共享方法、基于解码层共享方法和基于编、解码层同时共享方法3种,使用这3种方法分别拟合读者、写者情绪标注文本的情绪分值。
基于多任务学习的情绪分值回归方法的性能如表2所示。可以看出,无论选择何种共享机制,基于多任务学习的方法始终优于本文的基准方法(LSTM单任务方法),并且也优于RCL单任务方法,从而验证了本文所提出的多任务学习方法的有效性。显著性检验结果表明,本文的多任务学习方法相对于基准方法的改进效果是显著的(P<0.05)。

表2 基于多任务学习的情绪分值回归方法的性能Table 2 Performances of multi-task learning approaches to emotion regression
此外,本文的多任务学习方法在所有领域(语料融合了6个领域)的表现均比单任务学习方法更佳,其中编、解码层同时共享的多任务学习方法表现最佳。显著性检验结果表明,编、解码层同时共享的方法相对于仅共享编码层或仅共享解码层的方法,改进效果是显著的(P<0.05)。
为了更好地理解多任务学习方法的有效性,对结果文件进行了分析,发现基准方法拟合出的结果往往会超过情绪分值的最大值,而使用多任务学习方法时,正向分值受到逆向分值的影响,结果均小于情绪分值的最大值。
4 结论
本文提出了一种基于多任务学习的正逆向情绪分值回归方法,对EmoBank语料库中情绪的三维分值进行拟合。针对每种分值设计正向和逆向2种打分方式,利用多任务学习方法联合学习正向打分的情绪回归主任务和逆向打分的情绪回归辅助任务,在多任务学习中通过3种不同的共享机制实现中间特征信息共享。实验结果表明,这种基于多任务学习的方法比单任务学习的方法效果更佳;在多任务学习方法中,基于编、解码层同时共享的方法比仅基于编码层或解码层的方法获得了更好的回归性能。在未来的研究工作中,将考虑在编码层中尝试一些新的模型,以及探索语料库中读者和写者情绪之间的一些关联性,扩大多任务学习的范围,以进一步提高回归性能。
猜你喜欢
应用心理学(2022年5期)2022-11-05
中国石油石化(2022年12期)2022-07-16
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代信息科技(2021年21期)2021-05-07
中国外汇(2019年19期)2019-11-26
时代英语·高一(2019年5期)2019-09-03
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2017年23期)2017-02-02
中国新技术新产品(2016年23期)2016-12-26
