
基于语料库的听说综合性任务语言特征研究∗
2020-08-24 07:37徐鹰廖天华韩苏王亚琪
外语学刊 2020年1期
徐鹰 廖天华 韩苏 王亚琪
(华南理工大学,广州510641)
提 要:本文以故事复述任务为例,采用语料库方法对影响听说综合性任务表现的语言错误进行描写和诊断分析。根据中国学习者英语语料库(CLEC)言语失误标注原则,本研究对360 位考生故事复述任务录音进行转写和标注。 结果发现,vp(动词短语)、wd(词语)和sn(句子)是语言错误最为集中的3 种特征;这3 种特征能有效区分不同水平的考生;wd 和sn 能有效预测考生故事复述成绩。 上述结果对听说综合性任务评分标准开发和考试备考提供重要参考。
1 引言
对学习者的语言错误进行分析不仅能提供学习者习得的证据以及揭示学习者采用的策略(Corder 1967:161),而且能帮助研究者发现第二语言或外语学习的一般规律(何华清2009:2),因此对于深化外语教学意义重大。 错误分析同样对于语言测试有重要参考价值,并且往往结合语料库手段对其进行研究。 一个对学习者错误进行标注的语料库具有以下用途:(1)开发试题,比如确定考点或设计单项选择题的干扰项;(2)通过揭示区分不同能力等级的语言特征从而开发评分标准;(3)对考试内容效度进行检验(Park 2014:28,Cushing 2017:441)。 目前,国外众多学者和考试开发机构纷纷构建附带错误标注的学习者语料库进行语言测试研究,比如剑桥考试中心利用剑桥学习者语料库(Cambridge Learner Corpus)设计和开发考试;Hawkey 和Barker(2004)对参加剑桥考试中心组织的PET,FCE,CAE 和CPE 考试考生的作文语料进行错误分析,确定不同分数等级的区分性特征,最后构建面向剑桥英语能力系列考试写作部分的统一评分标准。 国内采用学习者语料库进行考试设计和效度研究的案例相对比较匮乏(邹绍艳2016:112)。 较有代表性的研究是穆惠峰(2011:66)采用自建语料库对大学英语四级考试完形填空题的内容效度进行验证。
综合性任务被普遍认为能更有效地测出考生的真实语言能力,并且能产生更积极的反拨效应,已经被越来越多大规模、高风险测试(如TOEFL)所采用(Purpura 2016:190)。 借助语料库手段对听说综合性任务进行语言错误分析的实证研究主要有以下两项。 为了探讨TOEFL 口试听说综合性任务所测构念的本质,Brown 等(2005:2)收集200 位考生的语音样本并进行转写和标注。 其中语法错误的标注种类包括5 种特定类型错误:时态错误、主语为第三人称单数时动词/系动词变化错误、名词复数错误、冠词使用错误、介词错误,以及1 种总体准确度特征:无错误T 单位百分比。10%的考生由2 位标注人分别进行标注,这6 种错误的标注信度在0.71-0.99 之间。 方差分析结果表明5 个不同考生分数等级在每种错误上都有显著差异,高分等级(4 级和5 级)之间差异明显,低分等级(1 级到3 级)之间差异不明显;5 种特定类型错误的效应量分别为0.15、0.08、0.17、0.14 和0.07,总体准确度的效应量值最大(0.22)。 根据Muijs(2004:195)的标准,虽然这6 种错误特征能区分不同能力考生,但是对考生分数差异的解释力度较弱或有限。 王华等(2018:413)通过对110 位参加某大型英语听说考试的考生故事复述任务口语产出录音进行标注,探讨听说综合性任务的口语能力区分性特征。 其中在语言准确性方面通过标注考生动词过去式使用错误率来表征具体错误,选用无错误小句比(error⁃free clauses ratio)判断总体准确性。 多元回归分析结果显示无错误小句比能显著预测考生口语能力(p<0.05)。 因此,听说综合性任务的口语能力构念应该包括语言准确性。
尽管这两项研究对影响听说综合性任务的语言因素进行过分析,但是对语言错误的描写则不够全面。 作为一种常用的听说综合性任务,故事复述已经应用在全国英语专业四级(TEM⁃4)口试和广东省高考英语听说考试中。 这两种考试采用的评分标准都包括语音语调、复述内容以及语法和词汇等维度,其中语法和词汇维度都把语言错误作为评判的主要依据之一。 那么哪些语言错误能有效区分不同能力考生呢? 这是本文要解决的核心问题。 鉴于此,本研究拟采用基于语料库的方法对影响故事复述任务表现的语言错误进行全面描写和诊断,从而回答以下研究问题:
(1)中国学习者故事复述任务口语产出的语言错误有什么特征;
(2)不同能力考生的语言错误是否有差异;
(3)哪些语言错误能够有效预测考生的故事复述分数。
2 研究设计
2.1 研究工具
广东省高考英语听说考试总分为60 分,包括模仿朗读、角色扮演和故事复述3 个任务。 故事复述任务要求考生先听一段大约两分钟的独白(通常为记叙文)两遍,然后复述所听的内容。 考生应尽可能使用自己的语言复述,而且复述内容应涵盖尽可能多的原文信息。
本研究的语料来自2013 年广东省高考英语听说考试A 卷考生录音。 故事复述任务总分24分。 评分标准包括内容和综合两部分。 内容部分按信息点评分,一共包括10 个信息点,每个1.5分,总分15 分。 综合部分总分9 分,要求对考生的总体表现进行评分,具体包括3 个档次:(1)如果考生口语产出忠实原文内容,语言得体性好、合乎规范,表达流利,且语音语调不影响理解,应该给7-9 分;(2)如果考生基本复述原文的主要内容,语言得体性较好、基本合乎规范,比较流利,尽管出现一些语音语调的错误,但基本不影响理解,应该给4-6 分;(3)如果考生不能复述原文的主要内容,语言得体性较差,出现较多的语言错误,不够流利,且语音语调影响理解,应该给0-3 分。A 卷故事复述任务文本见图1。
2.2 研究对象
本研究通过分层随机抽样的方法选取360 位考生录音。 首先,把考生按照考试总分排序,然后平均分成高分组(M =46.93,SD =5.50)、中分组(M =37.07,SD =6.75)和低分组(M =24.10,SD =9.15),每组120 位考生。 单因子方差分析发现3组考生总分组间均值差异显著[F(2,357) =295.867,p<0. 001, η2=0.624]。 Scheffe 事后检验表明,相邻组别的总分均有显著差异(p<0.001)。 按照上述方法随机抽取30 份考生录音用于培训,3 个水平组各10 位考生。

图1 2013 年广东省高考英语听说考试A 卷故事复述文本
2.3 研究过程
考生语料的处理包括转写和编码两个阶段。两位研究助手(拥有文学硕士学位)逐词将考生录音转写成文字。 转写后的总体和3 组考生录音文本单词量的描述性统计如下:M总体=62. 71,SD总体=23. 39;M高分组=79. 04,SD高分组=15. 79;M中分组=61. 53,SD中分组=17. 86;M低分组=37. 80,SD低分组=19.45。 单因子方差分析发现3 组单词量组间均值差异显著[F(2,357) =162.964,p<0.001,η2=0.477]。 Scheffe 事后检验表明,相邻组别的单词量均有显著差异(p<0.001)。
转写好的文本参照《中国学习者英语语料库》(CLEC)(桂诗春 杨惠中2003:1)的言语失误标注原则进行编码。 该标注原则一共包括11 大类(词形fm,动词短语vp,名词短语np,代词pr,形容词短语aj,副词ad,介词短语pp,连词cj,词语wd,搭配cc,句子sn)和61 小类,能够较全面地描写中国学习者英语产出的错误。 通过对用于培训的30 位考生语音转写文本进行分析,我们发现词语wd 分类较多(7 种),其中一些类型未在转写文本中出现(如wd1(词序)、wd6(重复)),而某些常见错误(如表1中wd1 例子hardly 在语料库中出现19 次)又难以归为现有的类型。 因此,为便于标注和分析,把wd 的标注分类数量从7 减少为2,并且重新进行定义,具体见表1。

表1 词语类型错误(wd)的定义和分类
修改后的标注框架一共包括10 大类(删除词形fm)和53 小类(删除词形fm 的3 小类,词语wd 的7 小类减少到2)。 两位研究助手采用该框架对全部考生语料进行标注。 在标注培训时,他们首先学习该标注体系,并共同讨论用于培训的15 份考生样本,然后独立对另外15 份考生样本进行标注,接着相互查看各自标注文本并讨论其中差异,最后达成共识。 培训结束后,两位研究助手分别对185 位考生录音文本进行标注(其中10位是共同考生)。 由于标注框架包含的语言错误种类非常全面,因此不同标注者的信度难以达到较高水平(Brown et al. 2005:51)。 在本研究中,这10 位考生一共产出244 个错误,两位标注者相同的错误数量为196 个(80. 33%),说明标注结果可信。
2.4 数据分析
首先采用AntConc 3.2.4w 统计各类特征频数。 由于不同水平考生口语产出的单词量存在显著差异,为做进一步的推断统计,将所有特征频数转化成每产出100 个单词出现该错误的标准频数。 然后,采用SPSS 18.0 对每个特征进行描述性统计分析,并对可能的区分性特征进行单因素方差分析。 最后,把所有考生按照分数排序并平均分为奇数样本(训练集)和偶数样本(测试集),采用多元线性回归分析奇数样本得到分数预测模型,并用偶数样本验证效度。
3 结果
3.1 中国学习者故事复述任务口语产出的语言错误特征
3.11 大类语言错误特征
全部3 组考生产生的语言错误原始频数总数为7,828 个,具体见表2。

表2 各组语言错误大类特征原始频数
在大类特征中,vp,wd 和sn 是语言错误最为集中的3 种,总和达到82.8%,且零错误考生数相对较少(最多不超过10%)。 其他7 种特征相对较少,其中4 种特征(aj,ad,cj 和cc)百分比不足1%,且零错误考生数相对较多。 这一结果说明vp,wd 和sn 是不同水平考生都会出错的特征,具有普遍性,可能是区分性特征,因此需要对它们做进一步的分析。
经过标准化处理后的vp,wd 和sn 这3 种大类特征标准频数的描述性统计结果见表3。
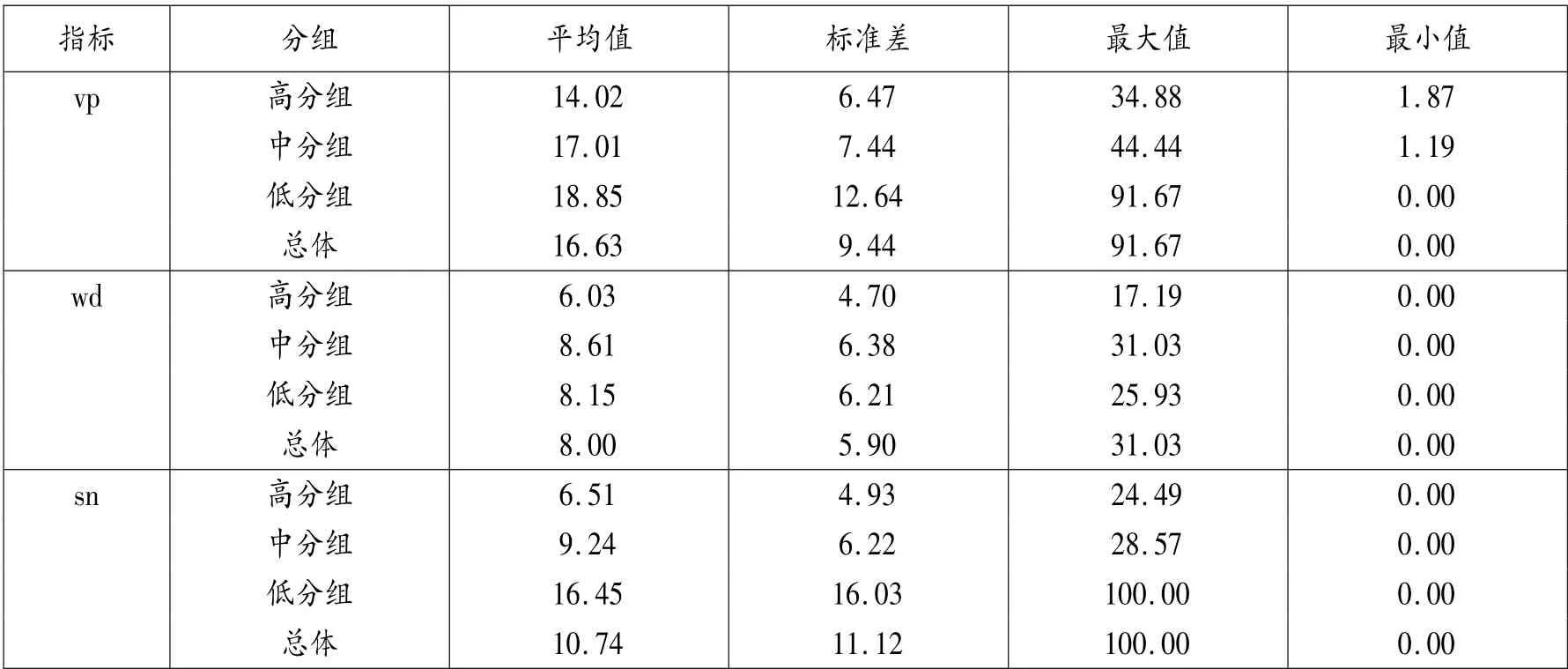
表3 各组vp,wd 和sn 标准频数描述性统计结果
总体而言,vp,wd 和sn 这3 种特征的标准频数都随着考生水平增加而降低。 值得注意的是中分组的wd 错误平均值大于低分组。 根据Ellis(1999:76)提出的中介语理论,中介语的特征之一体现为可预测性和内部一致性。 一些学习者将这一规则泛化,比如在hard 后面加上⁃ly 后缀构成副词。 因此,造成这一现象的可能原因在于中分组考生尚未完全掌握某些目的语规则,把“形容词加后缀⁃ly 变成副词”的规则过度使用,忽略不适用这个规则的特殊情况。 此外,学习者的中介语还具有动态性和开放性,因此中分组考生可能在使用某些目的语规则时出现前后不一致的情况,比如混用动词的过去分词和现在分词,因此会出现中分组wd 错误数多于低分组。
3.12 小类语言错误特征
对于vp 和sn 而言,高分组的错误标准频数平均值和标准差最小,低分组错误标准频数平均值和标准差最大,说明低分组的内部差异较大。vp 错误特征的原始频数是3,242,其中vp6(时态)频数为2640(81.43%)。 在9 种vp 小类错误特征中,只有vp6(时态)出现5 个考生没有犯错误,其他8 种小类错误的零错误考生数量至少超过180 人(50%)。 以上结果说明vp6(时态)可能是区分不同能力考生的小类特征。
sn 错误特征的原始频数是1,742,其中4 种小类错误(sn3(垂悬修饰语)、sn4(比较不符合逻辑)、sn5(主题突出)和sn6(并列))的原始频数为0。 sn8(结构缺陷)频数为1,414(81. 17%),只有35 位考生没有犯这一错误。 sn1(不断句)、sn2(片段)、sn3(主从)错误频数和比例分别为104(5. 97%)、202(11. 60%)和22(1. 26%),且没有犯这3 种错误的考生人数分别为276、235、341。 上述结果说明sn8(结构缺陷错误)可能是区分不同能力考生的特征。 根据CLEC 言语失误标注原则,结构缺陷主要指一个句子中语法结构的错误,包括improper splitting(不合理分隔)、pat⁃tern shif⁃ting(句式转移)和confusing structure(结构混乱)等主要类型。 考生常犯的sn8 错误如下:
①So he open[vp6] the door run[vp6] into the living room.[sn8]
②She knocked on the door hardly[wd1]. The door has[vp6] no answer.[sn8]
③Tom was very strange[sn8], because she seldom go[vp6] away.
对于wd 而言,虽然高分组的错误标准频数平均值和标准差最小,但是中分组错误标准频数平均值和标准差最大,且中分组和低分组的差别不明显。 这个结果说明中国学习者中介语发展过程不是直线上升,而是呈螺旋式上升的态势(崔艳嫣 王同顺2005:7)。 wd1(误用意义不相关词)和wd2(误用意义相关词)都是容易混淆的词语类型错误,考生常犯的wd1 错误如下:
④She must be in the chicken [wd1].
⑤a lady lying in the flower [wd1].
⑥Brown was lying on the door [wd1].
考生常犯的wd2 错误如下:
⑦He deliver [vp6] a letter to Miss [wd2]Brown.
⑧a glasses [np6] of milk was broke [wd2]on the floor.
⑨Mrs. Brown was so worry [wd2] and he could do little...
这两种错误的差别在于错误的词是否和正确的词有意义上的联系。 wd 错误特征的原始频数是1,533,其中wd1 和wd2 频数分别为243(15.85%)和1,290(84.15%),且分别有192 和60 位考生没有出现wd1 和wd2 错误。 因此,wd2错误可能是区分不同能力考生的特征。
经过标准化处理后的vp6、wd2 和sn8 这3 种小类特征标准频数的描述性统计结果见表4。
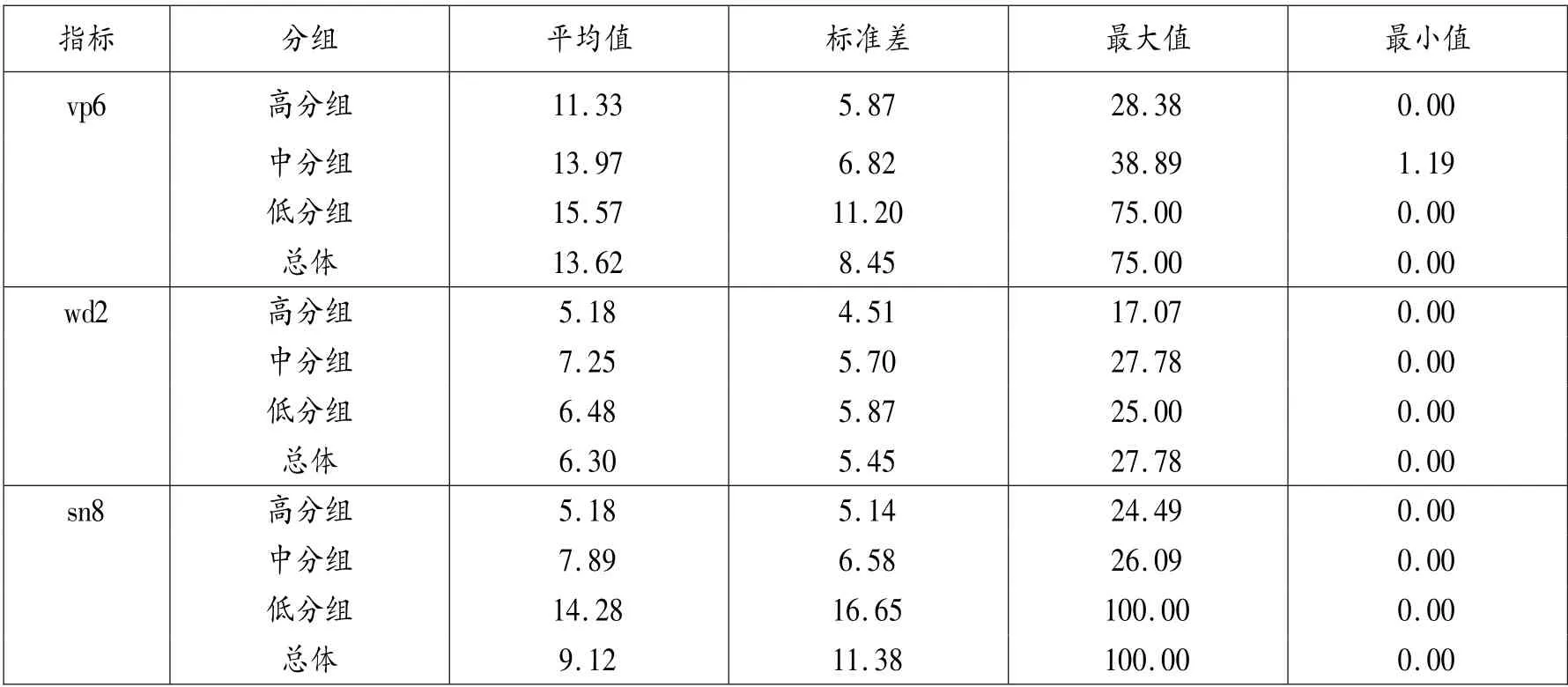
表4 各组vp6、wd2 和sn8 标准频数描述性统计结果
3.2 不同能力考生的语言错误特征的差异
在删除异常数据后,以考生水平为自变量,分别以vp,wd 和sn 标准频数为因变量进行3 次单因素方差分析,结果发现这3 个特征都能区分不同水平考生:
Fvp 标准频数(2,351) = 7.537,p <0.001,η2 =0.041;
Fwd 标准频数(2,354) = 5. 742,p <0. 01,η2 =0.031;
Fsn 语调分数(2,332) =37.274,p <0.001,η2 =0.183。
Scheffe 事后多重比较表明,vp 和wd 错误能有效区别高分和中、低分考生,但是无法区别中分和低分考生;sn 错误能有效区别高分、中分、和低分考生。
由于vp6、wd2 和sn8 可能是区分不同能力考生的小类特征,我们继续以vp6、wd2 和sn8 标准频数为因变量,以考生水平为自变量进行单因素方差分析。 在删除异常数据后,发现这3 个特征都能区分不同水平考生:
Fvp6 标准频数(2,351) =7.895,p <0.001,η2 =0.043;
Fwd2 标准频数(2,354) = 4.030,p <0.05,η2 =0.022;
Fsn8 语调分数(2,332) = 32. 282,p <0.001,η2 =0.165。
Scheffe 事后多重比较表明,vp6 和wd2 错误能有效区别高分和中、低分考生,但是无法区别中分和低分考生;sn8 错误能有效区别高分、中分、和低分考生。
上述结果证实Brown 等(2005:82)的研究结论:时态错误能够区分不同水平考生,且效应量不大。 此外,sn8 错误能有效区别高分、中分和低分考生,其原因在于sn8(结构缺陷错误)主要是对句子的总体准确性进行判断,在一定程度上和Brown 等(2005:52)的无错误T 单位百分比以及王华等(2018:416)无错误小句比的定义类似,因此也能够区分不同水平考生。
3.3 故事复述任务分数预测模型
首先采用独立样本t 检验对奇数样本和偶数样本考生成绩进行分析,结果显示两组考生分数无显著差异(t =-.153,df =358,p>0.05)。 然后采用Mahalanobis 距离整理奇数样本发现23 个异常值,删除后剩下157 位考生。 最后以vp,wd和sn 标准频数作为预测变量,考生分数作为因变量采用逐步进入法建立回归方程,结果得到两个分数预测模型(表5)。
如表5所示,两个模型都能预测考生成绩。 模型1 的预测变量只有一个,因此容忍度和VIF 值都为1。 模型2 的两个预测变量的容忍度都是0.979,VIF 值都是1.021。 上述结果说明两个模型都不存在共线性问题。 模型1(考生故事复述成绩(24 分制) =17.092-0.460 ×sn 标准频数)能解释考生分数23.2%的方差;模型2(考生故事复述成绩(24 分制) =18.390-0.435 ×sn 标准频数-0.217×wd 标准频数)能解释考生分数27.2%的方差,拟合优度更高。 因此,模型2 是较好模型。 在10 大类言语失误中,句子sn 对考生成绩的预测能力最强,其次是词语wd,其他特征无法预测考生分数。

表5 多元线性回归结果
第二步验证分数预测模型。 首先根据模型2计算出偶数样本的考生成绩,然后和考生的故事复述任务高考分数进行配对样本T 检验。 结果显示,模型2 预测分数和考生高考分数相关系数达到0.826(p<0.001),且没有显著差异(t =-0.559,df =179,p>0.05)。 因此,模型2 能有效预测考生的故事复述成绩。
4 讨论
本研究发现vp6(时态)、wd2(误用意义相关词)和sn8(结构缺陷)能有效区分不同水平的考生,主要原因如下。
首先,vp6(时态)错误可能是受到母语(汉语)迁移的影响。 语言迁移是一种普遍存在的现象,是指学习者掌握的多种语言之间的相互影响(蔡金亭2015:57)。 在学习者第二语言未达到自动化之前,无法随着时间的推移和学习者水平的提高而完全消失。 根据标记性和母语迁移的关系原则(Ellis 1994:206),母语中的无标记项在二语中的对应项如果有标记,那么母语的无标记特征会迁移到中介语中。 由于汉语缺乏时态系统(即无标记性),但是英语具有时态系统(即有标记性),那么汉语的无标记特征会迁移到中介语当中,即学习者的中介语也会出现没有时态的情况。此外,由于考生在考试时普遍存在紧张、焦虑的情绪,这种语际影响表现得更为明显。
其次是wd2(误用意义相关词)错误,包括两种类型:(1)误用正确单词的同根词,导致词性错误,例⑧和例⑨都是这种情况,其主要原因也是受母语迁移的影响。 Odlin(1989:79)指出,当两种语言的词汇在语义上对等而形态上不具相似性时往往发生词汇层面的迁移。 Larsen-Freeman 和Long(2000:107)进一步指出:母语中无标记的语言特征比有标记的特征更容易发生迁移。 由于汉语的词性没有明显标记,因此考生容易出现误用同根词的情况。 (2)大量考生(频数为316)把Mrs. Brown 错听成Miss Brown(例⑦),可能原因是部分考生过于紧张,且Mrs 和Miss 发音和意义都较为接近,容易出现混淆。
最后是sn8(结构缺陷)错误。 例①是一个典型的连动句或连动结构(serial verb construction,简称SVC),指的是充当单一述语、并且不带有任何并列、从属或其他句法依附性显性标记的动词序列(尚新2009:5),其特点是连动短语中的每个动词项都与一个主语联系。 这种结构在汉语中广泛存在,但在英语中普遍缺失(郑学丹2018:454)。 根据标记性理论(Eckman 1977:315),可以认为这种限定性动词和非限定性动词的区别对汉语而言是一种无标记性,对英语则是一种标记性,因此会产生母语负迁移。 例②和例③则是一种典型的词对词的翻译错误,即考生没有掌握英语句子的表达方式,只是按照汉语语序造句,也可以看成是一种母语迁移产生的错误。
5 结束语
通过构建一小型语料库并采用CLEC 言语失误标注原则进行标注,本研究对影响故事复述任务表现的语言错误进行分析,结果发现vp(动词短语)、wd(词语)和sn(句子)是语言错误最为集中的3 种大类特征,vp6(时态)、wd2(误用意义相关词)和sn8(结构缺陷)是语言错误最为集中的3 种小类特征,它们都能区分不同水平考生。 本文的研究成果主要有以下意义。
首先,有助于开发基于数据的评分标准(徐鹰2018:75)。 TEM-4 口试和广东省高考英语听说考试故事复述任务采用的都是基于专家直觉的评分标准。 尽管评分细则中提到语言错误,但是较为宽泛,既没有指明语言错误包括哪些错误类型,也没有界定多少语言错误算少或算多、或什么样的语言错误算严重等问题。 这就导致评分员只能凭借自身的经验去解读和使用评分标准,容易导致评分员误差,最终威胁考试的效度。 本研究发现的3 种大类错误和3 种小类错误能有效区分不同水平考生,且不同类型错误的效应量有差异,这就为充实评分标准的语言维度的等级描述语、明确语言错误的严重程度提供了重要参考,从而帮助评分员形成对评分标准统一的解读,进而为分数意义提供合理的解释。 同时,本研究发现上述错误特征能区分不同能力考生,为评分标准语言维度各分数等级之间的线性关系提供实证数据的支撑,从而增强评分标准的效度。
其次,有助于帮助师生明确备考的重点。 在备考故事复述这一题型时,也许考生会犯各种各样的语言错误。 但是,他们不应对所有类型的语言错误等量齐观,而应有所侧重,重点解决sn8、vp6 和wd2 3 种类型错误。 同时,教师应该在备考辅导中放弃“全面纠错” 的范式(Chandler 2003:267)以求对考生所有的错误提供反馈,而应采用“选择性纠错”的方式(Sheen 2007:255),重点帮助考生改正上述3 种类型错误,从而实现备考效果的最大化。
本研究的不足之处在于只采用一个任务的数据,结论的可推广性和概括性还有待增强。 下一步的研究可以采用不同的任务进行验证。
猜你喜欢
外语学刊(2021年1期)2021-11-04
初中生世界·八年级(2019年3期)2019-04-22
师道·教研(2017年11期)2017-12-10
小学生导刊(低年级)(2017年1期)2017-06-12
初中生世界·八年级(2017年3期)2017-03-24
意林(2016年21期)2016-11-30
中学生数理化·七年级数学人教版(2016年6期)2016-05-14
初中生世界·八年级(2015年4期)2015-08-04
改革与开放(2010年6期)2010-06-04
