
多标签文本分类模型对比研究
2020-07-25 02:48姜炎宏迟呈英战学刚
辽宁科技大学学报 2020年2期
姜炎宏,迟呈英,战学刚
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
智能化时代,人们日常接触到的文本信息数量呈现出爆炸式增长趋势。文本作为信息载体,以各式各样的形式流入互联网中。随着文本分类技术的快速发展,对文本信息内容进行高效的管理已经成为必然趋势。标注多标签的形式能够更好地反应出文本信息的真实意义,更加有效地发掘信息、使用信息和利用信息库。
根据样本数据关联标签个数,文本可以分为单标签文本分类和多标签文本分类[1]。为了提高网上信息的检索效率,单标签文本分类已经不能满足需求,多标签分类也就自然而然地出现了。多标签分类问题是指文本信息内容上的多样、复杂的分布性以及庞大的规模性,文本内容通常会和多个标签相关联,将标签映射到分类类别中就演化为多标签分类问题。对这类问题的研究已经逐渐成为文本分类领域的热点问题之一。
传统的文本分类方法[2]是通过人为设计提取规则对文本内容进行特征提取。特征提取是将文本中与分类结果相关联的内容筛选出来,降低冗余特征对结果的负面影响。由于是人为设计提取规则,如果文本内容相关领域发生改变,则需要重新设计提取规则。这种做法不仅扩展性较差并且耗时耗力,导致用户体验感很差。
随着在线文本数量增长和机器学习的兴起,基于深度学习的多标签文本分类方法也随之涌现。2000 年 Tom Μitchell[3]等将大量未标记文档与少量的带标签的文档混合在一起进行训练。2014年Yoon Kim[4]使用卷积神经网络(Convolutional neural networks,CNN)进行了一系列的对比实验,为进行句子级的文本分类任务提供便利。2016 年 Liu[5]等介绍了循环神经网络(Recurrent neural network,RNN)应用于多标签分类问题的设计方式和方法,模型利用最后一个词组表示文本的特征并连接全连接层,使用Softmax函数输出各个类别。
深度学习的方法对多标签文本分类问题进行求解过程中,最重要、最根本的是使文本内容得到良好的表达。本文首先提出使用文本循环神经网络(TextRNN)模型和文本卷积神经网络(TextCNN)模型进行多标签文本分类实验。TextRNN擅长处理序列结构,并且能够考虑到句子的上下文信息,但是整体运行速度过慢。TextCNN属于无偏模型,对文本浅层特征的抽取能力很强。对于长文本领域,TextRNN主要依据filter窗口抽取特征,在长距离建模方面能力受限,且对语序不敏感。为了解决二者的局限性,本文提出将TextRNN与TextCNN融合,并且引入Attention机制,使模型可以将注意力聚焦在对文本分类结果贡献较大的文本特征上面。
1 文本分类
1.1 文本分类定义
文本分类是指根据文本语义内容将未知类别的文本内容归类到已知类别集合中的过程。设有一个文本数据集合D={d1,…,d|D|}和已知的类别集合C={c1,…,c|C|},文本数据集合和类别集合之间的关系可由下列函数表示[6]
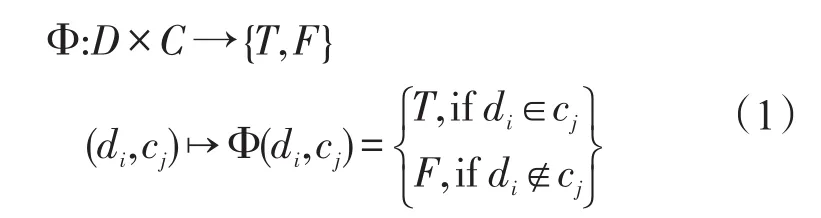
文本分类问题可以转化为找到函数⌒Φ代替Φ作为一种近似表示,目的是⌒使得函数Φ尽量逼近未知的真实函数Φ。函数Φ相当于文本分类器,可以反映出文本内容和标签类别之间的关系。训练效果优秀的分类器可以对未知标签类别的文本内容进行准确地分类,从而实现自动多标签文本分类。
1.2 Adam优化算法
Adam算法是一种对随机目标函数执行一阶梯度优化的基于适应性低阶矩估计的算法。Adam算法在2014年由Kingma[7]提出,文本数据在训练过程中不断地迭代,从而不断地更新神经网络权重。
Adam算法不同于随机梯度下降算法。随机梯度下降法在训练过程中学习率不会改变,而Adam算法通过第一和第二矩估计,计算不同参数的自适应学习速率。Adam优化算法收敛的速度较快,效果明显,实现简单,适用于非稳态目标,需要极少量的调参,对计算机内存要求低并且有很强的计算能力。
1.3 Attention机制
Attention机制[8]是模仿人类注意力而提出的一种解决问题的办法,简单地说就是从大量信息中快速筛选出高价值信息。受到计算能力限制和优化算法限制,引入注意力机制可以帮助神经网络模型处理信息过载,提高神经网路模型处理信息的能力。在RNN模型中,用来解决由长序列到定长向量转化而造成的信息损失的瓶颈,如图1所示。
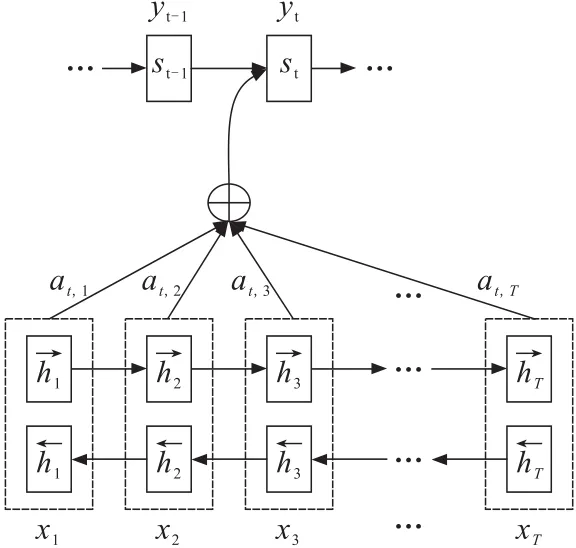
图1 引入Attention的RNNFig.1 RNN using attention mechanism
引入Attention的RNN计算过程:
Step 1 利用RNN结构得到编码器中的隐藏状态(h1,h2,…,hT)。
Step 2 假设当前解码器的隐藏状态是st-1,计算每一个输入位置j与当前输出位置的关联性

写成相应的向量形式
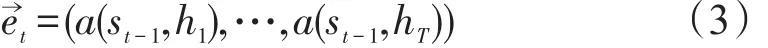
其中a是一种相关性的算符。
Step 3 对于e→t进行softmax操作,将其标准化得到Attention的分布

展开形式为
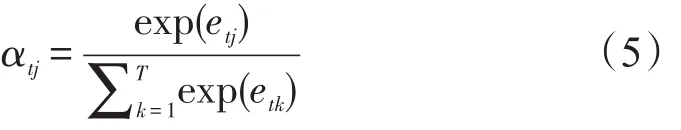
Step 4 对α→t可以进行加权求和得到相应的上下文向量

Step 5 计算解码器的下一个隐藏状态

及该位置的输出
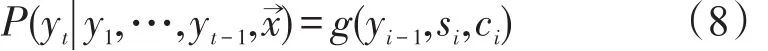
通过上述步骤计算编码器与解码器状态之间的关联性权重,得到Attention分布,对于比较重要的输入位置,在预测输出时权重较大。
在文本表示过程中,通常是直接将每个时刻的输出向量相加再求得平均值,这种做法认为每个输入词对于文本的贡献是相等的,但实际情况往往与之相反。在合并这些输出向量时,合理地分配注意力资源,为每个向量配以不同的权重,才能选出对当前分类结果更重要的文本向量特征。Attention机制本质上是给每个向量都赋予一个权值,将所有的输出向量加权平均。权值大小由词组对文本内容输出结果贡献程度而定,降低了其他无关词的作用,提高了计算效率。将Attention机制应用在多标签文本分类模型中,可以使文本特征得到更好的解释,从而使得分类结果更准确。
2 数据获取与处理
随着网络的迅速发展,互联网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战,网络爬虫随之产生。在对网站内容爬取过程中,可以合理地使用动态代理解决反爬虫问题,最终实现数据获取。
2.1 数据获取
悟空问答网站和百度知道网站具有带标签数据,因此从这两个网站获取数据和标签。
悟空问答网站是ajax技术动态加载页面信息和数据内容。因此,在对该网站进行爬取时,需要分析网页js脚本,找到含有页面内容js脚本。脚本url:“https://www.wukong.com/wenda/web/nativefe ed/brow/?concern_id=6300775428692904450&t=15 68099799213&max_behot_time=1568101150&_signature=lO1iGRAUyaadoRgΜT0SKrZTtYg”。它的请求参数包括:concern_id,t,max_behot_time,signature。通过js选项卡发现page_index_25f701a.js含有这几个参数:concern_id为固定值6300775428692904450;signature是 concern_id的签名,也为固定值;t为时间戳;max_behot_time为时间戳的整数位的值。得到四个请求参数的值,可以通过构造请求的网址,解析返回的json数据。Python对json数据的解码通过JSON模块来实现。解码过程是通过JSON模块的loads函数将json对象转换成Python对象的过程。进而获取标题和标题对应的标签。
百度知道网站只显示19页的内容,内容是动态更新,每页显示40条内容和其对应的标签。通过分析翻页 url:“https://zhidao.baidu.com/list?rn=40&pn=0&ie=utf8&_pjax=%23j-question-list-pjaxcontainer”。在url中,pn是按照40的倍数递增,而且只有这个变量是动态变化。爬虫的实质是模拟浏览器请求网站,需要将Request Headers的所有请求条件加上,保证了请求的顺利进行。采用BeautifulSoup解析该网站内容,获取文本内容和其对应的标签。在实际爬取过程中,设计了一个定时重启脚本,每隔30 min重新爬取该网站。这样能及时获取到该网站的大部分内容。
在爬取悟空问答网站和百度知道网站过程中遵循了Robots协议,避免对爬取网站的服务器造成压力。最终获得72万条带标签的文本数据。
2.2 数据预处理
2.2.1 数据清洗 在社交网络中,用户对自己的文本设置标签时,不乏有一些为了博人眼球的内容和标签,还存在广告传销等内容。为了保证数据的质量,必须对数据进行清洗。
(1)敏感词过滤。通过构建敏感词词汇表,对含有敏感词的数据进行过滤。由于文本数据量偏大,采用传统的方法进行过滤,效率低,时间久。因此采用 DFA[9](Deterministic finite automaton)算法对敏感词进行过滤,其原理是根据状态转移进行敏感词的检索,将敏感词构造成树形结构,能够减少检索的次数,提高计算效率。
(2)长度比过滤。文本数据如:“I hope you're here for me.怎么翻译?翻译|英文”,英文字母较多,不利于文本数据分析。通过Unicode的中文编码范围,统计数据中汉字和非汉字的个数及个数比,如果个数比小于2,就将该数据过滤掉。
(3)无意义文本过滤。数据中出现的零宽字符,例如“u200bu200c…”在进行分词处理时,会增加词汇表数量。处理零宽字符的方法是查看零宽字符的ASCII编码,将ASCII编码转为字符串格式,最后在文本数据中进行替换。同时对于文本中出现的诸如广告内容、版权信息和个性签名部分,需要进行过滤。这些内容都不应该作为特征。
(4)语义完整性判断。将获取到的数据进行简单的语义完整性判断。如果句尾是常用的截止符号,则认为文本内容是完整的,否则需要进行过滤。
经过以上步骤清洗,数据量最终为64万个,其中训练集60万个,校验集2万个,测试集2万个。文本的长度不同,对所有数据长度进行累和取均值,而后对数据进行截长补短。对数据的标签进行频率统计,保留前2 000个标签。数据的存储格式如表1所示。
2.2.2 数据分词及文本向量化表示 本文采用的分词工具是由沈阳雅译网络技术有限公司研发的Niutrans分词工具,该工具是基于语言模型进行分词,对日常生活中的用字方法和用字模式做了总结,不仅效率高,而且识别效果好。分词后的文本数据中含有很多停用词[9]。为了节省存储空间和提高搜索效率,根据已有停用词表,将数据中停用词进行过滤。

表1 数据存储格式Tab.1 Data storage format
训练词向量就是将文本采用向量表示。本文使用爬取的数据进行word2vec[10]模型训练。训练好的词向量将用于多标签文本分类模型的训练。使用Gensim接口调用word2vec工具训练词向量,Gensim的word2vec的输入是句子的序列,每个句子是一个单词列表。本文采用Skip-Gram模型将数据集训练生成词向量,具体参数设置如表2所示。通过以上方式,将文本数据转为其对应的词向量,词向量作为模型训练的输入,为后续实验提供方便。

表2 word2vec参数设置Tab.2 Parameters of word2vec
3 多标签文本分类模型
3.1 评价指标
对于多标签文本分类,目前采用的评价指标有准确率(Precision,P)、召回率(Recall,R)、F值(F-Μeasure,F)。
准确率:模型预测出的标签与数据对应的标签中的任何一个标签相同,即为正确,其中m为每个位置的准确率。
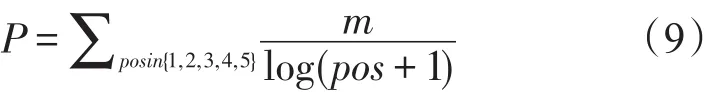
召回率:预测出的标签对原有标签的覆盖量,其中,f为预测标签总数,c为正确标签总数。

F值:评价指标为准确率和召回率的调和平均数。

采用按位加权的方式对模型进行评估,准确率值会大于1,但是这种方式能够很好地将标签与文本内容的关联程度表示出来。准确率与召回率的调和平均数F值能够很好地表示出模型的准确性,因此采用F值对模型进行评估。
3.2 文本循环神经网络
采用如图2所示的双向TextRNN模型进行多标签文本分类实验,神经网络采用BILstm[11]结构。训练序列由向上和向下的两个Lstm构成,并且每个Lstm都连接着输出层,在输出层可以得到训练数据特征的完整信息表示。
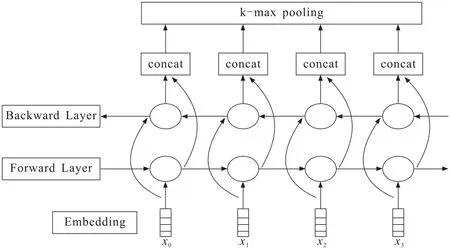
图2 双向循环神经网络结构Fig.2 Two-way circulation TextRNN neural network structure
双向TextRNN模型包括输入层、Embedding层、双向Lstm层、k-max pooling层和输出层。输入层将数据传入到模型中,Embedding层负责将输入的数据转为对应的词向量,输入维度为300,设置batch大小为128。在连接下一层时随机断开50%连接,用于防止模型过拟合。双向Lstm层主要负责提取句子向量的上下文信息,为了防止过拟合采用BatchNorm1d。在输出层进行分类时,将全部的神经元输出采取2_max pooling操作,而后再分类输出,输出的维度即为标签的总个数(2 000)。采用Adam算法结合反向传播算法在模型训练过程中进行不断优化。在模型训练过程中对优化目标函数增加约束条件以防止模型过拟合,因此使用L2正则化。在实际训练中,叠加了3层的双向Lstm进行训练,保证模型能够学习的更深更广。
3.3 文本卷积神经网络
TextCNN[12]的核心思想是将复杂问题简单化处理,将大量的参数降维成少量参数,对局部特征进行捕捉。对于多标签文本分类数据而言,局部提取就是指从特征映射矩阵中选取对应卷积核大小的特征,不同卷积核提取到的特征也不尽相同。因此可以得到多种层次的语境信息,使得文本信息表征更加完善。

图3 文本卷积神经网络模型结构Fig.3 TextCNN neural network structure
对TextCNN模型进行建模时,模型结构如图3所示。模型由输入层、Embedding层、两层卷积、池化层、全连接层组成。输入层将数据传入到模型中。Embedding层负责将输入的数据转为对应的词向量,batch大小为128,输入维度为300,并在连接下一层时随机断开50%的链接,防止模型过拟合。在卷积层中,卷积核大小是[3,4,5]。在连接下一层时,对每个神经元的值进行BatchNorm,激活函数采用Relu。下一层的卷积操作同上。在池化层中对所有卷积核进行1-max pooling操作,选择每个特征映射矩阵中的最大值,将这些代表最重要特征的值级联起来,可以得到最终的特征向量,并在连接下一层时随机断开50%的链接,防止模型过拟合。最后,将得到的特征向量再输入Softmax layer做分类。
TextCNN的特点是稀疏连接,表示文本内容的特征矩阵不要求每一个类别的数据有非常一致的特性,只具有某一些特性即可,适合用于文本分类。
3.4 TextRCNN_Attention
为了解决TextRNN和TextCNN的局限性,参考文献[14]中的网络结构,使用双向循环神经网络结构(TextRCNN)获取上下文信息,使文本信息得到更好地表征。在模型搭建过程中结合Attention机制,使模型将注意力聚焦在对文本分类任务贡献大的几个词上面,降低其他无意义的词对分类结果的负面影响。TextRCNN结合Attention机制构建的TextRCNN_Attention模型的结构如图4所示。
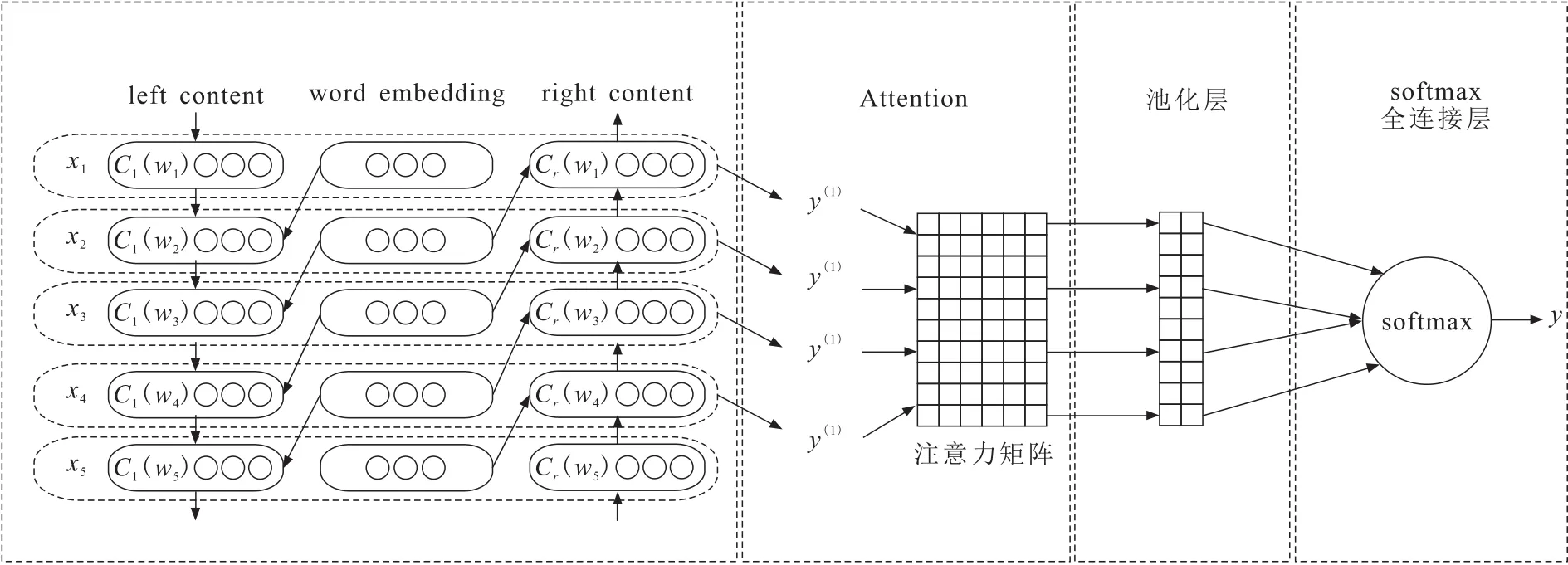
图4 TextRCNN_Attention神经网络模型结构Fig.4 TextRCNN_Attention neural network structure
TextRCNN_Attention模型本质是将TextCNN的卷积层替换为双向Lstm,引入Attention机制。首先将词进行词向量编码,通过word embedding层,得到词向量,维度为300。接着将词向量输入到双向循环神经网络,在实验中,为了得到词汇更多的上下文信息,双向循环神经网络使用的是Lstm结构。将词向量与两端的上下文信息进行结合,将结合结果使用Tanh函数作为激活函数进行计算。而后使用Attention机制为每个输出特征分配不同的权重。接着进行池化操作,使用1-max pooling找到输入的数据中最重要的特征,得到最重要的信息。最后是输出层,使用Softmax函数处理。
4 对比实验
分别采用TextRNN、TextCNN和TextRCNN_Attention模型进行实验。TextRNN模型结果如图5和图6所示。TextRNN模型在运行速度上丝毫不占优势,主要原因是TextRNN模型的后一个时间步的输出依赖于前一个时间步的输出,无法进行并行处理,导致模型训练的速度慢。迭代到10轮时,校验集涨幅和损失曲线基本稳定,已经达到很好的效果。为了实验结果最优,可以对模型进行微调,增训2轮,调整学习率,最终测试集的综合评价得分F值为0.952 5。
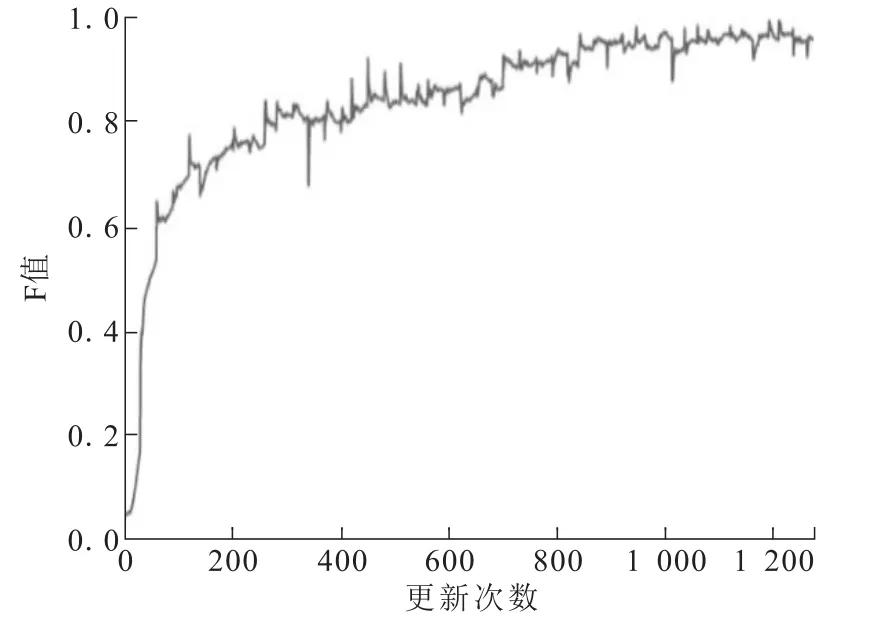
图5 文本循环神经网络校验集曲线图Fig.5 Check-set curve of TextRNN
TextCNN实验结果如图7和图8所示。迭代到10轮时,校验集曲线和损失曲线基本稳定,在训练过程中曲线波动比较随机。原因可能是不同的数据量使得某一类别数据的特征矩阵发生变化,而对于某一些特征变化,卷积神经网络没有及时捕获。适当调整超参数可能会减少这种现象的发生。为了实验结果最优,可以对模型进行微调[13],增训2轮,调整学习率,最终在测试集的综合评价得分F值为0.950 6。

图6 文本循环神经网络损失曲线Fig.6 Loss curve of TextRNN
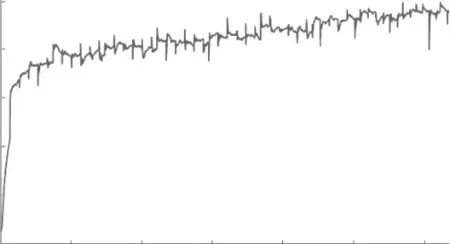
图7 文本卷积神经网络校验集曲线Fig.7 Check-set curve of TextCNN
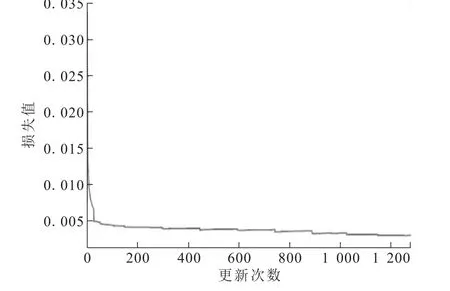
图8 文本卷积神经网络损失曲线Fig.8 Loss curve of TextCNN
TextRCNN_Attention实验结果如图9和图10所示。经过10轮训练,曲线基本稳定。在测试集上的综合评价得分F值为0.961 2,说明TextRCNN_Attention的性能优于TextCNN和TextRNN,更适合提取文本特征,同时能够及时捕获更多特征的上下文信息,使得分类结果最优。
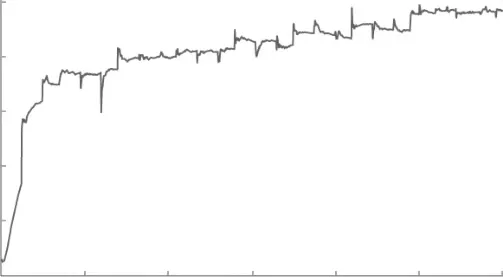
图9 TextRCNN_Attention校验集曲线Fig.9 Check-set curve of TextRCNN_Attentio

图10 TextRCNN_Attention损失曲线Fig.10 Loss curve of TextRCNN_Attention
5 结论
针对基于文本循环神经网络和文本卷积神经网络的多标签文本分类模型的局限性,提出TextRCNN_Attention多标签文本分类方法。文本数据爬取自网络。对数据进行长度比过滤、敏感词过滤、零宽字符过滤、无意义文本过滤和语义完整性判断的方式进行数据筛选,从而保证数据质量。采用word2vec将文本数据向量化,输入模型进行训练。实验结果表明,TextRCNN_Attention模型结合了TextRNN和TextCNN模型的优点,能更好地理解语义信息。同时,Attention机制对文本特征提取更加合理,模型将注意力聚焦在对文本分类任务贡献较大的特征上面,使得分类效果最优。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
