
基于改进NSGA-Ⅱ的多目标绿色作业车间调度问题研究
2020-12-02 01:19文笑雨孙海强李浩乔东平肖艳秋曹阳
河南理工大学学报(自然科学版) 2020年5期
文笑雨,孙海强,李浩,乔东平,肖艳秋,曹阳
(郑州轻工业大学 河南省机械装备智能制造重点实验室,河南 郑州 450002)
0 引 言
目前,中国工业化与现代化快速发展,温室气体排放量迅速增长[1]。环境问题已成为世界各国关注的热点,并列入世界议事日程。《中国制造2025》明确提出,全面推行绿色制造,实施绿色制造工程[2]。绿色车间调度是面向绿色制造的车间调度问题[3],是影响生产质量、效率、成本等因素的关键,对加工过程中的能耗产生重要影响[4]。通过资源分配、操作排序和运作模式的合理优化,可实现增效、节能、减排、降耗,提高经济效益,同时实现制造过程的绿色化[5]。
绿色车间调度问题是传统车间调度问题的扩展[3],其中作业车间调度(job shop scheduling,JSP)应用领域极其广泛,绿色作业车间调度问题(green job shop scheduling,GJSP)需同时考虑绿色生产指标和经济指标,比传统的JSP问题更复杂,求解难度更大。近年来,越来越多的学者对GJSP进行了研究。G.May等[6]分析了4种车间调度策略对作业车间调度完工时间和总能耗的影响,提出一种对多个优化目标进行评估的绿色遗传算法;A.Miguel等[7]研究了GJSP中能耗、完工时间和鲁棒性之间的相互关系,指出鲁棒性与能耗存在着明显的制约关系;ZHANG R等[8]将机器产出速率作为变量建立了面向能耗的作业车间调度模型,提出一种多目标遗传算法求解该模型;LIU Y等[9]研究了作业车间调度环境下能量的消耗情况,建立了非加工阶段能量消耗和总加权延迟时间的多优化目标模型,采用非支配排序遗传算法求得Pareto最优前端。
综上所述,GJSP问题的研究尚处于起步阶段,亟需建立更加贴合实际生产的多目标绿色作业车间调度问题模型,并结合问题特性设计更加有效的求解方法。本文针对多目标GJSP问题开展研究,建立兼顾最大完工时间指标、低碳指标和最大总拖期时间指标的多目标GJSP模型,低碳指标中增加了工件更换装夹方式时机器调整状态的碳排放量;提出改进的NSGA-Ⅱ进行优化求解,设计基于N5邻域结构和非支配关系的种群个体局部搜索策略;构造15组不同规模的多目标GJSP问题实例进行验证,计算结果证明了模型和算法的有效性。
1 多目标绿色作业车间调度问题模型
1.1 问题描述
本文求解的多目标GJSP可描述为:n个工件在m台机器上加工,已知每个工件包含的所有工序及工序的加工顺序,每道工序的加工机器、加工时长和加工时冷却液消耗量,通过合理安排每台机器上工件的加工顺序,寻找出一组兼顾绿色指标、效率指标及其他性能指标的均衡解。
多目标GJSP的目标是确定表1中每台机器(M1,M2,M3)上各工件(J1,J2,J3)的加工顺序及每道工序的开始时间,以同时兼顾多种性能指标。

表1 3个工件的加工信息
1.2 混合整数规划模型
本文求解的多目标GJSP同时优化以下3个目标:最小化最大完工时间(Cmax)、最小化总碳排放量(Catotal)、最小化总拖期时间(Tatotal),并满足以下假设条件:
(1)同一工件的加工工序所使用的刀具是固定不变的。
(2)每台机器上使用的冷却液、润滑油均采用同一类型。
(3)同一机器加工任意工序时运行功率不变。
(4)同一机器同一时间只能加工一个工件。
(5)同一个工件同一个时刻只能在一台机器上加工。
(6)每一道工序一旦开始便不能中断。
基于上述假设条件,目标函数定义如下。
(1)最小化最大完工时间f1
MinCmax={maxCi,i=1,…,n},
(1)
式中,Ci为工件Ji的完工时间。
(2)最小化总碳排放量f2
MinCatotal=Cproc+Cidle+Cfit+Ccold+Coil=

(2)
机器运转消耗电能引起的碳排放由机器的启动、预热、加工、空转、停止这5个阶段组成[10],本文在此基础之上增加了工件更换装夹方式时机器调整状态的碳排放量。对于多目标GJSP问题,考虑到机器的启动、预热、停止3个阶段的能耗仅与机器的启动次数有关,可视为常量不予考虑。因此,在零件制造过程中碳排放量影响因素包含机器负载运转消耗电能引起的碳排放Cproc、机器空转的能耗碳排放Cidle、更换装夹方式时机器调整能耗碳排放Cfit、冷却液消耗引起的碳排放Ccold、润滑油损耗引起的碳排放Coil。
式(2)中使用的符号说明如表2所示。
(3)最小化总拖期时间f3

表2 式(2)符号含义

(3)
式中,di为第i个工件的交货期。
对于多目标GJSP需满足以下约束条件:
(1)CTi,j-PTi,j+M(1-Yi(h,j))≥CTi,h,i∈{1,2,…,n};j,h∈{1,2,…,m}。
(2)CTi,j-CTq,j-tfq,i+M(1-Xj(i,q))≥PTi,j,i,q∈{1,2,…,n};j∈{1,2,…,m}。
(3)CTi,j≥STi,j+PTi,j,i∈{1,2,…,n};j∈{1,2,…,m}。
(4)STJk,j≥CTJk-1,j+tfJk-1,j,j∈(1,2,…,m)。
上述约束条件中:CTi,j为工件i在机器j上的完工时间;CTq,j为工件q在机器j上的完工时间;CTJk-1,j为机器j上第k-1个加工任务的完工时间;CTi,h为工件i在机器h上的完工时间;STi,j为工件i在机器j上的开始加工时间;STJk,j为机器j上第k个加工任务的开始加工时间;PTi,j为工件i在机器j上的加工时长;tfq,i为工件q与工件i之间机器调整时间;M是一个足够大的正数;Yi(h,j),Xj(i,q)为决策变量,其含义为
2 用改进的NSGA-Ⅱ求解多目标GJSP
本文在基本NSGA-Ⅱ框架下,结合多目标GJSP特性,设计了基于N5邻域结构和非支配排序的局部搜索策略[11],提出改进的NSGA-Ⅱ对多目标GJSP进行求解。
2.1 编码与解码
本文采用基于工序的编码方法[12]对种群中个体进行编码。解码是将染色体还原成一个可行调度的过程,本文应用插入式贪婪解码算法[7]进行解码,获得主动调度解。
2.2 种群初始化及适应度评价方法
种群中每个个体代表着一种可行的调度解,在对个体初始化时按照编码方法随机调整染色体中基因的排列顺序,对排序后的染色体进行主动解码操作,最后根据式(1)~(3)计算个体的各目标函数值。
本文设计的算法采用了NSGA-Ⅱ中的快速非支配排序、拥挤距离作为评价方法比较种群个体的优劣。种群中非支配等级低的个体的适应度优于非支配等级高的个体,对于同一等级中的个体,拥挤距离大的个体具有更好的适应度值。
2.3 种群个体的选择、交叉与变异操作
进行选择操作时,对种群中的个体采用锦标赛的方法选择,优先选择非支配等级低的个体染色体,相同等级下选择拥挤距离大的个体。
交叉操作决定了算法的全局搜索能力,它要求尽量保留父代个体的优良基因,本文采用文献[12]中交叉算子(precedence operation crossover,POX),变异操作是将染色体基因序列上的某些基因位上数值进行变动的过程,本文采用交换变异法变异,相互交换不同基因位上的数值。
2.4 基于N5邻域结构及非支配关系的个体局部搜索策略
为了增强算法局部搜索能力,本文在算法中设计基于N5邻域结构及非支配排序的个体局部搜索策略。如图1所示,邻域结构N5是通过交换关键路径上的关键工序块产生新的邻域解[13]。

图1 N5邻域结构
基于N5邻域结构及非支配关系的个体局部搜索策略流程如图2所示,具体流程描述如下。
步骤1 统计当前种群个体的总数目pu,令i=1,i为当前选择的个体。
步骤2 对当前个体i采用N5邻域结构的第一步移动操作产生邻域个体Ti。
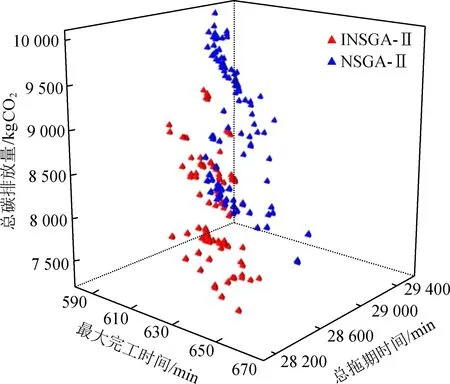
步骤3 对邻域个体Ti进行解码操作,计算邻域个体Ti的各个目标函数值(Cmax,Ctotal,Catotal),如果个体Ti的各目标函数值均小于当前个体i的相应目标函数值即fj(Ti) 图2 基于N5邻域结构及非支配关系的个体局部搜索策略 步骤4 对当前个体i采用N5邻域结构的第二步移动操作产生邻域个体Ti。 步骤5 对邻域个体Ti进行解码操作,计算邻域个体Ti的目标函数值(Cmax,Tatotal,Catotal),如果个体Ti支配个体i(Tii),则将个体Ti替换个体i;否则保留当前个体i顺序执行。 步骤6 令i=i+1,判断i是否大于pu,当i大于pu时,结束循环,否则跳转到步骤2。 结合上述算法关键步骤的描述,用INSGA-Ⅱ(improved,INSGA-Ⅱ)求解多目标GJSP的总流程如图3所示。 步骤1 设定INSGA-Ⅱ算法的参数:算法迭代次数Genmax,种群数目N,选择概率Ps,交叉概率Pc,变异概率Pm,Pareto解集最大数目MaxSize。 步骤2 初始化N个种群个体,定义该种群为父代种群P;令Gen=0。 步骤3 对种群P中的个体应用插入式贪婪算法解码,得到每个个体的主动调度解。 图3 INSGA-Ⅱ求解流程图 步骤4 计算解码后个体的目标函数值,根据种群个体的各个目标函数值,对种群P进行快速非支配排序,确定每个个体当前的非支配等级。 步骤5 更新Pareto解集。 步骤5.1 如果当前Pareto解集为空时,将当前种群中非支配等级为1的个体(irank=1)存入Pareto解集;如果当前种群P中irank=1个体数目大于MaxSize,计算当前非支配等级个体的拥挤距离,按照拥挤距离从大到小依次填入Pareto解集中。 步骤5.2 如果当前Pareto解集不为空时,剔除种群P中与当前Pareto解集中相同的个体,种群P中irank=1个体和Pareto解集中的个体存入种群Ptemp中,对种群Ptemp进行快速非支配排序及拥挤距离计算,如果种群Ptemp中irank=1的个体数目大于Pareto解集MaxSize,按照拥挤距离依次填入Pareto解集中,否则直接将irank=1个体存入Pareto解集。 步骤6 对种群P中的个体进行选择、交叉及变异,生成子代种群Q。 步骤7 剔除种群P和种群Q中相同的个体,合并种群P和种群Q为种群PN。 步骤8 根据种群PN中个体的非支配等级,构建非支配等级曲面{F1,F2,…,Fn}。 步骤9 在种群PN中选择N个个体形成种群P。 步骤10 根据2.4节中基于N5邻域结构及非支配关系的个体局部搜索策略,更新种群P中个体。 步骤11 令Gen=Gen+1,如果Gen>Genmax,输出Pareto解集,否则跳转到步骤3。 由于缺乏多目标GJSP基准测试实例,本文设计15组算例进行测试,并与基本的NSGA-Ⅱ算法进行对比,验证本文提出改进算法的有效性。 根据表3~5的工件加工信息制定表6~8的5组基准测试实例。 表3 10个工件在6台机器上的加工信息 续表3 表4 10个工件在10台机器上的加工信息 表5 10个工件在20台机器上的加工信息 表6 6台机器加工的GJSP实例 表7 10台机器加工的GJSP实例 表8 20台机器加工的GJSP实例 以表6为例,表9为该实例各机器在不同生产阶段的运行功率、冷却液和润滑油消耗量。同一机器加工不同工件时需要一定的调整时间更换工件,表10为加工不同工件时机器的调整时间(min)及交货期(min)。 表9 各机器的相关参数 表10 加工不同工件时机器的调整时间 电能碳排放因子αe取全国碳排放因子的平均值0.6747 kg CO2/(kWh),冷却液的碳排放因子、润滑油碳排放因子等参考香港中小企业碳审计工具箱[14],处理废液的碳排放因子2.75 kg CO2/L,冷却液使用碳排放因子0.3 kg CO2/L,取两者之和3.05 kg CO2/L作为冷却液的碳排放因子αcold,润滑油碳排放因子αoil为2.85 kg CO2/L。 使用Visual C++编程,进行优化求解,运行程序的计算机为Intel(R)Core(TM)i5-7400 CPU@3.00 GHz,4.00 GB运行内存。算法的实验参数如表11所示。 表11 算法实验主要参数 分别使用INSGA-Ⅱ算法和NSGA-Ⅱ对上述15组测试实例进行计算,针对每组实例,独立运行程序30次,分别统计30次独立实验中INSGA-Ⅱ和NSGA-Ⅱ算法求得的Pareto解,两种算法获得Pareto解的数目如表12所示。 表12 两种算法计算获得Pareto解的数目 针对表12中的每组问题实例,将两种算法求得的所有Pareto解集进行合并,并统计合并解集中的非支配解,两种算法合并解集的非支配解的数目如表13所示,同时给出了合并解集中的非支配解的数目。 表13 合并解集的非支配解数目 表13的计算结果显示,排序后的非支配解主要来源于INSGA-Ⅱ求得的解,NSGA-Ⅱ求得的解多数被INSGA-Ⅱ的解支配,INSGA-Ⅱ找到的Pareto解的非支配等级更高,初步验证了INSGA-Ⅱ算法优于NSGA-Ⅱ算法。 为了形象地对比INSGA-Ⅱ和NSGA-Ⅱ各自的优化效果,本文在表12中随机抽取出了问题10×6、问题15×10及问题30×20实例进行详细结果对比。 图4 问题10×6的Pareto解分布对比Fig.4 Comparisons of Pareto solutions distribution for problem 10×6 图4为表12中问题10×6的求解结果,通过对比分析,发现两组解中部分解之间存在一些支配关系,对两组解进行等级排序后,得到表13中问题10×6的计算结果,发现在两组解中总共可以找到68个非支配解,其中 INSGA-Ⅱ找到了67个,NSGA-Ⅱ找到了1个,因此,在该组实例问题的求解中,INSGA-Ⅱ算法优于NSGA-Ⅱ。再将问题的规划扩大到问题15×10、问题30×20上时,两者的优化效果如图5~6所示。 图5 问题15×10的Pareto解分布对比 图6 问题30×20的Pareto解分布对比 从图5~6 中可以清晰地发现,蓝点(NSGA-Ⅱ的Pareto解)基本上全部在红点(INSGA-Ⅱ的Pareto解)的右上方,大部分的蓝点被红点支配。再将问题规模扩展到问题30× 20上时INSGA-Ⅱ算法表现更加优秀,找到的95个非支配解均来源于INSGA-Ⅱ算法求得的Pareto解,验证了INSGA-Ⅱ算法优化效果好于NSGA-Ⅱ。 为了测试出INSGA-Ⅱ算法和NSGA-Ⅱ算法对于单个目标函数的优化情况,本文根据统计的实验数据将两种算法求得各优化目标(总碳排放量、完工时间和总拖期时间)的最小值进行对比,得出表14的计算结果。 表14 Pareto解中各优化目标的最小值对比 从最大完工时间看,9组实例的INSGA-Ⅱ算法拥有与NSGA-Ⅱ算法相同的完工时间,另外6组实例INSGA-Ⅱ算法找到了更小的最大完工时间;从总碳排放量看,INSGA-Ⅱ上找到了更低的总碳排放量;从总拖期时间看,INSGA-Ⅱ也找到了更小的总拖期时间。对于单个目标函数,INSGA-Ⅱ算法优化效果同样好于NSGA-Ⅱ算法。 INSGA-Ⅱ算法是在NSGA-Ⅱ算法基础上进行了基于N5邻域结构和非支配排序关系的局部搜索,通过移动个体关键路径上关键工序块,对个体进一步优化,部分工件间的空转时间、调整时间发生了变化,因此,能够找到多个优化目标相对更小的非支配解,从而支配了NSGA-Ⅱ求得的解,本文提出的INSGA-Ⅱ在求解MOGJSP问题时比基本的NSGA-Ⅱ性能更优。图7为问题30×20单个目标总碳排放量最小的甘特图。 图7 问题30×20总碳排放量最小解的甘特图 针对多目标GJSP,建立以最小化最大完工时间、最小化总碳排放量、最小化最大总拖期时间为优化目标的多目标混合整数规划模型,模型中的低碳指标增加了工件更换装夹方式时机器调整状态的碳排放量,提出了改进的NSGA-Ⅱ算法求解多目标GJSP,主要的改进内容是设计了基于N5邻域结构及非支配关系的个体局部搜索策略,设计了INSGA-Ⅱ算法的求解。计算结果显示INSGA-Ⅱ算法具有更好的优化性能。 在今后的工作中,将进一步研究绿色制造模式下的工艺规划与车间调度集成优化问题,并考虑引入NSGA-Ⅲ的一些机制设计出更有效的多目标优化方法。
2.5 用INSGA-Ⅱ求解多目标GJSP的总流程



3 算例验证
3.1 算例信息










3.2 计算结果及分析






4 结语与展望
猜你喜欢
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
农业工程学报(2022年7期)2022-07-09
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
智能制造(2021年4期)2021-11-04
逻辑学研究(2021年3期)2021-09-29
意林(2021年9期)2021-05-28
杭州电子科技大学学报(自然科学版)(2020年3期)2020-06-08
时代风采(2019年3期)2019-03-23
时代英语·高一(2019年1期)2019-03-13
计算机应用与软件(2018年12期)2018-12-13
