
基于ALBERT-BiLSTM模型的微博谣言识别方法研究
2020-09-15 16:30孙尉超陈涛
计算机时代 2020年8期
孙尉超 陈涛
摘要:随着互联网的高速发展,网络上的信息剧增,如何识别网络谣言也成为当下研究热点之一。针对谣言初期的传播具有一定隐蔽性的特征,结合预训练语言模型ALBERT和双向长短期记忆网络设计了ALBERT-BiLSTM谣言识别模型,通过挖掘谣言内容的深层文本特征进行识别,使之在谣言初期也能应用。五折交叉验证实验结果表明,ALBERT-BiLSTM模型在实验组中达到了最高的准确率98.095%、召回率98.014%和F1值98.098%,能够较好地识别微博谣言,对维护网络信息安全具有重要意义。
关键词:谣言识别;预训练语言模型;ALBERT;双向长短期记忆网络;ALBERT-BiLSTM
中图分类号:TP389.1 文献标识码:A 文章编号:1006-8228(2020)08-21-06
0 引言
科技和互联网高速发展,大数据时代的来临,越来越多的社交平台如雨后春笋般出现,提供给人们更多获取和传播信息的途径,同时,也产生大量谣言。谣言在拥有庞大用户基数的社交平台传播,在一定时间内必然会影响到部分用户情绪,引起舆论风波,威胁公民安全和社会稳定,所以对谣言的识别在维护网络信息安全工作中显得十分关键。由于谣言初期的传播特征具有一定的隐秘性,如何通过挖掘谣言文本内容的深层语义特征来判断信息真伪是谣言识别工作中的重点之一。近年来随着深度学习的兴起,越来越多的研究者开始利用深度学习模型来分析文本。本文以标注好的微博数据集MCG-FneWSⅢ为例,构建了ALBERT-BiLSTM谣言识别模型,并设计了对比实验组,经过五折交叉验证实验发现该模型在谣言识别精度达到了98.095%,能够较好地识别微博谣言。
1 研究现状
很多研究者在微博谣言识别工作中已取得一些成果。①Jin等[2]通过构建主题模型来挖掘微博文本中的冲突观点信息,并设计信用网络进行迭代学习,实验发现该模型在性能上明显优于基线方法。②Shu等[3]认为挖掘新闻发布者、新闻内容和社交网络用户的内在关系有助于提高对虚假新闻的检测水平,设计了一个三关系嵌入框架,它可以同时对新闻发布者和新闻内容的联系、社交网络用户和新闻的交互作用进行建模,用于识别虚假新闻。③Zhang等[4]首先通过大量数据挖掘作者、主题、帖子内容和新闻真伪的联系,并设计了一个深层的扩散网络模型学习显式特征和潜在特征并生成新闻可信度。④林荣蓉等[5]构建了谣言敏感词库,再通过Word2Vec模型提取词向量,将经过预处理后的文本中词的平均向量作为语义特征并融合提取到的统计特征和敏感词库特征作为微博特征的向量表示,输入到GBRT模型进行训练,同时建立了长短期神经网络模型进行二次识别,提高了谣言识别的精度。⑤杨真等[6]通过一系列机器学习方法在谣言识别比较研究中,对微博用户的谣言识别能力划分等级,并将谣言识别能力作为新特征引入模型,发现分类效果得到了提升。⑥曾子明等[7]定义了用户可信度和微博影响力特征变量,基于2016年雾霾谣言提出结合了LDA和随机森林的谣言识别模型。⑦王勤颖等[8]提取谣言识别的用户、传播和内容的基本特征并融合信任因素的特征,构建基于信任的微博谣言识别模型;同时将炸药爆燃爆炸过程的原理应用于微博谣言传播中,提出了微博能量参数的新特征,并融合原有特征建立了微博谣言信息爆炸识别模型。
过往的微博谣言识别模型的研究中,人们的关注点往往在整体特征的提取上,在文本深层语义特征的提取上并没有较好探究。近年来随着对自然语言处理领域研究的深入,在2017年Vaswan1等[9]提出了Self-Attention机制和Transformer框架,极大促进了语言模型的发展,为后续BERT和ALBERT的诞生做好了铺垫。本文结合了预训练语言模型ALBERT和双向长短期记忆网络模型,提出了ALBERT-BiLSTM模型,并将其应用于微博谣言识别上,实验发现该模型能够较好地提取文本深层语义特征并进行谣言识别。
2 微博谣言识别模型和方法设计
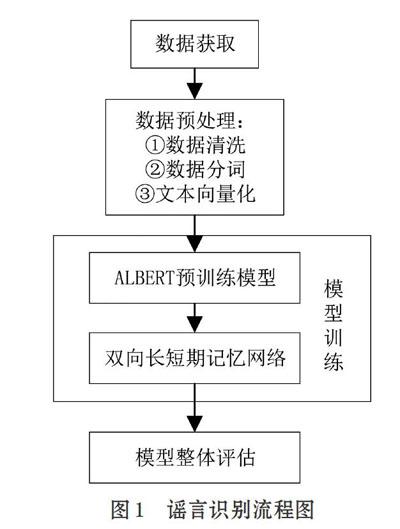
2.1 识别方法流程
微博谣言识别的流程分为四步,如图1所示。①数据获取;②数据预处理,包括数据清洗,数据分词,文本向量化;③模型训练,构建结合ALBERT和双向长短期记忆网络的模型,将经过预处理后的数据输入模型进行训练;④对模型进行整体评估。
2.2 BERT和ALBERT
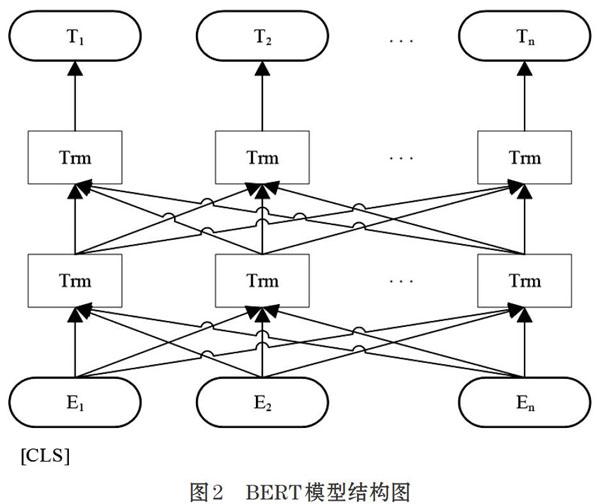
BERT (Bidirectional Encoder Representationfrom Transformers)是google的Devlin J等[10]于2018年10月提出的新型预训练模型,在当时11项自然语言处理任务中刷新了记录。其结构如图2所示。
BERT模型是采用了双向Transformer编码器,其训练方法分为两步:一是通过随机MASK训练集中15%的词。其中被打上[MASK]标记的词有80%的概率直接替换为[MASK]标签,10%概率替换为任意单词,10%概率保留原始Token,让模型预测被MASK的单词含义;二是通过从训练文本中挑选语句对,其中包括连续的语句对和非连续的语句对,让模型来判断语句对是否呈“上下句”关系。
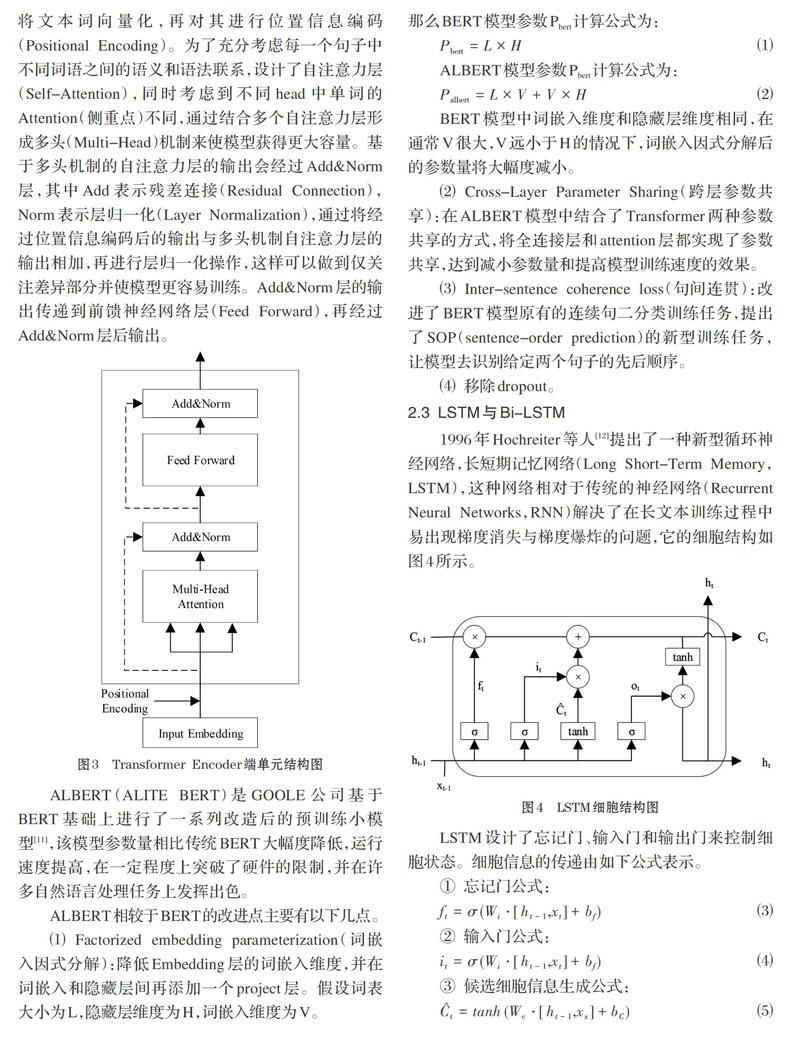
BERT模型中Transformer具体单元结构如图3所示。在输入文本后先进行词嵌入(Embedding)处理,将文本词向量化,再对其进行位置信息编码(Positional Encoding)。为了充分考虑每一个句子中不同词语之间的語义和语法联系,设计了自注意力层( Self-Attention),同时考虑到不同head中单词的Attention(侧重点)不同,通过结合多个自注意力层形成多头(Multi-Head)机制来使模型获得更大容量。基于多头机制的自注意力层的输出会经过Add&Norm层,其中Add表示残差连接(Residual Connection),Norm表示层归一化(Layer Normalization),通过将经过位置信息编码后的输出与多头机制自注意力层的输出相加,再进行层归一化操作,这样可以做到仅关注差异部分并使模型更容易训练。Add&Norm层的输出传递到前馈神经网络层(Feed Forward),再经过Add&Norm层后输出。
ALBERT (AIITE BERT)是GOOLE公司基于BERT基础上进行了一系列改造后的预训练小模型[11],该模型参数量相比传统BERT大幅度降低,运行速度提高,在一定程度上突破了硬件的限制,并在许多自然语言处理任务上发挥出色。
ALBERT相较于BERT的改进点主要有以下几点。
(1) Factorized embedding parameterization(词嵌入因式分解):降低Embedding层的词嵌入维度,并在词嵌入和隐藏层间再添加一个project层。假设词表大小为L,隐藏层维度为H,词嵌入维度为V。那么BERT模型参数P bert计算公式为:
ALBERT模型参数P bert计算公式为:
BERT模型中词嵌入维度和隐藏层维度相同,在通常V很大,V远小于H的情况下,词嵌入因式分解后的参数量将大幅度减小。
(2) Cross-Layer Parameter Sharing(跨层参数共享):在ALBERT模型中结合了Transformer两种参数共享的方式,将全连接层和attention层都实现了参数共享,达到减小参数量和提高模型训练速度的效果。
(3) Inter-sentence coherence loss(句间连贯):改进了BERT模型原有的连续句二分类训练任务,提出了SOP( sentence-order prediction)的新型训练任务,让模型去识别给定两个句子的先后顺序。
(4)移除dropout。
2.3 LSTM与Bi-LSTM
1996年Hochreiter等人[12]羽提出了一种新型循环神经网络,长短期记忆网络(Long Short-Term Memory,LSTM),这种网络相对于传统的神经网络(RecurrentNeural Networks,RNN)解决了在长文本训练过程中易出现梯度消失与梯度爆炸的问题,它的细胞结构如图4所示。
LSTM网络通过堆叠这种细胞结构来形成重复模链的结构。在LSTM的基础上,Graves等[13]提出了双向长短记忆网络(Bidirectional Long Short-TermMemory,Bi-LSTM),Bi-LSTM能够更好的捕获双向语义的依赖。Bi-LSTM的具体结构如图5所示,其中LSTM,和LSTM。分别是前向传递模块和后向传递模块,XN表示N位置上的词向量输入,h LN和hRN分别是N位置的前向传递隐层输出和N位置的后向传递隐层输出。Bi-LSTM在分类问题最终输出是[h LN,h RN]。
2.4 ALBERT-BiLSTM谣言识别模型
本文结合ALBERT模型和Bi-LSTM神经网络设计了一种微博谣言识别模型,该模型的具体结构如图6所示。处理好的句子向量首先会经过ALBERT模型进行词训练,再经过Bi-LSTM神经网络层进行特征提取,加入Dropout层为了防止过拟合的产生,最后进入全连接层降维,在判别层输出对应标签。
3 实验与分析
3. 1实验数据集的获取与处理策略
本文采用智源研究院·中科院计算所开源的已标注好的虚假新闻文本数据集(MCG-FNeWS)。该数据集共含有38471条微博新闻,其中包括真实新闻19186条,虚假新闻19285条。真实新闻标签为O,虚假新闻标签为1。
本实验对数据的处理策略如图7所示。①unicode编码:将文本数据转化为字符串。②奇怪字符处理:去除部分控制字符、替换字符,将多个空白字符转化为空格处理。③中文处理:中文按字用空格分开,英文和数字不变。④空格分词:去掉多余空白字符后按空格进行切分,返回字符列表。⑤多余字符处理和标点分词:去除变音符号并根据标点进行切分。⑥再次空格分词:操作同④。⑦二次切分:限制输入长度,将多余词标记为[unk_token],从左到右拆分多个字词,要求每个字词尽可能长。⑧句子向量化:根据词表的id转化为句子向量。⑨padding处理:将句子向量填充到指定长度,保证输入维度的一致性。
实验采用五折交叉验证(5-fold)处理数据集,将样本数据随机分成五组数据,每组数据与样本集比例为1:4,每次训练都是取其中1组作为测试集,余下4组作为测试集,所得五组数据见表1。
模型性能评价标准采用准确率(Precision,P),召回率( Recall,R)和Fl值(Fl-score,Fl),公式如下:
3.2 模型構建和具体参数设置
本文采用Tensorflow框架进行模型的构建,Tensorflow是Google公司开发的并且广泛应用于深度学习、机器学习等领域的开源计算库。
为了验证ALBERT语言模型能够更好地捕获语义特征,设置了结合Word2Vec语言模型的对比实验。Word2Vec预训练模型采用腾讯AI实验室汉字词嵌入语料库[14],并截取了其中45000个词向量作为嵌入层(Embedding)的词嵌入矩阵。Word2Vec预训练语言模型的词向量输出维度为200。对比实验的设置见表4。
3.3 实验结果
在MCG-FNeWS数据集上采用Word2Vec,Word2Vec-LSTM. Word2Vec-BiLSTM.ALBERT.ALBERT-LSTM.ALBERT-BiLSTM进行实验,具体实验结果见表5。
3.4 实验结果分析
根据表5我们可以发现:
(1)基于ALBERT的模型性能都优于基于Word2Vec的模型,并在评估指标上提升幅度较大。其中在准确率、召回率和Fl值上,ALBERT-BiLSTM模型相较于Word2Vec-BiLSTM模型分别提高了6.223%、7.778%、6.343; ALBERT-LSTM模型相较于Wor-d2Vec-LSTM分别提高了7.310%、8.665%、7.440%;ALBERT模型相较于Word2Vec模型分别提高了8.318%、10.174%、8.505%。传统的Word2Vec语言模型训练出的词向量是静态的,虽然通用性较强,但需要大量针对性的文本数据进行训练,并且该模型在文本中出现同义词、一词多义的情况下效果不佳,无法在特定任务下进行动态优化。而ALBERT语言模型集成Transformer框架和Self-Attention机制,能够更好地提取词的文本语义特征,从而提升模型的性能。
(2)在准确率、召回率和Fl值上,ALBERT-BiLSTM模型分别达到了98.095%、98.014%、98.098%,是所有实验模型中最高的,相较于ALBERT-LSTM模型和ALBERT模型有一定程度的提升,总体提升幅度不大。其中,ALBERT-BIL-STM模型相较于ALBERT-LSTM模型提升了0.161%、0.306%、0.164%; ALBERT-BILSTM模型相较于ALBERT模型分别提升了0.161%、0.202%、0.162%。实验表明,ALBERT-BiLSTM模型已经能够较好地识别微博谣言。
4 结束语
由于谣言初期的隐蔽性特征,人们很難根据谣言的传播特征、谣言发布者用户属性特征来判断内容真伪。本文设计的谣言识别模型通过挖掘文本的深层语义特征来识别谣言,识别准确率达到了98.095%。但由于模型自身的局限性和缺少海量数据支撑,无法通过挖掘不同内容之间的复杂联系来识别谣言。在大数据时代背景下,信息内容复杂和多样,信息传播迅速,如何快速识别谣言仍然非常困难。
参考文献(References):
[1]Cao J,Sheng Q,Qi P,et aL False News Detection onSocial Media[EB/OL]. arXiv preprint arXiv:1908.10818, 2019.
[2]Jin Z,Cao J,Zhang Y,et aL News Verification byExploiting Conflicting Social Viewpoints in Microblogs[C]//Thir[ieth Aaai Conference on Artificial Intelligence.AAAI Press,2016.3.
[3]Shu K,Wang S,Liu H.Beyond News Contents: The Roleof Social Context for Fake News Detection[C]. WSDM2019:312-320
[4]Zhang J,Cui L'Fu Y,Gouza F.Fake News Detection withDeep Diffusive Net,^iork ModeI[EB/OL].arXiv:1805.08751,2018.5.https://arxiv.org/pdf/1805.087 5l.pdf.
[5]林荣蓉.基于敏感词库的微博谣言识别研究[D].中南财经政法大学,2018.
[6]曾子明,王睛.基于LDA和随机森林的微博谣言识别研究——以2016年雾霾谣言为例[J].情报学报,2019.38(1):89-96
[7]杨真.新浪微博谣言识别研究[D].郑州大学,2018.
[8]王勤颖.微博谣言识别模型研究[D].山东师范大学,2019.
[9] Vaswani A, Shazeer N, Parmar N, et aL Attention Is AllYou Need[C].Advances in Neural Information Process-ing Systems 30,2017:5998-6008
[10] Jacob D, Ming-Wei C, Kenton L, Kristina T. BERT: Pre-training of Deep Bidirectional Transformers for Lan-guage Unde-rstanding[EB/OL], arXiv, 2018-10-11,https://arxiv.org/pdf/1810 .0480 5.pdf
[11] Lan Z,Chen M, Goodman S,et al. ALBERT:A Lite BE-RT for Self-supervised Learning of Language Repre-sentations[EB/OL]arXiv,2 019. 11, https://arxiv.org/pdf/1909.11942.pdf.
[12] Hochreiter S,Schmidhuber,J n rgen. Long Short-TermMem-onj[J].NeuralComputation,1997.9(8): 1735-1780
[13] Graves A, Ju rgen Schmidhuber. Framewise phonemeclassi-fication with bidirectional LSTM and otherneural network arch-itectures[J]. Neural Networks,2005.18(5-6):602 -610
[14] Yan S,Shi S,Li J,Zhang H. Directional Skip-Gram: Exp-Iicitly Distinguishing Left and Right Context forWord Embed-dings[C].NAACL,2018 (Short Paper).
作者简介:孙尉超(1996-),男,浙江绍兴人,硕士研究生,主要研究方向:自然语言处理。
通讯作者:陈涛(1970-),男,浙江淳安人,博士,副教授,硕士研究生导师,主要研究方向:人工智能审计,模式识别等。
