
面向OPAC的非个性化图书推荐算法
2021-02-04 07:50邹鼎杰方世敏
现代情报 2021年2期
邹鼎杰 方世敏

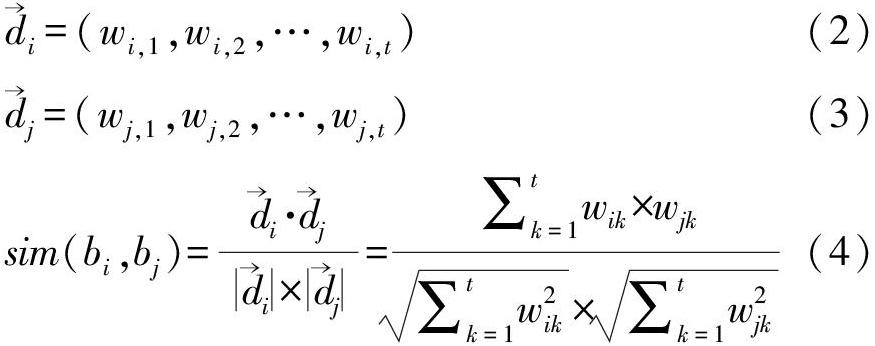

摘 要:[目的/意义]OPAC书目检索系统用户处于非登录状态,系统无法获取用户个人信息,个性化推荐算法难以发挥作用,有必要探索非个性化推荐算法。[方法/过程]首先提出基于图书语义相似度的图书推荐算法,通过构建向量空间模型计算图书语义相似度,向读者推荐与当前浏览图书相似的图书;然后提出基于共借关系的图书推荐算法,向读者推荐借阅了当前浏览图书的读者还借阅过的其他图书;最后讨论了两种算法的融合策略。[结果/结论]选取10本图书作为推荐窗口,在复旦大学图书馆真实借阅数据集上进行实验,推荐成功率为20%。每5名读者中有1名读者能在推荐列表中发现自己后续会借阅的图书。
关键词:OPAC;图书推荐;非个性化推荐;高校图书馆;复旦大学
DOI:10.3969/j.issn.1008-0821.2021.02.013
〔中图分类号〕G251 〔文献标识码〕A 〔文章编号〕1008-0821(2021)02-0125-07
Abstract:[Purpose/Significance]Non-personalized Book Recommendation Algorithm is necessary for OPAC book retrieval system,because users are always in the state of logging out.It is impossible to access user information,without which personalized recommendation algorithm cannot work efficiently.[Method/Process]Firstly,book recommendation algorithm based on semantic similarity was designed with vector space model recommending books similar to book browsing.Secondly,algorithm based on relation of same readers was introduced,which recommended books borrowed by readers who also borrowed the book that the user was browsing.Lastly,methods to merge two algorithm were discussed.[Results/Conclusion]With ten recommending books,the result of experiment on Fudan University library's book borrowed datasets showed that success rate of algorithm was 20%,such that one in five readers could find at least one books that he would borrow in recommending book list.
Key words:OPAC;book algorithm;non-personalized book recommendation;university library
高等学校图书馆是学校的文献信息资源中心,主要任务是建设全校的文献信息资源体系和建立健全全校的文献信息服务体系[1]。据教育部高等学校图书情报工作指导委员会统计[2],我国高校图书馆馆均纸质文献资源购置费为每年200余万元,中山大学图书馆等高校每年采购纸质图书的经费高达1亿元。根据各高校图书馆官网介绍,中山大学图书馆纸质馆藏总量达685.14万册,复旦大学图书馆收藏纸本、报纸合订本资源约546.4万册,浙江大学图书馆实体馆藏总量达655.8万册。面对海量的馆藏图书,如何让读者发现并利用这些图书,让“每本书有其读者”是图书馆在建设学校文献信息服务体系的时候需要考虑的关键问题。
OPAC(Online Public Access Catalogue,联机公共检索目录)是图书与读者之间的桥梁。对于采取闭架借阅制度的书库,OPAC系统是图书与读者之间的唯一桥梁。OPAC系统的主要职能是书目检索,读者在明确自己所需图书主题或者知道所需图书标题、作者、出版社等检索点时,通过输入检索表达式查阅图书。检索只能满足读者显性的、意识到的、能够用检索式表达的图书需求,无法满足读者隐性的、潜在的、尚未用检索式表达的图书需求。大量所需图书因为无法出现在检索结果中不被读者知晓,无法发挥应用作用。图书推荐可以根据读者的检索、浏览等行为数据以及图书馆的图书借阅数据“猜测”读者可能需要的图书,弥补检索带来的不足。
1 相关研究评述
根据推荐书目是针对1位读者还是多位读者,图书推荐分为个性化图书推荐和非个性化图书推荐。个性化图书推荐根据读者借阅历史等个人信息生成书单,不同读者收到的推荐书单并不相同,能够做到“千人千面”。非个性化推荐通常面向特定用戶群体提供一份相同的书单。
非个性化图书推荐由来已久。《论语》中就有孔子向弟子推荐《诗经》的记载[3]。梁启超编《西学书目表》,向公众推荐300余种图书,影响广泛。这种依托领域专家或者图书馆馆员生成的阅读书单至今仍然是重要的图书推荐手段,一般称作书目推荐[4]。除了依靠人工推荐图书,依托计算机技术生成书单也逐渐受到关注。黎邦群[5]受到信息检索中查询推荐的启发,提出了基于检索行为的非个性化图书推荐算法,认为通过用户的检索历史记录可以提供更有效的图书推荐,是非个性化图书推荐算法的一次不错尝试。明均仁等[6]提出一种推荐书目自动生成方法,通过收集豆瓣读书、京东图书、卓越亚马逊等网站的书评数据,经过数据预处理、资源整合、书单生成、人工筛选等步骤自动生成书单,使推荐书目更加高效且拥有群体智慧。刘丽帆等[7]从形式、效用、内容等维度提出了一种高校图书热门TOP图书的评价模型,用于向读者提供一份热门TOP书单。在非图书领域,崔春生等[8]提出了一种基于Vague值的非个性化产品推荐策略,Chakraborty A等[9]针对纽约时报、CNN等新闻网站用户处于非登录状态问题,围绕时效性、新颖性和多样性3个目标提出了新闻的非个性化推荐方法。相对于个性化推荐,依托计算机技术生成书单的非个性化推荐理论研究比较稀缺,缺乏对图书馆中的借阅数据和图书的著录数据的挖掘和利用。实践层面,图书馆OPAC系统的非个性化推荐却比较普遍。李民等[10]通过访问国内116所“211工程”院校的图书馆网站,发现100%的图书馆都提供非个性化推荐服务,主要有新书通告、热门检索、热门借阅、借阅排行等,这些推荐通常以一个简单页面将全部信息呈现给所有用户,不够灵活、缺乏智能。郭婧婧等[11]发现城市图书馆推荐系统的非个性化推荐主要有两类:一类是基于统计分析的推荐方法,如借阅排行、热门检索、热门借阅;另一类是基于手工的推荐方法,比如新生推荐、特色馆藏推荐等;但均存在智能化程度不高的问题,与李民等[10]的调查结果相一致。
实际上,个性化图书推荐的智能化程度更高,也是当前研究热点。只是个性化推荐算法要求用户处于“登录”状态以获取用户的借阅历史、性别、年级等个人信息,而OPAC系统用户通常处于“游客”状态,个人信息难以被系统获取,个性化推荐算法难以发挥作用。个性化推荐算法虽然无法直接用于非个性化推荐,但是其中的思想可以指导非个性化算法的设计。本文通过对个性化推荐算法的改进,提出了用户非登录状态下的非个性化推荐算法。
2 算法设计
图书推荐算法的目的是从大量图书中过滤掉用户不需要的图书,筛选出用户需要的图书。如果不引入额外信息、根据等可能假设,用户对每本图书的需要程度是相同的,在海量图书中发现用户所需图书的概率是1/N,其中N为图书总数量,通常在几十万至几百万不等,这是一个很小的概率。推荐算法通过引入额外信息消除不确定性,增加用户所需图书被推荐的概率。引入的额外信息包括以下3种:①图书的内容特征,包括标题、作者、出版社、主题词、分类号等,这些特征是读者选取图书的依据;②图书借阅历史,即所有读者在过去借阅图书的历史记录。借阅历史是协同过滤图书推荐算法依赖的信息,该算法认为拥有相似借阅偏好的读者在未来也将借阅相似图书,以此作为图书推荐依据;③待推荐读者的个人信息,既包括读者的年级、专业等属性信息,也包括读者借阅图书的历史记录。在非个性化推荐算法中,系统无法获取第3种信息,但依然能获取第1和第2两种信息。利用第1种信息发现读者所需图书的算法通常称作基于内容的推荐算法,本文将其称作基于语义相似度的推荐算法,该算法向读者推荐与当前浏览图书语义上最相近的k本图书。利用第2种信息的推荐算法通常称作协同过滤算法,本文将其称作基于共借关系的推荐算法,该算法向读者推荐借阅了当前浏览图书的读者都还借阅了其他k本图书。
2.1 基于语义相似度的非个性化推荐
语义是指文字载体承载的意义,意义是人们对世界的认识。意义通常在表达时赋予,在阅读时理解。算法可以在特定维度上“理解”文字载体上的意义,典型的做法有自上而下地构建本体和自下而上地提取特征两种。前者对领域专家的依赖程度较大,后者从海量数据中提取的統计特征。本文采用后一种思路,利用向量模型计算图书的语义相似度。
计算语义相似度之前有两个关键步骤:特征词的选取和特征词权重的确定。OPAC系统中的图书是纸质图书。纸质图书的特点是只有标题、作者、出版社等属性数据是电子化的,能够作为特征词的来源。纸质图书的内容一般不会电子化,难以成为特征词来源。相对于电子书、网页等载体,纸质图书的特征词来源稀缺。因此,纸质图书的特征词提取应当使用细粒度的分词技术以提升图书召回率。选用TF-IDF作为特征词权重,特征词i在图书j中的权重计算方法如式(1)所示,其中N是图书馆的馆藏图书种数,ni是包含有特征词i的图书种数,log2N/ni是反比文档频率(Inverse Document Frequency,IDF)的标准计算公式;fij是特征词i在图书j中的词频(Term Frequency,TF),为了与IDF值具有可比性,对频率fij做了取以2为底的对数处理,并通过加1避免出现值为0的情况。没有在图书j中出现过的特征词权值为0。
假设总共从馆藏图书中提取出t个特征词,利用t维向量表示图书的语义特征。图书bi和bj的向量空间分别如式(2)和式(3)所示。利用向量间的余弦夹角表示图书之间的语义相似度,计算方法如式(4)所示。
图书馆藏有图书规模较大,图书的特征词数量t是一个较大数值。以复旦大学图书馆5年间的借阅数据集为例,总共从数据集中提取40余万个特征词;但由于纸质图书特征词来源的稀疏性,一本图书的特征词通常不超过10个。如果直接使用向量存储特征词,空间利用率为1/40 000,利用率极低。该借阅数据集仅包含了该校图书馆不到1/10的图书,如果要表示该馆所有图书,特征向量会更长,空间利用率会更低。改用哈希表分别存储每本书的特征值权值将极大地节省存储空间。为每本图书创建一个哈希表,表的键是图书包含的特征词,表的值是对应特征词的权值,没有在图书中出现过的特征词的权值为零,无需存储。图书bi与bj之间语义相似度计算方法如式(5)所示,式中C是图书b的特征词集合,H是图书b的特征词哈希表,H[c]是特征词c对应的特征权值。
为了给一本图书寻找与其最邻近的k本图书,需要计算这本图书与其余所有图书的语义距离,然后根据距离排序,找出排名前k的图书。算法为每本图书寻找与其最邻近的k本图书。如果图书馆有N本图书,需要进行C2N次距离计算,计算时间复杂度为O(N2)。高校图书馆藏有图书规模较大,难以接受该计算复杂度。以拥有100万藏书的图书馆为例,需要进行1 000亿次距离计算。即便每次距离计算耗时为1微秒,所需耗时将达11天。大多数高校图书馆藏书都在100万以上。好消息是图书馆中绝大多数图书之间的语义相似度是0,即图书bi的特征词集合Ci与图书bj的特征词集合Cj的交集为空,Ci∩Cj=。利用索引技术找出与图书b距离非0的所有图书集合Cb,在Cb中寻找与图书bi最邻近的k本书。由于Cb的规模远小于整个图书馆的图书数量,因此可以极大地降低计算复杂度,使基于语义相似度的非个性化推荐算法变得可行。使用哈希表MAP表示该索引,其中的键是特征词c,对应的哈希值MAP[c]是包含有该特征词的所有图书集合B。图1是在哈希表中查找与图书b距离非零图书集合Cb的算法。关键步骤为(1)~(3),不断根据特征词查找包含有该词的图书并添加到集合Cb。图书b自身也会被查询并添加到集合Cb中,因此需要在步骤(4)将b从Cb中移除。
搜索到与待推荐图书b距离非零的图书集合Cb后,根据式(5)计算图书b与Cb中每一本图书的距离,排序后取相似度最高的前k本图书,即为向用户推荐的图书。基于语义相似度的非个性化推荐算法可以视作一种查询扩展技术,即通过读者对图书的点击信息帮助读者重构查询式,并将查询排名前k的图书展现给读者。该思想与文献[5]有相似之处。
2.2 基于共借关系的非个性化推荐
共借关系是指图书bi与bj共同被若干名读者借阅的关系,这两本书或许在语义上有较高的相似度,也有可能在语义上体现不出相似度,是由于其他因素被共同借阅。基于共借关系的推荐算法被认为比基于语义的推荐算法更能帮助读者发现新颖图书。协同过滤算法利用图书之间的共借关系向读者推荐图书,这种推荐算法无法直接应用于非个性化推荐,需要做相应改进。
在协同过滤算法中,计算两本图书邻近关系的方法主要有余弦相似度和皮尔逊相似度,这两种相似度计算方法无法直接适用于共借读者人数较少的情况。由于两种计算方法原理类似,以余弦相似度为例说明。余弦相似度的计算方法如式(6)所示,Ri是图书bi的读者集合,Rj是图书bj的读者集合,daysrb是用户r借阅图书b的天数。如果两本图书只有1名读者借阅,这两本图书的余弦相似度为1,即最大值;如果两本图书本有两名读者借阅,仅当这两名读者的借阅天数相等时,余弦相似度才等于1,否则余弦相似度将小于1。也就是说,两本图书共被借阅的人数为1时,它们之间的相似度最大;随着这两本图书共借人数的增加,这两本图书的相似度会逐渐下降。该算法不符合常识。实际上,余弦相似度和皮尔逊相似度仅在图书的共借人数较多且相等时有比较价值。决定图书之间共借相似度的首要因素是共借读者人数n。因此将图书共借关系强度定义为式(7),即共借人数与余弦相似度之和。共借人数是整数,余弦相似度的值域区间为(0,1]。从数值上比较图书之间共借关系强度时,共借读者人数是首要因素,余弦相似度是次因素。
基于共借关系的推荐算法与基于语义相似度的推荐算法面临类似问题——需要计算每本图书之间的距离,由此带来的时间复杂度已经在上一节中论述,在此不再赘述。类似地,图书馆中拥有共借关系的图书并不多,因此可以直接提取拥有共借关系的图书而忽略没有共借关系的图书。高校图书馆的读者借阅记录通常保存在数据库中,可以利用数据库的连接查询技术快速获取拥有共借关系的图书。在查询到与图书b具有共借关系的图书集合以后,根据式(7)计算图书之间的共借关系距离,排序后取前k本图书推荐给读者。
2.3 融合语义相似度和共借关系的非个性化推荐
基于语义相似度的推荐算法与基于共借关系的推荐算法有各自的优势,也有各自的劣势。基于语义相似度的推荐算法通常向用戶推荐主题相近的图书,这些图书或者在标题上具有某种相似度,或者来自同一作者,或者来自同一出版社,或者兼而有之。对于正在进行主题阅读的读者,语义推荐算法能够给他们带来较大帮助,因为推荐算法能够满足他们发现同一主题下大量图书的需求。语义推荐算法的弊端也很明显,这些主题相近的图书通常在相邻排架甚至同一排架,即便没有推荐系统,读者也可以在排架上方便地找到这些图书。基于共借关系的推荐算法是在向读者回答“读过这本书的人还读过哪些书?”,推荐的图书在语义上可能相关,也可能无关。基于共借关系的算法更能够给读者带来新颖性,能够帮助读者发现意想不到的图书,通常认为基于共借关系的推荐算法优于基于语义相似度的推荐算法。但是基于共借关系的算法存在一个弊端——冷启动问题,对于借阅率较低的图书,算法甚至无法找到足够数量的推荐图书;对于从未被借阅过的图书,算法无法根据共借关系作出推荐。两种算法的融合能发挥各自优势,带来更好的推荐效果。本文提出了平等融合和补充融合两种策略,前者在把两种推荐算法视作同等地位,后者以基于共借关系的推荐算法为主,基于语义相似度的推荐算法作为补充,解决冷启动问题。
平等融合算法认为通过语义关系和共借关系获得的图书具有同等重要的推荐价值,首选同时被两种算法推荐的图书,然后根据排名先后选取只被一种算法推荐的图书。同时被两种算法推荐的图书根据在各自推荐列表中的排名求和后重新排名。通过例子说明选取和排序的规则。假设推荐5本图书,两种算法给出的推荐图书分别是a、b、c、d、e和g、c、e、b、f。同等融合算法首选同时出现在两个列表的图书b、c、e,这3本图书在两个列表的排名之和分别是6、5、8,因此排序应当是c、b、e。然后从余下图书中选取排名靠前的a和g构成5本推荐图书。
补充融合算法认为共借关系推荐的图书最重要,语义算法推荐的图书在共借算法无法发现足够图书时作为补充。假设推荐窗口为k本,如果共借算法能够发现k本以上图书,则使用该算法发现的前k本图书;如果共借算法只发现j(j 3 实验结果及其分析 评估推荐算法的常用方法有离线评估、用户调查和在线评估,本研究根据实际情况选择了复旦大学图书馆的真实外借数据集进行离线评估。 3.1 数据集 测试数据为复旦大学图书馆在2013—2017年间的所有图书借阅记录,该数据集由2019年首届“慧源共享”上海高校开放数据创新研究大赛主办方提供,包含有该高校5万余名读者在2013—2017年间对大约40万种图书的160余万条借阅记录。由于高等院校的教学活动以学年为单位进行,为了更接近高校图书馆图书推荐的真实情况,将数据集分为2013—2014年、2014—2015年、2015—2016年和2016—2017年4个学年,以前3个学年的借阅数据作为基于共借关系的非个性化推荐算法的训练集,以2016—2017学年的借阅数据作为测试集。基于语义的推荐算法以所有图书作为训练集,以2016—2017学年的借阅数据作为测试集。 3.2 评估方法 选取最终效用作为评估标准,即推荐窗口的图书是否包含用户后续借阅图书。以2016—2017学年借阅两本以上图书的读者作为测试标准,假设读者借阅的第1本图书在OPAC系统中检索过,且读者浏览了这本书的详细页面。在这本书的详细页面中,算法将推荐10本与第1本图书相关的图书,如果推荐窗口中有用户后续借阅的图书,则认为是一次成功的推荐;如果窗口中任何一本图书都没有被读者借阅过,则认为是一次失败的推荐。举例说明,读者r在2016—2017学年间按照时间先后顺序借阅3本图书b1、b2、b3,假设读者r借阅图书b1时在OPAC系统上检索并浏览了该书的详情页面,算法将在页面底部根据图书b1推荐10本图书,如果r后续借阅的图书b2或b3出现在这10本图书之中,则认为算法是一次成功的推荐;如果后续任何一本图书均没有出现在推荐范围内,则认为是一次失败的推荐。以推荐成功率作为评估效果的指标,计算方法是成功推荐次数除以总推荐次数。
3.3 實验结果
3.3.1 算法的成功率
4种推荐算法的成功率如图2所示。基于共借关系的推荐效果略好于基于语义相似度的推荐效果。融合以后的推荐效果要好于单一推荐算法的效果,但提升的程度并不十分明显。把语义推荐结果和共借推荐结果视作同等重要的平等融合的效果最好,以共借关系为主,语义关系为辅的补充融合算法虽然也能起到一定改进作用,但效果不如前者。从实用的角度,每5名读者中有1名读者能够在推荐列表中发现他这一学年会借阅的图书,是一个可以让读者接受的推荐效果。
3.3.2 推荐窗口大小对成功率的影响
推荐窗口大小是指最多允许向读者推荐的图书数量。图3中,横坐标为推荐窗口大小,纵坐标是推荐成功率。图中可以看出,推荐窗口大小与推荐成功率表现为成类似对数函数的曲线关系,在推荐窗口较小时,推荐成功率随窗口的增大而迅速增大;在窗口较大时,推荐成功率的增幅趋于平缓。这说明盲目增大窗口并不是总能带来更好的效果,过大的推荐窗口反而会带来糟糕的用户体验。
3.3.3 推荐算法对不同受众的影响
高等院校图书馆的读者主要有本科生、硕士生、博士生和教职员工,他们的借阅习惯存在一定差异,因此体验到的最终效果也存在一定差异。整体来看,推荐算法在本科生中的效果最好,在教职员工中的效果最差,这与训练样本中本科生远多于教职员工有关,数据驱动的算法更有利于大多数群体。对于本科生人群,基于共借关系的推荐算法成功率远高于基于语义推荐算法的成功率,说明本科生读者的共借关系比较密切。本科生的主要任务是学习公共课和专业课,所学内容比较相近,因此共借关系比较密切。随着学历层次的增加,基于语义推荐算法的成功率逐渐增加,而基于共借关系的推荐算法成功率逐渐下降。原因是学历越高的读者,他们之间的需求差异越大,共借关系偏弱。而他们研究的书目普遍处于同一主题,因此基于语义推荐的算法更有效。通过上述分析,可以清晰地看到同一个算法面向不同受众的弊端,在个性化推荐算法中,这些弊端将得到较好地解决。
4 结 语
针对OPAC系统用户普遍处于非登录状态,个性化推荐算法难以发挥效用的问题,本文分别从语义相似度和共借关系两个角度提出了两种图书非个性化推荐算法。通过构建词向量模型计算图书之间的语义相似度,提出基于语义相似度的算法,推荐成功率为15.5%;基于共借关系的推荐成功率为17.2%。两种算法有各自的优势也有各自的缺点,提出了两种算法融合策略:一种是基于平等关系的融合策略,该策略把两种算法推荐的结果视作同等重要,推荐成功率为22.1%;另一种是以共借关系为主体以语义关系为补充的融合算法,推荐成功率为19.1%。另外,本文还讨论了在大规模图书和读者条件下算法的实现问题,通过引入哈希表有效节省了向量空间模型带来的存储开销,通过引入索引技术解决了距离计算量的问题。
需要说明的是,成功率并非评估推荐算法的标准,多样性、惊喜度等在推荐算法中同样重要。在实践中,推荐算法的选择还应当与图书馆的服务宗旨和服务理念相一致。因此,本文提出的4种推荐算法没有绝对的优劣之分,只有在不同场景下合适还是不合适的区别。
参考文献
[1]中华人民共和国教育部.普通高等学校图书馆规程[EB/OL].http://www.scal.edu.cn/gczn/sygc,2020-02-20.
[2]教育部高等学校图书情报工作指导委员会秘书处.2018年高校图书馆发展报告[EB/OL].http://www.scal.edu.cn/sites/default/files/attachment/tjpg/2018年中国高校图书馆发展报告.pdf,2020-02-20.
[3]王心裁.文化冲突交融中的导读目录[J].图书情报知识,1998,(4):2-6.
[4]蒋小峰.近十年来我国图书馆推荐书目服务研究综述[J].图书馆理论与实践,2017,(9):6-11,20.
[5]黎邦群.基于检索行为的非个性化图书推荐[J].图书馆杂志,2013,32(8):36-41.
[6]明均仁,周知,陈雪.阅读推广推荐书目的自动生成研究[J].图书馆论坛,2017,37(10):94-99,113.
[7]刘丽帆,朱紫阳.基于“全评价”理论的高校图书馆热门TOP图书推荐模型研究[J].图书情报工作,2018,62(7):47-53.
[8]崔春生,苏白云.基于Vague值的非个性化产品推荐研究[J].计算机工程与应用,2012,48(13):63-66.
[9]Chakraborty A,Ghosh S,Ganguly N.Optimizing the Recency-Relevance-Diversity Trade-offs in Non-personalized News Recommendations[J].Information Retrieval Journal,2019,22(5):447-475.
[10]李民,王颖纯,刘燕权.“211工程”高校图书馆馆藏资源推荐系统调查探析[J].图书情报工作,2016,60(9):55-60.
[11]郭婧婧,王颖纯,刘燕权.城市图书馆馆藏资源推荐系统调查分析[J].图书馆学研究,2019,(4):76-82,101.
(责任编辑:郭沫含)
猜你喜欢
阅读(中年级)(2022年10期)2022-11-08
中国临床医学(2019年5期)2019-10-29
中国临床医学(2018年6期)2018-12-29
中国临床医学(2018年5期)2018-11-15
法语学习(2015年5期)2015-04-17
数学教学(2013年7期)2013-08-22
