
一种改进的Faster-RCNN电路板字符检测方法
2020-06-05 12:18吉训生李建明
小型微型计算机系统 2020年6期
吉训生,李建明
(江南大学物联网工程学院,江苏无锡214122)
1 引 言
目前,人工检测与记录电路板上的字符效率较低,通过目标检测技术可以极大地提高检测效率,进而可以实现检测流程的自动化.
字符检测是目标检测[1]的一个重要应用领域.近年来,字符检测常用方法包括:传统图像处理结合浅层机器学习的方法和基于深度学习的目标检测[2].
传统图像处理结合浅层机器学习的过程中,分类训练与提取目标所需特征均为人工设计,依赖于大量的先验知识,且提取出的特征表现力弱,对于具有复杂特征的电路板图像字符检测效果较差.
基于深度学习的方法已成为目标检测的研究热点,应用在目标检测领域里的深度学习方法以卷积神经网络(Convolutional Neural Network,CNN)[3]算法为支撑.相比传统算法,CNN 在对图像的特征学习以及提取具有判别力特征中的表现优异,具有更强的泛化能力和鲁棒性.由CNN 发展而来的目标检测算法包括基于候选区域的方法和基于回归的方法.基于候选区域的方法具有较高的准确率,但检测速度一般,其代表是Shaoqing Ren 等提出的区域卷积神经网络(Region Convolutional Neural Network,RCNN)[4]及其优化算法 Fast-RCNN[5]和 Faster-RCNN[6].Faster-RCNN 由于实现了端对端的训练且检测精度高,被加以改进后运用到各种场景,包括车辆检测、小交通标志区域检测工业场景下中的自然场景文本检测等[7-10],效果比传统检测方法更好.基于回归的方法无需生成候选区域,检测速度快,但精度较低,常用的有YOLO(You Only Look Once)[11]算法和 SSD(Single Shot MultiBox Detector)[12]算法.
由于较差质量电路板图像中的字符难以识别,同时鉴于传统图像处理和基于深度学习方法的适应性、准确性等问题,本文提出一种改进的Faster-RCNN 电路板字符检测方法.为降低漏检率,在区域提议网络RPN(Region Proposal Network)中针对数据集中字符目标的长宽比特点,优化锚框的选取.在感兴趣区域池化层(RoI pooling)上进行改进,融合多分辨率特征,提取更多的候选区域卷积特征,避免目标相互靠近导致漏检和误检.在模型评估阶段,本文将从漏检率、准确率和整张图片识别率3 个指标评估算法性能.
2 Faster-RCNN 检测方法
Faster-RCNN 的模型框架如图1 所示.
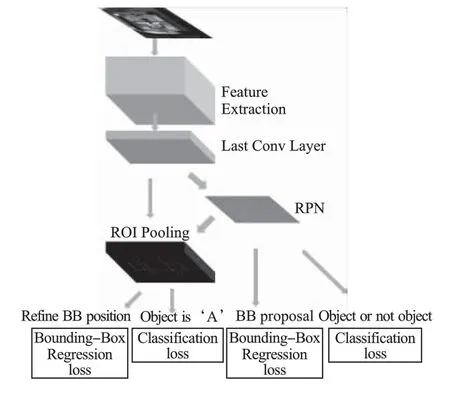
图1 Faster-RCNN 模型Fig.1 Faster-RCNN model
对一张输入图像,首先通过特征提取网络进行特征提取得到特征图,然后检测框的生成采用基于区域提议策略的RPN 网络替代耗时的滑动窗口加图像金字塔[13]与选择性搜索策略[14].在RPN 网络中,将特征提取层的最后一层特征图的每个点前向映射得到k 个锚框,根据IoU 分配正负样本,通常 IoU>0.7 为正样本,IoU<0.3 为负样本,再通过 softmax激活函数判断锚框是前景还是背景,并回归得到正样本与真实框的偏移量与缩放量,接着在ROI Pooling 中,对不同尺寸的正样本目标候选区域所对应的特征图区域进行分块,池化成大小相同的特征图,生成固定维度的特征向量,然后利用softmax 函数判断对应候选区域的目标类别,利用Smooth L1函数优化候选框的位置以标记出图像中的字符.IoU 的计算如式(1)所示:
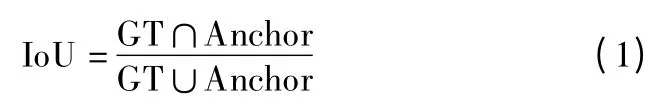
式中 GT 表示真实框,Anchor 表示锚框.Softmax 函数定义如式(2)所示:

Smooth L1 函数定义如式(3)所示.
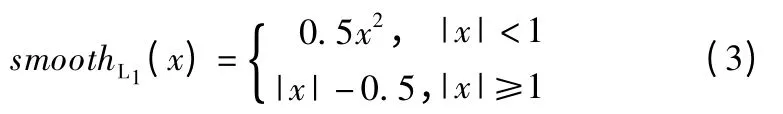
两阶段的Faster-RCNN 根据RPN 的初调和RoI Pooling的全连接层的细调使得字符检测精度较高,但是Faster-RCNN 仅采用特征提取网络的最后一层进行RPN 中产生的提议框的特征选取,虽有效使用深层语义特征,但忽略了电路板字符的浅层位置信息.电路板字符的检测不仅需要字符的精确,无遗漏,更重要的是整张图片的全部字符识别准确,为使字符检测效果更好,对其进行改进.
3 Faster-RCNN 字符检测的改进
Faster-RCNN 电路板字符检测的核心过程就是通过区域提议网络利用锚框拟合真实框,定位包含字符概率更高的若干区域,然后提取这些区域的特征从而检测字符.因此,锚框以及特征选取至关重要.基于此,本文对区域提议网络以及感兴趣区域池化层进行改进.对特征图的提取,VGG-16[15]包含若干卷积层和池化层堆叠,形成较深的网络结构,低层的局部特征由于网络层数的加深聚合成高级特征,更具有表现力,在实验部分,本文将 VGG-16、ResNet-50 和 ResNet-101[16]这 3种特征提取网络进行对比.虽然VGG-16 网络不如残差网络ResNet50 与 ResNet-101 网络深,而且 VGG-16 的参数更多,但是针对该场景下的字符识别,VGG-16 具有更好的效果,因而仍采用VGG16 特征提取网络.
3.1 区域提议网络优化
在Faster-RCNN 算法中,RPN 连接在 VGG16 的卷积层conv_5 后.特征提取网络总共有四个最大值池化层,由于卷积层操作不影响特征尺度,最大值池化层使尺度减半,因此在最后一层特征每个点对应原图像的16×16 的区域.Faster-RCNN 根据Pascal VOC、MS COCO 数据集的目标大小设置了 9 种锚框,分别对应 3 种尺度(8、16、32)和 3 种长宽比(1∶1、1∶2、2∶1),但针对电路板图像数据集,Faster-RCNN 设置的3 种尺度和3 种长宽比显得并不合理.为了加快收敛速度,本文从锚框尺度与长宽比的选择出发,根据电路板图像中字符的长宽比特点,在原来的长宽比不变的情况下,将锚框的尺度修改为(4、8、16),则对应原图的面积是(642、1282、2562).
3.2 多分辨率特征融合
在Faster-RCNN 算法的感兴趣区域池化层中,将RPN 生成的提议框从输入图像的坐标映射到conv_5,然后将提取到的对应区域水平方向和竖直方向各分成7 等份,对每份进行最大值池化,得到7×7×512 固定大小的结果.conv_5 卷积层虽具有高级语义信息,但特征图的分辨率低,conv_3 卷积层分辨率高且具有细节位置信息,若只在conv_5 层特征图上提取提议框的特征,必然会浪费conv_3 浅层特征图中的高分辨率特征.因此,本文根据conv_5 和conv_3 卷积层提取得到特征的特点,对原感兴趣区域池化层进行改进.首先对conv_5和conv_3 分别进行感兴趣区域池化,分别得到7×7×512 和7×7×256 大小的特征图,将两个特征图在维度上进行拼接,得到7×7×768 大小的特征图,再用1×1 的卷积核对拼接得到的特征图进行卷积操作,最后与全连接层连接.多分辨率特征融合的改进Faster-RCNN 网络模型如图2 所示.
Concat 特征融合实现了维度数上的叠加,对叠加的特征图进行卷积操作实现特征融合,另一种比较常见的是ResNet中的add 特征融合,该方式是通过对应特征图的相加,增加每一维度下的信息量,再进行下一步卷积操作.Concat 和add 如图3 所示.
Concat 和add 的卷积公式如式(4)、式(5)所示.
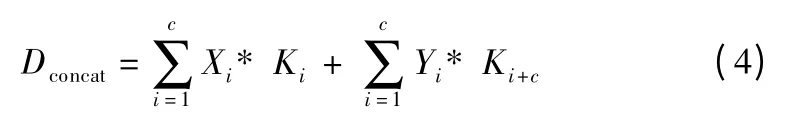
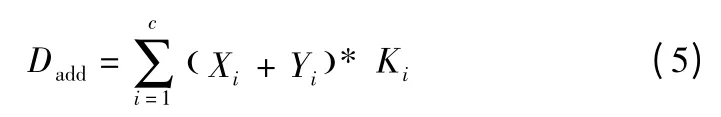
式中,Dconcat与Dadd表示单个输出通道,Xi与Yi表示输入通道,Ki表示对应通道的卷积核.

图2 多分辨率特征融合的改进Faster-RCNN 网络模型Fig.2 An improved Faster-RCNN network model for multiresolution feature fusion
可以看出,add 特征融合共享卷积,具有更少的参数量和计算量.但是concat 维度上的增加不仅可以减轻梯度消失、加强特征传递,而且能够实现特征重用.在实验部分本文对add特征融合和concat 融合进行了实验比较,由于concat 特征融合的效果更好,因此在感兴趣区域特征融合部分采用concat.
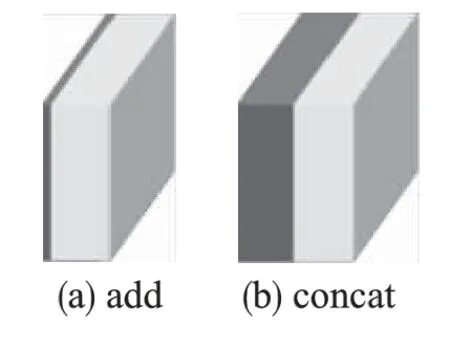
图3 特征融合Fig.3 Feature fusion
本文的方法将多通道卷积层感兴趣区域池化,通过concat 拼接,在特征通道维度上对特征图进行相加,再对拼接特征图进行same 卷积,该卷积不仅融合了拼接特征,结合了高层语义信息与浅层细节位置信息,而且卷积后特征图的大小不会发生改变,更好地保存了特征信息.相较于原始Faster-RCNN,本文从多分辨率角度进行特征提取与学习,可以聚集多层信息,更好地辅助类别判别与边框回归.
4 实验结果与分析
本文实验硬件平台和参数如下:Windows64 位系统,32GB 内存,Inteli7-7700 3.60GHz 处理器,GTX1080 8G 显卡,使用深度学习框架Tensorflow 结合CUDA8.0 和CUDNN5.0,代码运行环境为Python3.6,迭代步数40000,学习率learning rate 为 0.001,动量 decay 为 0.0005,学习率衰减系数 gamma为0.1,学习率衰减步数为30000.
4.1 电路板图像数据集与评价指标
实验中使用的电路板图像来自现场收集,整个数据集共包含2191 张图片,选择其中的1576 张作为训练集,395 张作为验证集,剩余的220 张图片作为测试集.对图片左右翻转,将训练集与验证集图片扩充至3152 张和790 张.图片中包含28 类字符,分别为 0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F、H、I、J、K、L、N、U、V、W、X、Y、Z,人工标注完字符边框后,将数据集转化为PASCAL VOC 的格式进行训练.
本文采用漏检率(Omission Ratio,OR)和精确率(Precision,PR)评估上述模型性能.除此之外,针对实际应用场景,本文设计新的评价指标:整张图片识别率(Total Image Identification Rate,TIIR).漏检率、精确率和整张图片识别率的公式如式(6)、式(7)和式(8)所示.
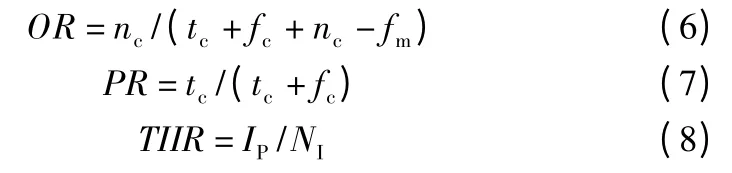
式中,tc表示正确检测相应字符的个数,fc表示错误检测相应字符的个数,fm表示非字符检测成字符的个数,nc表示未被框选出来的字符个数,IP表示完全正确检测的图片,NI表示图片总数.
4.2 不同特征提取网络实验对比
为了选取适合的特征提取网络,本实验在Faster-RCNN模的基础上,分别对 VGG-16、ResNet-50 和 ResNet-101 三种特征提取网络进行模型的训练.随着模型迭代次数的增加,不同特征提取网络在模型中的损失曲线对比情况如图4 所示.显然,基于VGG-16 的Faster-RCNN 收敛速度更快.
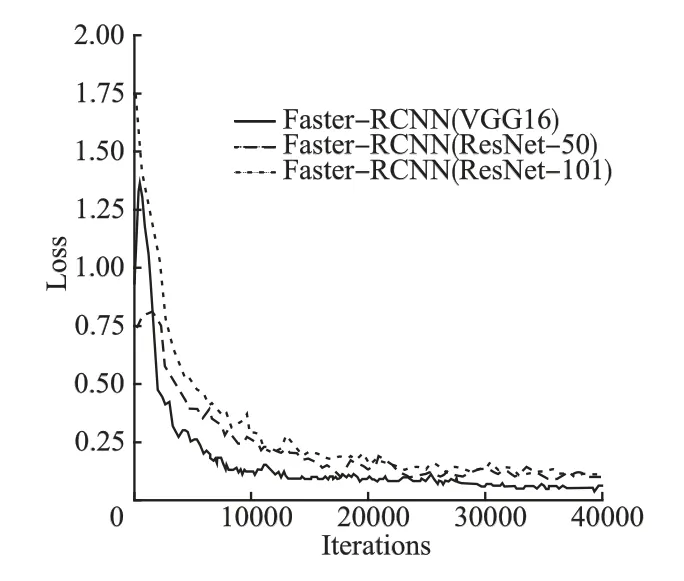
图4 不同特征提取网络的Faster-RCNN 模型整体损失对比Fig.4 Comparison of overall loss of Faster-RCNN models with different feature extraction networks
由于残差网络ResNet-50 和ResNet-101 网络更深,因此需要的迭代次数更多,训练时间更长,本实验还对比训练了100000 次迭代的残差网络(ResNet-50 和ResNet-101 在迭代次数为100000 次时均已收敛).实验结果对比如表1 所示.
从表1 中可以看出,更深的网络反而导致了性能的下降.相比较于另外两个特征提取网络而言,基于VGG-16 的Faster-RCNN 表现出优异的性能,在本文后面的实验中均采用VGG-16 特征提取网络.

表1 特征提取网络实验对比Table 1 Experimental comparison of feature extraction networks
4.3 改变锚框尺度实验对比
通过对数据集中3152 张图片字符的长宽比特征进行统计,有针对性地修改锚框的尺度.在长宽比为(0.5,1,2)的基础上,将锚框的尺度比例修改为(4、8、16),因为 conv_5 每个点在原图上的感受野是162,最终在原图上对应的三种面积是(642、1282、2562).
本节在不同锚框尺度下进行对比实验,实验结果如表2所示.

表2 改变锚框尺度实验对比Table 2 Experimental comparison of changing anchor scale
由表2 可见,修改后的锚框尺度,漏检率有所下降,但误检率和整张图片识别率变差.可以看出,改变后的锚框更加适用于此数据集,可以检测到更多的字符目标,但由于字符的质量问题以及获取图片的环境问题使得获取到的特征不足以正确检测,本文在改进锚框的基础上进行了特征融合,可以将修改锚框尺度的模型在测试集上漏检率降低到2.19%,精确率为98.19%,整张图片识别率为85.00%.
4.4 不同超参数的改进网络实验对比
实验过程中的一些超参数,比如:置信度阈值(conf_thresh)、非极大抑制阈值(nms_thresh),这些参数对实验结果均有影响.因此,进行了多次对比实验以确定最优参数配置.
非极大抑制在检测部分起着过滤多余窗口、提升准确率的作用,而非极大抑制的前提是设置阈值获取目标框的置信度得分列表.因此,置信度阈值的选取十分重要.本文在不同的nms_thresh 和conf_thresh 下进行对比实验,如表3 所示.
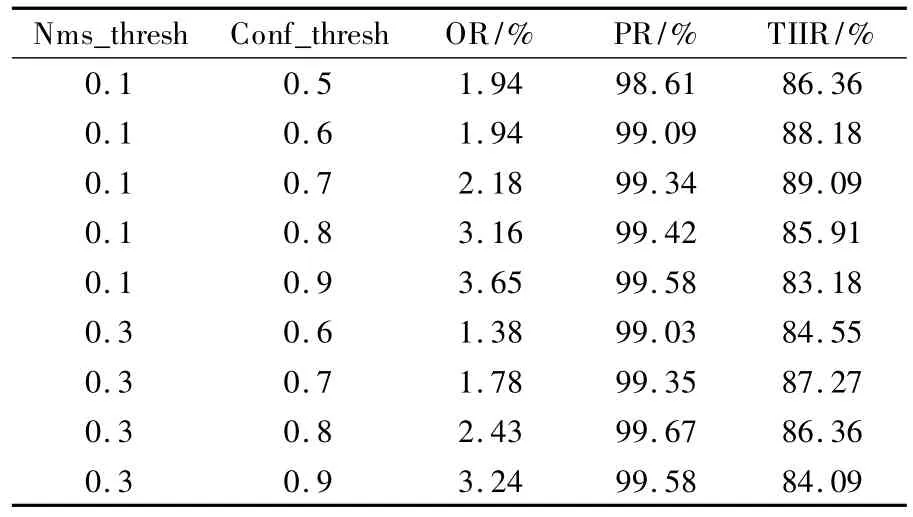
表3 不同nms_thresh 和conf_thresh 的模型实验对比Table 3 Experimental comparison of different nms_thresh and conf_thresh
图像中的部分字符存在模糊、腐蚀等情况,在检测时这些字符的置信度较低,在分类网络中由于特征较弱的问题也会产生误检,表3 中的数据说明了在相同非极大值抑制阈值下,置信度阈值越高,漏检率也就越高,误检率越低,这与之前的分析是一致的.在相同的置信度阈值下,较小的非极大抑制阈值会抑制掉距离相近同类字符中的一个框,从而导致漏检.由于最终目标是减少漏检、提高整张图片识别率,经过对比最后选取参数 nms_thresh 为 0.1 以及选取参数 conf_thresh 为0.7,此时漏检率降低到2.18%,精确率提升至99.34%,整张图片识别率提升至89.09%.
4.5 特征融合实验对比
为选取合适的特征融合方式,本节对VGG-16 的conv_3+conv_5 与conv_4+conv_5 分别进行不同的特征融合方案.对于conv_3+conv_5 采取add 特征融合,由于 conv_3 的输出维度是256,先对其进行1×1 卷积升维.不同特征融合实验对比如表4 所示.从表中可以看出,conv_4+conv_5 采取add 融合提高了精确率,但漏检率和整张图片识别率有所上升.conv_4+conv_5 采用concat 融合反而使各项性能均变差,这是因为conv_4 和conv_5 的concat 融合增加了背景与目标以及类别间的相似度.conv_3 和conv_5 的concat 融合性能最好,不仅漏检率下降,还提高了精确率和整张图片识别率.
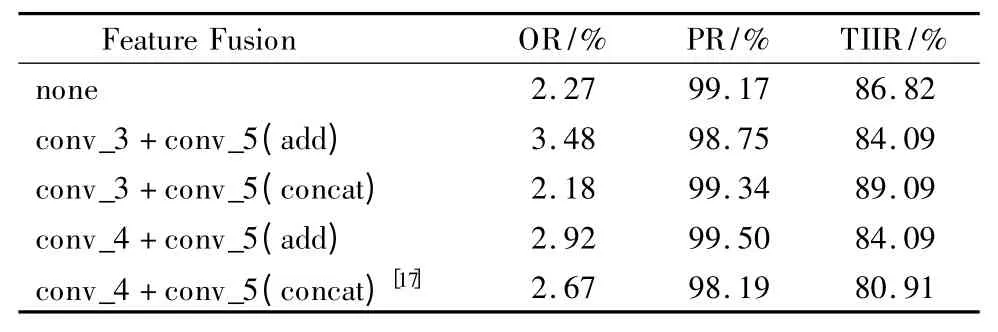
表4 不同特征融合实验对比Table 4 Experimental comparison of different feature Fusion
4.6 不同算法的比较
为测试本文所改进的Faster-RCNN 性能,本节采用深度学习中的 Faster-RCNN、YOLOv3[18]和 SSD300 模型,分别进行电路板字符检测性能测试对比,不同算法的实验对比如表5 所示.
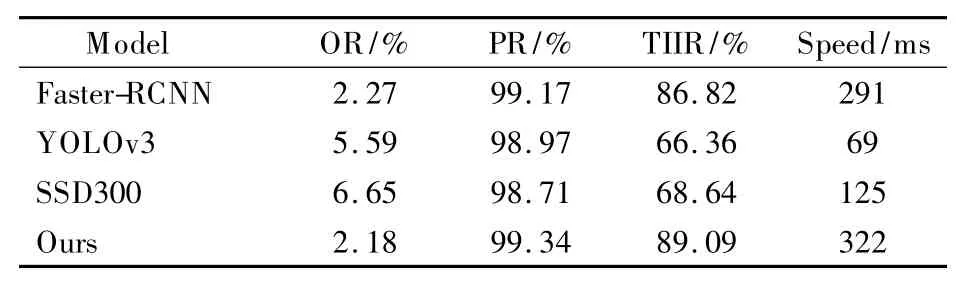
表5 不同算法实验对比Table 5 Experimental comparison of different algorithms
从表5 可以看出,针对此场景下的字符检测,两阶段方法比一阶段方法的性能更加优异,缺点也很明显,就是检测速度相对较慢.本文改进的Faster-RCNN 方法先对锚框尺度改进,然后利用conv_3 的浅层高分辨率特征和conv_5 的深层抽象特征进行感兴趣区域池化,相比较于原始的Faster-RCNN 和其余算法,各项指标均更优,检测时间的增加也在可接受范围之内.
为了更加直观地体现本文改进算法的效果,随机选取一张图片对不同算法进行测试比较,如图5 所示.

图5 不同算法检测效果对比图Fig.5 Comparison of detection effects of different algorithms
5 结 论
针对电路板字符检测难度大的问题,提出了一种改进的Faster-RCNN 电路板字符检测方法.在VGG16 为特征提取网络的Faster-RCNN 的基础上,根据字符目标的特点优化区域提议网络,并在感兴趣区域池化阶段,结合浅层高分辨率特征与深层抽象特征提取候选区域特征.在数据集中进行训练与测试.实验表明,改进算法减少了漏检率,提高了检测精度.由于仍然存在部分漏检且检测速度相对于较慢,在未来的工作中,漏检率仍需进一步降低,检测速度有待提高,模型也有待精简,从而进一步提高检测效率.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
