
卷积神经网络图像语义分割技术
2020-06-05 12:18田启川
小型微型计算机系统 2020年6期
田启川,孟 颖
1(北京建筑大学电气与信息工程学院,北京100044)
2(建筑大数据智能处理方法研究北京市重点实验室,北京100044)
1 引 言
图像语义分割是通过计算机将图像分割为若干个视觉上有意义或感兴趣区域的技术,其目标是对图像中每个像素进行语义信息标注,以不同颜色对分割出的区域进行标记,进而确定每个分割区域所属的类别.目前,图像语义分割在无人驾驶、医疗影像、目标检测、地理遥感、时尚搭配等领域都拥有广阔的应用前景.例如,无人驾驶领域通过语义分割对车体前方道路、行人等进行定位,帮助无人车自动判别路况;医疗影像领域通过病灶的自动分割实现计算机的辅助诊断.图像语义分割具有巨大的应用价值和研究价值.
目前国内外的专家学者对语义分割方法进行了大量研究,但是,语义分割技术依旧面临以下几个问题:
1)由于拍摄视角、运动等发生几何形变或图像背景层次复杂导致物体的误分割问题;
2)同类物体间的相异性和不同类物体的相似性引起的误分类问题;
3)物体的尺度过小导致的细节信息丢失问题.
为了解决上述问题,传统的图像分割方法往往采用基于阈值、边缘检测或区域的分割算法,这些方法不仅需要通过人工设计的特征对图像进行分割,还需要与其他方法相结合,具有很大的局限性.而基于卷积神经网络的语义分割方法利用神经网络自动提取图像中每个像素的语义信息,实现端到端的识别与分类,目前已被广泛地应用于语义分割任务.
国内一些文献对基于深度学习的图像语义分割方法进行了综述.文献[1-3]对现有方法进行了总结,但总结不全面,且缺少方法间的对比.文献[4-6]对语义分割方法综述较全面,但对算法分类的标准不够明确.
本文以直观的分类方法对主流的图像语义分割算法进行综述,针对不同应用背景,介绍相关数据集和性能评价标准,并对具有代表性的算法进行比较研究.
2 图像语义分割与典型网络结构
2.1 图像语义分割
图像分割作为计算机视觉中有关图像识别和分析的关键技术,用于把图像分成若干个特定的、具有独特性质的区域并提取出感兴趣的目标[7],而图像语义分割是通过逐像素分类,将分割出的区域赋予语义信息的过程.
图像语义分割的发展主要经历了三个时期[5].
1)传统方法时期:采用阈值法、边界检测法、区域法等对图像进行分割,这些方法只能利用图片中边缘、颜色、纹理等低级特征,分割结果并不精确.
2)传统分割方法和CNN 相结合的时期:先利用传统算法处理图像,再利用CNN 模型训练分类器,虽然带来了分割精度的提升,但依旧受到传统方法的限制.
3)基于CNN 时期:全卷积神经网络(FCN)的出现开启了图像语义分割领域的新篇章[8].FCN 将CNN 中的全连接层转换为卷积层,首次实现了端到端的、像素级的分类.FCN的提出为研究人员提供了全新的研究思路,在CNN 和FCN的基础上,U-Net[9]、SegNet[10]、DeconvNet[11]、RefineNet[12]、EncNet[13]等模型相继出现,为语义分割领域的发展做出了杰出贡献.
2.2 典型网络结构
CNN 的流行促进了图像语义分割的发展.现有的基于CNN 的图像分割技术以经典的 VGG[14]、GoogLeNet[15]、Res-Net[16]、DenseNet[17]网络结构或它们的变体为基础.
VGG 网络模型由 Simonyan 等人提出,其在 LeNet-5[18]模型结构上,采用小尺度的卷积核不断加深网络结构,反复堆叠3×3 的卷积核和2×2 的池化核对数据集进行训练和预测,减少模型参数,增强模型的表征能力.研究者通过实验证明网络达到一定深度会引发过拟合,并提出网络层次为16-19层时,模型性能最佳.
GoogLeNet 网络模型由Szegedy 等人提出,通过Inception模块堆叠 1×1、3×3 和 5×5 三种尺度的卷积核,提取并融合图像多尺度特征,提高了模型预测分类的准确率,同时,通过1×1 的卷积核对特征图进行降维,降低模型的参数量,提高了计算效率.
ResNet 网络模型是由何凯明等人提出的一种跨层连接的网络结构.ResNet 在VGG 模型的基础上搭建残差网络学习模块,将浅层网络与深层网络跨越连接,使深层训练误差可以反向传播至浅层,解决了网络结构过深引起的梯度弥散问题,实现了训练更深层次网络模型的目的.
DenseNet 是由黄高等人提出的稠密连接神经网络.DenseNet 以ResNet 为基础,通过 Dense Block 模块和 transitionlayer 实现高效地特征提取与重用.Dense Block 模块中的每一层都可以从前面的所有层获得额外输入,并将本层特征映射传递到后续所有层,这种方式不仅可以使网络的每一层都应用到浅层信息,还可将梯度从最后一层反向传递至浅层,减轻梯度消失和过拟合问题,加快网络的收敛速度.
3 全监督图像语义分割
全监督图像语义分割是指利用经过人工精确标注的数据集进行网络模型的训练和预测.由于不同方法的提出致力于改善网络模型不同的功能,因此以网络模型的功能为分类标准,从特征提取、复原、融合和优化四个方面对全监督的图像语义分割方法进行综述.
3.1 特征提取
卷积神经网络通过卷积层和池化层实现图像特征的提取.卷积层中每个卷积核对应为某一类特征提取器,通过卷积运算可以学习图像中各种特征和像素间的空间关系,而池化层可以对输入的特征图进行压缩,不仅可以提取主要特征,还可以简化网络计算的复杂度.不同卷积层和池化层的组合方式构造了多种特征提取方式.
3.1.1 利用串行空洞卷积增加感受野
空洞卷积是由Fisher 等人提出的可用于密集预测的卷积层,又名扩张卷积[19].空洞卷积在普通卷积的基础上引入扩张率,即在计算时将卷积核中间插入一个或多个零值,使卷积核以不同的间距处理数据.空洞卷积可以增大感受野,避免了池化层引起的图像分辨率降低问题.卷积与空洞卷积对比图如图1 所示.
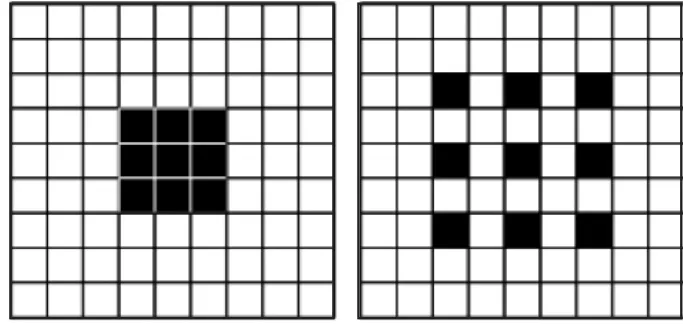
图1 普通卷积与扩张率为2 的空洞卷积对比图Fig.1 Comparison of convolution and 2-dilated convolution
DeepLabV1 网络模型由 Chen 等人于 2014 年提出[20].DeepLabV1 创新性地将空洞卷积应用到VGG16 网络,通过将VGG16 的全连接层转换为卷积层,并将VGG 模型第四个和第五个池化层之后的所有卷积层分别变换为扩张率为2 和4 的空洞卷积,使感受野的范围恢复至原图像大小,提升了模型分割的准确率.
ENet 是由Adam Paszke 于2016 年提出的实时语义分割模型[21].该模型借鉴 ResNet 的思想提出了 bottleneck 模块,利用bottleneck 模块串行不同扩张率的空洞卷积增加感受野,缓解了模型过度下采样导致的特征分辨率降低问题.其参数少,计算速度快等特性使实时语义分割技术成为可能.
DRN 网络模型由 Fisher Yu 等人于2017 年提出[22].DRN以ResNet 为基础,利用空洞卷积替换普通卷积,保持原有网络的感受野和图像空间的分辨率.DRN 将ResNet 最后的两组卷积层分别替换为扩张率为2 和4 的空洞卷积,增强了空间信息,通过移除最大池化层、移除残差操作等方法解决了反复使用空洞卷积带来的“棋盘效应[23]”,利用全局平均池化[24]和全卷积得到逐像素的分类输出.
上述方法都采用串行不同扩张率的空洞卷积增大感受野,提取空间性更强的语义特征.但过多地使用空洞卷积会导致棋盘效应和小目标特征丢失,也会占用大量计算机内存,因此有很多方法在空洞卷积的基础上做了改进[26-37].
3.1.2 利用空间金字塔池化模块提取全局语义特征
空间金字塔池化模块(SPP)由何凯明等人于2014 年提出[25].SPP 采用不同窗口和步长的最大池化层,将输入的特征图转换为不同尺度的特征后进行拼接,从而得到固定维度的特征.SPP 的优势在于,可以将任意尺度的输入转换为相同尺度的输出,且不同尺度特征的提取和拼接可以提高任务精度和网络模型的鲁棒性.基于SPP 的思想,又出现了许多特征提取方式,提高了语义分割的精度.
DeepLabV2 由 Chen 等人于 2014 年提出[26].DeepLabV2利用带洞空间金字塔池化模块(ASPP)提取全局语义信息,增强了对多尺度物体的识别能力.在DeepLabV1 的基础上,ASPP 模块采用四个并行的、扩张率分别为 6,12,18,24 的空洞卷积分支得到4 张特征图,利用融合层将4 张特征图相加获取多尺度特征.该方法虽然带来了一定的精度提升,但是ASPP 模块的加入导致参数大幅增加,而且模块中特征图简单的相加操作并没有充分利用提取出的多尺度特征.
Chen 等人随后提出了 DeepLabV3 网络模型[27].Deep-LabV3 在ASPP 模块中增加1* 1 的卷积层和全局平均池化以获取更优的特征图,将串行连接的空洞卷积与ASPP 模块相结合,获取更加丰富的全局语义信息.实验结果表明,Deep-LabV3 在不加入全连接的条件随机场的情况下,可以取得比DeepLabV1 和DeepLabV2 更高的准确率.
虽然ASPP 模块可以获取多尺度特征,但Maoke Yang 等人认为其在尺度轴上的特征分辨率不够密集,实际的感受野不能满足任务需要,为此提出了DenseASPP 网络模型[28].该模型以DenseNet 和ASPP 为基础,通过密集连接,使网络的每一层既能利用前面所有层的信息,也能将本层信息映射至后面所有层,实现了更为密集的多尺度特征提取.在 Cityscapes 数据集上的均交并比(mIoU)达到80.6%,相较于很多经典的分割网络取得了优异的性能.
PSPNet[29]网络模型由 Zhao 等人于 2016 年提出,该模型提出了金字塔池化模块以获取不同子区域和不同尺度的特征,同时结合空洞卷积和全局平均池化的优点,使输出的特征图包含丰富的上下文信息.金字塔池化模块将特征图以4 种尺度分成不同层级,每个层级具有不同大小的子区域,通过池化层获取每个区域的特征后,再将不同层级的特征与原始特征进行拼接.最后将拼接的特征图上采样回到输入图像大小进行分类.实验证明该方法对大物体的分割准确率更高.
将多种扩张率的空洞卷积串行或并行连接引发的棋盘效应会导致局部信息完全丢失和语义信息不连续的问题,因此文献[23]提出利用混合空洞卷积(HDC)消除棋盘效应的影响,论文设计了锯齿波空洞率的串行卷积序列,即将不同扩张率的空洞卷积串行连接获取特征图,避免了感受野中存在空洞的现象,有效地消除了网格.文献[30]提出利用平滑扩张卷积解决棋盘效应,该研究的优势体现在利用可分离和共享的卷积平滑空洞卷积,避免堆叠过多卷积层,极大地减少了网络结构的复杂性.
以上所论述的网络模型都是利用单一网络结构提取全局语义特征,也是主流的特征提取方法.为了提取全局语义特征,也有研究者利用多种网络结构提取多种语义特征进行融合[31-32]或是利用多分辨率的分支网络提取多尺度特征进行融合[33-35],这些方法丰富了特征的提取方式,为语义分割领域的科研人员提供了有价值的参考.
3.2 特征复原
特征复原是指利用双线性插值、反池化、反卷积等操作对特征图进行上采样,恢复特征图的分辨率和空间信息.不同的上采样方法会产生不同效果,根据不同的任务需求选取合适的上采样方法,更有助于分割精度的提升.
双线性插值是语义分割领域应用较为广泛的上采样方法,其利用原图像目标点四个最邻近的像素值来共同确定目标位置的像素值,计算简单,适用于没有明确边界的连续数据集分割.文献[20,23,26]等很多经典语义分割方法均采用双线性插值恢复图像的分辨率,可以产生平滑的输出.
反池化是指在最大池化层记录最大值的位置信息,之后在上采样阶段使用该信息扩充特征图.Vijay Badrinarayanan等人2015 年提出SegNet 网络模型利用反池化的方法恢复特征图的空间信息.SegNet 是一个对称的编码-解码结构,在编码阶段利用改进的VGG16 提取特征,在解码阶段利用反池化恢复下采样损失的信息,可以得到更平滑和精细的输出.反池化示意图如图2 所示.
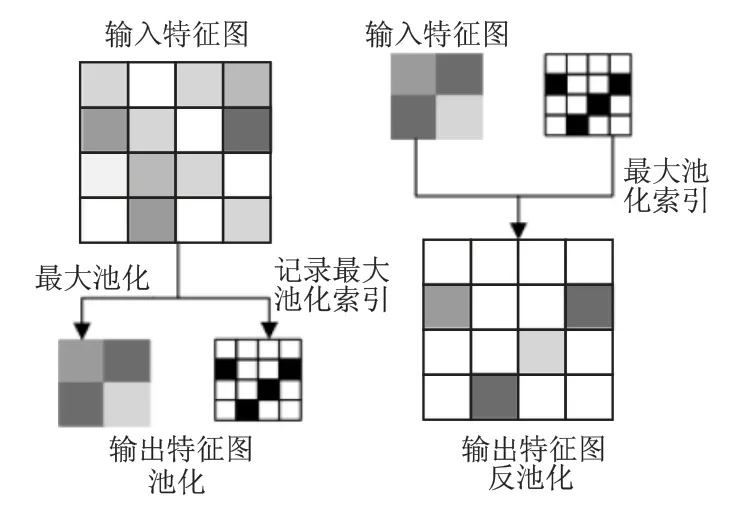
图2 反池化示意图Fig.2 Schematic diagram of unpooling
2010 年,Zeiler 等人首次提出反卷积的概念,不仅可以替代双线性插值恢复特征图的信息,还可以实现特征图可视化[38].2014 年文献[39]首次提出利用反卷积和上池化实现特征图可视化,通过可视化的特征图调整网络结构,提高了分割精度.2015 年,HyeonwooNoh 等人提出 DeconvNet 网络模型,在上采样阶段利用反卷积代替双线性插值,并利用上池化记录最大池化索引,有助于克服物体大小变化引起的分割问题.相较于双线性插值和反池化,反卷积过程中卷积核的参数是可学习的,可以增加细节信息的复原能力.
近年来,也提出了一些新型的特征复原方法用于提高语义分割的性能.文献[23]提出了利用密集上采样模块(DUC)恢复图像的空间分辨率,其优势在于通过学习一组上采样滤波器来放大低分辨率的特征图,捕获丢失的细节信息.文献[40]提出了利用DUpsample 模块进行上采样的方法,该模块可以建立每个像素之间预测的相关性,减少模型对特征图分辨率的依赖,并且极大地减少了运算量.文献[41]提出联合金字塔上采样模块(JPU),该模块创新性地并行不同扩张率的空洞卷积以恢复图像分辨率,不仅可以提升分割精度,还显著提升了模型的计算速度.文献[42]提出的DRINet 网络模型通过Unpooling 模块对合成路径的特征图进行级联和上采样,可以更有效地利用特征图信息.文献[43]提出了上下文解卷积网络,利用空间上下文模块对像素间的空间依赖关系进行建模,从而使像素在某些局部区域上更具表现力.
3.3 特征融合
特征融合是指将提取出的特征图进行相加或拼接融合.在特征提取阶段,需要对多尺度的特征进行融合使特征图的语义信息更加丰富,在特征的利用阶段,需要对不同层级的特征进行融合以利用全局有效信息,提高分割进度.特征融合方法主要分为层级融合和加权融合.
3.3.1 层级融合
层级融合是指利用跳跃连接或稠密连接机制,将不同层级提取的浅层特征和复杂特征相加或拼接,整合不同层级的上下文信息,提高模型性能和语义分割准确率.
FCN 由Lonjong 等人在2014 年提出,是图像语义分割领域的开篇之作.该模型将分类识别网络结构的全连接层改为卷积层,首次实现了端到端的、像素级的预测.采用远程跳跃连接的思想,将第五个池化层得到的特征图分别进行32、16和8 倍的上采样,并将16 倍和8 倍上采样得到的特征图分别与第四个和第三个池化层得到的特征图融合,充分利用浅层信息,提高模型的语义分割能力.但网络中多次重复的下采样和反卷积会导致图像信息损失.
U-Net 是由Olaf 等人2015 年构建的适用于较少训练集进行端到端训练的网络结构.其在FCN 基础上,采用经典的编码-解码结构,利用编码器生成低维到高维的金字塔型抽象特征,利用解码器生成与特征金字塔对应层级的特征图,通过跳跃连接将下采样得到的低分辨率抽象特征图和上采样生成的与特征金字塔对应层级的特征图相融合,既包含了复杂抽象的特征,还引入了各层级中低维特征的细节信息,提高了分割准确率.U-Net 网络结构示意图如图3 所示.
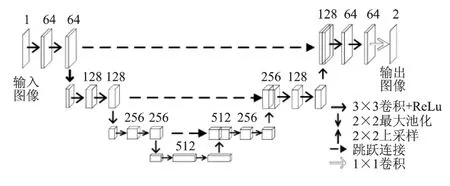
图3 U-Net 网络结构示意图Fig.3 Schematic diagram of U-Net
2017 年,RefineNet 在U-Net 跳跃连接的基础上增加残差连接,使梯度信息更有效地传递至整个网络,在PASCAL VOC 数据集上取得了优越的性能.2018 年,周纵苇[44]等人在U-Net 的基础上提出了UNet++网络模型,他指出U-Net 直接将浅层特征和高层抽象特征融合会带来语义鸿沟,因此设计实现了基于稠密连接机制的融合方法,反复融合各个层级的特征,通过特征再利用获取更加精确的语义信息.2019 年,董荣生等人提出的 DenseU-Net[45]利用 DownBlock 模块融合不同层级特征,实现了浅层细节特征和深层抽象特征的融合,有助于提高小尺度目标分割的准确率.文献[46]利用自适应融合机制将不同特征提取路径提取出的特征图进行融合,实现特征的最佳组合.文献[47]在 U-Net 结构的基础上提出MultiResUNet 网络模型,该模型通过MultiRes 模块以残差连接的方式获取更丰富的语义空间信息,同时构建编码器与解码器之间的Res Path 路径减少语义鸿沟.
3.3.2 加权融合
特征加权融合指对输入特征图进行加权求和,使网络通过学习的方式自动获取每个特征通道的重要程度.由于层级融合没有综合考虑特征图各个位置的联系和相关性,因此采用特征加权融合的方式可以增强全局特征,提高分割精度.
SENet 由 Momenta 公司发表于 2017 年[48].SENet 从特征通道之间的关系入手,采用全新的“特征重标定”策略,建模特征通道之间的相互依赖关系.这种方法可以使模型通过学习的方式自动获取每个特征通道的重要程度,然后依照这个重要程度增强有用的特征并抑制对当前任务用处不大的特征,自适应地重新校准通道的特征响应.
DANet 由Jun Fu 等人于2018 年提出的自注意力机制模型[49].模型通过自注意力机制捕获上下文的依赖关系.位置注意力机制通过所有位置的特征加权总和选择性地聚集每个位置的特征,通道注意力机制通过整合所有通道图中的相关特征,有选择地强调相互关联的通道图,最后将两种注意力机制的输出相加,使网络模型可以捕获全局特征的依赖关系和空间特征的相关性.
CCNet 由 Huang 等人于 2018 年提出[50],作者指出 SPP、ASPP 等模块忽视了像素间的长依赖关系.CCNet 通过纵横交错注意模块,利用特征加权建立像素间的联系,在水平和垂直方向聚合远程像素间的上下文信息,提升分割精度的同时,大幅节省了计算机内存.2019 年,李夏等人提出了基于期望最大化的EMANet[51],将期望最大化算法引入注意力机制,以最大化迭代的方式对注意力图进行更紧凑的估计.文献[52]提出的双路径密集卷积网络(DP-DCN)在FuseNet 的基础上修改路径融合策略,利用支持密集连接的融合模块融合两个路径提取的有效特征,增加模型功能的多样性.文献[53]通过构建全局特征捕获模块(GFCM)来提高分割性能.GFCM由全局编码模块(GEM)和空间注意模块(SAM)组成,其中GEM 利用字典学习、残差编码和全局平均池化等操作提取上下文信息,SAM 则利用特征加权建立全局空间的依赖性.文献[54]在deepLabV3+的基础上,重构神经网络模型,采用加权融合的方式融合不同尺度的输出特征图.
3.4 特征优化
特征优化是指利用条件随机场(CRF)或马尔科夫随机场(MRF)对语义分割的预测结果进行优化.传统的使用CRF或MRF 作为后处理的操作方式通过将低层图像信息和系统输出的逐像素的类别得分相结合,以提高模型捕获细粒度的能力,但是这类方法会占用大量计算机内存.现阶段的优化方式主要是把CRF 或MRF 整合到神经网络中,让网络中的所有参数同时训练,形成一个端到端的系统.
文献[55]提出的CRF-RNN 模型将CRF 与神经网络相结合,在不影响网络模型前后向传播的基础上,充分考虑图像中每个像素与其他像素的关系.2015 年,Liu 等人提出了基于CRF 的深度解析网络(DPR)[56].DPR 在 CRF 能量函数公式的二元势函数上加入描述图像上下文信息的惩罚因子,获取了更充足的局部信息.另外,将CRF 构造成与卷积神经网络共同训练的形式,可以通过一次的前向推理得到输出结果,简化了计算过程.2016 年,文献[57]提出利用卷积神经网络分别对条件随机场中的一元势函数和二元势函数进行训练,并利用局部相似性约束方法优化最终的预测结果,提高了分割准确率.2018 年,文献[58]通过制定基于CNN 的成对势函数将CNN 与CRF 相结合,捕获语义信息间的相关性.文献[59]构建的深度解析网络,通过MRF 对特征进行优化,减少了反向传播过程中迭代的次数.2019 年以来,很多研究者采用将CRF 或MRF 与CNN 相结合的思想优化特征,在多个应用领域的研究中取得了较高的性能[60-63].
4 非全监督图像语义分割
全监督语义分割方法要对数据集进行精准标注,会耗费大量时间成本和人力成本,因此图像语义分割领域衍生出了非全监督图像语义分割方向.非全监督图像语义分割包括弱监督和半监督的图像语义分割.弱监督语义分割是指利用边框、线条、图像标签等弱标注训练语义分割模型;半监督语义分割指利用少量像素级标注数据和大量弱标注数据训练语义分割模型.下面按照不同标注方式对弱监督和半监督的语义分割方法进行综述.图4 为强标注和弱标注示意图.

图4 强标注和弱标注示意图Fig.4 Schematic diagram of strong and weak annotations
4.1 弱监督图像语义分割
边框级标注是指利用包含整个物体的矩形区域提供标注信息.文献[64]提出的BoxSup 网络模型在FCN 模型的基础上,首先利用MCG[65]算法确定初步目标候选区域,然后利用该区域作为监督信息送入FCN 模型进行优化,将输出的结果反复在FCN 模型中迭代,直至模型最终收敛.文献[66]结合交互式语义分割方法,将物体框内部和外部的像素作为前景和背景信息,使用估计的分割掩码作为标签训练语义分割模型.文献[67]基于 GrabCut[68]算法提出 DeepCut 算法,在 CNN 中不断迭代,并利用CRF 优化输出,逐步提升分割准确率.
线条级标注是指通过任意形式的线条获取物体位置和范围的稀疏信息作为图像的标签.文献[69]提出的ScribbleSup方法首先根据线条对图像生成像素块,再利用GraphCut 算法建模,实现图像自动标记,最后将标记的图像送入FCN 中进行训练,获取分割结果.文献[70]在U-Net 的基础上,提出了一种利用稀疏注释的立体数据训练三维分割网络的方法,主要分为两个阶段:第一阶段利用单个稀疏标注的数据集进行训练并预测该数据集上其他未被标注的像素,第二阶段利用多个稀疏标注的数据集进行训练,预测新的数据并进行三维分割.2018 年,文献[71]通过构造一种原则性损失函数来解决标准损失函数不能区分种子区域和误标注像素的问题,利用纹理、颜色、位置等浅层信息作为分割标准评估网络输出,取得了和强监督学习接近的性能.
图像标签级标注是指使用图像的类别标签作为训练标注,这种标注方式效率高、工作量小,需要通过网络模型来建立图像类别标签和像素之间的关联,并自动推断物体在图像中的位置.文献[72]首先通过假设感知分类生成基于可靠假设的定位图,再通过这些定位图以有监督的方式训练分割网络.文献[73]提出利用STC 框架进行弱监督的语义分割,该框架包括初始分割网络和增强分割网络两部分.首先通过显著性检测技术获取大量简单图片对应的显著图,并利用显著图构建语义标签跟像素点的关系来训练初始分割网络,将初始网络预测的结果作为增强网络的标签进行训练,最后利用增强网络进行预测以获取更精确的输出.文献[74]则是通过对抗擦除的方法不断擦除待分割物体上最具判别力的一部分区域,从而使分类网络发现物体其它更多的区域,提高分割的准确率.
4.2 半监督图像语义分割
半监督图像语义分割面临的主要问题是使用不平衡的、异构的标注数据训练网络模型.为了解决上述问题,2015 年Hong等人采用深层编码器-解码器解耦网络将语义分割解耦成分类和分割两个子网,独立训练[75].分类网络从图像级标签标注的数据中学习;分割网络从像素级标注的数据中学习,显著提高了半监督语义分割的性能.文献[76]提出一种可转移的半监督语义分割方法.该方法包括标签传输网络(L-Net)和预测传输网络(P-Net),L-Net 通过跨类别共享的方法,将学习的分割知识从强标注传递到弱标注的图像,并生成粗糙的像素级语义图;P-Net 通过对抗学习策略产生精度更高的分割结果.2019年,Mostafa 等人提出了一种具有自我校正功能的半监督模型[77].该方法先通过辅助模型为弱监督图像生成初始分段标签,再利用自校正模块训练主分段模型,在PASCAL VOC 2012数据集上取得了近似于全监督语义分割模型的成果.
5 应用领域及性能对比
图像语义分割技术在自动驾驶[78]、室内外场景理解[79,80]、医学图像[81-85]、遥感图像[86-88]等多个领域都拥有广阔的应用前景.不同应用领域数据集的特点、标注质量和评价指标均不同,下面分别进行介绍.
5.1 无人驾驶
5.1.1 数据集
CamVid 数据集由剑桥大学的研究人员于2009 年发布[89].CamVid 由车载摄像头拍摄得到的5 个视频序列组成,提供了不同时段701 张分辨率为960×720 的图片和32 个类别的像素级标签,包括汽车、行人、道路等.数据集中道路、天空、建筑物等尺度大,汽车、自行车、行人等尺度小,待分割物体尺度丰富.
KITTI 是目前国际上最大的用于自动驾驶场景的算法评测数据集,可进行3D 物体检测、3D 跟踪、语义分割等多方面研究[90].该数据集包含市区、乡村、高速公路等真实图像数据,一张图像最多达15 辆车和30 个行人,每张图像中有各种程度的遮挡与截断,研究者可根据个人需求自行构建数据集.
Cityscapes 由奔驰公司于2015 年推动发布,专注于对城市街景的语义理解[91].它包含50 个城市不同场景、不同季节的5000 张精细标注图像和20000 张粗略标注图像,提供30个类别标注.数据集提供了像素为2048×1024 的高分辨率图像,图像中街道背景信息复杂且待分割目标尺度较小.此数据集可用于实时语义分割研究.
5.1.2 评价指标
自动驾驶领域的性能评价指标主要包括像素精度(PA),均像素精度(MPA)、均交并比(mIoU)和运行时间.其中PA、MPA、mIoU 的定义和公式如式(1)-式(3)所示.
①PA 是指正确分割的像素数量占图像总像素数量的百分比.
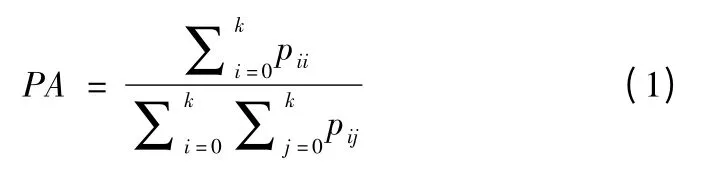
②MPA 是指每个类内正确分类的像素数量占该类所有像素数量的百分比.

③mIoU 用来计算真实值和预测值两个集合的交集和并集,也就是计算预测结果与原始图像中真值的重合程度.

其中k 表示标签标记的类别,k+1 表示包含空类或背景的总类别,pii表示实际为i 类预测为i 类的像素数量,pij表示实际为i 类但预测为j 类的像素数量,pji表示实际为j 类但预测为i 类的像素数量.
④运行时间表示分割一张图像所消耗的时间.
5.1.3 算法性能对比
表1 给出了基于Cityscapes 数据集的算法性能对比结果.可以看出,在自动驾驶领域,研究者主要通过改进特征提取和融合方式实现提取并利用多尺度的上下文语义信息.近年来,通过特征加权融合训练注意力机制的网络模型可以在简化特征提取的基础上获得优越的分割性能,是一个值得关注的研究方向.特征的优化方法虽然可以带来精度的提升,但是由于自动驾驶需要考虑网络模型的实时性,近年的研究方法逐步减少了对CRF 和MRF 的使用.

表1 基于Cityscapes 数据集的算法性能对比Table 1 Performance comparison of algorithms based on Cityscapes dataset
5.2 室内外场景理解
5.2.1 数据集
SiftFlow 是2011 年由刘策等人收集的室外场景理解数据集[92].SiftFlow 提供包含背景的 34 类语义标签和 2688 张像素为256×256 的训练图像,包含8 种不同户外场景,如街道、山脉、海滩、城市等,适用于室外场景理解.
PASCAL VOC 2012 是由国际计算机视觉挑战赛发布的用于图像分类、物体检测或语义分割的权威数据集之一[93].PASCAL VOC 2012 提供了20 个物体对象和1 个背景的类别标签,包括人、动物、室内生活用品等.原始的数据集提供了1464 张用于语义分割的训练图像.2014 年,该数据集的增强版(PASCAL VOC 2012+)又重新标注了8498 张用于训练的图像.数据集中图片的尺寸不固定,每张图片包含不同数量的物体,物体尺度不一且存在遮挡现象.
Microsoft COCO 是由微软团队2014 年建立的用于图像识别和语义分割的数据集[94].Microsoft COCO 提供了包含背景信息的81 种类别标签,328000 张图像和2500000 个物体实例.数据集中的图像来源于日常的室内外场景,目前主要用于对卷积神经网络进行预训练以提高模型的性能.
SUNRGB-D 是2015 年发布的室内物体语义分割数据集[95],拥有 10335 张 RGB-D 图像和 37 个语义类别.该数据集在四个RGB-D 传感器获取的图像的基础上结合多个数据集集合而成,在二维和三维空间均有密集的标注,提供了更加复杂的物体尺度信息和背景信息.
ADE20K 是2017 年发布的大规模的场景解析、分割、多物体识别和语义理解数据集[96].该数据集提供的场景种类更丰富,标记内容更详细,总共包括151 个语义类别的标签和超过20000 张训练图像.数据集要求对图像中的物体和背景进行语义分割.
5.2.2 评价指标
室内外场景理解的性能评价指标主要包括像素精度(PA),均像素精度(MPA)和均交并比(mIoU).公式同5.1.2 节.
5.2.3 算法性能对比
表2 给出了基于PASCAL VOC 2012+数据集的不同算法性能对比结果.根据表2 可以看出,室内外场景理解领域主流的语义分割方法和自动驾驶领域具有一定的重合性.
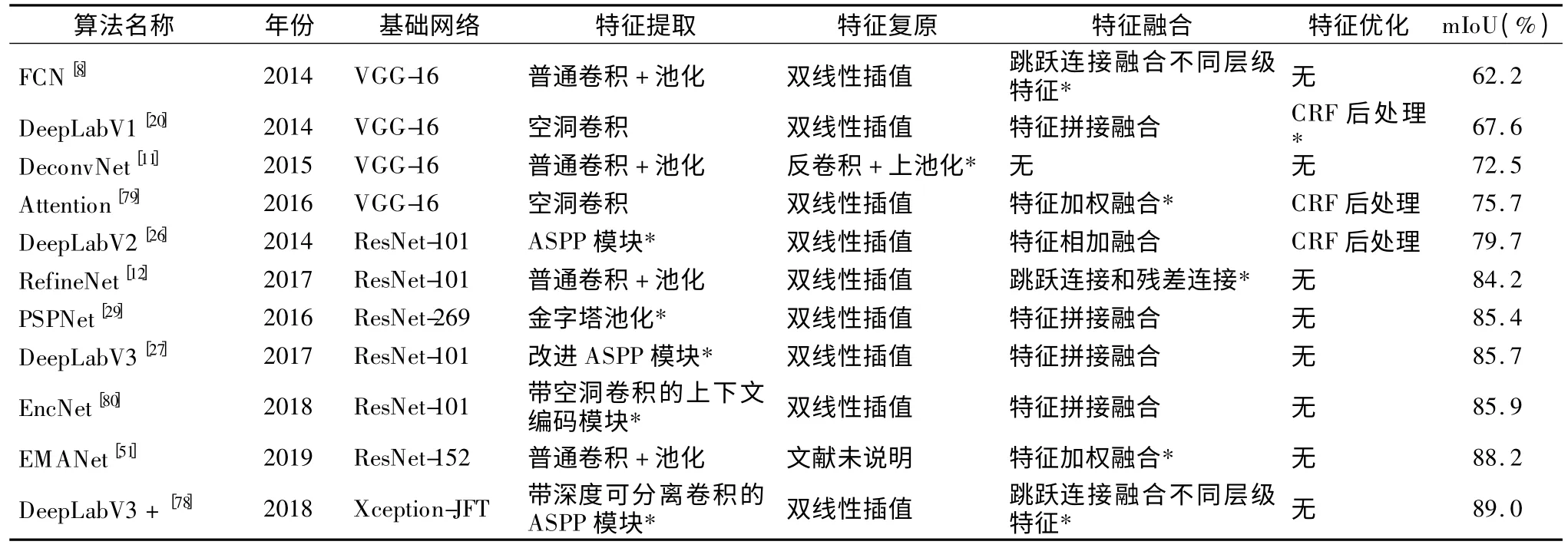
表2 基于PASCAL VOC 2012+数据集的算法性能对比Table 2 Performance comparison of algorithms based on PASCAL VOC 2012+dataset
5.3 医学图像
医学图像分割涉及人的眼部、脑部、胸部、肺部、心脏等众多领域,本文以人的眼底视网膜图像为代表,分析语义分割技术在医学图像领域的应用.
5.3.1 数据集
STARE 是由Hoover 等人于2000 年公开的用于视网膜血管分割的彩色眼底图像数据集[97].它包括20 幅眼底图像,其中10 幅有病变,分辨率为605×700,每幅图像以2 个专家手动分割的结果作为标签,是常用的眼底图像标准库之一.
DRIVE 是由Niemeijer 团队在2004 年根据荷兰糖尿病视网膜病变筛查工作建立的彩色眼底图库[98].数据来自453 名糖尿病受试者通过光学相机拍摄得到的视网膜图像,从中随机抽取40 幅,其中7 幅含有早期糖尿病视网膜病变.训练集和测试集分别包含20 张像素为565×584 的图像,每幅图像都以专家手动分割血管的二值图像作为标签.
DIARETDB1 是由Tomi Kauppi 等人于2007 年创建的糖尿病性视网膜病变数据集[99].它包含89 幅由眼底相机拍摄的彩色眼底图像,分辨率为1500×1152,由4 名专家手动标注的病变位置作为标签.数据集中含有84 幅病变图像和4 种病变标注.但数据集的标签只涵盖病变区域,病变边界不清晰,需要通过标签中标记的亮度确定病变位置.
5.3.2 评价标准
视网膜图像分割采用准确率(accuracy)、特异性(specificity)、灵敏度(sensitivity)和作为评价指标,计算公式如式(4)-式(6)所示.
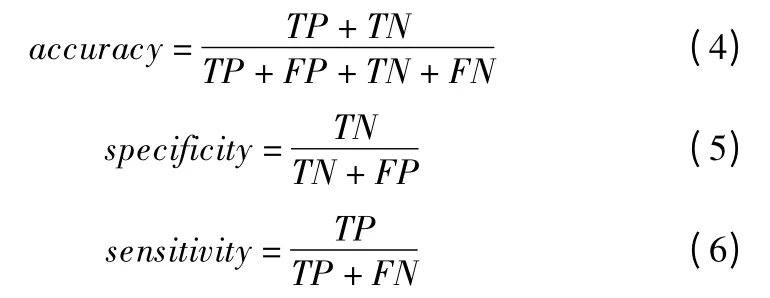
其中预测为正、真实为正的像素点数目称作真阳性TP;预测为正、真实为负的像素点数目称作假阳性FP;预测为负、真实为正的像素点数目称作假阴性FN;预测为负、真实为负的像素点数目称作真阴性TN.

图5 ROC 与 AUC 示意图Fig.5 Schematic diagram of ROC and AUC
AUC 表示 ROC(Receiver OperatingCharacteristic)曲线下方的面积,面积越接近1,说明语义分割算法的性能越好.图5表示ROC 曲线和 AUC 示意图.
5.3.3 算法性能对比
表3 给出了基于DRIVE 数据集的不同算法性能对比结果.根据表3 可以看出,医学图像的语义分割方法往往在FCN 和U-Net 的基础上进行改进.虽然改进特征提取方法可以提取更加丰富的语义信息,提高分割的准确率,但是不同特征提取方法间的准确率差异微小,这是由于医学图像更注重小尺度特征的提取,多尺度卷积、空洞卷积等增大感受野的方法对医学图像的分割没有明显效果.同时,在特征的利用方式上,通过跳跃连接融合浅层和深层特征的方法并不能实现对已提取特征的有效利用.可以从如何提取小尺度特征和如何更好地利用已提取特征的角度提高医学图像的分割准确率.

表3 基于DRIVE 数据集的算法性能对比Table 3 Performance comparison of algorithms based on DRIVE dataset
5.4 遥感图像
5.4.1 数据集
Massachusetts Roads dataset 是 由 Volodymyr Mnih 等 人2013 年公布的道路分割数据集[100].它提供了来自马萨诸塞州各城市和郊区的1171 张航拍图像,覆盖面积2.25 平方公里.每张图像的分辨率为1500×1500,提供背景和道路2 类标签.
ISPRS Vaihingen 2D 是由国际摄影测量与遥感学会2015年公布的遥感图像数据集[101].它包括33 幅在德国Vaihingen地区拍摄得到的高分辨率(大于2000×2000)正射影像.其中只有16 幅图像被标注,标注类别包括道路、草地、建筑物、车辆、树木和杂类地物6 类.
Inria Aerial Image Labeling Dataset(IAILD)数据集是由Maggiori 等人于 2016 年发布的遥感图像数据集[102].IAILD数据集涵盖了奥斯汀、芝加哥等地区形状、大小、建筑风格不同的建筑物航空遥感图像.该数据集提供180 张5000×5000像素的彩色图像和对应的二值图像作为训练集和标签,提供180 张彩色图像作为测试集,但测试集不含标签.
卫星影像 AI 分类与识别数据集是由中国计算机协会2017 年在大数据与计算机智能大赛中公开的数据集[103].该数据集拍摄于中国南方某地区,提供人工标记的高分辨率遥感图像5 幅,标签包括植被、道路、建筑、水体及其他类别共5 种.
WHU building dataset 数据集是由季顺平等人于2019 年公开的高分辨率遥感影像数据集,适用于建筑物提取[104].该数据集包括航空建筑物数据集和卫星建筑物数据集两部分.航空建筑物数据集涵盖了新西兰市不同风格、用途、尺度和颜色的22 万栋建筑.卫星数据集包含卫星数据集Ⅰ和Ⅱ.卫星数据集Ⅰ包含204 张分辨率为512×512 的图像,拍摄自全球不同区域的不同城市.数据集Ⅱ包含6 张相邻的、色彩差异明显的卫星遥感图像,主要用于验证算法对数据源不同、建筑物类型相似的样本的泛化能力.
5.4.2 评价标准
遥感图像的评价标准主要包括准确率、均交并比和F1 Score.
F1 Score 的定义如公式(7)所示.

其中,

5.4.3 算法性能对比
表4 给出了基于IAILD 数据集的不同算法性能对比结果.由表4 可知,在遥感图像领域,基于FCN、U-Net 等网络结构进行改进的语义分割方法取得了优越的性能.遥感图像更加注重空间和位置信息,因此增大空间感受野的特征提取方法可以带来精度的提升.同时,利用特征加权融合训练注意力机制的网络模型也开始在遥感图像领域崭露头角.表5对各个领域常用的语义分割数据集进行了汇总,总结了用于不同场景下数据集的分类数量、分辨率、训练集、验证集、测试集等信息,并且综合阐述了不同领域数据集的特点,对从事图像语义分割方向的研究具有十分重要的参考价值.

表4 基于IAILD 数据集的算法性能对比Table 4 Performance comparison of algorithms based on IAILD dataset

表5 常用语义分割数据集汇总表Table 5 Summary table of commonly used semantic segmentation datasets
6 总结与展望
图像语义分割是图像理解分析的重要研究内容,论文通过分析图像语义分割领域的文献,认为该领域目前具有挑战性的研究方向主要有:
1)特征上采样方法:现有图像语义分割方法主要是对特征提取和融合方式进行创新,忽略了特征复原的方法,因此丰富特征上采样方式是一个十分值得研究的方向.
2)非全监督图像语义分割方法:非全监督图像语义分割可以采用弱标注的数据集进行研究,大大减少了手工标注的成本,这类技术将会是未来的发展趋势.
3)实时图像语义分割技术:深度学习模型由于层数多,参数量大,严重降低了方法的实时性,如何改进网络结构以提升分割的速度是一个有待解决的难题.
4)注意力机制:训练注意力机制可以在简化特征提取方式的基础上提升模型性能,非常具有研究价值.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
红领巾·萌芽(2019年8期)2019-08-27
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
长江学术(2015年1期)2015-02-27
