
基于Solr的标准信息检索技术及其优化
2020-04-08 08:18于晓明史胜楠甘克勤
科学技术与工程 2020年4期
于晓明, 史胜楠, 甘克勤
(1.陕西科技大学电子信息与人工智能学院, 西安 710021; 2.中国标准化研究院, 北京 100191)
标准是通过标准化活动,按照规定的程序经协商一致制定,为各种活动或其结果提供规则、指南或特性,供共同使用和重复使用的文件[1]。标准信息检索语言、检索方法、检索途径、检索工具等具有专有性。汤悦荣等[2]提出了相似度计算的方法应用于标准检索,该方法降低了检索对客户的要求;陈强[3]提出了基于Java语言开发,使用正则表达式分析用户输入并构建查询语句从而得出检索结果,这一方法提高了系统易用性;目前对标准信息资源检索开发的网站有很多,荣鼎慧等[4]统计出检索平台有60余个,例如:国际、各国标准化组织机构网站、商业性数据库开发商网站、标准文献研究机构、出版机构等;刘佳等[5]对主要的国际标准检索平台进行了调研和分析,发现了其中的不足。这些方法或网站中均存在检索结果不准确、不全面、效率低的问题。
因此对标准信息的检索进行研究,通过对理论研究和应用实践,利用现有标准文献资源,实现一个对标准号、关键词进行检索的系统,提高对标准文献信息的利用率,加强标准文献信息资源服务能力。将Solr(search on lucene replication)搜索引擎技术应用在标准号和关键词的检索,在文献[6-10]中的通用Solr数据检索技术的基础上,针对标准信息的独特性进行优化,针对标准号的特殊性进行专门分析和处理,并针对标准特有的关键词和标准之间的关联关系做好充分的数据准备从而达到更好的检索效果,优化标准信息检索业务系统。同时通过对Solr技术在标准领域的应用,能够促进Solr开源技术的发展。
1 关键技术
1.1 Solr搜索引擎
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。通过对Solr进行简单合适的配置,有些情况下可能还需要进行编码,Solr可以查阅和使用创建在其他Lucene应用程序中的索引。可以使用Solr的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。不仅限于搜索,Solr也可用于储存。像其他NoSQL数据库一样,它是一种非关系数据储存和处理技术。
1.2 SSM框架
文献[11-13]中提出的SSM框架,是Spring+Spring MVC+MyBatis的缩写,这个框架是在SSH框架之后流行起来的,而且是现阶段比较广泛使用的Java EE企业级应用框架,它方便用在构建各种大型的企业级的应用系统中。
1.3 MMSeg4j中文分词器
mmseg4j 是用Chih-Hao Tsai 的MMSeg算法来实现的中文分词器,并实现了 lucene的analyzer和solr的TokenizerFactory以方便在Lucene和Solr中使用。mmseg4j 的词库的格式是utf-8,因为utf-8格式的文件有带与不带BOM之分,建议词库第一行为空行或为无BOM格式的utf-8文件;霍庆等[14]研究表明:MMSeg算法包括两种分词方法:Simple和Complex,它们都是根据正向最大匹配法实现,Complex增加了四个过滤的规则,并且mmseg4j已经实现了这两种分词算法。
2 优化设计
2.1 词表和分词优化
由于标准本身的特殊性,每个标准文件都会产生不同的关键词,标准间关联关系更是错综复杂,为了满足不同用户的需求,将标准的不同属性取出来分析,做成与标准相关的数据表,项目所需的原始数据表都存储在Oracle中,参看文献[15-16],将这些数据映射导入进Solr中,一共创建了18个实例,数据主表,国际、国外分类表,代替、被代替关系表,引用、被引用、关系表,采用、被采用关系表,热词表,同分类下其他关系表,提示词表,国家表等。每一个关键词都代表着一个标准的使用范围,标准和关键词之间的关系是多对多,数据库的存储方式导致关键词数据无法在实际中应用起来,经过对多个用户和Solr检索机制调研最终形成关键词提示表。提示词表中融合标准相关的多方面属性词,其中包括关键词、主题词、中国标准分类法、国际标准分类法、标准起草单位和标准指标等,分别给予不同关系属性不同的优先级,这样就可以在检索效果中的符合更大范围客户的使用,使标准检索做到了真正的“一键搜”。下面用标准关键词为例做分析创建关键词表的SQL语句如图1所示。

图1 关键词表的创建Fig.1 Keyword table creation
因为Solr是一个开源的搜索平台,主要功能就是把用户输入的搜索信息分类汇总并进行数据库的查询,而中文众所周知语义比较复杂,而且中文所占的字节和英文也有所不同,所以就出现了中文分词器,实现模拟中文语义对数据进行分词衍化。默认Solr提供的分词组件对中文的支持是不友好的,它把每一个词都分开了,而且不能扩展用户词库,可以想象如果一篇文章这样分词的搜索的体验效果非常差。因此引入Mmseg4j中文分词组件优化中文分词的准确率。下载解压,提取其中的三个文件:
mmseg4j-analysis-1.9.1.jarmmseg4j-core-1.9.1.jar,mmseg4j-solr-1.9.1.jar。放到项目WEB-INFlib,修改配置文件schema.xml,添加下面的代码:
配置完成后,重新启动Solr服务,进入管理界面Analysis查看分词效果。
2.2 标准号拆分优化
标准号是由标准代号+专业类号+顺序号+年代号组成,例如:GB/T 1.1—2009。通过用户输入的检索内容对其进行拆分:①首先根据输入是否含有数字判断是否为标准号检索,否则为关键词检索;②截取第一个数字前的字符串,从而获得标准代号;③截取最后一“-”或“:”之后的数字获得年代号;④截取代号和年代号中间部分,以“.”分隔,分别获取专业类号和顺序号。
用户输入时对其进行正确提示,显示相应提示词,输入会有以下几种情况:①Query=gb的情况,会查询含有标准代号的Solr实例,返回各种相近的标准代号;②Query=gb1的情况,会拆为gb 和1,分别对应标准代号和专业类号,标准代号会查询只含有标准代号的solr实例表,返回一个与其相近的标准代号集合,将该集合中的标准代号分别与专业类号1进行精准匹配,再对专业类号加上“.”进行模糊匹配,再加上“-”进行模糊匹配。返回的是所有相似的标准代号与专业类号进行精准的“.”模糊“-”模糊后的集合;③Query=1(数字)的情况,会将1当做专业类号进行向右模糊查询;④Query=GB/T 1.1—2009的情况,会将完全命中该标准号的标准返回。
通过以上对标准号的拆分和对用户输入进行正确提示使得标准号的检索结果更加准确。
2.3 排序优化
对于标准的检索结果,一个好的排序优化方式往往会给到用户更好的体验,标准的更新作废周期是十分快速的,然而作废的标准依然有着它不可代替的历史作用。而对于大众来说现行标准是第一选择对象,因此把现行标准作为默认检索结果。
由于标准号组成的特殊性,不同检索结果就会出现多种排序方式,甚至对于标准号的检索和中文词的检索排序也大不相同,下面就简单介绍对于标准检索结果的排序优化方式: 标准号的组成由标准代号+专业类号+顺序号+年代号,这也就给予了标准三种不同的排序方式。根据标准号的特殊性在数据库中单独建立发布单位字典表以及赋予发布单位不同的优先级,然后在主表中引进排序码字段,有效的解决Oracle中数字排序的问题,在主表中单独取出一个字段将年代分离出来以便使用发布单位的排序。在实际操作中,依照不同的检索方式配合不同的结果排序方法,使检索效果更上一层楼。
中文词的检索排序和标准号检索之间也存在的较大的差异,这里应用权重的方法来排序。标准存在多个用来检索的中文字段,每当输入的中文词在不同的字段中命中一次给予一个加权值,如下代码所示:
parameters.set(″qf″,″a298_c^1.4 a835KEY_c^0.8 a104CN_c^0.8 a825CN_s^0.6 a826CN_s^0.6 a330_c^2″);
按照最后检索完成的权数来进行排序,更加准确地获取用户想要的检索结果。
3 系统实现
系统项目框架采用SSM(Spring+Spring MVC+My Batis)框架,数据库为Oracle,并结合使用Solr搜索引擎技术。系统体系架构图如图2所示。

图2 系统体系架构图Fig.2 System architecture diagram
整个系统前端采用Java语言编写,页面布局简洁清晰,左边可以选择要查询标准的国别或者分类号,右边上部分为检索框和检索按钮,下部分展示将要实施的标准信息。在搜索框用户可输入标准号或关键词进行检索,同时可提示用户进行正确输入。标准检索首页如图3所示。

图3 检索系统首页Fig.3 Search system homepage
4 实验效果对比
对优化前后系统分别输入“gb1”进行检索,优化前检索结果有11 641条记录,结果只有一条记录符合检索词: 标准代号为gb开头向右模糊,专业类号仅为1,其他结果均为开头为1的专业类号。优化后的检索结果有2条记录,结果精确符合输入的标准代号向右模糊和专业类号为“1”,检索结果准确,使得用户对检索效果更加满意。如图4、图5所示。
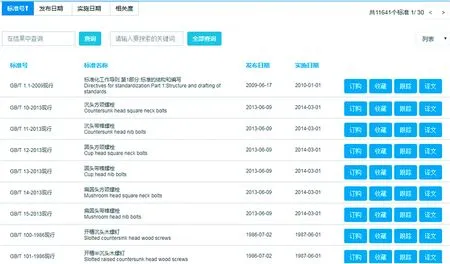
图4 优化前检索结果Fig.4 Pre-optimization search result

图5 优化后检索结果Fig.5 Optimized search result
5 结论
通过对Solr搜索引擎技术的研究和使用,在通用Solr整合SSM框架项目基础上,针对标准信息这一特定领域,对其中的关键词和标准号切分、检索结果排序和主题词表进行了优化设计,来完成基于Solr的标准号和关键词检索系统,经过测试使用,大大提高了检索结果准确性和检索效率,用户体验实现了良好的效果。系统的实现,对标准文献资源的利用和服务方面具有一定的实用价值,证明了Solr搜索引擎技术的实用性,同时,这项技术在标准领域的应用也能够促进该技术日后的发展。
猜你喜欢
中兽医学杂志(2022年9期)2022-12-18
名家名作(2021年4期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
小哥白尼(军事科学)(2020年10期)2021-01-18
趣味(数学)(2020年3期)2020-07-27
小学生作文辅导·中旬刊(2020年6期)2020-07-24
科普童话·学霸日记(2020年1期)2020-05-08
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小天使·一年级语数英综合(2019年2期)2019-01-10
