
基于教与学优化改进的近邻传播聚类算法①
2020-05-22 04:47马翩翩张新刚梁晶晶
计算机系统应用 2020年5期
马翩翩,张新刚,梁晶晶
(南阳师范学院 计算机与信息技术学院,南阳 473061)
近邻传播聚类算法是2007 由Frey BJ 和Dueck D提出的一种新型的发展较快的聚类算法[1],与K-means算法相比它把所有的数据点作为潜在的簇中心,通过消息传递不停迭代进而确定最终的簇中心.该算法对点与点之间的相似性没有绝对的要求,可以根据具体的应用来选择对应的相似性度量方法,相似性的值可以是正的或负的,也可以是非对称的.该算法已经被广泛应用在数据流聚类、图像处理、文本聚类、基因序列等领域[2–5].但是该算法在实际应用中也有一定的局限性:1)该算法属于无监督聚类,不能利用已有的标记信息来进行聚类;2)偏向参数的取值对最终簇的结果有较大的影响,取值过大,最终划分的簇集偏多,取值过小,最终簇的集合偏小;3)对形状复杂的数据集的聚类效果不佳、时间复杂度较高.
针对以上问题,不同的学者从不同的角度进行了改进.为了利用已有的标记信息,文献[6]根据半监督聚类的思想,使用少量已知的标签数据和成对点约束对数据集形成的相似度矩阵进行调整,进而达到提高AP 算法的聚类性能;文献[7]在半监督聚类的基础上利用惩罚参数添加软约束来调整相似性度量,从而提高聚类质量.为了克服预设偏向参数和阻尼系数对聚类结果的影响,有学者利用群体智能优化算法对偏向参数和阻尼系数寻优:文献[8]提出了将偏向参数和阻尼系数作为粒子群算法中的粒子,使用粒子群算法对系数寻优,从而提高聚类质量;为了寻找较优的偏向参数值,文献[9]通过改进的布谷鸟搜索对偏向参数和阻尼系数进行调整,从而提高聚类效果;文献[10]使用量子优化中量子叠加态和旋转门对偏向参数编码和寻优以提高AP 算法聚类的精确度和时间.为了处理复杂形状的数据集:文献[11]通过对数据集构建概率图模型,分析数据集的概率密度,并将其注入偏向参数进而进行近邻传播聚类;文献[12]提出了一种基于全局核与高斯核的混合核函数的相似性度量,增强了泛化能力,从而提高了提高聚类质量;文献[13]在密度分布的基础上,利用最近邻搜索的方法进行相似性度量来对球面和非球面分布的数据进行聚类.也有学者使用其他方法来对近邻传播聚类进行改进,文献[14]使用迁移思想,在综合考虑源数据域和目标数据域的数据特性及几何特征的基础上改进AP 算法中的消息传递机制提高聚类效果;文献[15]提出了一种进化亲和传播聚类方法,考虑潜在的动态和保存时间平滑性同时对多个时间点收集的数据进行聚类.本文则使用教与学的群体智能优化算法来对近邻传播聚类算法中的偏向参数和阻尼因子寻优,进而提高聚类质量.
1 教与学的自适应近邻传播聚类
1.1 教与学优化算法
教与学优化算法(Teaching Learning-Based Optimization algorithms,TLBO)是由Rao RV 等[16]于2010年提出的新的群体智能优化算法,具有简单、无参、快速收敛、易于实现等特点.它被广泛应用在机电工程、结构优化、模式识别、图片处理、人工神经网络等领域.
该算法模拟一个班级的教师与学生的学习过程.其中班级相当于智能优化算法中的种群,教师和学生相当于种群中的个体,所学科目为智能优化算法中的变量,各科成绩为目标函数的适应度值,全局最优即为目标函数的极值.假设最优化问题用式z=maxF(x)表示,则X=(x1,x2,···,xi,···,xd)表示自变量,对应学生个体;Xi表示任意一个决策变量,对应学生的某一个科目;d表示决策变量的维度,对应学生所学科目数;S={X|XiL≤Xi≤XiH}表示有个体构成的种群,即由学生构成的班级;其中XiL和XiH分别代表个体Xi的下界和上界.
教师是从学生种群中选取出来的最优秀个体,即z=argmaxF(x).为了找到在决策空间中的目标函数极值,需要经历两个阶段.(1)教学阶段.该阶段主要借鉴在学习场景中教师是最优学习者,其他学生在教师的教授下得到进步,所以首先找到在该次迭代中的最优学习者即具有最优目标函数值的参数作为教师,其他参数向此轮最优参数学习;(2)学习阶段.该阶段主要借鉴于学生与学生之间互相学学习的场景,从众多参数中随机选取和自己相异的参数进行学习,以改变自己的参数从而提高目标函数值.
1.1.1 教师阶段
在此阶段,在整个搜索空间中随机生成解.最优函数值将在所有随机生成解中进行选择,并把最优搜索解称为教师Xteacher,而教师通过教授学生Xi,从而提高群体的整体知识水平,使平均成绩得到一定提高.具体如式(1)、式(2)所示:
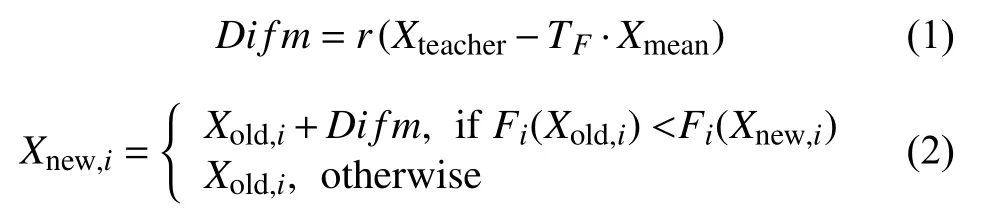
其中,Xmean代表的是整群体的平均水平,而老师讲授知识,学生接受新知识的过程是一个随机的过程,具体学习效果取决于学习补长r和教学因子TF,r为取值范围为[0,1]的随机数,TF=roud[1+rand(0,1)].式(2)中Xnew,i代表的是第i个学生学习之后的知识水平,Xold,i代表的是学习前的知识水平,知识水平是否得到提升取决于个体的目标函数是否朝着优化方向前进.
1.1.2 学生阶段
如上所述,根据教与学的过程,学生可以学习知识;通过学生之间的互动,学生也可以增加他们的知识.因此,一个搜索空间中的解(学生Xi)与总体中的其他解(学生Xj)随机互动,肯定有一方会学到新的东西.如果Xi优于Xj,则Xj将向Xi移动,如式(3)所示;反之Xi将向X移动,如式(4)所示.具体描述如下:

1.2 近邻传播聚类算法
聚类算法是寻找数据内在特征的一种划分过程.在一组含有N个样本D={x1,x2,···,xi,···,xN},维度为d,xid={xi1,xi2,···,xid}的数据集中,聚类算法是将样本数据集划分为k个不相交的簇{Cl|l=1,2,···,k}其中CL’∩L’≠LCL=ϕ且D=∪l=1k.近邻传播是近年来发展较快的聚类算法,它按照聚类定义找出簇中心,使簇内距离最小.
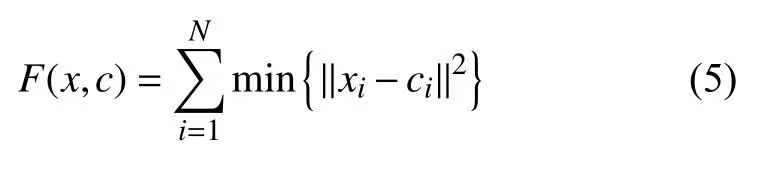
其中,i=1,···,k,代表该聚类结果中有k个簇.Ci为簇中心,Ci≠ϕ,且Ci∩Cj=ϕ.
在近邻传播聚类算法执行过程中需输入任意两点i和k之间的相似性s(i,k)所构造的相似度矩阵,默认为负的欧式距离,即s(i,k)=–||xi–xk||2;设定自相似性s(k,k)又叫偏向参数p,因为近邻传播聚类算法不需要指定簇的个数,而是通过参数p来影响最终的簇个数.
其次近邻传播聚类算法的聚类过程是点与点之间的消息传递来实现的.信息有两类,吸引度r(i,k)和归属度a(i,k).r(i,k)代表的是从簇成员i发送到簇中心k的消息,表示数据点i作为以k为簇中心的簇成员的度量;a(i,k)代表的是从簇中心k发送到簇成员i的消息,表示数据点k作为数据点i的簇中心的度量;结合归属度和吸引度,对于数据点i,找到使a(i,k)+r(i,k)达到最大化值的k时,如果k=i,则点k为簇中心;如果k≠i时,则表示数据点k作为数据点i的簇中心.初始时r(i,k)=0,a(i,k)=0;当循环终止时寻找(diag(A)+diag(R))>0 的点k作为簇中心.r(i,k)和a(i.k)更新公式如下:
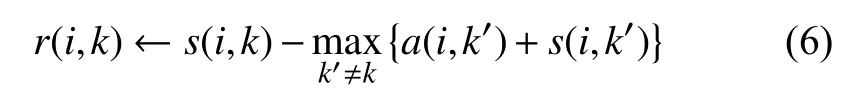
如果i=k,则:

如果i=k,则:

根据式(8)可知归属度a(i,k)被设置为吸引度r(k,k)加上潜在簇中心k从其他点获得吸引度的总和,而且只添加传入吸引度为正值的那一部分,再次验证了一个好的簇中心只需要表明他很适合作为一些数据点的簇中心即可(所以只添加正值的吸引度),而不管他多么不适合做为其他点的簇中心 (负值的吸引度).如果自吸引度r(k,k)是负的,则表明点k不适合做为簇中心;如果r(i,k)为正值,那么a(i,k)也会增加.为了限制强势吸引度r(i,k)的影响,对总和进行阈值,使其不能超过零.
根据近邻传播聚类算法的消息传递过程可知,在迭代过程中,当一些点被分配到合适的簇中心时,它们的归属度a(i,k)如式(8)所示将会降到0 及其以下.根据式(6)可知这些负归属度可减少一些输入相似性s(i,k)的有效值,从而从竞争中删除相应的候选范例.在式(7)中如果i=k时,吸引度r(k,k)的值为s(k,k)减去点i和所有其他候选簇中心之间的相似性的最大值,这种“自我吸引”即偏向参数p反映了在聚类迭代过程中k点是否适合做为一个簇中心,即偏向参数p的设定会影响最终的聚类效果.较高的偏向参数值表示成为簇中心的点较多,结果导致划分的簇集较多;较低的偏向参数值代表成为簇中心的点较少,结果导致划分的簇偏少.
同时在更消息更新过程中,为避免在某些情况下出现振荡,需对消息即吸引度和归属度进行阻尼.具体如下所示:
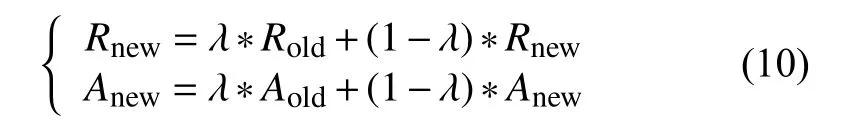
1.3 基于教与学优化的近邻传播聚类
教与学优化的近邻传播聚类(TLBOAP)是一种基于AP 的改进聚类方法,是在计算目标函数过程中进行近邻传播聚类,即通过群体智能优化中的教与学优化算法来寻找最优偏向参数p从而提高AP 的聚类效果,同时该算法在聚类过程中会调整阻尼因子λ防止发生震荡.算法1 为基于TLBO 的AP 算法.

算法1.TLBOAP 算法1)加载数据集.2)对数据集进行归一化处理.算法种群规模为n,对应数据集中样本个数,决策变量为偏向参数p,最大迭代次数为Tmax.3)采用负的欧式距离建立相似度矩阵S.4)根据式(6)~(9)执行近邻传播聚类,同时根据聚类目标函数(5)计算目标函数值.

?
在步骤2)中为了提高教与学寻找最优参数的效率,需指定参数p的搜索空间.在文献[17]中验证了当p的上限取值为pm/2;文献[18]中根据净相似度来求出p值的下限p=dpsim1-dpsim2.净相似性指的是数据集中任一点和它所对应的簇中心的相似性之和.式(11)中dpsim1 代表的是聚类后簇个数为1 的的净相似度值,
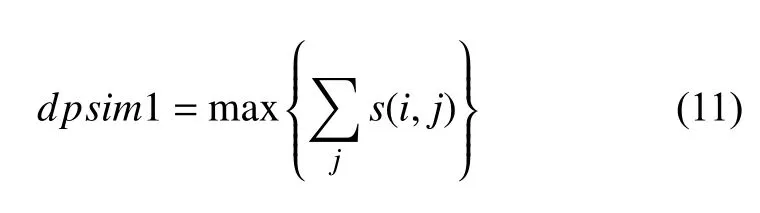
式(12)中dpsim2 代表的是聚类后簇个数为2 的的净相似度值.
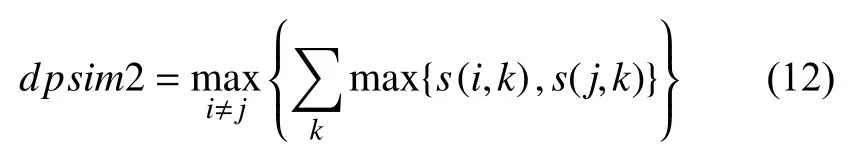
在步骤4)进行近邻传播聚类过程中,通过监控窗口的设置监控震荡.设置监控窗口大小为v=40,如果窗口中长度有三分之二簇个数不断发生变化,则认为发生震荡,此时以步长0.05 的速度调整阻尼因子λ的值,λ默认值为0.5,同时阻尼因子λ有上限,需小于1.因为当阻尼因子过大时,会导致聚类速度过慢.
2 实验与分析
为了验证TLBOAP 算法的聚类效率,在内存4 GB、处理器为Intel(R)Core(TM)i7—7700Q、Windows7 64 位的计算机上用Matlab R2012a 来实现.已在6 个UCI 数据集上进行了测试,具体数据集如表1所示.

表1 数据集性质
实验中最大迭代次数为5000,连续收敛次数为50.将本文算法与原AP 算法、自适应AAP 从簇的个数、准确率、正则化信息、芮氏指标、时间等方面对聚类结果进行评估.
1)准确率(ACC)
准确率代表的是聚类正确的样本数占总样本数的比例.

其中,k为聚类后所得簇的个数,Li为第i个簇中聚类正确的样本个数,是一个直观的度量指标.
2)正则化互信息(NMI)
正则化信息表示的是聚类后簇个数与真实簇之间的关联程度,指标范围为[0,1].越接近1,表示关联程度越高,聚类效果越好.
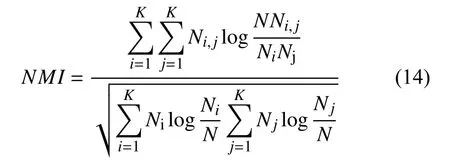
其中,K为聚类后所得簇的个数;N为样本总数;Ni、Nj表示第i、j簇中样本数目;Nij表示样本在第i个簇中但属于第j个簇的数目.
3)Rand 指数(RI)
Rand 指数是聚类性能度量中将聚类结果与外部“某个参考模型”相对比的外部指标.

其中,聚类结果用C={Cl|l=1,2,···,k}表示,外部参考模型用C*={C*l|l=1,2,···,s}表示.其中a表示在C中隶属于同一簇且在C*中也隶属于同一簇的样本数;b表示在C中隶属于同一簇但在C*属于不簇的样本数;c表示在C属于不同簇但在C*隶属于同一簇的样本数;d表示在C中不属于同一簇且在C*中也不属于同一簇的样本数.是在簇Cl和C*不明确簇的对应情况下的聚类结果度量.
在近邻传播聚类过程中,由于偏向参数p的取值不同,产生的簇数目也不同.对于原始近邻传播聚类算法AP,p初始值默认为相似矩阵的均值,在传递过程中不发生改变;对于AAP 算法来说,主要通过调节阻尼系数λ 进而调节偏向参数p,相较于原始近邻传播算法来说,侧重点在于防止发生震荡,而不在于寻找最优参数;而在本文中所提到的TLBOAP 算法,侧重点在于通过群体智能优化算法教与学对方法在聚类过程中寻找最优偏向参数.
由表2可知在AP、AAP 方法中产生的簇较多,而TLBOAP 在多数数据集中产生的正确个数的簇,当维数过高时产生的簇的数目会多于实际产生的数目,但是较AP、AAP 方法来说产生的簇数目还是更接近真实簇数目.
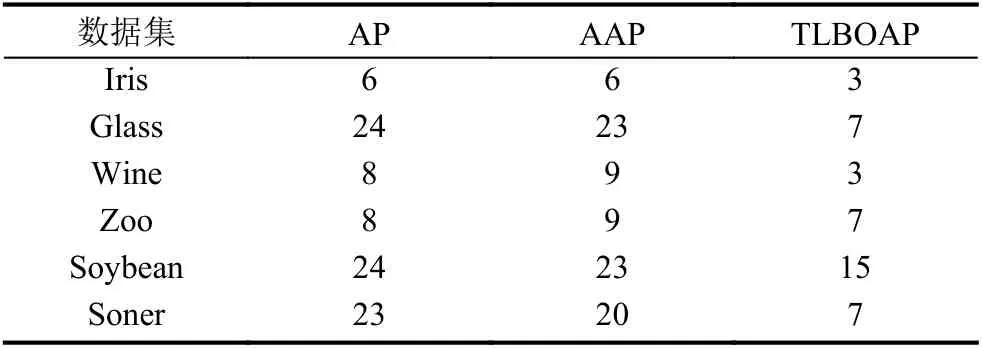
表2 簇个数
偏向参数p值的选择不但会影响簇中心的多少,也会确定最终的簇中心,簇中心的确定会影响最终簇聚类的质量.原始近邻传播聚类算法AP,偏向参数p值固定且不变;对于AAP 算法来说,为调整阻尼系数的基础上以固定步长调整偏向参数;TLBOAP 算法,则通过教与学优化算法在有限有空间中寻找最优偏向参数p,所以会导致聚类性能指标差别也较大.
表3中的Iris 数据集是聚类分析最常用的数据集,有150 个样本,3 个类簇.本文TLBOAP 算法能达到0.9457 的聚类准确率,相较于AP 算法、AAP 算法ACC指标分别提升43.44%,71.10%;TLBOAP 算法对Iris 数据集聚类结果的NMI和RI评价指标也优于AP、APP 算法,NMI指标为0.8322,较AP、AAP 算法分别提升了20.61%、34.74%;RI指标为0.9341,较AP、AAP 算法分别提升了10.92%、15.12%.

表3 各聚类算法ACC、NMI 和RI 聚类评价指标比较
在含有178 个样本,3 个类簇,13 个特征的数据集Wine 中,本文TLBOAP 算法能达到0.7427 的聚类准确率,相较于AP 算法、AAP 算法ACC指标分别提升1.04 倍,1.18 倍;NMI指标中分别提升了29.12%、21.92%;在RI指标上分别提升了6.09%、6.33%
在高维特征的数据集中Zoo、Sonar 为例,虽然在NMI、RI指标上基本持平,但是在ACC指标上有较大提升.在Zoo 数据集中,ACC指标较AP 算法、APP 算法均提升了14.94%;在Sonar 数据集中,ACC指标较AP 算法、APP 算法分别提升了1.64 倍、88.47%.
总之,在度量聚类效果时,要进行整体考虑,因为不同的指标方法不同,侧重点也不同.由表3可知,在6 个UCI 数据集中,本文中的TLBOAP 算法聚类效果整体上均优于AP 算法、AAP 算法.
原始近邻传播聚类算法AP 因为偏向参数p取值较大,所以收敛速度慢;自适应AAP 算法,因为迭代过程中需要针对每次阻尼因子的取值调整偏向参数p值,然后在该偏向参数p值下再次循环调整阻尼因子;TLBOAP 算法,因为教与学优化算法无参数,鲁棒性强,所以在有限有空间中寻找偏向参数p值较快.
由表4可知,本文算法的计算效率优于AP、AAP.在数据集Iris、Glass、Wine、Zoo、Soybean、Sonar 上,TLBOAP 算法的运算速率较AP 算法分别提升了是12.1 倍、6.7 倍、7.7 倍、3.1 倍、9.8 倍、21.2 倍;较AAP 算法分别提升了61.82%、88.67%、33.03%、基本相同、44.95%、18.28%.

表4 运行时间
3 总结
本文依据聚类的度量标准,通过使用群体智能算法中的教与学优化在偏向参数p空间中寻找合适的偏向参数取值,同时通过步长调整来防止震荡,最终确定最终聚类结果.同时和已有的算法AP,AAP 进行了对比试验,在度量指标ACC、NMI、RI 运行时间上均有一定的提高.但是该算法在相似性度量上采用的是欧式距离,对于非凸数据集的聚类有一定的局限性,下一步将结合特征提取工程和核函数来提高聚类质量.
猜你喜欢
材料研究与应用(2022年4期)2022-09-01
动力学与控制学报(2022年4期)2022-08-31
心理学报(2022年7期)2022-07-09
心理学报(2022年1期)2022-01-21
现代英语(2021年18期)2021-11-22
当代陕西(2020年23期)2021-01-07
当代陕西(2019年12期)2019-07-12
振动工程学报(2019年2期)2019-05-13
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
