
基于重采样与特征选择的不均衡数据分类算法
2020-06-05 12:18张忠林曹婷婷
小型微型计算机系统 2020年6期
张忠林,曹婷婷
(兰州交通大学电子与信息工程学院,兰州730070)
1 引 言
在现实世界中存在大量不平衡数据,给研究带来了一定的挑战.不均衡数据分类,在许多领域中有着重要的应用,如信用卡欺诈[1]、医疗健康预测[2]、异常检测[3].传统的分类方法旨在最大化整体分类准确性.对于不均衡数据分类,少数类的错分代价相对较大,比如在医疗诊断数据中,人们更加关注的是异常错误诊断的数据;在气象预测上,人们更加关注沙尘暴、暴雨、霜冻等极端天气的预测精度.
国内外学者们对不均衡数据的研究主要集中在以下四方面,第一方面从数据层面上主要采用不同的抽样方法平衡各类别的样本数,如欠采样[4](Under-Sampling)、过采样(Over-Sampling)、混合采样(Mixed Sampling)以及相应的改进算法SMOTE[5](Synthetic Minority Oversampling Technique)、Borderline-SMOTE[6]、CBNM[7](Clustering-Based NearMiss)等;胡峰等[8]提出TWDIDO 算法,结合三支决策理论,对边界域和负域中的小类样本进行不同的过采样处理,有效解决不平衡数据的二分类问题.第二方面是降维,常用的降维方法有特征提取和特征选择.Sherif F.Abdoh 等人[9]用随机森林(RF)和SMOTE 结合递归特征消除(RFE)和主成分分析技术(PCA)两种降维技术,发现RF 与SMOTE 结合提高了分类性能.第三方面是算法层面,为了对不均衡的数据分类有较好的适应性,对传统算法进行适当修改,代价敏感与集成算法取得较好的结果.最后一个方面就是找出新的合适的分类评价度量指标,使分类器不向多数类偏倚.
目前,将采样技术与集成方法结合也是一种有效解决不均衡数据分类问题的有效途径,SMOTEBoost[10]、SMOTEBagging[11]、RUSBagging[12]等算法均先运用采样技术降低数据不平衡度,再采用集成策略进行相关研究.
学者们已经对不均衡数据分类问题进行了大量研究,但依旧存在一些不足,一般的欠采样方法容易删除有用的部分数据,造成一些重要信息的缺失;随机过采样只是简单的复制样本来增加少数类样本的数量,模型产生过拟合的几率比较大;SMOTE 过采样算法产生的模糊边界问题;按照经验选择参数一般很难得到性能最优的分类器[13].
本文针对以上不均衡数据分类中存在的问题,从特征选择与重采样方法出发提出BSL-FSRF 方法,首先提出BSLSampling 对数据重采样,进行数据均衡化操作,其次对各个维度上的特征的分类能力进行评价,进行特征删减,因为猜中近邻nearHit 和猜错近邻nearMiss 也不再只选一个,而是选择几个进行平均,拥有更好的稳定性,且改善了SMOTE 算法模糊边界问题,可用于多类的问题;最后运用改进的Gridsearch 算法对随机森林参数进行优化.通过公共数据集进行验证,结果表明本文所提出的算法BSL-FSRF 在Kappa 系数,F-measure和AUC 值方面有一定的提升,针对不平衡数据分类偏向多数类的问题有一定的参考价值.
2 算 法
BSL-FSRF 算法首先提出一种BSL 重采样,将少数类样本进行边界区分后只对边界样本进行SMOTE 插值,之后再利用Tomek link 进行欠采样,在使数据集基本达到均衡的同时,减少噪声样本的数量;其次引入“假设间隔”(hypothesis margin)思想对各个特征维度进行度量,设定合适的阈值,将与类别相关性不高的特征移除,对数据进行降维,减少运行时间,提高模型精确度,并可扩展到多类别分类问题;最后采用随机森林对数据进行分类,用Gridsearch 对参数进行寻优,对寻优方式进行改进.
2.1 BSL 采样
SMOTE 算法基本思想是对少数类样本进行分析并根据样本间的欧氏距离人工合成一定数量的新样本,针对其容易产生模糊边界问题,BSL 采样算法首先将少数类样本分为安全样本,噪声样本和边界样本,只对边界样本进行SMOTE 插值,对插值的边界进行限制,从而使合成后的少数类样本分布更合理.再利用Tomek link 数据清洗技术进行欠采样,删除Tomek link 对中多数类样本,进一步去除噪声.Tomek Link 对表示两个分别属于不同类别的样本距离最近的一对样本,其中一个是噪音样本,或者两个样本都位于边界附近.通过移除Tomek Link 对,清洗掉类间重叠样本,从而更好地进行分类.BSL 采样算法具体步骤如下:
算法 1.BSL-Sampling
输入:原始样本训练集D,最近邻样本个数k
输出:新的样本训练集T ″1
Step 1.将原始样本训练集D 按照4:1 切分为训练集T1和测试集T2.
Step 2.按照式(1)计算少数类样本每个样本点Xi与所有T1中训练样本的欧氏距离,获得该样本点k 个近邻样本.
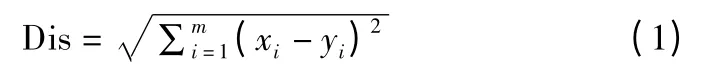
Step 3.对少数类样本进行划分.设在k 近邻中有k ″(0≤k ″≤k)个属于多数类样本.
若k″=k,Xi被定义为噪声样本;
若 k/2≤k ″≤k,Xi被定义为边界样本;
若 0≤k ″<k/2,Xi被定义为安全样本;
边界样本记为{x'1,x'2,x'3,…,x'i,…,x'num},num 表示少数类边界样本个数.
Step 4.计算边界样本点与少数类样本Xi的k 近邻,根据采样倍率N,根据式(2)进行线性插值.

Step 5.合成的少数类样本与原始训练样本T 合并,构成新的训练样本T'1.
Step 6.对整个训练集样本T'1进行Tomek link 数据清洗完成欠采样,删除Tomek link 对中的多数类样本,更新训练集为 T″1
2.2 BSL-FSRF 算法
随机森林[14]作为一种改进的Bagging 集成方法,是集成学习领域中一个重要组成部分.文献[15]对179 个分类算法分别在121 个数据集进行了研究分析,结果表明RF 算法是最优秀的.网格搜索算法(Gridsearch)通过穷举法遍历所给定的参数组合来优化模型,遍历完成需要耗费大量训练时间,文献[16]提出了一种基于袋外数据估计的分类误差,改进了网格搜索算法,通过不断缩小网格间距,优化RF 的参数决策树数量k'和候选分裂属性数mtry,该方法克服了交叉验证的缺点,提高了训练速度,节省了时间.
基于重采样与特征选择的随机森林算法(BSL-FSRF)主要包括数据预处理阶段与分类两个阶段.
1)数据预处理阶段,从重采样与特征选择两个方面出发,首先对训练集中的样本进行BSL-Sampling,使样本基本达到均衡并去除噪声样本,更新训练集.其次对新的训练集进行ReliefF 特征选择,根据特征重要性进行一定的删减,再次更新数据集;
2)分类阶段,分类采用随机森林算法,并运用改进Gridsearch 网格搜索算法,先采用大步长进行大范围搜索,再进行小范围寻优,用于优化随机森林的决策树数量k'和候选分裂属性数mtry两个参数;最后进行基于混淆矩阵的分类模型的评价.
BSL-FSRF 算法的具体步骤如下:
算法 2.BSL-FSRF
输入:样本训练集D,抽样次数t,特征权重阈值σ.
输出:参数调优后随机森林分类器模型,以及分类结果.
Step 1.调用算法1,生成新的平衡样本训练集T″1
Step 2.对训练集T″1用ReliefF 特征选择算法,利用公式(3)赋予所有和类别相关性高的特征较高的权重,更新并得到新的数据集T″1;
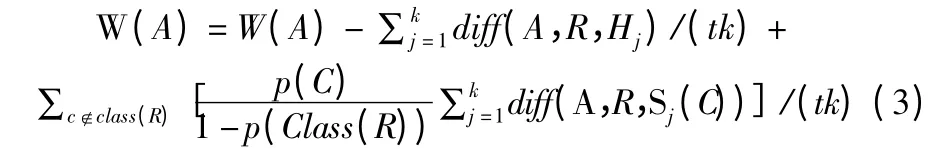
diff(A,R1,R2)表示两个样本 R1、R2在特征 A 上的差,R为训练集D 中随机选择的一个样本,Sj(C)表示类别C ∈Class(R)中的第 j 个最近邻样本,Hj(j=1,2,…,k)表示 R 同类中的k 个近邻.

Step 3.将 T″1作为随机森林的输入,采取 boostrap 采样,有放回地为每棵树构造训练集,大小为N.在每个节点处随机选择m 个特征,根据最小Gini 指数,比较并选择佳特征,划分数据集;
Step 4.递归生成决策树,不剪枝;
Step 5.根据公式(4))计算未知样本x 分类为M 的概率;
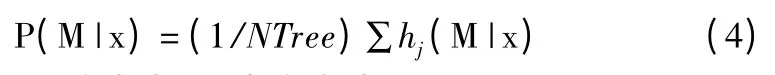
Step 6.采用多数投票法确定类别M ←arg max P(M |x),并计算分类误差;
Step 7.返回随机森林分类器模型,分类结果.
Step 8.通过改进的Gridsearch 算法选择合适的参数,优化生成决策树的数目k',候选分裂属性数mtry两个参数.网格搜索时,先选择较大范围的参数与步长,再逐渐缩小阈值范围与步长大小,不断调整搜索范围找到较优参数.
Step 9.返回参数调优后随机森林分类器模型以及分类结果.
Step 10.在测试集中T2中,测试调优模型的分类效果,并进行评价.
BSL-FSRF 整体算法流程图如图1 所示.
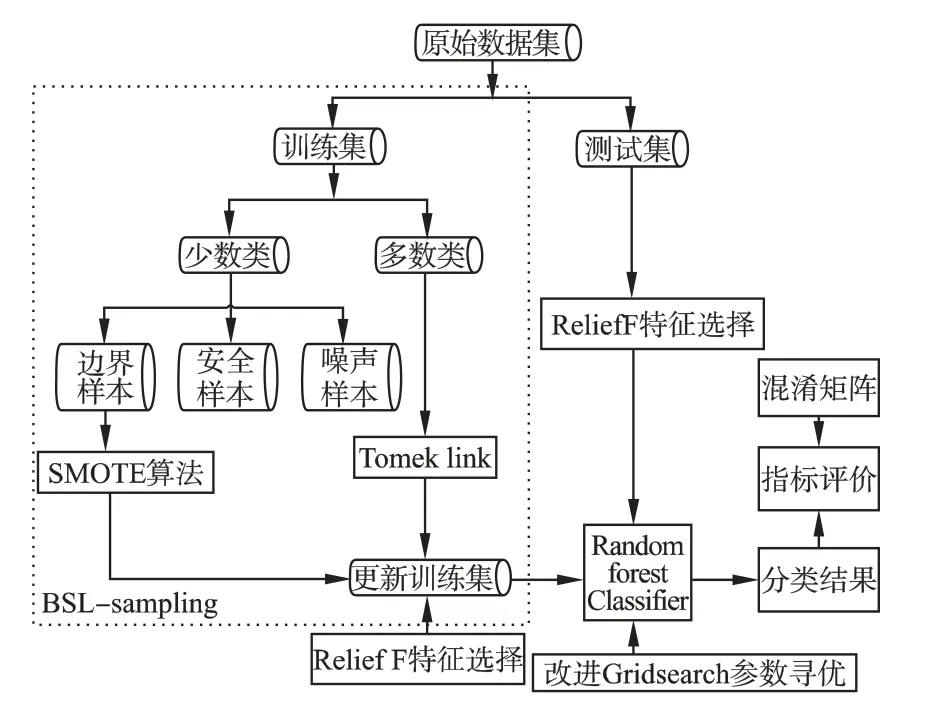
图1 整体算法流程图Fig.1 Overall algorithm flow chart
3 评价指标
传统的用于衡量分类模型性能的整体正确率(Accuracy)已不再适用不均衡数据集,会对分类结果产生误导.因此在处理不平衡的数据时,选择有效的评价指标是非常有必要的,不均衡数据分类模型评价指标通常在混淆矩阵的基础上,二分类混淆矩阵如表1 所示.

表1 二分类混淆矩阵Table 1 Two-class confusion matrix
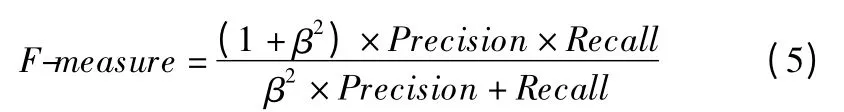
公式(5)中β 表示查准率(Precision)和查全率(Recall)的重要性相对关系,一般取值为1,表示两者的重要性相同.

其中F-measure[17]值是查准率(Precision)和查全率(Recall)的调和平均值;Kappa 系数评价分类器与真实分类之间的差异,此统计量越接近于1,表明分类器越优秀.ROC 曲线[18]的绘制需要经过调整不同的判定阈值,FPR 作为x 轴,TPR 作为y 轴,可以通过ROC 曲线评价一个分类器好坏,AUC 值越大,则正确率越高,分类器越好.
对于不均衡数据集,我们更加关注对少数类的分类结果,因此本文选取kappa 系数,少数类分类的F-measure 值以及ROC 曲线下的面积AUC 作为评价标准.
4 实验及结果分析
4.1 数据集
本文使用类别不均衡的二分类公共数据集对提出的算法进行验证,其中8 个数据集来自KEEL 数据库,2 个来自加州大学欧文分校提出的用于机器学习的UCI 数据库,具体信息描述如表2 所示,每个数据集的类分布是不均衡的,不平衡度IR(Maj/Min)从 1.79 到 41.4.(其中 glass 数据集代表 glass-0-1-2-3_vs_4-5-6)
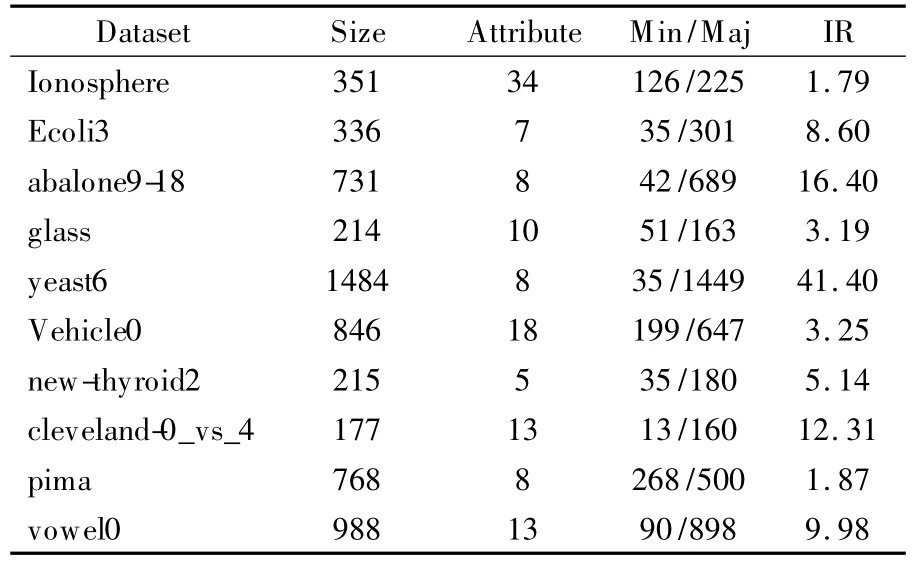
表2 二分类不平衡数据集Table 2 Two-class unbalanced data sets
4.2 实验及结果分析
4.2.1 实验设计思路
为了验证所提出的BSL-FSRF 算法在解决不均衡数据分类问题上的有效性,从四个角度进行相关的实验验证.
1)进行基础实验的验证.
2)分类阶段均采用RF,数据处理阶段采用SMOTE 结合不同的降维方法,记为 SMOTE-CFS、SMOTE-PCA 算法、SMOTE-ReliefF,分别与本文数据预处理阶段算法BSL-FS(FS 代表ReliefF 特征选择算法)进行对比.
3)数据处理阶段均采用BSL-FS 算法,分类阶段分别采用不同的分类器J48,Naive Bayes,Adaboost 与改进网格搜索参数寻优后的随机森林算法进行相应对比.
4)与其他相关算法的对比.
经过整体实验对比分析,证明本文所提出的BSL-FSRF算法在不均衡数据分类问题上体现出一定的优势.
4.2.2 参数设置
本文实验重采样算法用Jupyter Notebook 实现,分类算法基于Weka 平台.对BSL-FSRF 算法中ReliefF 的特征权值阈σ 的选取针对每个数据集的实际情况,进行了初步探索.采样算法SMOTE 的最近邻k 值是提高随机森林分类效果的关键参数,根据国内外学者大量的实验研究,表明在多种情况下当k 值取5 时[19],采样有很好的效果,借鉴其研究本文 k 值选取5,上采样倍率N 设为1,所有实验均采用10 折交叉验证(10-fold cross-validation).为提高实验的可对比性,AdaBoost集成算法基分类器的选取与随机森林保持一致,均为分类回归树(CART).
4.2.3 实验结果分析
将未经采样的随机森林RF 模型、只经过BSL 采样的BSL-RF 模型,只经过ReliefF 特征选择的FS-RF 模型和同时经过 ReliefF 与 BSL-Sampling 处理的 BSL-FSRF 模型(未进行参数寻优)在10 个公共数据集进行了基础实验比较,可以看出重采样与特征选择结合算法的BSL-FSRF 模型有一定的优势.经过BSL 采样前后数据分布如表3,ReliefF 算法在10个数据集上各特征权重比较如图2,表4 给出了选取的各个数据集特征信息,分类后的结果如表5 所示,其中AVG 行代表10 个数据集上各少数类评价指标的平均值.
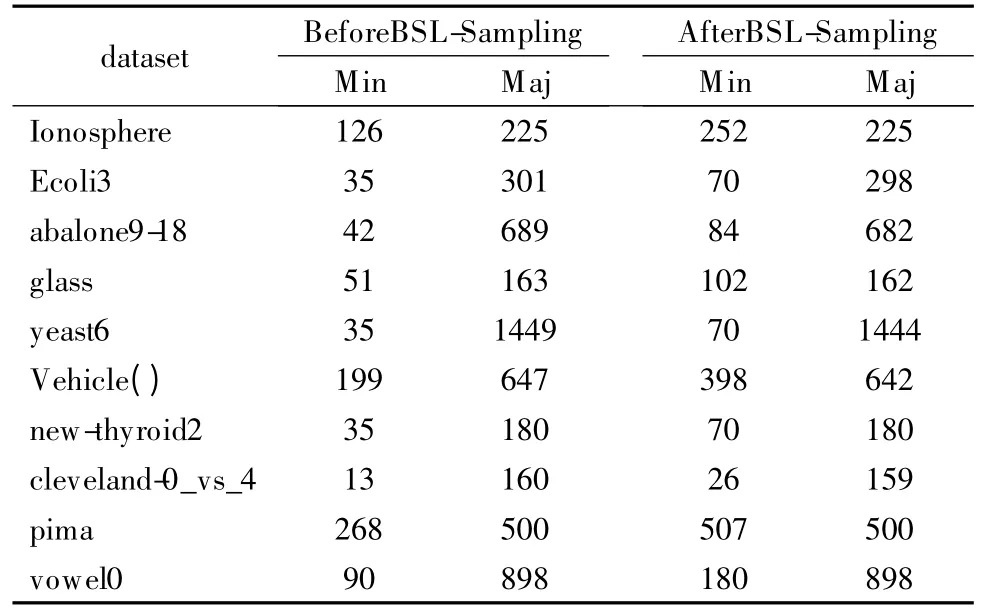
表3 BSL-Sampling 前后数据分布Table 3 Data distribution before and after BSL-Sampling
分析各数据集上不同特征的权重,认为出现负值的情况表明该特征起到负作用,直接将其删除.经过对ReliefF 算法阈值的初步探索,所选取的特征如表3 所示.分析表3,经过 BSL-sampling 算法在一定上采样比率处理后数据的不均衡性得到了很好的改善且去掉了部分噪声样本.从表5 可以看出,同RF算法相比,BSL-FSRF 算法Kappa 平均值从69.0%提升到86.1%,F-measure 平均值从 73.2%提升到 89.7%,AUC 平均值从94.4%提升到97.32%,本文方法在评价指标 Kappa 系数,F-measure 以及AUC 上都有一定的提升;经过重采样,均衡了样本分布,ReliefF 特征选择算法算法根据给定的权重进行数据的降维,减少冗余特征,使分类具有更好的效果,BSL-FSRF 算法比分别单个使用ReliefF、BSL-sampling 算法的使用具有更高的泛化能力,相对未采样各个指标有一定提升.
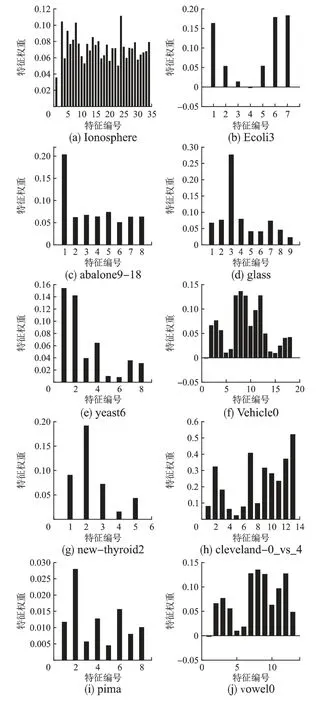
图2 特征权重比较Fig.2 Comparison of feature weights
为了比较数据处理阶段的BSL-FS 算法的性能,分类器均使用RF,将本文算法与SMOTE-CFS 算法、SMOTE-ReliefF算法、文献[9]中提出的SMOTE-PCA 算法在不平衡不比不同的10 个数据集上进行了对比,用柱状图对比了三种不同的方法在两个指标上的少数类的平均值,更加清晰直观,其F-measure、AUC 值分别如图3、图4 所示,数据集按照表1 顺序进行编号分别为1-10.
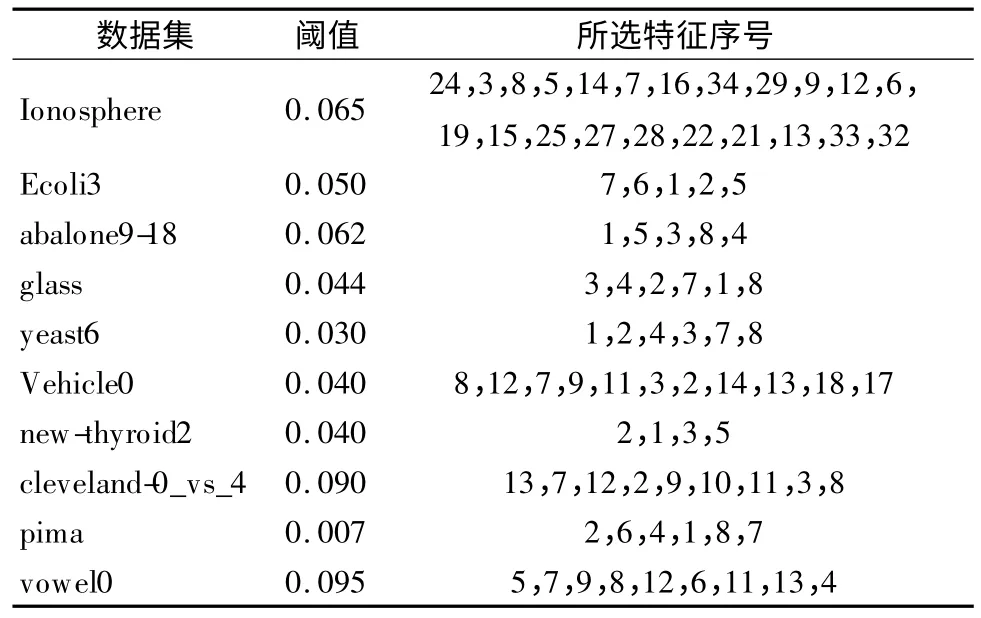
表4 选取的特征信息Table 4 Selected feature information
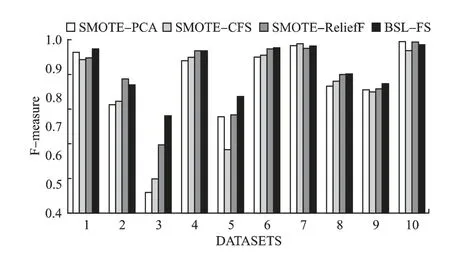
图3 不同数据处理在10 个数据集上F-measure 对比Fig.3 Comparison of F-measure values on 10 data sets for different data processing
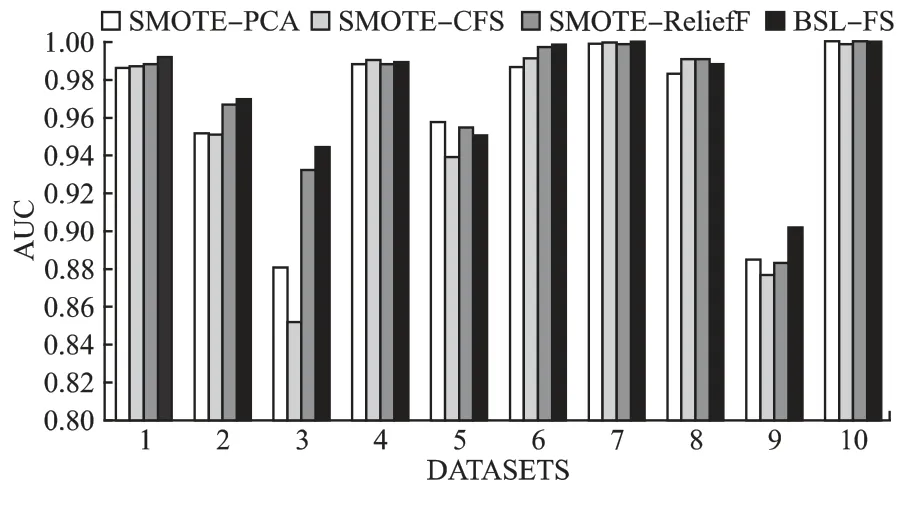
图4 不同数据处理在10 个数据集上AUC 值对比Fig.4 Comparison of AUC values on 10 data sets for different data processing
分析图3 和图4,数据集上的AUC 值没有显著地改善,但是本次实验算法侧重点在于预处理阶段方法即BSL-FS的对比,所以更多关注评价指标 F-measure,7 个数据集上F-measure 都有一定的提升,在数据集Abalone9-18 上,BSL-FS算法比SMOTE-PCA 算法提升 26.3%,比 SMOTE-CFS 算法提升了21.7%,比SMOTE-ReliefF 算法提升了9.9%,因为主成分分析法按照各个特征的贡献率取一定的特征个数,因此可能会有部分重要信息的丢失.
进一步验证BSL-FSRF 算法的有效性与通用性,预处理阶段均选用 BSL-FS 进行处理,分别选取J48,Naive Bayes,Adaboost 分类器进行研究,并优化随机森林参数决策树数量k'和候选分裂属性数mtry两个参数,寻优过程以abalone9-18数据集和对k'的优化为例.因为随机森林算法在默认参数下能取得较好的分类效果,其它参数均保持一致,用袋外数据进行分类误差估计,在100 附近先进行大步长搜索,范围设置为[0,200],步长为20,经过搜索,在决策树数量为60 时最优,范围缩小至[40,80],步长缩小到 5,依旧为 60 最优,[55,65],步长设为1,搜索后当数量为63 时最优.实验结果kappa值以及少数类的F-measure、AUC 值,如表6 所示,图5 给出了四种算法在所选取的6 组数据集(Ionosphere、abalone9-18、yeast6、Vehicle0、cleveland-0_vs_4、pima)上的 ROC 曲线图.
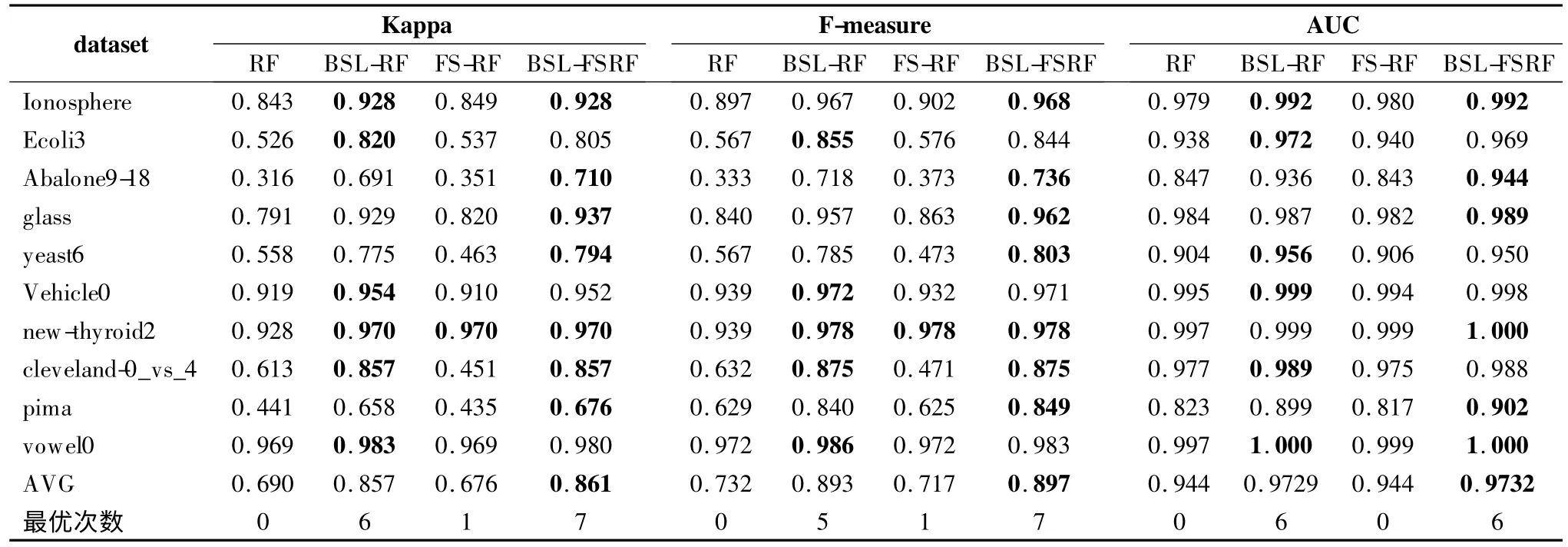
表5 不同方法的 kappa 系数 F-measure、AUC 值比较Table 5 Comparison of kappa coefficient F-measure and AUC values of different methods
分析实验结果,BSL-FSRF 算法对在三个评价指标上有一定提升,取得最优次数最多且均值最高.从表6 看出相较于J48 决策树与朴素贝叶斯算法,集成方法有一定的优势,Ada boost 仅次于RF,相较取得较好效果的BSL-FSAdaboost 算法,在 Kappa 系数上提高了 1.5 个百分点,F-measure 提高了0.9 个百分点,AUC 提高了 1.0 个百分点,RF 比 Adaboost 算法在pima 数据集上提升效果更明显.另外,对比表5 与表6中BSL-FSRF 算法三列可以看出,经过改进的Gridsearch 参数寻优选定合适参数后分类器性能有一定提升.
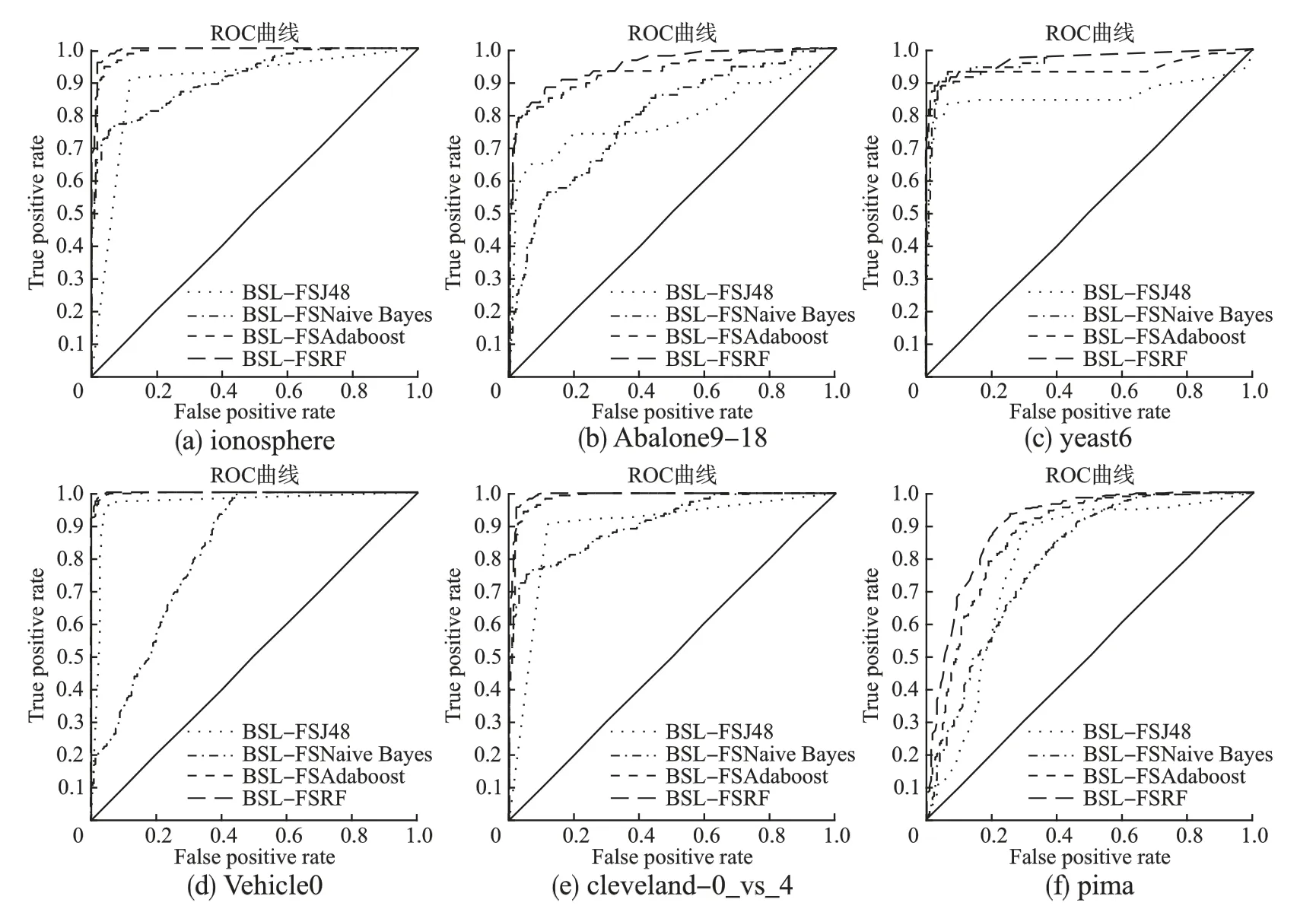
图5 不同分类器在6 个不同数据集上的ROC 曲线对比Fig.5 Comparison of ROC curves of different classifiers on 6 different data sets
将 SMOTEBoost,SMOTEBagging,RUSBagging 相关算法与BSL-FSRF 算法进行对比,结果如图7-图9 所示.分析可知,BSL-FSRF 算法在8 个数据集上表现良好,因为BSL 采样算法限定了边界且删除了部分重叠样本,改善了SMOTE 算法容易产生模糊边界的问题;其次是RUSBagging算法,相较于 SMOTEBagging 算法,RUSBagging 算法结合了 SMOTE 与RUS-Sampling 采样算法,进一步验证了结合过采样与欠采样算法的有效性.

表6 不同分类方法下AUC、kappa 系数、F-measure 比较Table 6 Comparison of AUC,kappa coefficient and F-measure under different classification methods
从10 个二分类数据集的实验结果对比可以看出,相对于文中的其他方法,BSL-FSRF 算法可以较好地解决数据失衡问题,对不均衡数据分类的各个指标都有一定的提高,整体上算法性能较优.
5 结束语
本文从特征选择与重采样方法出发提出了一种BSL-FS-RF 算法.该算法:1)提出BSL-Sampling 算法进行数据均衡化重采样;2)删除几乎没有相关性的噪声数据,然后人工插入数据,在一定程度上提高了不平衡数据集的分类性能;3)引入“假设间隔”思想,对数据集各个维度特征进行度量,通过设定合适的阈值,移除与类别相关性较小的特征,通过去除冗余达到降维的目的,克服了原始数据中噪声数据可能会引起数据分布改变的不足,为维度较高的二分类问题提出了解决思路,并可扩展到多分类;4)以集成算法随机森林作为分类器,并进行Gridsearch 参数寻优,改进寻优方式,节省了运行时间,相较于传统网格搜索算法,当数据维数越多,节省时间越多,优化后的参数能一定程度上提高随机森林的分类性能.从实验结果可以看出,BSL-FSRF 算法适用于大多数不均衡数据集,但是不适用于每一个数据集,本文的算法从特征选择与采样方法进行的研究,进一步优化采样方法增强决策边界可作为今后研究的切入点.
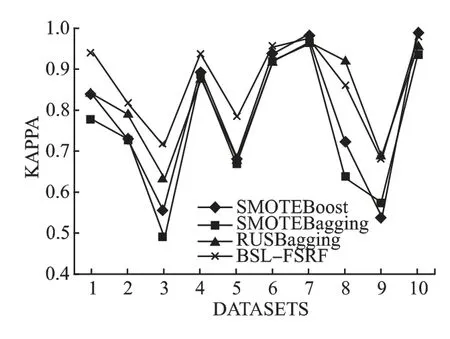
图7 10 个数据集上的Kappa 系数对比Fig.7 Comparison of Kappa coefficients on 10 data sets
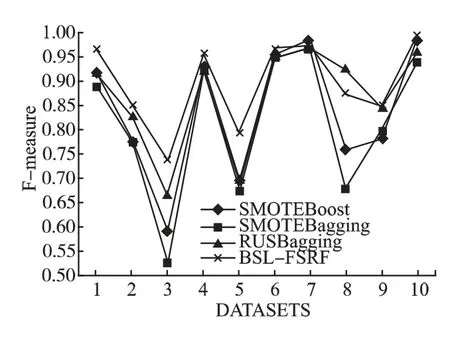
图8 10 个数据集上的F-measure 值对比Fig.8 Comparison of F-measure values on 10 data sets

图9 10 个数据集上的AUC 对比Fig.9 Comparison of AUC values on 10 data sets
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机研究与发展(2022年1期)2022-01-19
计算机系统应用(2021年2期)2021-02-23
软件导刊(2017年4期)2017-06-20
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
