
一种用户自我感知的位置隐私保护算法
2020-09-09 03:09叶吉祥曹文慧
计算机应用与软件 2020年9期
叶吉祥 曹文慧
(长沙理工大学计算机与通信工程学院 湖南 长沙 410076)
0 引 言
日常生活中,用户可以通过第三方软件使用基于位置服务(Location based service,LBS)[1]来获取导航服务、紧急救援服务、娱乐信息服务等[2]。在此过程中,如果攻击者盗取用户的位置信息或暴露给不可信任的第三方软件,必然造成严重影响。因此,在享有LBS的同时保证用户的位置隐私成为当前一个研究热点。
1 研究概述
位置隐私的概念最早由Beresford等[3]提出,自此,国内外许多学者提出了一系列的解决方案。目前,位置隐私保护措施主要有三类[4]:(1) 位置模糊保护法,主要包括位置的偏移、构造假位置等;(2) 引入密码学的加密方法,对用户位置进行加密后发送;(3) 制定隐私保护策略,主要针对服务商进行规范和约束。Gruteser等[5]将K-匿名[6]技术用于位置请求服务的隐私保护中从而达到保护目的。文献[7-10]将K-匿名算法通过构造不同的几何形状,产生不同的匿名区域来完成保护。Kim等[11]在未知的数据访问的情况下执行数据访问模式,保证了加密数据和用户查询记录的机密性,但是使用TTP结构不能保证中间匿名服务器绝对的安全,且容易造成系统堵塞,必然会产生新的问题。
在位置隐私保护的过程中,不仅要保护用户的位置信息,还要防止用户其他私人信息(姓名、爱好等)泄露。周长利等[12]通过构造真实用户与邻居用户的共同特征来形成匿名区域,采取几何形心作为基准进行查询,达到保护的目的。文献[13-15]根据用户与高频兴趣点将全局地图的位置进行单元区别划分,用户可根据网格单元中兴趣点的分布获取周围具体各项兴趣点的分布情况,保证匿名区域的多样性。
上述大多数文献均在理想环境下,以K-匿名方法作为收集方式,达到匿名效果。在人迹稀疏的情况下,通过假位置方法正好弥补了这一不足,但由用户根据自身的隐私需求构造假位置,并将这些假位置与真实位置一起发送到服务器,使得攻击者无法区分用户的真实位置信息。在生成的假位置的过程中,由于无法判定地形(如湖面、山脉)等因素,因此会影响假位置的可靠性。
针对上述问题,本文提出一种用户自我感知的位置隐私保护算法(简称USA)。用户自我感知周围邻居用户的分布密度情况,排除地形原因并形成匿名区域,随后将匿名区域呈多个矩形划分,最后按所分区域一同将请求内容发送至服务器。与现有方法相比,本文方法能够提高用户位置匿名性、可靠性,降低合谋攻击成功率。
2 系统模型
2.1 系统结构
位置隐私保护方法目前适用于两种系统结构:中心服务器结构和基于P2P结构。
中心服务器结构中,在移动用户和位置服务提供商(LSP)之间引入一个可信任的匿名器作为中间体,将用户位置信息通过匿名服务器模糊,最后发送到LBS服务器完成请求。P2P结构由移动用户组成与LBS服务器,搭载P2P协议通过单跳或多跳通信产生可靠的匿名区域,各区域间用户之间相互合作完成保护。
为了方便用户感知有效的邻居用户位置信息,本文采用P2P结构的LBS系统,系统模型如图1所示。由于本文主要研究的是用户的位置隐私保护,所以假设在用户之间、用户与服务器之间的通信都是安全的。
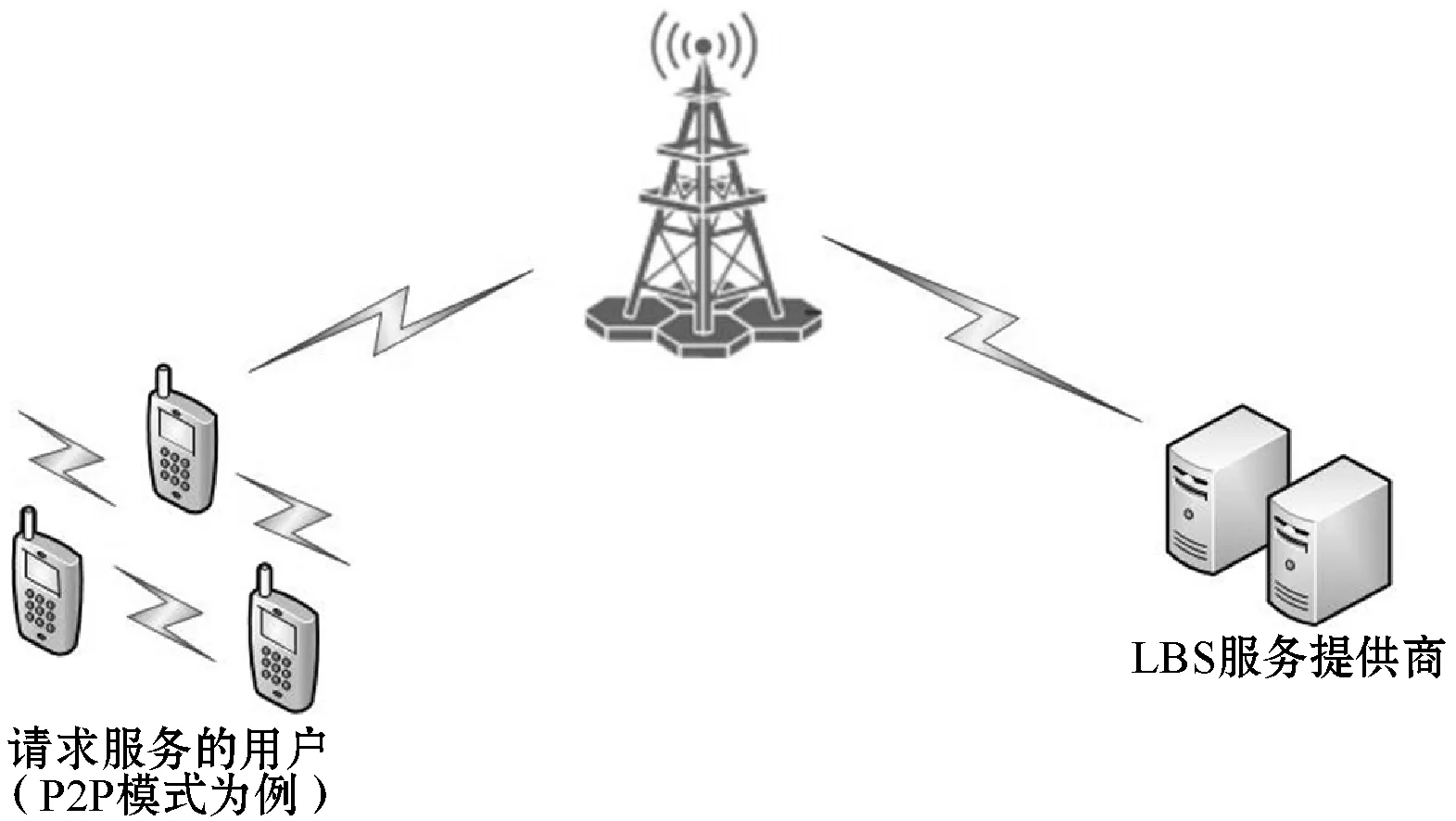
图1 位置隐私保护系统模型
2.2 基本思路
如图2所示,USA算法主要分为四个步骤:(1) 请求使用LBS服务的用户在有限跳数下感知自身周围邻居用户的分布密度;(2) 将感知到所有邻居用户所在位置的整体区域划分为多个矩形子区域;(3) 在每个矩形子区域中添加伪用户来均衡矩形内的用户稀疏分布;(4) 用户、邻居用户和伪用户共同将请求LBS的用户的内容发送至服务器,等待回应,当服务器回应给用户时,对返回结果筛选求精即可得到当前位置信息。

图2 USA算法步骤演示
3 算法实现
3.1 用户感知
在连通空间C中,对于用户u,周围的邻居用户都有特定的用户群密度ρu,称为周边用户平均密度,即周围感知用户个数为n(ρu,h),当h=1时,即一跳所感应的平均用户数量(h≥1),ρu以增加h的情况下在自身的ρu上进行迭代更新,此处使用极大似然估计的原理来估计平均用户数量。
(1)
式中:Cu表示第一跳周边用户的总数量。
由于通信传输时并不是在理想环境下的传输,因此,必须考虑非理想情况下能感知到的用户总数,因此,加入损耗因子μ,计算方法为:
(2)
因此:
(3)
显然,h越大,用户的数量虽然增多,但通信链路增多,通信开销增大,且LBS的准确度降低。
邻居用户感知算法中,用户u在初始化后,在规定的t周期内检测ρu,当在检测周期内发现ρu发生改变或有新的邻居用户加入时,则向“L”发送携带自身ρu和邻居位置信息;收集完成“L”集合并重新检测当前邻居用户的个数;读取每条“L”的位置信息并更新ρu。具体算法如下:
输入:邻居的“L”位置信息集合。
输出:ρu以及“L”的信息。
1. 设置ρu的初始值P、时间周期t
2. 初始化邻居用户的集合且为空
3. WHILE(t周期)
4. IF(ρu有变化)
5. 产生并发送“L”位置信息
6. END IF
7. 收到“L”的位置信息
8.Pu←P(u,1);
9. WHILE(“L”中的每一个位置信息)
10. 读取每个邻居的ρu
11.ρu更新
12. END WHILE
13. IF(ρu发生变化)
14 ρu←(Σ ρu+Pu)/|Pu|
15. END IF
16. END WHILE
3.2 矩形区域划分
在区域划分这一过程中,主要会经历以下步骤:
(1) 用户u发出位置请求时,使用上述位置感知算法之后感知周围的用户,且收集到至少K-1个用户节点信息。
(2) 将这K-1个用户节点开始模糊化去除,使得以用户为中心的整体区域去重化偏移,提高用户位置安全性。
(3) 在满足K匿名的情况下,将用户及感应到的邻居用户形成一个区域,随后将生成的区域划分成多个矩形子区域。
(4) 为了使每个矩形子区域内的用户分布均衡,不失重,在完成矩形子区域划分之后,通过随即添加伪用户来调节,提高用户位置的模糊性和自我匿名的能力区域划分的算法如下:
输入:邻居用户节点集合U,用户初始位置Loc,搜寻节点数Nu,划分子区域数目n,匿名需求K。
输出:n个匿名区域Ci(1≤i)。
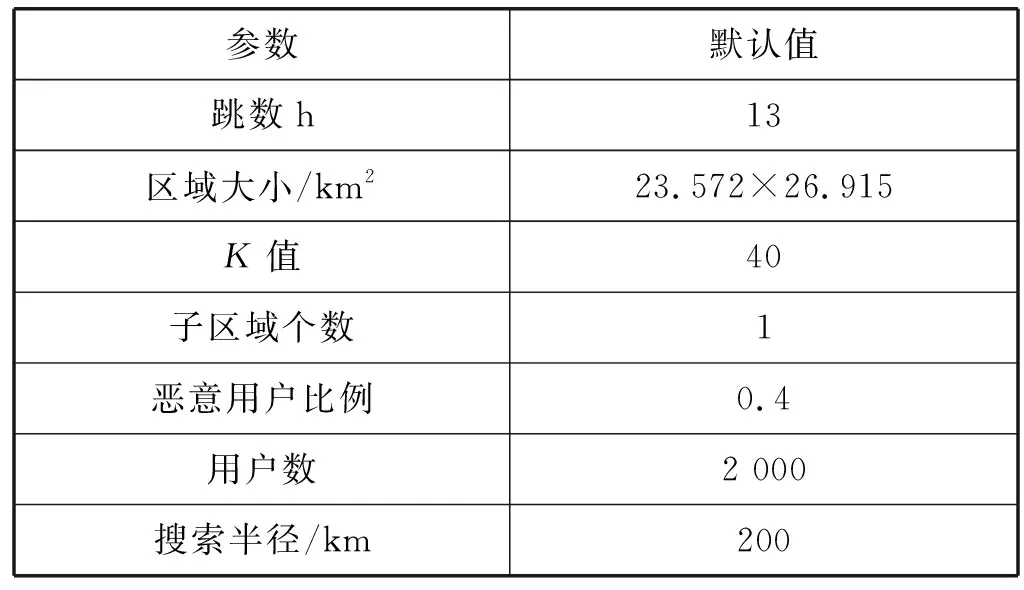
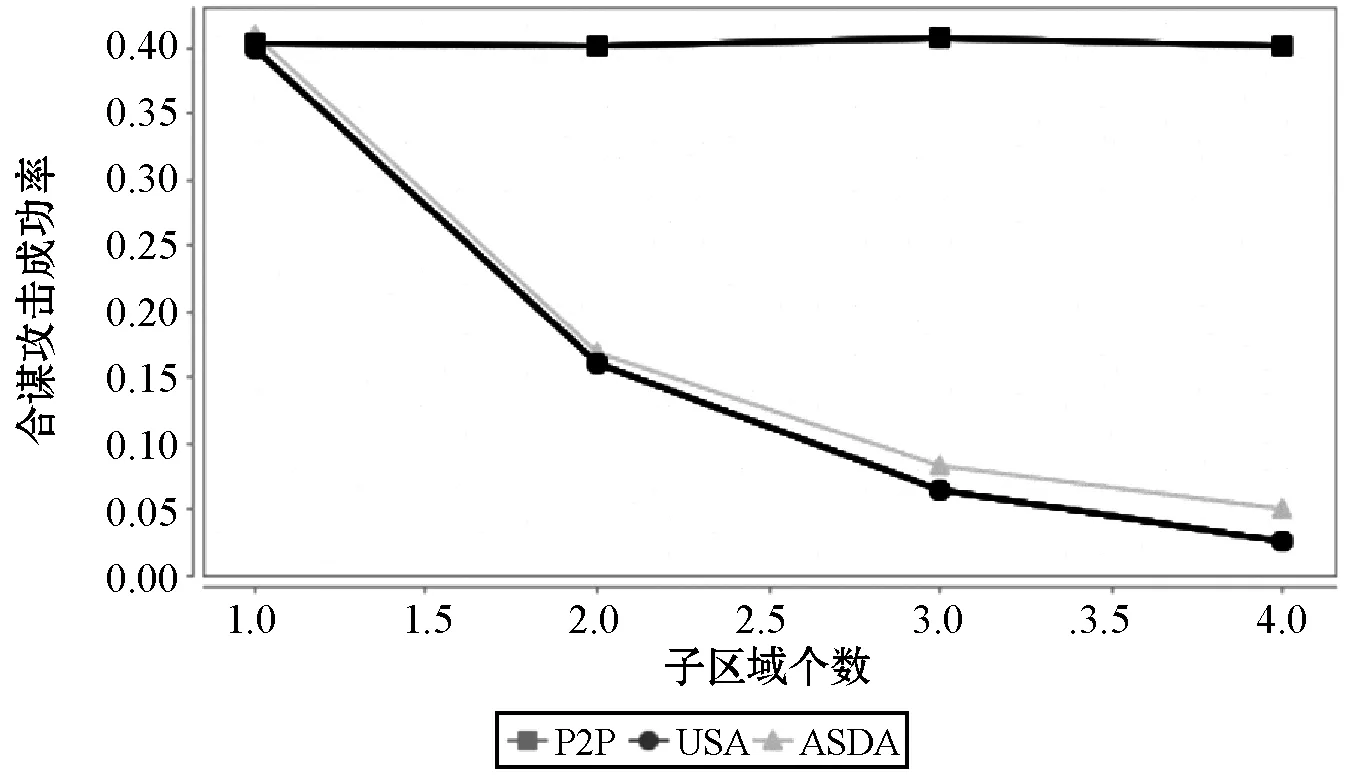
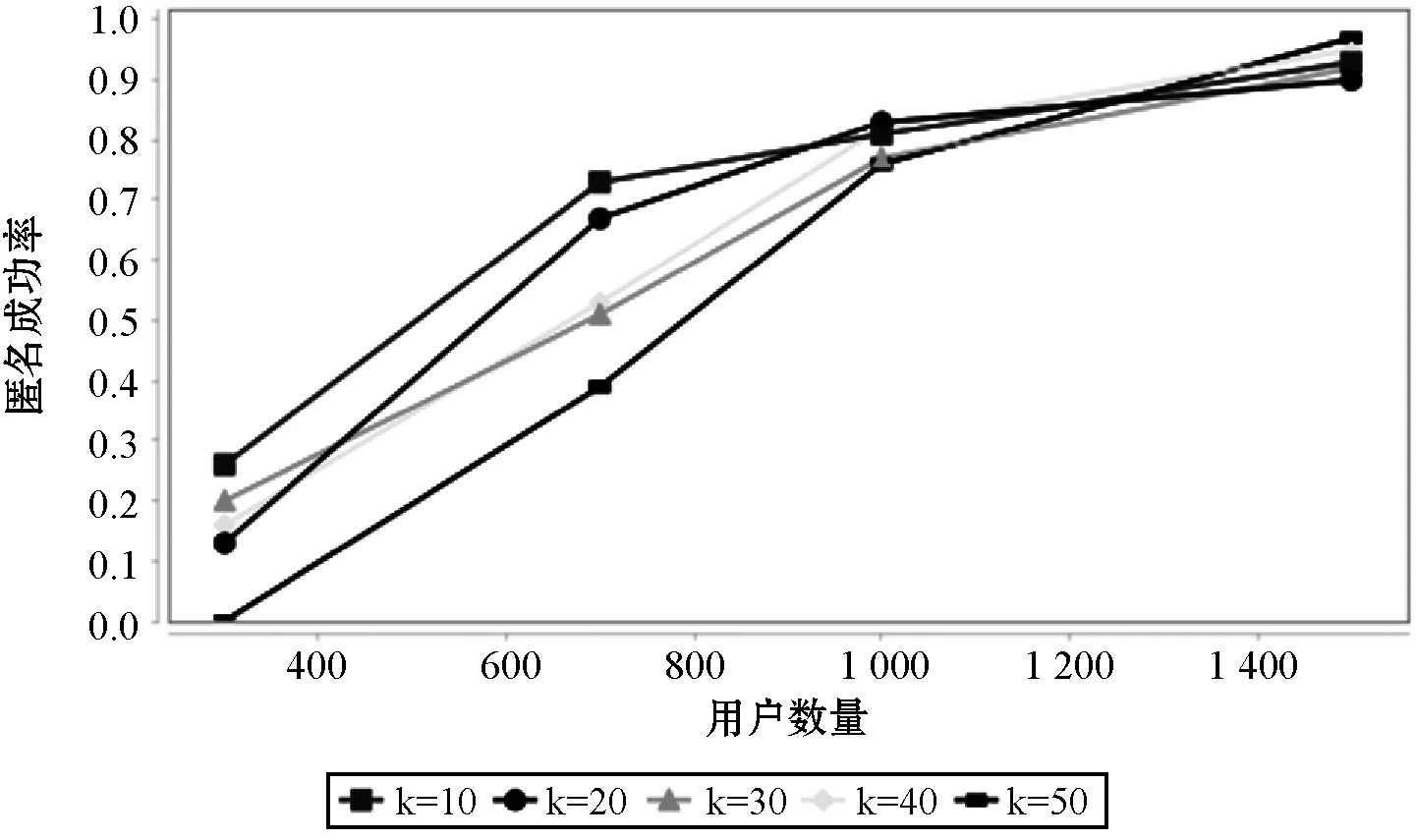
1. IF(Nu 2. End if 3. 把Loc添加到集合U中 4. 多于节点数目N′=Nu-K+1,IF(N′=0),跳至第7步 5. 将U中节点横纵坐标按随机方向排序求出最大与最小的N′个节点,并排序节点集合Ux与Uy 6. 去除Ux中q(q为随机数,且0≤q≤N)个节点与Uy中前(N′-q)个节点,并将去除的节点放入多余节点集合Ud。若Ud中已经包括去除的节点,则该集合多取一次节点放入Ud集合中,直到Ud里无重复的节点,且个数为N′,U=U-Ud[16] 7.U为随机选取中的节点,依据节点坐标方向以及坐标值大小进行排序,同时得到排序节点集U′ 8. 用户余数r=K%n,平均用户个数m=K/n 9. 将集合U′依据顺序进行划分为n个集合,选择一个集合包含m+r个用户,另n-1个集合则包含m个用户 10. 在n个节点集中,计算出每个集合的最小外接矩阵C 11. 返回n个子匿名区域C1,C2,…,Cn 在P2P通信结构下,由于用户可以与用户直接传送信息,没有中间服务器工作的影响和其他的物理损耗,因此,匿名成功率的本质即可表示为通过查询用户本身成功匿名的数目与进行总查询的用户数目之间的比值[16],具体见公式: SR=Nsuccess/Ntotal (4) 在完成匿名的用户区域中,如果攻击型用户与用户u在同一个子区域,此时会增加成功被攻击的机率。假设区域中有k个用户,m个攻击型用户,矩形子匿名区域有w个用户,真实用户在第j个子匿名区域,即用户u在查询区域中暴露的概率等于所有子匿名区域受到攻击的概率之积[15]。公式如下: (5) 本文仿真采用Java语言实现,实验数据来自德国Oldenburg为主的交通路网[17],仿真数据使用参数如表1所示。在此基础上对USA算法的性能进行仿真,挑选和USA算法在相同空间里和网络环境下的区域相似性划分算法(ASDA)和基于用户均衡性划分算法(UUDA)以及P2P经典方法,分别在不同场景下进行性能比较。 表1 仿真参数 将整体区域划分多个子区域是USA算法的关键,其性能决定了USA算法对用户保护的力度。在固定的用户基数内,划分的矩形子区域的个数不同所带来的影响也不同。如图3所示,当用户范围在2 000人时,随着划分的子区域个数的增加,用户被攻击成功的概率就逐步降低,但是无限划分子区域将带来额外的通信开销,故本文所用的子区域个数均为4。 图3 合谋攻击成功率受子区域个数的影响 图4为P2P经典算法和ASDA算法与USA算法进行比较的示意图。对于P2P经典算法来说,没有子区域的划分,用户直接通过K值的大小在整体范围把请求的内容发送至服务器,造成被攻击的概率大幅度提高,而ASDA算法和USA算法在划分子区域的基础上,用户被攻击的概率明显降低。由于USA算法提前感知用户周围用户分布密度,继而通过添加伪用户的调和,进一步降低了被攻击的概率。 图4 划分子区域对合谋攻击率的影响 图5为相同的环境下在不同算法中,用户数对平均匿名时间的影响。可以看出,在经典P2P算法当中,用户所需要的平均匿名时间是最少的,ASDA算法次之。尽管如此,经典P2P算法在安全性上对比时间上微小的毫秒差距用户是可以忍受的,而UUDA算法和USA算法虽然平均匿名时间比经典P2P算法高,但安全性大大提高。由于ASDA算法中没有对匿名区域内的用户进行失重调整,因此其平均匿名时间较低。而USA算法与UUDA算法在匿名区域中都使用了添加伪用户的过程。在平均匿名时间的性能上,USA算法略低于UUDA算法,提高了用户使用位置服务的时间,同时也提高了位置隐私保护方法的质量。 图5 用户对平均匿名时间的影响 图6为在USA算法中不同的K值对于匿名成功率的影响的对比图。随着用户数量的增多,匿名成功率整体上涨。当K值越小,用户的数量越多时,匿名成功率越大;当K值越大,用户数量越少,匿名成功率越小,可能会导致匿名失败。因此,在一定范围内选择合适的K值是至关重要的。 图6 K值对匿名成功率的影响图 针对LBS中存在的位置隐私泄露问题,提出了一种用户自我感知的位置隐私保护算法,通过用户提前感知自身周围用户分布疏密的情况,排除因地形因素影响位置隐私保护方法效果不佳的原因,再使用区域划分的方法主动降低被攻击型用户攻击的概率,在一定程度上加强保护用户位置隐私的力度。下一步将通过把用户位置隐私保护的方法放在不同的生活场景下进行深入探索,比如社交网络等,同时也会融入密钥保护等手段与增强隐私安全度结合来提高位置隐私的保护效率。4 性能分析
4.1 匿名成功率
4.2 合谋攻击成功率
5 仿真与分析
5.1 实验环境

5.2 算法性能分析

6 结 语
猜你喜欢
天天爱科学(2022年9期)2022-09-15
当代水产(2022年6期)2022-06-29
小学生学习指导(低年级)(2021年9期)2021-10-14
中国生殖健康(2020年8期)2021-01-18
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
小学生学习指导(低年级)(2019年9期)2019-09-25
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
福建中学数学(2016年4期)2016-10-19
