
基于Hadoop的文本分析平台实践
2020-04-04 06:49
安顺学院学报 2020年1期
(1、2.贵州师范大学大数据与计算机科学学院,贵州 贵阳550001)
现阶段,人工智能和机器学习正在改变当下业务形态,特别是随着深度学习革命的兴起,其系统化实现将引领数据驱动的计算智能在各领域爆发[1-3]。数据分析能力将逐渐成为商业游戏规则的核心竞争力。而针对当前大多数领域的数据分析而言,其数据往往停留在一些易获取、易量化、可度量的传统数值数据分析阶段,数据驱动智能还远远没有体现。特别是针对文本信息,其作为人类自然语言的载体,信息处理一直是智能化的瓶颈问题。
中文信息的预处理是一项繁杂的工作,近年来,随着自然语言处理技术的发展,作为一种处理海量非结构化文本的前沿技术,其为大量的社会科学如传播学[4]、社会学[5]等发展带来了新的机遇。针对大量的非结构化文本数据,开源的数据分析平台,解决了一台计算机无法进行存储、无法在要求时间内进行处理的关键问题。Hadoop[6]作为一个开源的分布式系统,因其实现了云计算和分布式云存储,近年来得到广泛的开发应用。围绕大数据存储、大数据分析及管理,Hadoop形成了自身的大数据生态。文章结合Hadoop开源分布式计算框架,嵌入IKAnalyzer中文分词模块进行了中文分词及词频统计分析,结合Spring boot框架及Node.js技术,搭建了一个基于Web的中文分词及词频分析统计平台。与此同时,研究利用下载的金庸小说文本语料及贵州极贫乡镇教育调研收集的文档语料进行了相关数据分析实践。
一、基于Hadoop的文本分析框架
Hadoop继承并改进了Google的MapReduce编程框架[7],可以把应用程序处理成众多小块,让集群节点并行进行处理。Hadoop分布式计算基础架构由分布式文件系统(HDFS, Hadoop Distributed File System)和MapReduce编程模块两部分组成。HDFS部署在成本较低的PC上,它以流式访问模式访问数据,能够大大的提高数据吞吐量以提高系统整体的效率。它为MapReduce计算框架提供了基础数据支撑,一个HDFS分布式文件管理系统包括一个NameNode节点和多个DataNode节点,NameNode节点即为文件管理系统的 “管理者”,主要负责管理文件系统的命名空间、存储块的复制和集群配置信息,DataNode节点是文件存储的基础单元,主要负责将文件块存储至本地文件系统并周期性地发送所有存储的文件块的信息给NameNode节点。MapReduce为并行计算框架,此系统中完成对中文信息的分词及统计。
结合应用及现有资源,系统基于同一局域网下三台CentOS系统的虚拟机进行三个节点的Hadoop分布式集群搭建,三台虚拟机主机分别为:HadoopAdmin(192.168.160.81)、HadoopPart01(192.168.160.82)、HadoopPart02(192.168.160.83),其中HadoopAdmin主机作为名称节点,主要负责管理整个HDFS文件系统,同时也作为数据节点,另外两台主机作为数据节点,主要负责保存文件中的数据,HadoopPart01 作为SecondaryNameNode节点,HadoopPart02 作为ResourceManager服务器。本研究中构建的HDFS体系集群结构如图1所示[8]。

图1 HDFS体系结构
为快速进行应用开发,系统选取Spring Boot作为系统框架[9],其为2013年推出的一款全新的Java Spring框架,目的在于解决用户在Spring开发过程中需要进行大量繁杂配置的问题,使得开发人员能够从复杂配置中解脱出来专注于程序开发。Spring Boot框架对现在主流的Maven构建工具也提供了非常好的支持。因此,系统选取该框架作为系统开发的工具。
与此同时,选取了开源的Java中文分析包IKAnalyzer作为中文分词及词频统计的工具包[10]。IKAnalyzer以开源项目Lucene为应用主体的,结合词典分词和文法分析算法实施分词。本文研究中采用的是IKAnalyzer2012_u6版本,在2012_u6版本中,其实现了分词歧义排除算法,采用正向迭代最细粒度切分算法,支持细粒度分词模式和智能分词模式。
例如:“交管局正在治理解放大道路面结冰问题”
细粒度分词模式对应分词结果为:交管局 | 交管 | 管局 | 正在 | 治理 | 理解 | 解放 | 放大 | 大道 | 道路 | 路面 | 结冰 | 问题
智能分词模式对应分词结果为:交管局 | 正在 | 治理 | 解放 | 大道 | 路面 | 结冰 | 问题
系统在普通的环境中具有160万字/秒的高速处理能力。
为了使得系统有一个友好而灵活的UI呈现,系统采用了node.js技术,选取了Vue.js构建数据驱动的Web界面框架。利用iView组件及百度提供的Echarts实施前端设计及数据可视化呈现[11]。
Vue.js具有组件化开发思想,数据双向绑定等优点。利用组件化进行开发,能体现出高内聚低耦合的特性,并且组件化能够将HTML、CSS、JavaScript前端开发语言集成到一个文件中,非常便于前端开发人员编写、维护前端项目。各组件之间的数据、逻辑方法等互不干扰,非常利于开发人员定位解决问题。双向数据绑定即是视图层显示数据与数据模型之间的绑定,当视图层显示数据发生改变时,其对应的数据模型也发生改变,同样的,当数据模型发生改变时,其对应的视图层显示数据也会发生相应的改变,这样大大降低了前端开发人员的工作量。
系统搭建了友好的应用界面,以便用户能在Hadoop平台实施应用,研究实践了从文档收集、文档预处理、分布式计算、词频分析、可视化呈现的初步流程实践。
二、文本分析系统组成
基于Hadoop分布式计算框架为大规模文本分析提供了基础保障,嵌入IKAnalyzer中文分词器进行中文文本切割,借助Hadoop自带的交换Key-Value功能实现按词频降序排序功能。结合Web系统服务应用开发,用户可通过访问前端Web页面实现用户注册,文件上载,文本分析,结果可视化等文本分析服务。
系统整体框架如图2所示。现阶段实现的基础功能如下:
(一)用户管理
系统搭建了Web应用,用户管理模块可完成用户信息注册,登录,查看和修改等功能,以便管理用户为注册用户提供文本分析服务;
系统实施注册用户验证登陆后提供服务模式,用户填入用户名和密码进行登录,用户可选择记住密码,若选择记住密码,登录成功后系统将自动记住该用户账号和密码,下次登录时不用再输入账号密码信息,若验证通过则跳转至系统首页,否则页面不做跳转。
用户登入系统进入首页后,可将鼠标放置到用户头像处进行用户信息查看,点击“修改密码”图标进行密码修改,点击“退出系统”图标登出系统,点击“上传文件”按钮进行待分词文本文件上传,点击“开始分词”按钮调用算法进行中文分词及词频统计操作,点击“查看统计图”按钮进行分词结果查看。
(二)文件管理
系统可进行服务端口配置,文件上载大小配置,为注册用户提供计算文档的上载接口;在文件上传成功后,便将文本文件重命名为text.input作为备用文件。
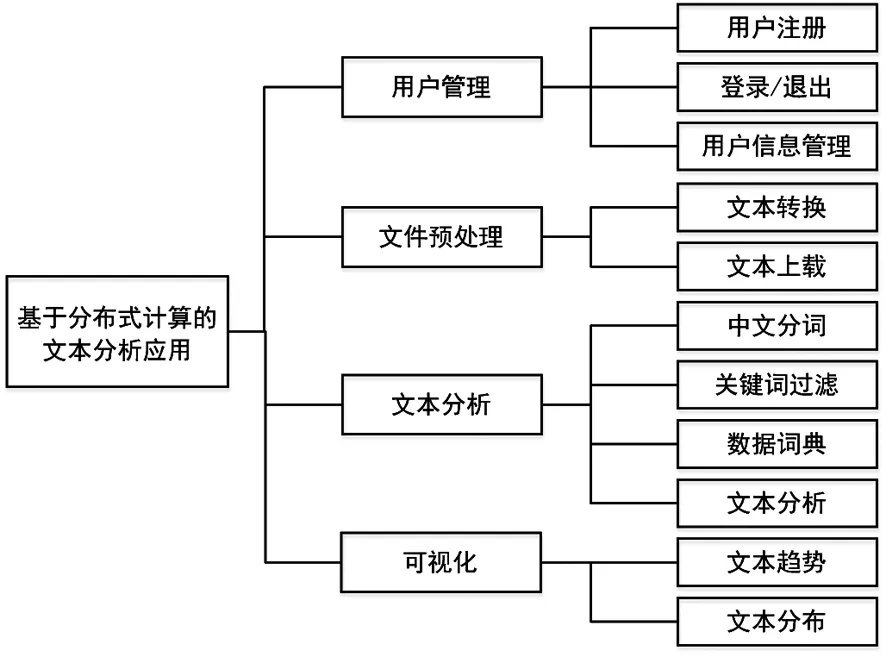
图2 系统模块
(三)文本分析
分词是中文信息处理一个很难回避的基础问题,文本分词、关键词提取、词频统计都是自然语言处理基础性任务,西方字母文字语言,如英语可利用单词之间的空格作为自然分界符。中文信息是表意文字,缺乏形态变化,语义和语法规则进行字或词切分存在固有的技术难点和障碍,所以,中文文本分词被广泛研究。常见的分词工具有LTP,ICTCLAS,Jieba分词,THULAC等,考虑基于Java开源平台搭建Web应用,研究采用开源的IKAnalyzer工具包,其中的IKSegmenter将文本内容进行智能切分,并配置停用词表将中文分词常用停用词进行过滤。
当中文文本数据量非常大时,基于Hadoop分布式系统进行并行运算,在MapReduce阶段完成对大量文本数据的分词与词频统计任务,从而提高了文本分析系统的运行效率。
关键词是文本分析的关键,其往往是文本摘要,主题呈现的关键,系统初步进行分词词频,借助数据词典,改进TF-IDF,如论文统计中考虑TF所在标题或摘要中的权重。TextRank等即可实现初步需求。系统给更进一步的主题分析提供了接口
(四)可视化结果
系统利用node.js环境构建Web前端服务,通过安装npm构建Vue项目,通过npm包管理工具下载和安装iView组件库、vuex管理工具、axios和echarts。借助可视化图表库echarts完成文本统计结果的可视化呈现。
当前,系统集群计算主要是利用Mapreduce进行分词及词频统计,Map借助IKAnalyzer中文分词器的IKSegmenter将文本内容进行智能切分模式的切分,并配置停用词表进行文本滤掉。Reduce将Map产生的输出结果作为输入数据进行切分好的词语的词频统计,最终以键值对的方式输出,关键词为键,词频为值。Reduce按照键来排序,因中文关键词为键,所以当分词和词频统计任务结束后先将输出的结果文件保存至临时文件夹temporaryData下,然后将临时文件夹下的结果文件作为按词频降序排序任务的输入文件继续创建并执行Job,此任务借助由Hadoop库提供的InverseMapper类完成,该类将键值对数据中的键和值进行交换,交换后词频为键词名为值,Hadoop会根据键值对中的值即词频进行降序排序,然后将结果文件输出至指定目录。
平台实施文本分析的初步策略为:
1. 提供用户管理,系统登录平台,传输所需要处理的文档进行文本转换等预处理操作。
2. 首先进行数据预处理,提取出数据集中所有的中文文本信息,将提取出的信息以UTF-8编码格式整合至txt文本中,然后将待分词txt文本上传至Hadoop平台的HDFS分布式文件系统上。
3. 后端程序创建并提交任务至Hadoop平台,以上传的待分词文本为输入数据,经过分词,词频统计和按词频降序排序步骤将结果输出至HDFS文件系统上。
4.实施文本分析任务,将计算结果处理后进行显示与数据可视化处理。
三、系统实施及数据测试
数据实验语料来源之一为网络下载的金庸小说集文本文件。与此同时,现实中大量的文本信息并非标准化文本文件,本文实验语料之二来源于其他项目研究中获取的贵州省20个极贫乡镇基础教育办公调研收集的1237份(约1G)基层文档数据。借助Python文本数据处理的便利性,如工具包Pdfminer等构建了文本预处理模块,完成了pdf、doc、docx等文件的预处理及数据去噪工作。金庸武侠语料文本文件可直接作为text.input进行上载,基层教育文档则需进行批量预处理转存后作为处理文档进行上载。如由于Word不同版本,要考虑压缩文件,不同后缀.doc及.docx的批量统一转换,以及文档遍历进行内容的格式转换。如图3所示。
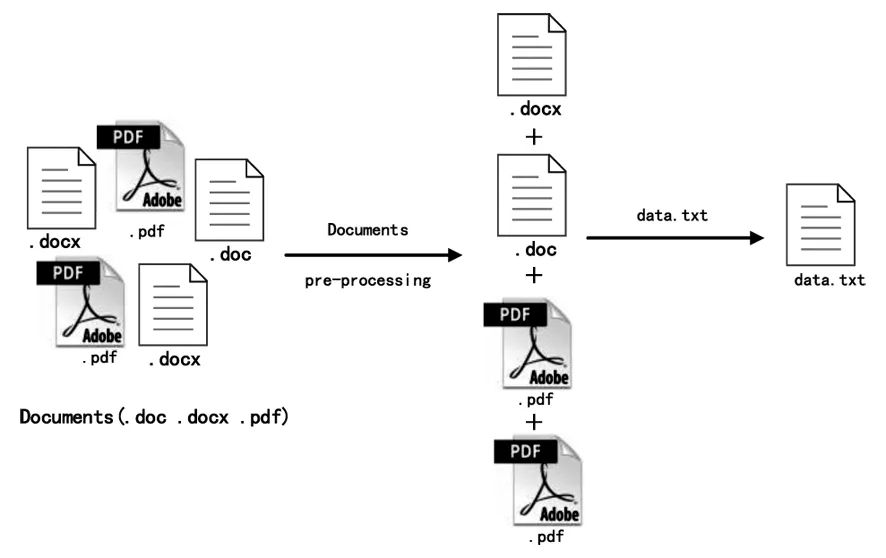
图3 文档预处理
由于Web应用采用了Vue.js构建的数据驱动Web框架,页面显示可由数据进行动态驱动,借助百度开源Echarts中可视化应用,可以提供友好的可视化界面呈现。
语料一分析时长为33.371s,分析结果显示,几大英雄人名占主导地位,如郭靖、黄蓉、欧阳锋和洪七公为出现频次最多的四位,在文中出现次数分别为4993次、3644次、1167次和1059次,而“武功”中以“掌”为重点。
语料二分析时长为32.015s。计算得到基层教育调研文本中词频前十五名词语在文本中出现次数差值并不是特别大。排名前三的依次为学生、教师和学校,分别出现16469次、14634次和12298次,图4显示了收集文档的高频关键词汇。可见极贫地区基础教育文档数据反映学生、教师、学校三者主体地位不言而喻。而排名靠前的教学、活动、教育、工作、学习、课和培训,说明基层教育办公文档核心内容主要围绕教学活动开展及发展。总体文档显示整体基层教育仍然不断在夯实基础上下功夫,相信教育才是我省精准扶贫的长效机制。

图4 高频关键词统计结果
结合词云图分析等文本可视化技术,系统能更直观对信息文本进行直观呈现。而相信引入更精细文本分析是大数据和智能计算的一个关键。
四、结论及展望
综上所述,多学科融合,数据实证研究的兴起,给文本计算提供了很多应用场景,也给计算机应用的集成提供了契机。本文的工作及研究具有很好的应用价值和现实实践意义,具体表现在:
自然语言处理是人工智能皇冠上的宝石,毫无疑问,文本是最便捷和广泛的语言信息载体,日益增长的海量数据中,大量存在非结构化文本数据。因此,基于Hadoop构建一个文本分析系统具有很好的现实意义,而文本分词和词频统计是文本分析中最基础和重要的环节,借助MapReduce并行计算模型实现分布式、并行运算可大大提升计算效率,增强文本处理的能力。
整合了文档预处理及中文分词和词频统计,可视化呈现,为中文信息处理提供了一个基础的信息处理流程的Web应用,借助Spring Boot进行系统开发,并实施基于node.js的数据驱动UI前端设计,为数据驱动的Web应用提供了一个很好的案例实践。
在现阶段实践的基础上,还有以下两个方面的工作需做更进一步的探索:
1.集群规模及效率
本系统基于三台CentOS系统的虚拟机进行三个节点的Hadoop分布式集群搭建,集群处理数据能力有限,在今后研究中,集群节点扩大,集群性能优化,集群运行效率及稳定性等方面还有待于结合理论做进一步实践。
2.中文信息表示及分析
由于中文信息缺乏形态变换,语言具有模糊性,歧义性等特点,且其形态在语素、词、短语、句子、段落、篇章整体的切分及对应的语义变换上存在固有的不确定性。因此,系统在后续的数据处理、语义表示及数据呈现上将进行更多的文本分析探索和实践,相关研究将做进一步的系统集成。从语言和领域知识角度探讨语义关系将需要进一步研究[12-13]。
当前大规模语言预训练模型如BERT, ERNIE,XLNet等得到了广泛的关注和应用,与此同时,随着自然语言处理技术的发展和行业融合,结合领域知识,文本挖掘将为各领域数据处理带来更多新的发展机遇和挑战[14-15]。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
电脑爱好者(2017年7期)2017-05-06
读者·校园版(2015年7期)2015-05-14
