
基于PAM聚类的学科队伍构建方法研究*
2020-06-10 03:38张月
图书馆研究与工作 2020年6期
张 月
(淮阴工学院高等教育研究所、学报编辑部 江苏淮安 223001)
1 引言
2015年8月18日,中央全面深化改革领导小组会议审议通过《统筹推进世界一流大学和一流学科建设总体方案》并于同年11月由国务院印发,决定统筹推进建设世界一流大学和一流学科,学科建设被提到了重要的战略高度。2017年10月18日,习近平同志在十九大报告中指出,“要加快一流大学和一流学科建设”[1],为高校的发展指明了方向。随着“双一流”建设的推进,全国高校掀起了加强学科建设的高潮。学科是高校发展最基本、最基层的学术组织,学科建制虽小,但学科建设却是一项复杂的、宏大的系统工程[2],主要包括制度建设、人才队伍建设、基地与平台建设、人才培养、学术研究五个方面的内容。其中人才队伍是学科建设的主体,是学科建设的决定性因素[3]。作为地方高校,学科队伍建设的质量直接决定着学科建设的质量。
目前,学科队伍主要通过一些传统的方法建立,如依据学科带头人的带动方式来建立,学科带头人确定学科定位,做好业务表率,通过选拔、培养与引进人才的方式建立学科队伍[2,4-5]。这是一种行之有效的学科队伍构建方法,但也存在缺陷,如过于依赖学科带头人的带动作用,无论从学科带头人的选定还是从学科带头人自身的素养与业务能力来看,都存在着许多不确定因素,一旦出现学科带头人能力不足或判断失误等问题,就可能会导致学术队伍向着不恰当的方向去发展。同时,这种传统的学科队伍建设方法还存在着学科方向相对固定,难以快速吸引不同学科方向人才加入队伍,进而通过学科交叉等方式产生新方向的问题。随着学科建设的不断发展,科技创新的要求不断提高,学科交叉正成为新形势下学科产生新方向的主要方式。学科交叉不能通过生硬的嫁接方式仅依靠学术带头人指定,而应该从现有的学术人才库中通过信息化等手段去发掘。
本文从学术人才的科研成果数据分析着手,运用数据聚类技术发现科研成果的内在联系,从而将科研成果相似度高、学科交叉可能性大的学术人才汇聚到一起,构建科学合理的学科队伍。聚类方法不同于分类方法,它不指定分类标准,只通过数据分析得到自然聚类,能够得到潜在的知识[6],因此,运用聚类方法构建学科队伍时能够获得未经指定的学科方向,它可能与现有的学科队伍代表的学科方向一致,也极有可能是潜在的学科交叉新方向。对于高校而言,在“双一流”建设大力推进的大好时机下,这种相对快速合理的信息化方法能够为学科建设提供强劲有力的支持,为高校的学术创新与科研实力提升提供更加广阔的空间。
2 学科成员相似度度量
学科成员的科研成果决定了他的科研方向。本文通过对学科成员科研成果的分析发掘其内在联系,对科研人员进行聚类,将科研方向相似度大的科研人员归为一类,进而构建学科队伍。运用聚类算法,首先要确定学科成员的相似度,学科成员的相似度则是基于文献相似度度量确定的。目前,多种文献相似度计算方法如利用词频向量空间模型VSM[7]、利用语义角色标注[8]及通过构造领域本体进而进行文献相似度计算的方法[9]等,这些计算方法往往存在着当运用不同的概念抽取方法时抽取的概念差异较大的问题,其对计算结果的影响也很大,抽取方法的准确程度制约了相似度计算。学科队伍的建设是基于科研人员研究领域的相似或相关程度,对于学术人才发表的科研成果而言,只要取其所在领域,分析其与别的科研人员的研究领域相似度就足够了。为叙述方便,文中提到的文献仅指代科研论文。本文利用中国图书馆分类法(以下简称“中图分类法”),结合文献作者与领域专家的意见将文献进行分类,进而通过类间相似度的确定来定义文献的相似度。在文献数据量比较小的情况下,这种分类方法的精准度高,能够为文献相似度的度量提供可靠的计算基础。
2.1 文献的预处理
为了计算文献相似度,需要先将文献按中图分类法进行分类。一般情况下,中文文献自身带有文献分类号,中国知网等数据库也有为文献分配的文献分类号,在计算精度要求不高的情况下,可以就这两种文献分类号运用本文提出的计算方法计算文献间的相似度,进而进行粗略聚类。当需要更加精确的学科队伍聚类结果时,往往需要作者与领域专家重新分配文献分类号。另外,外文文献也需要通过类似的方式加上中图分类号,对于已有分类号的外文文献可以通过相关转换[10]实现与中图分类号的统一。
对于一篇文献而言,一个分类号往往不能概括其所在的领域,这时可以对一篇文献分配多个分类号,对于存在学科交叉的文献而言一般分配两个分类号比较恰当(当文献分类号过多时其分类权重也逐渐减少,为叙述方便,本文研究的数据将文献分类号限制在三个以内)。当一篇文献的分类号不止一个时,还需要对不同的分类号分配不同的权重,这是因为文献涉及的领域侧重程度是不同的,如表1所示。
2.2 基于中图分类法的文献相似度度量方法
基于中图分类法的文献相似度度量方法原理是在文献分类的基础上考察两文献所在类之间的相似度,以确定两文献的相似度。当两文献处于不同的底层分类中,将其相似度称为类间相似度;当两文献处于相同的底层分类中,称其为类内相似度,需考察此类内文献间的相似度。类间相似度与类内相似度根据分类号目录深度与分类相关度综合专家意见定义。
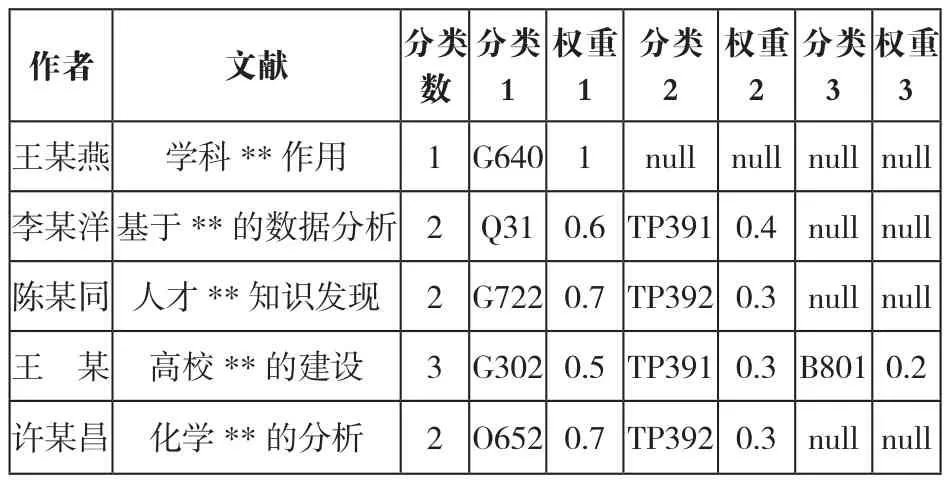
表1 文献分类号分配示例
文献相似度的定义遵循以下四个原则:①类间相似度定义值的赋予仅限于从同一个类划分出的多个类,即从不同的高层类划分出的类之间不具有相似度定义值,如图1所示,A1与A2之间相似度定义值为0.12,而A2与B1之间由于不存在共同的上一级类,其类间无直接的相似度定义值;②从同一个高层类划分出的所有类之间的相似度值是相同的,如A21与A22的相似度值为0.26,A21与A23之间的相似度值为0.26,A22与A23之间的相似度值也为0.26,它们具有相同的高层类A2;③高层类划分到低层类后,得到的类间相似度大于高层类间相似度,如A11与A12两类的相似度总高于A1与A2之间的相似度,层级越高,同层类间的相似度越低;④任何两个类或文献之间的相似度都不大于1。

图1 基于中图分类法的文献相似度定义示例
处于底层的类,除了类间的相似度需要定义之外,还需要定义类内文献的相似度,以便于衡量两文献处于同一个底层类时文献间的类内相似度。
2.3 文献相似度的计算
以an表示文献,其中n为文献序号,n>0,以clp表示中图分类号所代表的类,p>0,以Db函数表示文献间相似度,Dc函数表示类间或类内相似度。为叙述方便,先考察任一文献只有1个中图分类号的情况。利用上述文献相似度定义,可以确定两文献am与an之间的相似度:当am与an属于两个不同的底层类时,寻找两文献所在类之间的相似度定义值,若无定义值,则向上一级寻找其父类之间的相似度定义值,直到找到有相似度定义值的两个类clp与clq为止,则两文献的相似度即为此两个类的相似度定义值,即Db(am,an)=Dc(clp,clq);当am与an属于同一底层类即p=q时,文献间的相似度可以表示为Db(am,an)=Dc(clp,clq)或Db(am,an)=Dc(clp),此时Dc(clp)表示的是底层类clp的类内相似度。
根据上述文献相似度计算的方法,考虑文献具有多个中图分类号的情况,即文献的中图法分类数大于1的情况。对于某个文献而言,它可能属于多个中图法类,不同的类具有不同的权重,文献分类相关的参数表示方法如表2所示。

表2 文献参数表示法
其中,an_t取值范围为{1,2,3},文献具有的分类表示为an_clt,分类对应的权重为an_wt。若an_t=3,则文献an具有3个分类,它们分别是an_cl1,an_cl2和an_cl3,这3个类对应的权重分别是an_w1,an_w2和 an_w3。任意两文献am与an之间的相似度可以通过两文献所属类间的相似度计算确定:
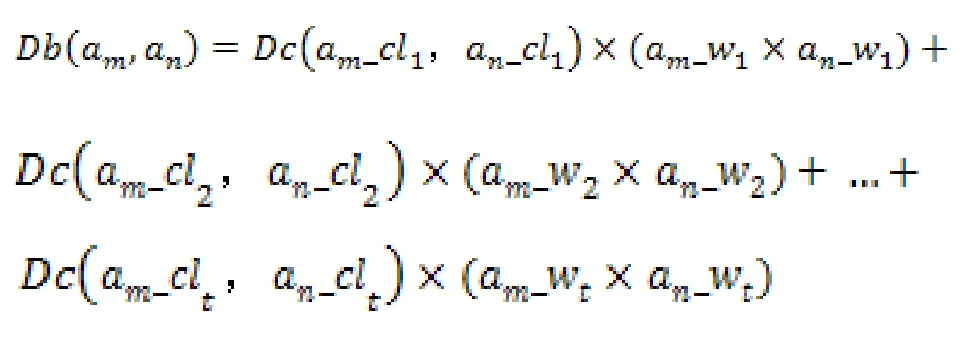
此相似度计算公式考虑了文献所具有的不同类所占的权重因素,同一篇文献具有的所有类的权重之和为1。显然,文献a与文献b的相似度和文献b与文献a的相似度计算值是相同的,
2.4 学科成员相似度的度量
学科成员相似度的度量可以通过考察其科研成果的相似度确定,通常情况下,学科成员会有多个科研成果即科研成果集,考察两个学科成员的相似度即是计算其科研成果集的相似度。在上述文献相似度度量的基础上可以进一步定义科研成果集的相似度度量方法。以学科成员A的单一科研成果与学科成员B的所有科研成果逐一进行比较,将结果相加即可得到A的单一科研成果与B的科研成果集的相似度,将学科成员A的所有单一科研成果与B的成果集进行比较即可得到A与B的总相似度。这种相似度的度量方法不同于生硬地使用欧几里得距离函数的方法,它在文献相似度度量的基础上考虑两学科成员成果集的相似度,能有效地反映出学科成员科研成果集的领域相似度。
设有学科成员A(a1,a2,…,an),即A的科研成果集为{a1,a2,…,an},其中an表示其科研成果,n>0;学科成员B(b1,b2,…,bk),科研成果集为{b1,b2,…,bk},其中k>0,假设上述两者的任一科研成果只属于1个中图法类,即任一文献的中图法分类数都为1,则学科成员A与B的相似度S(A,B)可以通过以下公式计算:
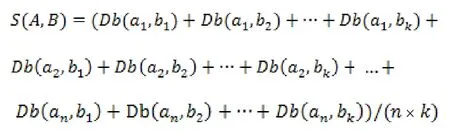
考虑到不同的学科成员科研成果量虽然不同,但作为科研主体,每个学科成员的总成果量应具有相同的权值,即不论其科研成果量多少,计算两个学科成员的成果相似程度时应保证两个学科成员的重要性是一致的。基于此,在计算相似度时应将任一学科成员的任一科研成果赋予相同的权重,若科研成果量为n,则单篇文献所占权重应为1/n。两个学科成员的相似度计算应为:文献两两比较相似度之和/(n×k),其中n×k为两学科成员的所有文献两两比较的次数,则单次比较在所有比较次数中所占的权重为1/(n×k)。显然,学科成员A与学科成员B的相似度和学科成员B与学科成员A的相似度计算值是相同的,即S(A,B)=S(B,A)。
3 利用PAM算法进行学科成员聚类
相较于传统的指定学科带头人或指定学科方向建立学科队伍的方式,聚类方法的优势在于它是基于数据分析的自动化过程,能发现潜在的学科交叉方向,同时凝练出相应的学科队伍,能够跟随数据的更新随时调整学科队伍的成员。本文采用基于划分的聚类算法,目前相关的典型算法有K平均与K中心点算法[6]。K平均算法需要计算簇中对象的平均值,且对“噪音”和孤立点(离其他数据点非常远的数据点)敏感。由于学科成员的科研成果数量不一,科研方向多样,导致“噪音”和孤立点较多,故而不适用于学科成员数据的聚类。PAM算法是典型的K中心点算法,相较于其他的划分聚类算法,PAM算法对“噪音”和孤立点数据不敏感,且能够处理不同类型的数据,适用于学科成员的聚类计算。
3.1 PAM算法概述
PAM算法的目的是对n个数据对象给出k个划分。PAM算法的基本策略[11]:先为每个簇随意选择一个代表对象(中心点),剩余的对象根据其与代表对象的相异度或距离分配给最近的一个簇。然后反复地用非代表对象来替换代表对象,以提高聚类的质量;聚类质量由代价函数来估算。该函数用来判断一个非代表对象是否是当前某代表对象的好的代替,如果是则进行替换,否则不替换,最后给出正确的划分。代价函数的计算基于学科成员相似度的计算。
3.2 算法过程
为了在学科成员数据库D中找到k个学科成员簇,需要为每一个簇定义1个代表成员。该代表成员被称为中心点,即这个代表成员是其所在的簇中最中心的学科成员。当k个中心点选定以后,剩余的n-k个非选中成员被划分到k个簇中,划分规则是:将非选中成员划分到离它最近的代表成员所代表的簇,为此,需要依据学科成员相似度计算方法确定非选中成员到代表成员的距离。
为了找出k个中心点,PAM算法首先随机地选择了k个学科成员。然后在每一步中,用一个非选中成员Rh替换一个选中成员Ri,只要这样的替换能够提高聚类质量。为了估量Rh与Ri之间替换的效果,PAM算法为每一个非选中成员Rj计算代价Cjih。根据Rj属于下列哪种情况,Cjih用不同的公式定义。
第一种情况:Rj当前属于Ri所代表的簇,并且Rj离Ri2比Rh近,即此处Ri2是Rj的第二接近中心点。这样,如果Ri被Rh替换作为中心点,Rj将属于Ri2所代表的簇,因此就Rj而言替换的代价为:
第二种情况:Rj当前属于Ri所代表的簇,并且Rj离Rh比Ri2近,即此处Ri2是Rj的第二接近中心点。这样,如果Ri被Rh替换作为中心点,Rj将属于Rh所代表的簇,因此就Rj而言替换的代价为:
第三种情况:Rj当前属于另一个非Ri所代表的簇,Ri2是Rj所属簇的代表成员,并且Rj离Ri2比Rh近,即这样,如果Ri被Rh替换作为中心点,Rj将留在Ri2所代表的簇,因此就Rj而言替换的代价为:
第四种情况:Rj当前属于另一个非Ri所代表的簇,Ri2是Rj所属簇的代表成员,并且Rj离Rh比Ri2近,即这样,如果Ri被Rh替换作为中心点,Rj将从Ri2所代表的簇中跳入Rh所代表的簇中,因此就Rj而言代价为:
综合考虑以上四种情况,对所有n-k个Rj的代价Cjih求和,用Rh替换Ri的总代价为:此处符号Σj表示对当前所有n-k个非中心点成员Rj的代价Cjih求和。
算法处理流程如下:
算法:学科成员数据的PAM聚类
输入:预期学科成员簇的数目k,包含n个学科成员及其对应科研成果(文献)的数据库;
输出:k个学科成员簇,使得所有学科成员与其最近代表学科成员的相似度总和最大;
Step1:随机选择k个学科成员作为初始的代表成员;
Step2:repeat;
Step3:指派n-k个剩余的学科成员给离它最近的中心点所代表的簇;
Step4:对于代表对象Mi,任意选择一个非代表学科成员Mh;
Step5:计算用Mh代替Mi的总代价;
Step6:如果TCih<0,则用Mh替换Mi形成新的k个代表学科成员的集合;
Step7:until所有形成的k个学科成员簇不再发生变化。
需要说明的是,算法中涉及任意两个成员距离与替代代价的计算都离不开学科成员相似度的计算,因为相似度与距离是相反的,即相似度越大,距离越远,因此距离计算本质上与相似度计算是可以直接换算的。运用上述PAM聚类算法时需要输入预期得到的学科成员簇数量。当输入不同的初始簇数值时,得到的聚类结果必然不同,一方面,调整初始簇数目增加了学科建设需要考虑的因素,不恰当的初始簇数目的输入可能会导致不恰当的聚类结果;另一方面,通过对初始簇数目的调整可以得到多样化的聚类结果,有利于对比分析,根据结果的合理性人为地在更多的可能结果中做出最恰当的选择。预期学科成员簇数量的确定需要考虑的因素主要有原有的学科队伍数量、每支学科队伍的大致人数及科研群体的科研能力等,原则上可以在原有的学科队伍数量上逐步加大,通过分析选取最恰当的值。
4 实验与分析
以某高校学科队伍建设为例,以2018年元月为时间基准点,以该校所有教职工近五年的科研成果作为分析数据,预期聚类结果12个成员簇。经筛选形成该校所有符合近五年内有科研成果的学科成员基本信息表,学科成员数为516,其片段如表3所示。

表3 学科成员信息表片段
与表3对应的是所有学科成员的科研成果表,经数据收集与整理,基于CNKI数据库已标注的中图分类号,结合领域专家意见确定科研成果的分类及其权重,形成学科成员成果表,其片段如表4所示。
根据该校原有学科队伍数量与队伍的平均成员数,调整聚类预期簇数为12,同时将以上两表作为基础数据,经PAM算法处理,最终得到12个聚类簇。为方便表示,将其统计结果片段如表5所示。
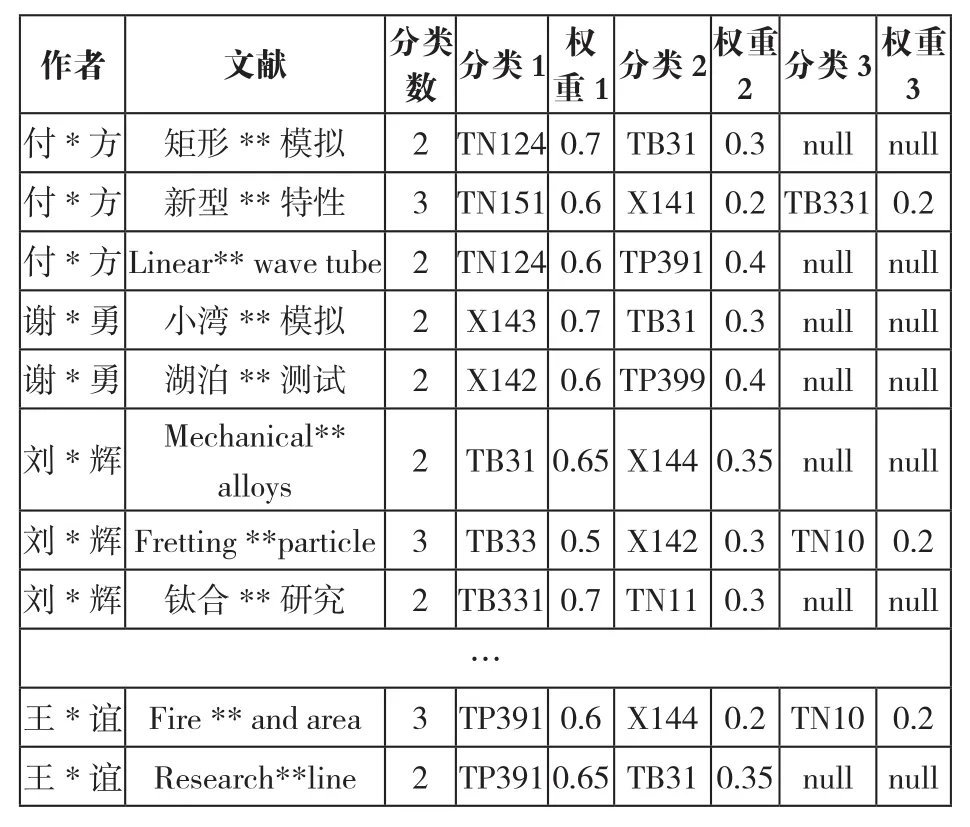
表4 学科成员成果表片段
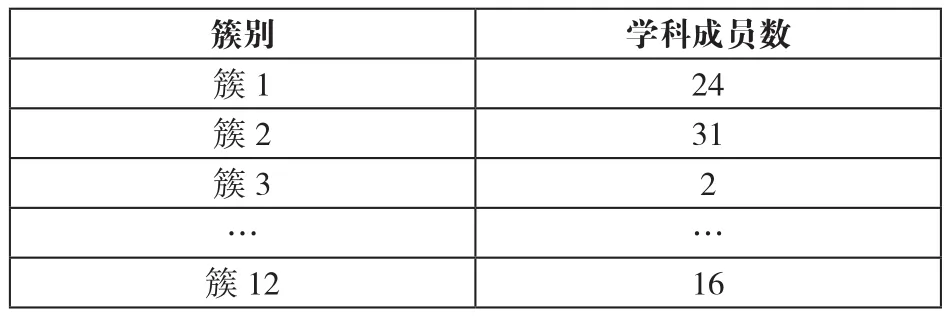
表5 聚类结果统计片段示例
分析聚类结果,发现其中10个簇与原有的学科队伍数量、各学科队伍成员构成基本一致,另2个簇不一致,其中簇3人数较少不具备构成学科队伍的条件,簇12从学科成员数量与学科方向来看符合学科队伍构建的条件。经分析簇12中学科成员普遍存在2-3个研究领域有交叉的科研成果,如通信与信息系统、环境工程、有色金属。我们将该簇称为有效簇,其相关数据片段如表6所示。
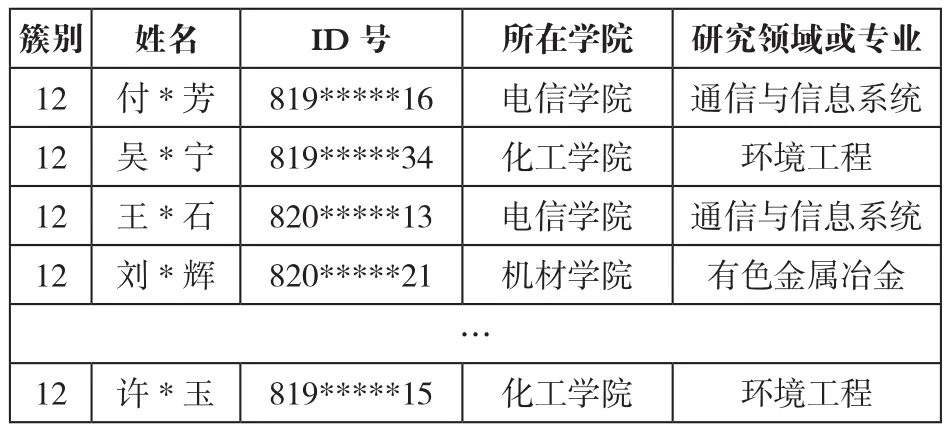
表6 有效簇相关数据片段示例
预期的簇数对结果的影响很大,如果对聚类结果不满意可以调整预期簇数作为输入重新计算,直到得到合适的聚类结果为止。
通过上述实验结果得到的学科队伍与传统的通过指定学科成员的方法建立的学科队伍对比可以看出,本文的方法能够得到一些难以人为发现的学科方向,同时列出对应的学科成员构成,这是传统的方法难以做到的。但是初始的聚类结果可能会存在少许不合理的情形,如科研成果相关度并不大的某个成员被纳入某个簇中,这是因为原始数据中出现的人员必会被分配到某个簇中,从数据聚类的角度上来看这种分配是合理的,但是从实际学科相关性上来看却未必合理,这时就需要在聚类结果的基础上加以人工分析,从相关簇中剔除一些不合理成员以达到优化聚类结果、实现学科队伍合理构建的目的。
5 结语
本文针对学科成员的科研成果数据的特性提出了科研成果的相似度计算方法,进而提出学科成员相似度的度量方法,运用基于划分的PAM聚类算法对学科成员进行聚类,以期找出合理的学科队伍的成员构成。实验结果表明,本文提出的学科队伍构建方法是有效的,相较于传统的学科成员构建方法,它能发现潜在的难以确定的学科方向,同时列出对应的学科成员,结合人工分析对结果进行优化,构建合理的学科队伍。运用信息化处理的手段从海量的数据中分析并得到合理的学科队伍聚类,对于当前大力开展学科队伍建设的科研院所与高校来说是有益的尝试,尤其对于需要寻找学科交叉新方向的机构而言,它的作用更加明显。目前相关研究虽处于初级阶段,但是相较于传统的学科队伍建设方法,它的优势是显而易见的,随着相关研究的进一步深入、各种信息化方法的不断完善,相信学科队伍建设必将越来越科学、越来越合理,也必能为我国的学科建设提供更多的选择,为“双一流”建设提供强有力的技术支持。
猜你喜欢
水运工程(2022年7期)2022-07-29
计算机技术与发展(2020年8期)2020-08-12
新世纪智能(英语备考)(2020年3期)2020-08-11
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
课程教育研究·新教师教学(2016年1期)2017-04-10
大众摄影(2015年9期)2015-09-06
现代教育科学(高教研究)(1998年1期)1998-09-13
