
基于深度特征融合的图像分类算法的研究
2020-10-15 12:15蔡志锋袁宝华刘广海
计算机应用与软件 2020年10期
蔡志锋 袁宝华 刘广海
1(三江学院计算机科学与工程学院 江苏 南京 210000) 2(南京理工大学泰州科技学院计算机系 江苏 泰州 225300) 3(广西师范大学计算机科学与信息工程学院 广西 桂林 541004)
0 引 言
基于内容的图像分类主要通过图像的视觉特征信息对图像进行分类,是近年来计算机视觉、人工智能等领域中一个非常热门的研究课题。传统的图像分类方式通常使用统计学习算法进行图像分类,例如:支持向量机[1](SVM)、K均值聚类[2]和最近邻距离[3]等。但上述算法未曾考虑图像的高层语义信息,因此经常产生错分、漏分等现象,分类精度较低。
深度学习网络是近十年来兴起的一种方法,已经应用到图像的各个领域中并取得了令人惊喜的进展,如:目标识别[4]、图像检索[5]和图像分类[6-7]等。深度学习通过多个隐含层的学习,从大规模数据中逐层进行学习和特征提取,寻找数据最优的抽象表达方法,从而提高分类或识别的准确率。但深度网络模型需要大量的数据进行训练,耗时较长,对存储要求也相对较高。对于小数据量的数据集,直接采用CNN进行训练,往往容易造成过拟合现象,因此通常采用预训练的CNN网络。输入图像经过深度学习预训练网络,将卷积层或者连接层的响应值作为该图像的深度特征,然后通过训练SVM等常规分类器对场景图像进行分类。
数据模态的多样性必然导致特征抽取方式的多样性,每种特征抽取方式都有其关注的侧重点,比如:纹理特征描述符只关注纹理而不关心颜色,因此单个特征通常只表征某一方面的信息。特征融合优势是明显的,因为同一模式所提取的不同特征向量反映了模式的不同特性,对它们进行优化组合,既保留了参与融合的多组特征的有效鉴别信息,又消除了特征向量之间的冗余信息。深度学习方法已经深入到在计算机的各个领域中,研究适用于深度学习的信息融合技术很有必要。融合方法通常分为像素级、特征层以及决策层的融合[8]。特征层的融合[9-11]相比其他两种融合更有效,因为其融合后的特征通常包含更多丰富的信息,从而提高识别率。Miao等[9]通过ResC3D深度学习网络提取深度特征,然后采用典型相关分析方法进行特征融合,用在手势识别上取得了不错的效果。Haghighat等[10]考虑分类中的类别信息,提出鉴别相关分析的方法用于多模态的特征融合,该方法能够有效地消除类间的相关性,限制类内的相关性。Chaib等[11]采用VGG预训练网络不同全连接层的特征,通过判别相关分析(Discriminant Correlation Analysis,DCA)进行特征融合,最后通过SVM进行分类。借鉴文献[9-11]的思路,本文采用不同的预训练网络来提取图像的高层语义特征,然后进行特征融合,最后采用SVM分类器分类。
本文比较了两种不同的深度特征获取策略:(1)采用同一预训练深度学习网络的不同层特征的特征融合;(2)采用多个深度学习网络的全连接层特征的特征融合。同时,通过增加权重,重新定义DCA方法中的类间散度矩阵,使其能够对那些类别差异较小的类别也有较好的区分度。该方法可以充分利用深层网络结构的优势,获取图像的高层语义特征,提高分类结果的准确性,同时考虑了深度特征融合,能更有效地挖掘高层语义特征,大幅降低训练时间并提高分类精度。构建多个预训练CNN的深度特征的特征融合,将其应用到图像分类中,实验结果表明该特征融合方法获得的深度特征相比于单个深度学习特征,具备强大的特征表征能力和低维特性,从而提高图像分类性能。
1 相关知识
1.1 特征融合
典型相关分析(Canonical Correlation Analysis,CCA)通常是用来解决两组随机向量之间相互关系的统计方法,其目的是寻找两组投影方向,使两个随机向量投影后的相关性达到最大[12]。然而,CCA的主要缺点是其忽略了数据集中的类别信息。近年来,DCA的出现克服了CCA中忽略类别信息的缺点,能够将同类样本特征相关性最大化,同时最小化不同类样本特征之间的相关性,有利于提高分类性能。
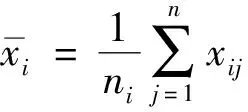
(1)
类间散度矩阵定义为:
(2)
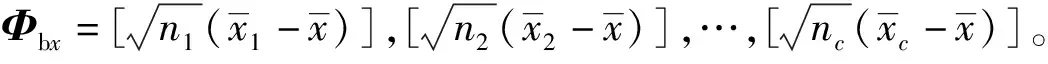

(3)
式中:P是正交向量矩阵;Λ是由非负特征值组成的对角矩阵。式(3)可表示为:
(4)
式中:φ(c×r)是最大非零的特征向量矩阵;r表示矩阵的秩。
Sbx最大r个特征向量能通过映射φ→Φbxφ得到:
(Φbxφ)TSbxΦbxφ=Λ(r×r)
(5)

(6)
(7)
第二特征集Y也采用上述方法得到:
(8)
(9)
式中:r为转换后特征的秩。
r≤min(c-1,rank(X),rank(Y))
(10)
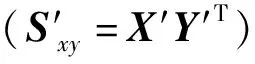
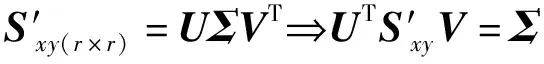
(11)

(12)
(13)
式中:Wx=WbxWcx和Wy=WbyWcy分别表示X和Y的最终的转换矩阵。
1.2 深度特征网络
在过去的十年中,已经开发出几种用于大规模图像分类和物体检测的CNN模型,例如:Alexnet[13],VGG[14],ResNet[7],Inception-v3[16],GoogLeNet[17]和Inception-ResNet-v2[18]等。不同的预训练网络具有不同的特性,它们都具备了提取强大且丰富特征的能力,从而使得其能迁移学习到其他领域中。不同的深度学习网络具有不同的网络结构,下面介绍几种典型的深度网络。
(1)AlexNet:由Alex Krizhevsky设计的卷积神经网络,共八层,前五层是卷积层,后三层是全连接层。在网络中使用非饱和ReLU激活函数,其能够提供比tanh和sigmoid等激活函数更好的训练性能。实验中,网络的输入图像大小通常为227×227,提取第一个全连接层特征作为图像特征,其维数为4 096维。
(2)ResNet:2015年提出的深度卷积网络,当年在ImageNet竞赛中获得图像视觉挑战中三项任务的冠军。通过增加网络的深度来提高识别率,从而解决网络深度增加带来的退化问题,使网络更容易优化。实验中,提取残差网络的全连接层作为图像特征,其维数为1 000维。
(3)VGG:在AlexNet网络的基础上开发的,其具有良好的泛化能力。VGG网络由conv、pool、fc和softmax层组成。它的主要贡献是使用一个非常小的3×3卷积内核进行网络设计,并将网络深度增加到16或19层。在实验中,采用第一个全连接层的特征来作为图像特征,其维数为4 096维。
(4)GoogLeNet:由Szegedy等构造的深度学习网络,其网络结构稀疏且具备高计算性能。该模型通过构造Incepteion模块和均值池化来代替全连接层来减少模型参数规模。在网络设计之初,研究人员就考虑了计算效率和实用性,从而让GoogLeNet能够在不同设备上运行。实验中,获取最后一个池化层特征来作为图像特征向量,其维数是1 024维。
几种典型的深度学习网络参数如表1所示。

表1 典型的深度学习网络参数
与大多数基于SIFT、SURF和HOG等低层特征的场景分类方法相比,本文提出的框架是基于不同预训练CNN模型的深度特征的融合。将不同预训练CNN模型的全连接层作为输入的特征向量,能够描述图像场景的重要特征。
2 基于深度特征融合的图像分类算法
2.1 Weighted DCA(WDCA)
DCA算法考虑了类别信息,能够使同类特征相关最大化,并且不同类的特征相关最小化,但是其不能很好区分类间距离较小甚至重叠的类别。DCA的类间散度矩阵如式(2)所示,对于那些类间距离越大的类别,其散度矩阵中对应的值越大,反之,则越小。这样会导致过分强调那些离散度大的类的作用而忽略了离散度较小的类。
为此,通过增加权重来约束,降低那些离散度大的类的影响,提高离散度较小类的作用。重新定义DCA算法中的类间散度矩阵为:
(14)
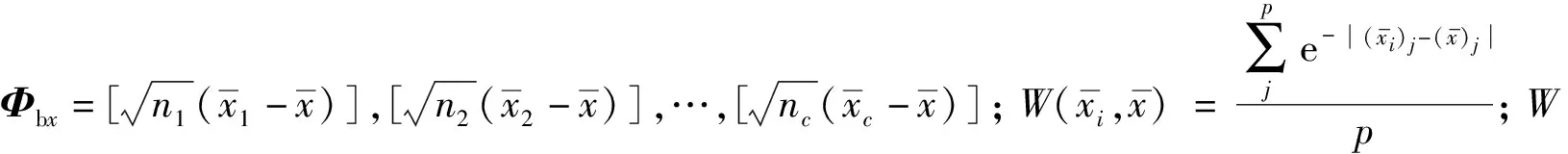
2.2 基于WDCA的图像分类算法
目前,常用的特征融合方法通常有:简单叠加和串行连接。简单叠加方法难以反映多特征之间的差异性,而串行连接方法通常会产生高维的融合特征,其包含了过多的冗余信息,导致计算效率降低。因此本文将WDCA的方法应用于深度网络的高层语义特征的融合,其不但能够有效地表征不同的语义特征之间差异,而且能够有效地降低特征融合后的维度,从而大大地节约计算成本。本文采用两种策略来进行深度网络的高层语义特征获取,并在实验中进行比较分析。
第一种策略:首先输入图像通过同一类型的卷积神经网络,然后分别提取不同层的深度特征作为图像特征,对其采用WDCA的方法进行融合。
第二种策略:首先输入图像通过两个不同类型的卷积神经网络提取到深度特征,然后对深度特征采用WDCA的方法进行融合。
两种策略仅在于深度学习特征的获取方式不同,后续特征融合的步骤相同。采用上述策略,特征融合后的特征维数为100×2,维数大大降低,使训练时间大大缩短,最后通过SVM分类器进行识别,如图1所示。
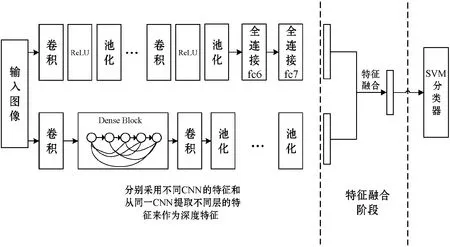
图1 基于深度特征融合的图像分类框架
选择不同深度网络的全连接层或者同一深度网络的不同层作为图像的深度特征,然后通过WDCA方法对两个不同的深度特征进行融合。由于X和Y的维数通常远大于类别数,如式(10)所示,则融合后的特征维数最大为C-1,C为类别数。采用两种形式来表示单个图像的特征:
(15)
此为串行形式,融合后的特征维数2×(C-1)。
(16)
此为求和形式,融合后的特征维数为C-1。
基于深度特征融合的图像分类算法步骤如下:
(1)利用不同的预训练网络,分别提取训练集图像的全接连层的深度特征,构成图像深度特征矩阵Xm×p=[φ1,φ2,…,φm]和Ym×q=[ψ1,ψ2,…,ψm]。
(2)根据WDCA特征融合算法,利用式(12)和式(13)将矩阵X和Y融合后分解为DX、DY以及投影矩阵Wx、Wy;根据式(15)或式(16)组合成训练图像最终的特征融合向量Z1或Z2。
(3)利用不同的预训练网络,提取测试图像的深度特征矩阵TXn×p=[φ1,φ2,…,φn]和TYn×q=[ψ1,ψ2,…,ψn]。分别将其投影到对应的特征空间Wx、Wy,得到测试图像的深度融合特征A和B特征向量:
A=WxTX
(17)
B=WyTY
(18)
(4)根据式(15)或式(16)将测试图像的特征A和B组合成测试图像最终的特征融合向量TZ1或TZ2。
(5)采用SVM分类器进行图像分类。
3 实验结果
3.1 实验平台
为了验证特征融合方法的有效性,本文在公开的Caltech 256数据集上,对算法进行评估。在分类任务中,采用SVM分类器,使用LIBSVM库[1],并通过五个交叉验证选择正则参数。实验中计算机配置如下:Intel Core I7-4710Mq CPU @2.5 GHz×8, 内存12 GB,无GPU。实验中软件环境为MATLAB 2018b,使用的深度学习网络架构均来自MATLAB 2018b自带的深度学习包。
对于第一种策略,采用VGG预训练网络,提取fc6、fc7层特征进行特征融合;对于第二种策略,分别采用VGG(简称V)、resnet101(简称R)、GoogLeNet(简称G)和inceptionresnetv2(简称I)四种不同结构的预训练网络进行特征融合。
Caltech 256数据库是Li等[18]在Caltech 101数据集的基础上进行的扩展,分为256个不同的对象类别,共有30 607幅图像。Caltech 256数据库选自Google Image数据集,总共分为256个类别,每个类别包含的图像数量为80到827幅不等,每幅图像的尺寸大小不等,图2为Caltech 256部分示例图。

图2 Caltech 256部分图像
3.2 实验分析
在使用不同的卷积神经网络处理之前,需要根据不同的深度CNN网络的要求对输入图像大小进行调整。为了验证WDCA方法对于深度特征融合的有效性,分别采用单独的深度学习网络提取特征,然后采用不同深度网络的深度特征融合,最后采用SVM分类器进行分类识别,分类结果如表2所示。
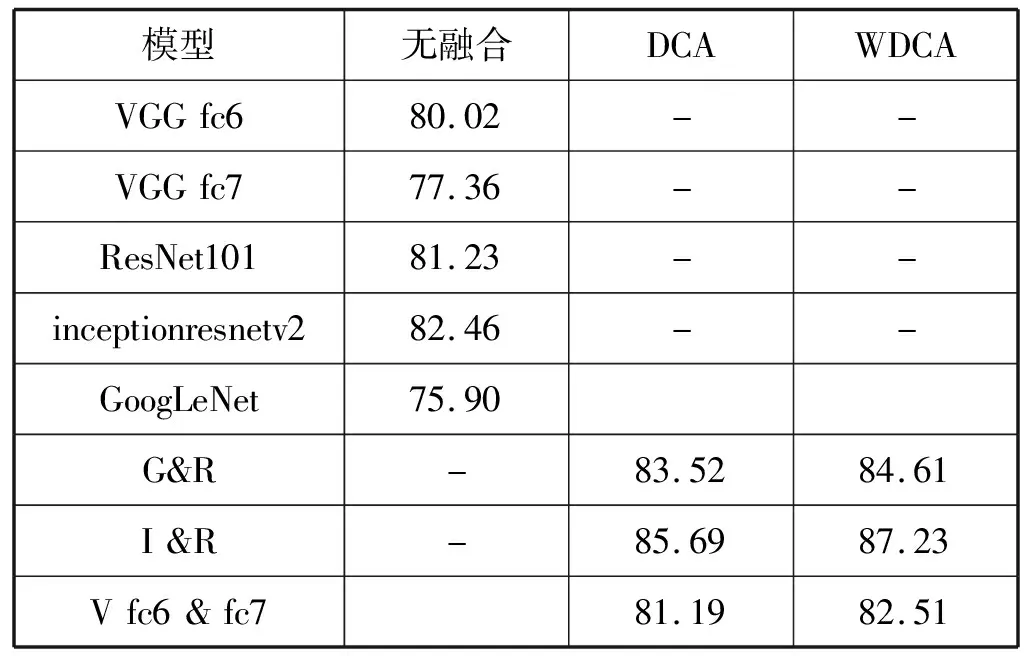
表2 不同的深度特征的图像分类结果 %
可以看出,与采用单个深度学习网络结果相比,本文提出的两种不同策略的深度特征融合方法的识别率有较好的提升,说明融合后的深度特征更能够描述场景,有利于提高场景的识别率。同时,WDCA的特征融合效果要优于DCA,这主要因为其平衡了类别差异的影响,类别差异小的类别能够增加其类间距离,而那些类别差异较大的类别,降低其类间距离,也不影响其区分度。
此外,从不同的深度学习框架提取的特征融合策略要优于从同一深度学习框架提取的特征融合,这主要因为不同的深度学习框架其特征的互补性要优于同一个深度学习网络的不同层。
不同的深度学习框架提取的特征,识别率也不相同,这说明不同的深度网络提取的特征各有差异。从融合后的结果来看,其不同的深度网络特征尽管不同,但是具有一定的互补性,因此融合后的特征表达能力要强于单个特征。GoogLeNet预训练网络的特征识别率最低,但是融合后的特征识别率提升幅度最大。这也说明融合前的各自特征表达能力强,不代表融合后的特征表达能力一定强。融合后的特征表达能力强弱主要取决于融合前特征的互补性。
为了验证特征融合方法的执行效率,比较了单个深度网络的图像分类方法和基于WDCA深度特征融合的图像分类方法的训练时间和测试时间,结果如表3所示。可以看出,经本文方法融合后的特征维数仅为200,远小于全连接层的4 096维特征,因此其训练时间和测试时间也大幅降低。特征融合方法是对深度特征进行优化组合,既保留了参与融合的深度特征的有效鉴别信息,又消除了特征向量之间的冗余信息。

表3 不同方法的训练时间和测试时间的比较 s
4 结 语
针对复杂场景下的图像分类问题,本文提出基于深度学习预训练网络对场景进行特征学习,然后基于权重的DCA方法进行特征融合,最后通过SVM分类器进行图像场景的分类识别。传统的特征融合方法不仅容易导致维数增高,而且冗余信息较多。深度特征虽然表达特征能力较强,但是其维数较高且包含冗余信息,不同的深度网络结构提取的特征的表达能力也各不相同。本文提出的深度特征融合方法不仅能够有效地优化不同的深度CNN网络组合,而且能够有效地消除冗余信息,其特征维数也大大降低,在提高图像分类识别率的同时又减少了样本训练和测试时间。实验结果验证了本文方法的有效性和正确性。
猜你喜欢
广西大学学报(自然科学版)(2022年2期)2022-07-06
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
火力与指挥控制(2021年10期)2021-12-29
广东蚕业(2021年2期)2021-04-22
少儿画王(3-6岁)(2020年4期)2020-09-13
福建基础教育研究(2019年6期)2019-05-28
东方教育(2018年20期)2018-08-22
微型计算机(2009年4期)2009-12-23
新课程研究·上旬(2009年2期)2009-03-02
