
基于高分辨率特征保持的图像去模糊
2021-01-08 07:33杨爱萍李晓晓何宇清
天津大学学报(自然科学与工程技术版) 2021年4期
杨爱萍,张 兵,王 前,李晓晓,何宇清
(天津大学电气自动化与信息工程学院,天津 300072)
图像采集过程中,由于曝光时间内摄像机抖动或拍摄场景快速运动,造成所拍摄图像模糊,严重影响图像的后续处理,如图像比对、特征提取、图像识别等.图像去模糊研究在交通安全[1]、监控影像[2]、医学影像[3]和目标检测等[4]领域起着极其重要的作用.
目前,针对去模糊问题已经做出了大量的工作,传统方法大多在贝叶斯框架下对清晰图像和模糊核做一些先验假设,然后将这些先验作为正则项约束构造目标函数,通过求解目标函数最优解估计模糊核进而复原清晰图像,如暗通道先验有助于自然图像的复原[5]、像素强度先验有助于得到显著边缘[6]、梯度先验能够有效去除伪影等[7].Zhang 等[8]提出分别利用低、中、高3 个强度的先验估计模糊核,进而估计清晰图像.虽然基于图像统计先验的去模糊方法取得了较好的复原效果,但是这类方法严重依赖于对图像信息的先验假设,很难泛化到其他模糊类型;同时,对模糊核先验假设过于简单,实际的模糊核是复杂和非线性的,现有方法难以解决实际问题.
近年来,由于深度神经网络具有强大的非线性逼近能力,其在低层视觉任务如图像超分辨率[9]、图像去模糊等[10-15]领域得到了广泛的应用.对于空间均匀去模糊问题,一些研究利用深度神经网络学习一个从模糊图像到模糊核的映射函数[10-11].但是,由于图像模糊核的多样性,采用神经网络估计模糊核的方法效果较差.为了解决复杂的空间非均匀模糊去除,一些研究采用端到端的训练方法,利用深度神经网络学习模糊图像到清晰图像之间的映射关系.Zhang 等[14]采用递归权重设置方法增大网络的感受野,使其能处理较大幅度的运动模糊;Kupyn 等[4,15]先后提出的DeblurGAN、DeblurGAN-v2 利用生成式对抗网络获得更加逼真的清晰图像,但是其图像复原求解模型采用的是交叉熵作为损失函数,容易出现梯度饱和,使梯度消失,造成无效的训练.Nah 等[12]提出利用多尺度特征金字塔训练策略,学习一个由残差块堆叠的深度神经网络,但该网络存在参数量大、实时性不足等问题.Tao 等[13]在此基础上引入尺度间的权值共享,大大减少了参数量,提高了训练效率.Gao 等[16]提出的选择性参数共享跳跃连接去模糊网络(PSS-SNR)由粗到细地提取图像特征,并且使用选择性参数共享及嵌套跳跃连结的方式提高网络的去模糊效果及训练效率.尽管以上基于深度神经网络的去模糊方法取得了更优的去模糊效果,但是网络训练难度较大,且采用了自编码-自解码网络结构.虽然这种网络结构在相同深度下可以增加网络感受野并获取不同层级的图像特征,但是,自编码-自解码网络会对特征图进行下采样,其可保留特征图的结构信息,却丢失了高频信息,导致复原图像细节模糊.
针对以上问题,本文提出了一种高分辨率特征保持去模糊网络.不同于现有的多尺度特征金字塔网络通过串行连接由低-高或由高-低分辨率图像特征图,所设计网络并行连接由高至低各分辨率特征子网络,无需经过由低分辨率到高分辨率的重建过程来恢复高分辨率信息,可以在整个去模糊过程中较好地保持图像的高分辨率信息不丢失.另外,本文通过交叉连接各并行子网络来融合不同分辨率的特征图,从而使得网络可以自适应地选择去模糊特征来复原清晰图像.最后,本网络使用动态卷积神经网络,以非线性方法聚合多个卷积核信息提取图像特征,自适应调节感受野大小,提高网络泛化能力.
1 基本原理
1.1 图像去模糊数学模型
在图像盲去模糊问题中,模糊核未知,需要从退化图像中同时估计出模糊核和清晰图像.图像模糊退化过程在数学上可表示为

式中:y、k、x 和w 分别为模糊图像、模糊核、原始清晰图像以及加性噪声;⊗表示卷积运算.根据式(1)可知,图像去模糊过程即为由观测模糊图像估计清晰图像x 的过程.
1.2 基于卷积神经网络的去模糊模型
近年来,随着深度学习在高层计算机视觉领域的迅猛发展,基于卷积神经网络(convolutional neural network,CNN)的低层视觉如去图像模糊等问题受到广泛关注.目前基于CNN 的去模糊网络一般由编码器和解码器构成.如图1 所示.编码器通过卷积层和池化层提取输入图像的多种特征,然后通过激活函数实现非线性变换进行输出.解码器通过反卷积层和上采样对编码器的输入特征进行映射得到与模糊图像大小相同的清晰图像.

图1 自编码-自解码网络结构Fig.1 Architecture of encoder-decoder
2 高分辨率特征保持去模糊方法
基于CNN 框架,本文设计了一个高分辨率特征保持网络,该网络并行连接由高至低的几个不同分辨率子网络,实现无需通过由低分辨率到高分辨率的特征重建过程来恢复图像.因此,可以在整个去模糊过程中保持高分辨率信息不丢失,很好地保持图像细节特征.另外,本文通过交叉连接各并行子网络来融合不同分辨率特征图,从而使得网络可以自适应地选择去模糊特征来复原清晰图像.最后,本网络使用动态卷积神经网络以非线性方法聚合多个卷积核信息提取图像特征,提出的高分辨率特征保持网络整体结构如图2 所示.网络包含由高至低的几个不同分辨率并行子网络,本文从上到下分别设计1 024×1 024、512×512、256×256 三个不同分辨率的子网络.

图2 整体网络结构Fig.2 Architecture of the Network
2.1 高分辨率特征保持网络
所设计高分辨率特征保持去模糊网络,主要包括3 个不同分辨率的并行子网络,低分辨率子网络的特征图可由高分辨率子网络特征图进行下采样得到,并行子网络结构如图3 所示.

图3 并行子网络结构Fig.3 Architecture of subnet in parallel
其中Nij代表第j 层子网络到第i 层深度的特征信息.3 个子网络特征图的大小分别为 1 024×1 024、512×512、256×256.
浅层卷积可以提取图像的纹理和细节特征,而深层卷积可以提取图像的轮廓和形状.代表高分辨率的浅层网络得到的特征图包含更多的局部信息,代表低分辨率的深层网络得到的特征图包含更多的全局信息.本文采用并行连接由高至低各分辨率特征的子网络,不仅充分利用不同尺度下提取的特征,而且可以在整个去模糊过程中较好地保持图像的高分辨率信息不丢失.此外,为了丰富高分辨率网络的特征信息,本文将并行子网络之间进行交叉连接来融合不同分辨率的特征,从而使得网络可以自适应选择适用于模糊去除的特征来复原清晰图像.并行融合过程如图4 所示.

图4 子网络并行融合结构Fig.4 Architecture of subnet fusion in parallel
网络分为高、中、低3 个分辨率的子网络.其中,由中至高、由低至高分辨率融合均使用1×1 的上采样后接一个1×1 的卷积层.由高至低、由高至中分辨率融合均使用3×3 的卷积,步长分别为2 和4.每个子网络输入特征图记为,其中,Xn表示特征图X 的第n 个通道,H 和W 分别为特征图的高度和宽度.然后对输入特征图进行并行融合和通道加权得到输出特征

式中:kY 表示特征图Y 的第k 个通道输出特征,输出特征图的分辨率与输入特征图分辨率大小相同;a( Xi,k)表示从分辨i 到分辨率k 的特征图分别进行上采样操作或下采样得到的特征图.
对并行融合特征进行图像复原,如图2 所示,图像复原部分包括1 个反卷积层和2 个卷积层. 反卷积层卷积核大小均为3×3,步长为1,2 个卷积层卷积核大小均为1×1,步长分别为2 和1.另外,使用跳跃连接将输入图像特征添加到输出,可使特征信息更灵活地向后传播,并将图像细节从下层传递到顶层,以实现更好的细节重建.最后输出1 280×720 的复原图像.
2.2 动态卷积神经网络
为了获取有效图像的内容特征,本文使用动态卷积神经网络提取图像特征,如图5 所示.其中:S 表示通过全局平均池化生成各个通道特征图的全局统计量;Z 表示通过卷积核为1×1 的卷积层学习所得的特征向量;a、b 表示2 个分支的权重向量.该网络主要包含分离、融合、选择3 个操作.

图5 动态卷积神经网络Fig.5 Selective kernel convolution
(1) 分离.对包含 C ′个通道的输入X,首先在两个分支进行卷积核大小分别为3 核大小和5 核大的不同卷积运算得到两组包含C 个通道、尺寸为 H× W的特征图和,表示为

(2) 融合.为使得神经元能够根据输入的内容动态地调整其感受野.首先,将两个分支的结果采用逐元素相加进行合并得

然后,采用全局平均池化(global average pooling,GP)生成各个通道特征图的全局统计量s,则s 的第c项可以表示为

式中:Uc表示第c 个通道的特征图;Uc(i , j )表示在点(i, j) 的像素值;最后,采用一个卷积核尺寸为1×1的卷积层来学习其映射关系,并通过降维提升效率,即
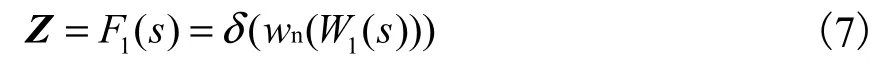
式中:δ 表示激活函数;wn表示权重归一化;W1表示卷积核为1×1 的卷积层的参数,维数减少倍数设置为r.
(3) 选择.采用跨通道的注意力机制来动态地选择来自不同空间尺度的信息,根据学习到的特征向量Z,对不同分支的同一维度的特征向量做归一化指数函数运算,决定卷积层最终输出中该维度采用哪个分支的特征图.可表示为

式中:A 和B 代表两个全连接层;cA 为全连接层A 的第c 行;ac代表a 的第c 项;cB 为全连接层B 的第c行;cb 代表权重向量b 的第c 项.最后,通过对各个不同卷积核分支的特征图赋予权重以得到最终的输出特征图V.

最终卷积层输出为 V= [V1, V2,…, Vc],即经过动态卷积核选择后的输出特征图.
2.3 损失函数
本文在训练网络时采用的损失函数是L2损失(最小平方误差)和感知损失,其中L2损失函数可以表示为

其中对于训练集( Bi, Ii),包含N 个模糊/清晰图像对,θ 为网络参数,F 为高分辨率特征保持卷积神经网络.此外,本文使用感知损失衡量恢复的模糊图像和其对应的清晰图像之间的语义特征差异,表示为


由经验可得,λ =0.01.
3 实验与结果分析
3.1 实验设置及数据集
本文方法基于Pytorch 框架实现,在Ubuntu 环境下使用 NVIDIA 1080Ti GPU 训练去模糊网络.初始学习率设置为0.000 1,150 个阶段训练之后学习率设置为0.000 001,批大小设置为16,采用动量衰减指数β1=0.9、β2=0.999的Adam 优化器进行优化.采用开源GOPRO 数据集,共包含3 214 张模糊图像和3 214 张清晰图像.选取其中的2 103 张清晰图像以及对应的2 103 张模糊图像作为模糊图像的训练集,剩下的1 111 张模糊图像和清晰图像作为测试集进行网络性能的评估.
3.2 实验与结果分析
本文选择与目前的去模糊方法进行对比实验,包括经典去模糊方法:Xu 等[6]提出的基于L0稀疏度量的去模糊算法、Zhang 等[9]提出的基于不同强度先验对图像进行去模糊算法;以及近期基于深度学习的去模糊方法:Nah 等[12]提出的基于多尺度去模糊卷积神经网络、Tao 等[13]提出的尺度循环去模糊网络(scalerecurrent network,SNR)、Kupyn 等[4,15]先后提出的DeblurGAN、DeblurGAN-v2、Gao 等[16]提出的选择性参数共享跳跃连接去模糊网络.采用峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)、参数量及运行时间等客观评价指标对去模糊算法所恢复的图像质量进行评价,各方法实验结果如表1 所示.由表1 可以看到,本文提出的高分辨率特征保持网络去模糊方法在GOPRO 测试集上取得了最高的SSIM 值.PSNR 也取得相对较高值.此外,由表1 可以看出,Xu 等[6]提出的基于L0稀疏度量的去模糊算法需要进行复杂模糊核估计,因此运行时间较长,而且容易出现振铃和纹路.Nah 等[12]提出的基于多尺度去模糊卷积神经网络存在参数量大、实时性差等问题.

表1 在合成数据集上PSNR和SSIM结果Tab.1 Comparison of PSNR and SSIM tested on deblur images
另外,从GOPRO 数据集中选取4 张模糊图像与最新算法进行主观质量评价,各方法去模糊效果如图6 所示.由图6(c)可以看出,SNR[13]当图像模糊严重时去模糊图像存在伪影且细节恢复不足(如图6(c)中的广告牌区域).DeblurGAN-v2[15]去模糊图像得到良好的视觉效果,但细节恢复不足(如图6(d)广告牌文字区域).由图6(e)和(g)可以看出,本文方法与Gao 等[15]提出的PSS-SNR 都得到了良好的去模糊效果.但PSS-SNR 使用多尺度特征金字塔训练策略提高模糊图像处理能力的同时其复杂推理过程导致运行时间较长.如图6(f)所示,Zhang 等[9]使用的传统方法去模糊仍然存在振铃和纹路.如图6(b)和(g)所示,本文使用的高分辨率特征保持网络去模糊较为彻底,能更好地保持图像的特征信息,复原图像细节更为清晰.

图6 GOPRO数据集上实验结果Fig.6 Experimental results of the GOPRO dataset
3.3 消融实验
为验证本文算法各模块的合理性与有效性,本节设计动态卷积神经网络特征提以及子网络分支数量选择消融实验.
为了验证动态卷积神经网络特征提取能力,本文分别使用常规卷积神经网络及动态卷积神经网络提取图像特征,结果如表2 所示.可以看出,使用动态卷积神经网络在PSNR 及SSIM 上均可以得到有效的提升.另外,由图7 可以看出,使用动态卷积神经网络提取图像特征具有更好的去模糊效果.

表2 不同网络特征提取性能对比Tab.2 Comparison of feature extraction performance of different networks

图7 动态卷积神经网络消融实验Fig.7 Ablation results of the selective kernel network
为了验证子网络不同分支数量的效果,分别尝试增加子网络分支数量和减少子网络分支数量.其中两个子网络只得到 28.96 dB 的 PSNR,SSIM =0.928 1. 而使用4 个子网络PSNR 仅提升0.002 dB,处理时间使用1.55 s,相较于使用3 个子网络慢0.35 s. 因此,本文使用3 个子网络.
4 结 语
本文提出了一种基于高分辨率特征保持网络的单幅图像去模糊方法,通过并行子网络之间的交叉连接来融合不同分辨率的特征,从而使得网络可以自适应地选择适合去模糊的特征来复原清晰图像.所提网络在实现去模糊的同时能够较好地保持图像的细节特征.本文方法使用动态卷积神经网络(SK-Net)提取图像特征信息,通过非线性方法聚合多个卷积核信息自适应调节感受野大小,显著提升网络的泛化能力.
猜你喜欢
中国典型病例大全(2022年12期)2022-05-13
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
健康体检与管理(2021年10期)2021-01-03
海外文摘·艺术(2020年22期)2020-11-18
家庭影院技术(2020年2期)2020-03-25
计算机应用(2016年10期)2017-05-12
岁月(2016年5期)2016-08-13
太空探索(2016年3期)2016-07-12
CHIP新电脑(2016年3期)2016-03-10
