
基于Bi-LSTM-CRF的商业领域命名实体识别
2020-03-05 09:47丁晟春方振王楠
现代情报 2020年3期
关键词:深度学习
丁晟春 方振 王楠


摘 要:[目的/意义]为解决目前网络公开平台的多源异构的企业数据的散乱、无序、碎片化问题,提出Bi-LSTM-CRF深度学习模型进行商业领域中的命名实体识别工作。[方法/过程]该方法包括对企业全称实体、企业简称实体与人名实体3类命名实体识别。[结果/结论]实验结果显示对企业全称实体、企业简称实体与人名实体3类命名实体识别的识别率平均F值为90.85%,验证了所提方法的有效性,证明了本研究有效地改善了商业领域中的命名实体识别效率。
关键词:商业领域;命名实体识别;深度学习;Bi-LSTM-CRF
DOI:10.3969/j.issn.1008-0821.2020.03.010
〔中图分类号〕TP391 〔文献标识码〕A 〔文章编号〕1008-0821(2020)03-0103-08
Abstract:[Purpose/Significance]In order to solve the problem of scattered,disordered and fragmented multi-source heterogeneous enterprise data of the current network open platform,the Bi-LSTM-CRF deep learning model was proposed for the named entities recognition in the business field.[Method/Process]This method included three kinds of named entities:enterprise full name entity,enterprise short name entity and personal name entity.[Result/Conclusion]The experimental results showed that the average F value of the recognition rate of the three types of named entities,namely enterprise full entity,enterprise abbreviation entity and person name entity,was 90.85%,which verified the effectiveness of the proposed method.It was proved that this study effectively improved the efficiency of named entity recognition in the commercial field.
Key words:business domain;named entity recognition;deep learning;Bi-LSTM-CRF
隨着国民经济的稳定发展,中国正步入改革开放的关键时期,经济全球化的发展和国家政策的支持正给国内企业发展带来新的机遇与挑战。企业信息作为企业决定自身发展、企业间合作及政府监管的一项重要依据,对推动经济社会的发展有着重大影响。基于企业产生的大量数据,具有重要的研究价值和实践意义[1]。
然而,大数据时代的到来引发的“信息爆炸”使得人在轻松获取大量信息的同时,也带来了信息来源繁杂、数据散乱无序、质量真伪难辨等诸多问题,这些问题使得全面了解一个企业变得困难。用户所需的企业相关知识通常是稳定和行业通用的,但这些知识往往以图形、文档等不同形式存在,存储地点零散,分布平台广泛,查找费时费力又难以保证准确性。这样的信息难以获取更加难以让用户进行阅读和理解,因此深入关联地挖掘企业各种信息之间潜在的关系,挖掘互联网上实时的财经公告和新闻信息等非结构化文本信息,对相关信息进行识别整合,有助于改善用户的阅读体验和效率。
在此前提下,本研究以商业领域信息为研究对象,针对命名实体识别任务提出Bi-LSTM-CRF命名实体识别算法,帮助用户挖掘和组织商业领域的信息。
1 相关工作
实体识别,就是指从文本中识别出有意义的命名性实体,并将其划分到指定类别的过程,主要包括人名、地名、机构名、专有名词的识别等。实体识别最早在上世纪90年代的MUC任务中被提出,自此一直是信息抽取和自然语言处理领域研究的热点课题[2]。
早期的命名实体识别(Named Entity Recognition,NER)主要使用基于规则的方法,通过分析实体的构成特点和上下文特征,人工构造有限的特定规则,再从文本中识别满足这些规则的实体。如Ralph G N[3]针对不同类型的实体编写不同的抽取规则,周昆等[4-5]构建了命名实体识别的规则库。此类方法中规则的制定编写通常需要众多领域专家来参与,对语言参与者的知识水平的要求很高,难度大,可移植性低。
到20世纪90年代后期,基于统计的方法开始成为处理命名实体识别问题的主流。HMM[6-7]、ME[8]、CRF[9]和SVM[10]等常见的统计机器学习模型都被成功应用于命名实体的序列标注问题上,且取得了较好的结果。其中,条件随机场(CRF)方法是最为常见的一类模型,它是Lafferty J D等在2001年提出的一种典型的判别式模型(Discirminative Model)[11],既拥有判别式模型的优点,又兼具生成式模型考虑生成标签的转移特征的特性,因此在命名实体识别任务中得到了广泛地研究与应用。
近年来,基于深度学习的方法能够从数据中自主的学习特征,而不需要人为的去设定特征,成为研究的热点,也有越来越多的学者把深度学习模型应用到命名实体的识别之中。如王国昱[12]基于栈式自编码的深度神经网络模型(DNN),在人民日报语料集上的地名、机构名的识别,Dong X等[13]基于卷积神经网络(CNN)模型,提出一种两阶段的电子病历的命名实体识别方法,朱丹浩等[14]基于词向量的双向长短时记忆神经网络模型(BI-LSTM)等。
综上所述,本文在分析了商业领域企业名称、人物名称的构成特点之后,将结合LSTM[15]模型和CRF模型进行商业领域企业名、人名的命名实体识别研究。
2 商业领域实体识别
实体信息除了可以在各种相应的网站的结构化或半结构化的数据之中抽取,例如政府监管机构公布的企业信息,企业公布的年报等等,还有更多丰富的信息蕴藏在大量的、动态的财经资讯、商业公告这类非结构化数据之中。
2.1 模型框架
本文提出一种综合多特征的Bi-LSTM-CRF深度学习模型进行商业领域中企业全称、企业简称与人名的命名实体识别工作,模型整体架构如图1所示。该模型为基于字符的序列标注模型,主要可分为3部分:输入特征层、Bi-LSTM中间层、CRF输出层。首先将文本分割成一个一个字,每个字使用拼接的特征向量表示,作为模型的输入;中间层使用包含前向和后向两个方向的LSTM神经网络层对输入的文本序列建模;最后采用CRF层作为模型的输出层生成对应的类别标签序列。
1)Input:Input为模型的输入特征层。将训练集文本看成是字的聚合,每个字在模型的输入由字向量(Char Embedding)和额外的特征向量(Additional Features)联结而成。其中字向量为Word2Vec训练出的词向量,额外的特征向量为不同特征组合(分词特征、词性特征及实体边界特征)下拼接形成的特征向量。
2)Bi-LSTM:利用双向的具有LSTM单元的循环神经网络对输入序列信息进行特征提取,最终将两个方向的LSTM结果进行联结,输入到CRF层。
3)CRF Layer:CRF作为模型的输出层,生成文本的序列标注结果。
其中,在Input和Bi-LSTM层之间,还使用了一个Dropout参数进行正则化。Dropout通过在前向计算过程使一定比例的单元随机失活来防止隐藏单元的共同调整,使得网络对于噪声更具鲁棒性。
2.2 输入特征层
首先,在对语料进行分词后,使用分布式表示将每个词映射到一个较短的词向量上,解决One-hot向量维度过大的问题。同时考虑到传统模型输入只考虑字级别的词向量,可能会丢失词语层面的语义信息,因此本文在此基础上,从百科网站、企业黄页、搜狗词库等语料库中搜集大量相关语料信息,研究分析商业领域中企业名称、人名的构成特点,得到了商业领域中关于企业名称、人名独特的分词特征、词性特征和实体边界特征,定义了额外的特征向量作为模型的输入补充,以提高模型识别的效果。
2.3 Bi-LSTM-CRF层
本文采用双向长短时记忆神经网络和条件随机场相结合(Bi-LSTM-CRF)的方法,构建神经网络模型进行3类实体的识别。该方法相较于传统的机器学习的优势在于,神经网络可以自行学习数据的特征,无需人工构建复杂的特征工程,可以获得不错的效果。由于神经网络具备自主学习特征的特性,使得我们可以将多个不同类别的命名实体任务结合到一个模型中,将不同类型的命名实体识别任务转化为有监督的多类别的序列标注问题,提升识别任务的工作效率。
2.3.1 LSTM
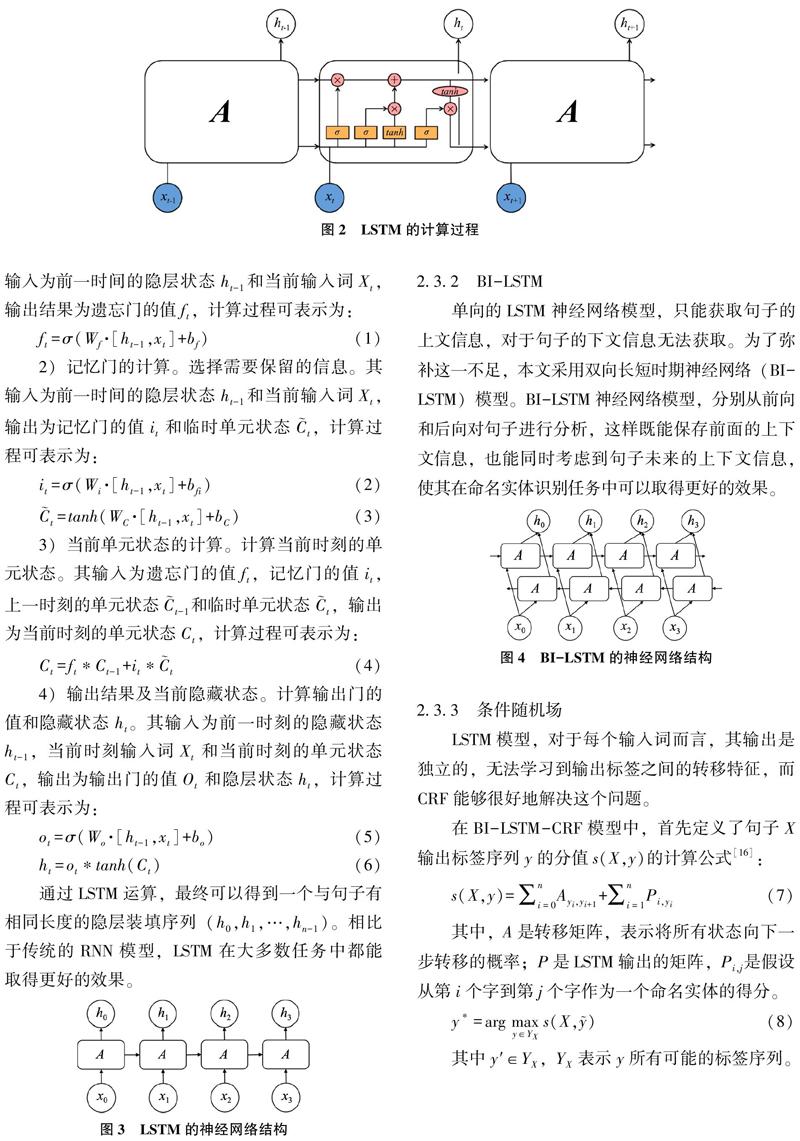
LSTM(Long Short-Term Memory,长短期记忆网络),是近年来较为火热用来进行命名实体识别的深度学习模型。LSTM是RNN(Recurrent Neural Network,循环神经网络)的基础上改进而来的一个模型,本质是具备长短时记忆单元的循环神经网络,其缓解了传统RNN训练时产生的梯度消失问题,且能建模词之间的长期依赖关系,被广泛地应用于文本序列建模任务中。LSTM计算过程如图2所示。
LSTM计算过程包括以下步骤:
1)遗忘门的计算。选择需要丢弃的信息。其
2.3.2 BI-LSTM
单向的LSTM神经网络模型,只能获取句子的上文信息,对于句子的下文信息无法获取。为了弥补这一不足,本文采用双向长短时期神经网络(BI-LSTM)模型。BI-LSTM神经网络模型,分别从前向和后向对句子进行分析,这样既能保存前面的上下文信息,也能同时考虑到句子未来的上下文信息,使其在命名实体识别任务中可以取得更好的效果。
2.3.3 条件随机场
LSTM模型,对于每个输入词而言,其输出是独立的,无法学习到输出标签之间的转移特征,而CRF能够很好地解决这个问题。
在BI-LSTM-CRF模型中,首先定義了句子X输出标签序列y的分值s(X,y)的计算公式[16]:
3 实验设置与结果分析
3.1 数据采集及预处理
1)数据集来源
本文数据集主要来源于财经网站。目前,国内较有影响力的财经网站有东方财富网、财经网、和讯网、新浪财经、网易财经等,如表1所示,通过对比百度搜索指数提供的多个网站的整体搜索指数和移动搜索指数,本文最终选择关注度最高、最受用户欢迎的东方财富网作为本文的实验信息来源。具体数据采集方式为人工编写相应的爬虫框架,通过分析网页数据的分布特征,针对性地采集东方财富网上的财经公告板块。
按照既定的规则模板爬取页面上的数据信息时,由于模板的覆盖面终究有限,解析出的文本内容往往存在一些“杂质”,如一些HTML标签〈br〉、〈em〉,无法识别的特殊字符,多余的空白占位符等,这些都会对后续的信息抽取产生不良影响。针对这些残留的HTML标签和特殊字符,本文统一借助正则表达式实现相应的过滤和替换操作,以获取高质量、无杂质的网页文本数据集。
2)数据集
本实验数据来源于爬取的东方财富网财经公告数据。其中,人工标注了1 200篇文本数据作为实验的数据集,如表2所示,涉及企业全称实体2 985个,企业简称实体3 095个,人名实体1 139个,合计实体7 219个。处理完的数据集格式部分如图5所示,采用BIO标注模式,文本中的每一个字及相应的标注即为一行,其中ORG表示企业全称实体,ABR_ORG表示企业简称实体,PERSON表示人名实体,O表示非实体。即在该图中,“长沙海格”表示一个企业简称实体,“易灿”、“徐建军”分别表示一个人名实体,“湖南高新创业投资集团有限公司”表示一个企业全称实体。最终将数据集按7/3的比例划分训练集和测试集,进行命名实体模型的训练。
3.2 实验设计
为了寻找模型的最佳参数配置,本文进行了参数搜索试验。搜索过程中,将词向量的维度定在[50,100,150]之间,每层LSTM的单元数定在[64,128]之间,Dropout定在[0.4,0.5,0.6]之间。最终定下模型最佳的训练参数设置如表3所示,即:字向量维度为100,分词特征、词性特征、边界特征向量维度为20,每层LSTM维度为128,Dropout值为0.5,Batch Size大小为20,学习率为0.001,优化算法为Adam。
为了验证文本提出的Bi-LSTM-CRF神经网络模型和添加的特征组合的有效性,在该部分设计了两类任务:1)比较传统CRF模型和Bi-LSTM-CRF神经网络模型在本文命名实体识别任务中的实体识别效果。2)探究在Bi-LSTM-CRF神经网络模型下,针对3类实体识别效果最好的输入特征组合。
最终定义了10个模型进行对比:
模型1:只考虑输入单词本身特征的CRF模型。
模型2:考虑输入单词本身及词性特征以及上下文单词及词性特征的CRF模型。
模型3:只考虑字向量输入的Bi-LSTM-CRF模型。
模型4:考虑字向量、分词特征的Bi-LSTM-CRF神经网络模型。
模型5:考虑字向量、词性特征的Bi-LSTM-CRF神经网络模型。
模型6:考虑字向量、实体边界特征的Bi-LSTM-CRF神经网络模型。
模型7:考虑字向量、分词特征、词性特征的Bi-LSTM-CRF神经网络模型。
模型8:考虑字向量、分词特征、实体边界特征的Bi-LSTM-CRF神经网络模型。
模型9:考虑字向量、实体边界特征、词性特征的Bi-LSTM-CRF神经网络模型。
模型10:考虑字向量、分词特征、词性特征、实体边界特征的Bi-LSTM-CRF神经网络模型。
具体实验中,为方便书写,将分词特征简写为Word,词性特征简写为Pos,边界特征简写为Boundary。
3.3 任务一实验结果分析
任务一的实验结果如表4所示,从中可以发现:
1)对比模型1与模型3,在仅考虑字向量输入的情况下,模型3的命名实体识别F值达到了87.82%,明显高于模型1的F值82.89%,且在企业全称实体、企业简称实体、综合识别效果上都达到了最佳,而人名实体识别比模型1略低但差距不大。综合来看,Bi-LSTM-CRF神经网络模型的实体识别效果明显优于传统的CRF模型。
2)对比模型2与模型3,模型2为考虑了词本身单词特征、词本身词性特征、上下文词特征、上下文词性特征等多种特征组合的CRF模型,其实体识别的F值为85.66%,比模型1的F值高2.77%,但仍比模型3的F值低2.16%。这表明考虑特征组合的CRF模型的实体识别效果与传统CRF模型相比有明显提升,但仍低于无特征的Bi-LSTM-CRF模型的识别效果。
3.4 任务二实验结果分析
任务二的实验结果如表5所示,从中可以看出:
1)无论是分词特征、词性特征还是实体边界特征,都有助于模型识别效果的提升,尤其是词性特征,添加后模型整体F值比基准模型高出了2个百分点。
2)实体边界特征的添加对企业全称的识别有显著的提升,企业全称的识别F值直接从89.77%上升到了93.27%。词性特征的添加对企业简称的识别F值有小幅度的提升,从86.05%提升到了87.60%。分词特征和词性特征的组合添加对人名识别有着显著的提升,人名识别的F值从87.52%上升到了92.17%。这说明本文结合实体自身的特点,提出的额外特征是有效的,这些特征在不同程度上都提高了命名实体的识别质量。
3)最好的模型是综合考虑3种特征组合的模型,即模型10,其在企业全称识别的F值上达到了93.95%,企业简称识别的F值上达到了87.09%,人名识别的F值达到了93.62%,综合F值达到90.85%,超出基准模型3个百分点,超出传统CRF模型8个百分点。这再一次验证了本文提出的特征的有效性,综合使用这3种特征能显著提升神经网络模型对于企业全称、企业简称及人名命名实体的识别效果。
以上模型中企业简称的识别率相对较低,提升幅度也最小,究其原因可能是:企业简称构词复杂、形式多变,神经网络难以捕捉到其特征;模型训练依赖于标注语料,可能存在人工标注的部分错误和遗漏,导致模型识别出的简称被判断错误;且标注语料中,企业简称的标注数量也相对较少,导致模型训练不充分;另外人工添加的特征中,词性特征和词典特征对企业简称的覆盖也较少,实体边界特征更是只考虑人名和企业全称的构成规则,没有考虑企业简称的自身特点,因此额外添加的特征对企业简称的识别提升较小。但总体来说,采用添加分词特征、词性特征和实体边界特征的Bi-LSTM-CRF神经网络模型对企业全称和人名的识别率都在93%之上,3类實体的识别率在90%之上,这对于在商业领域的文本中抽取相关实体是非常有助益的。
4 总结及展望
本文从商业领域中企业名称、人名的构成特点考虑,提出一种综合分词特征、词性特征和实体边界特征的Bi-LSTM-CRF深度学习模型,实现对商业领域中3类实体的命名实体识别工作,实验验证了本文提出方法的有效性。在未来的研究中,还将考虑企业间实体的开放性抽取,并对抽取的实体关系进行聚类研究,进一步探索使用更为复杂的神经网络模型来实现商业领域的命名实体识别。
参考文献
[1]田娟,朱定局,杨文翰.基于大数据平台的企业画像研究综述[J].计算机科学,2018,45(S2):58-62.
[2]孙镇,王惠临.命名实体识别研究进展综述[J].现代图书情报技术,2010,(6):42-47.
[3]Ralph G N.The NYU System for MUC-6 or Wheres the Syntax?[C]//Message Understanding Conference,1995.
[4]周昆.基于规则的命名实体识别研究[D].合肥:合肥工业大学,2010.
[5]郑家恒,李鑫,谭红叶.语料库的中文姓名识别方法研究[J].中文信息学报,2000,(1):7-12.
[6]Bikel D M,Miller S,Schwartz R,et al.Nymble:A High-performance Learning Name-finder[C]//Conference on Applied Natural Language Processing,1997.
[7]Bikel D M,Schwartz R,Weischedel R M.An Algorithm that Learns Whats in a Name[J].Machine Learning,1999,34(1-3):211-231.
[8]Borthwick A E.A Maximum Entropy Approach to Named Entity Recognition[M].New York University,1999.
[9]Mccallum A,Li W.Early Results for Named Entity Recognition with Conditional Random Fields,Feature Induction and Web-Enhanced Lexicons[C]//Conference on Natural Language Learning at Hlt-naacl.Association for Computational Linguistics,2003.
[10]Isozaki H,Kazawa H.Efficient Support Vector Classifiers for Named Entity Recognition[C]//International Conference on Computational Linguistics,2002.
[11]Lafferty J D,Mccallum A,Pereira F C N.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[J].Proceedings of Icml,2001,3(2):282-289.
[12]王国昱.基于深度学习的中文命名实体识别研究[D].北京:北京工业大学,2015.
[13]Dong X,Qian L,Guan Y,et al.A Multiclass Classification Method Based on Deep Learning for Named Entity Recognition in Electronic Medical Records[C]//Scientific Data Summit.IEEE,2016.
[14]朱丹浩,杨蕾,王东波.基于深度学习的中文机构名识别研究——一种汉字级别的循环神經网络方法[J].现代图书情报技术,2016,(12):36-43.
[15]Hochreiter S,Schmidhuber J.Long Short-term Memory[J].Neural Computation,1997,9(8):1735-1780.
[16]李明浩,刘忠,姚远哲.基于LSTM-CRF的中医医案症状术语识别[J].计算机应用,2018,38(S2):42-46.
(责任编辑:孙国雷)
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
