
基于结构分解的端到端水下视频压缩方法
2021-02-14 06:24李擎
电视技术 2021年12期
李 擎
(福州大学,福建 福州 350000)
0 引 言
海洋和人类的生活息息相关,紧密相连。海洋占全球面积的71%,体积高达14亿立方公里,规模比陆地大。海洋是现今各个国家新的发展空间。海洋除了蕴含丰富的矿物、生物、气体等资源外,其辽阔的海域还是交通的要道、边土防御的天然屏障,可以说,海洋开发潜力巨大,在现今陆上资源日益匮乏的状况下,海洋资源已经愈发成为全球新的经济与科技发展的新动力源[1]。
水下视频信号的压缩与传输在水下环境具有极其广泛的应用,如沿海军事和战术多媒体监测、海底和海上资源的勘探、石油管道和桥梁检查、海底到海界面地质的生物过程和农业渔业养殖方面的视频监测,这些都需要实时水下视频资源来协助采集和分类。但是,由于水下频谱的限制和声学信道的易误差特性,在现今水下恶劣复杂的带宽环境下实现大量高效和可靠的视频数据传输是一个巨大的挑战。在水下环境,射频波会被吸收几十米及以上的距离,而光波需要较为狭窄的激光束,在水下环境会遭受光散射和海浪不规则运动[2]。声波在水下环境具有良好的传播特性,由于光波和电磁波无法在水中很好地发挥作用,在某些水下场景中,声学是能够进行水下无线通信的技术[3]。声波作为最合适的传输介质,可以传播几十公里,使得声波的水下通信信道非常动态,但是容易衰落,光谱有限,通带带宽受限,并受到非高斯噪声的影响,传输信道速度大概在100~300 kb·s-1。传统的视频压缩传输技术受到水下较差的光照条件、水造成的模糊、视频帧遮挡和抖动、不同地质环境之间形状和纹理的相似性、不规则移动的水生动植物和背景的混乱方面的挑战,严重阻碍了传统技术在现实水下场景中的应用[4-5]。
由于水下环境恶劣复杂,可见度低等因素,人类自身无法在水下自由开展水下活动以获取有效资源[6],因此水下活动的正常开展需要借助水下无人机(Autonomous Underwater Vehicle,AUV)和图像视频拍摄设备来进行,水下图像及视频压缩传输的相关技术对于水下无人机(AUV)获取周围水环境和有效资源信息起着重要的作用[7]。水下视频的信息便于观察,所含内容丰富,便于人类观察和获取水下环境中的有效信息,做到对水下各类资源和有效信息的高效监控、利用和及时应对。水下视频传输有着时延长、波动较大等问题,如何在有限的带宽和复杂的环境下提高传输效率,成为水下视频传输的关键问题。
近年来,水下视频拍摄设备不断进步,在水下恶劣的传输带宽条件下,视频清晰度的提高使得传输整幅高清晰的图像可能会存在一定的延迟,难以保证实时性。因此必须将传统视频压缩传输技术和水下恶劣的带宽条件和复杂情况相结合分析,来保证水下视频的有效压缩传输。由于水下视频传输的困难,感兴趣区域和目标物的提取在水下视频传输中起着重要作用。为了解决水下视频传输过程中的问题,需要将传统视频传输技术与水下情况相结合来考虑。文献[8]为了适应水下环境低带宽的情况,基于小波变换提出了一种利用运动估计和运动补偿来去除压缩传输过程中水下视频中冗余的方法。NJIKI-NYA PATRICK等人[9]将视频帧分为纹理区域和非纹理区域,非纹理区域采用传统的基于预测和变换的编码方式编码,而对纹理区域,则并不直接编码,而是提取出相应的纹理参数作为边信息编码传输,在解码端根据解码得到的纹理参数进行纹理合成重建,在保证解码视频帧主观质量的同时,大幅降低了码率。JONGHYUN AHN等人[10]使用水下自主航行器(AUV)传输水下视频时对视频中感兴趣区域和目标进行选择并且对水下视频中视频帧图像颜色衰减和光照不均匀等问题进行了优化。MEHDI RAHMATI等人[11]采用可伸缩编码和多个水下航行器(AUV)的网络内共享来传输重建感兴趣区域的水下视频帧,克服了光波散射和海浪运动等困难。这些方法都能比较好地传输重建水下视频的内容,但是在目标物和感兴趣区域的提取和加强上还有所不足。
为了解决目前还存在的技术问题,弥补当前的不足,进一步提高水下视频的传输性能,本文基于水下视频帧中关注度和感兴趣区域的提取,利用一种基于结构分解的端到端水下视频压缩传输方法使传输过程中感兴趣部分图像的失真尽量小,压缩传输所得到的视频中的内容能够更加符合人类视觉感官。利用水上高计算能力的计算机,可以实现对传输视频较好的重建效果,可以实现更好的实时传输。
1 水下视频压缩方案框架设计
本文算法包括编码端的结构分解和解码端的重构合成。在编码框架中,输入的水下视频被分解成基本轮廓和细节纹理两个部分,基本轮廓是视频帧图片中感兴趣区域和目标物的大致轮廓和边缘部分,细节纹理则是色彩和图片的细节纹理。对输入的水下视频帧分解的两部分分别进行增强处理后,进行端到端的视频帧传输,最终在解码端合成,生成重建后的水下视频帧图像。算法框架如图1所示。结构分解后,两部分内容分别通过端到端的水下视频压缩学习网络进行深度学习压缩传输,由于压缩后传输的视频帧图片大小大大减小,并且分成了两个结构部分分别进行传输,本文的方法只需要传输高质量的感兴趣区域和目标部分,其他背景区域进行低质量传输,因此可以降低传输所需码率,克服了水下带宽条件苛刻的情况。重建后的水下视频帧由于经过传输前的增强处理,重建结果图片在光照颜色和清晰度方面更能显现出感兴趣区域和目标物。算法流程包含基于结构分解的水下视频帧增强预处理和端到端的水下视频压缩学习网络两部分方法,将在下面章节进行介绍。
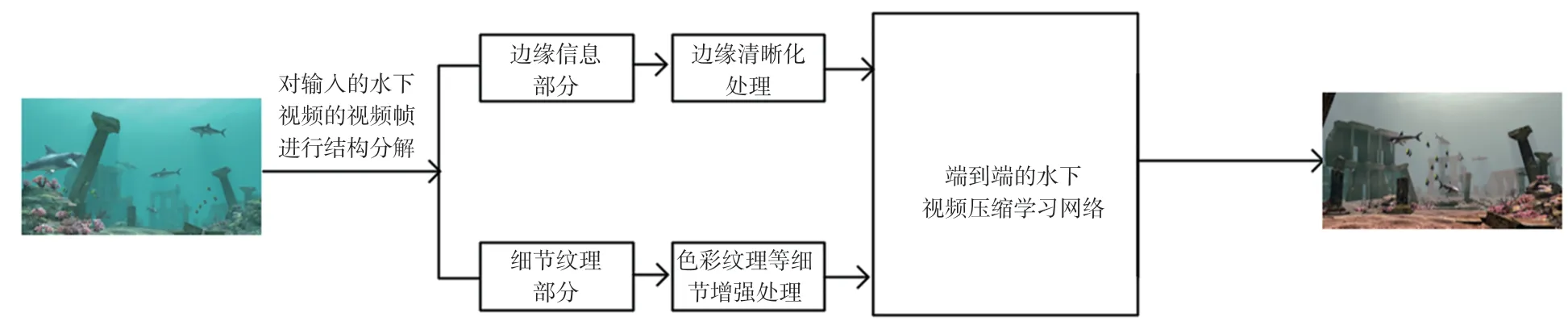
图1 算法框架整体流程
2 基于结构分解的端到端水下视频压缩传输方法
由于水下环境条件恶劣,水下视频的传输会因为带宽较低和时延长等原因受阻,水下视频帧往往会因为水下光照条件差、杂质较多等诸多因素产生噪声和伪影等干扰。光在水下环境中容易被吸收并发生散射,使得图像色调偏向蓝绿色。水中漂浮的杂质粒子也会使得光波在水下发生前向或背景散射,使得图像往往出现视觉失真,如低对比度、颜色失真和雾霾样效应[12-13],使得传输的水下视频帧内容中感兴趣区域和目标模糊,不容易被识别,因此重建还原效果欠佳,无法得到真实清晰的水下视频帧。由于水下环境造成图像质量差,传统的传输方法重建的水下视频帧与真实情况的视频帧可能偏差较大,造成压缩传输后的视频质量欠佳。为了改善水下视频压缩传输质量,本文对输入的水下视频进行结构分解增强处理,分别传输分解后的两部分内容,有利于降低传输视频所需码率;增强处理后进行压缩传输,可以使得重建后的水下视频帧在视觉感官效果上得到提升。
本文的方法将输入的水下视频帧视为I(x,y),经过结构分解[14]后的高频边缘轮廓部分和低频细节纹理色彩部分分别视为IH(x,y)和IL(x,y)。
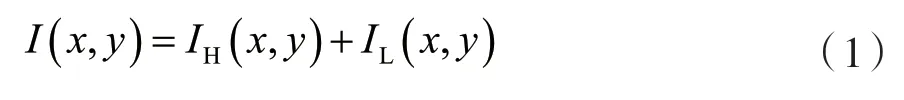
经过分别增强处理后[14]的两部分组成分别表示为JH(x,y)和JL(x,y),则上式转换成
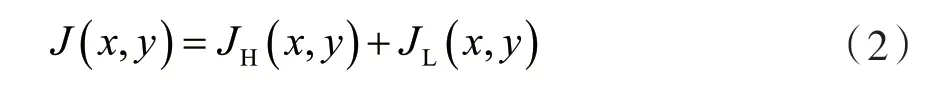
而在水下光学成像方面,JAFFE[15]和MCGLAMARY[16]提出的三分量模型中,相机拍摄的总能量ET(x,y)的定义为:
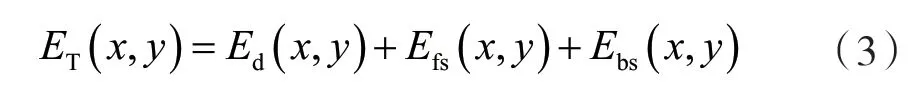
式中:Ed(x,y),Efs(x,y)、Ebs(x,y)分别表示直向亮度分量、前向散射分量、背景散射分量。
由于水下场景和摄像机的距离通常较大,可以忽略前向散射分量的影响,然后考虑直接亮度分量和背景散射分量。因此,式(3)得以简化为:

式中:Iλ表示捕捉到的水下视频帧图片,Tλ表示传输图,Bλ表示图片的全局背景光。由此,将增强后的式(4)代入式(1)、(2),就可以得到:
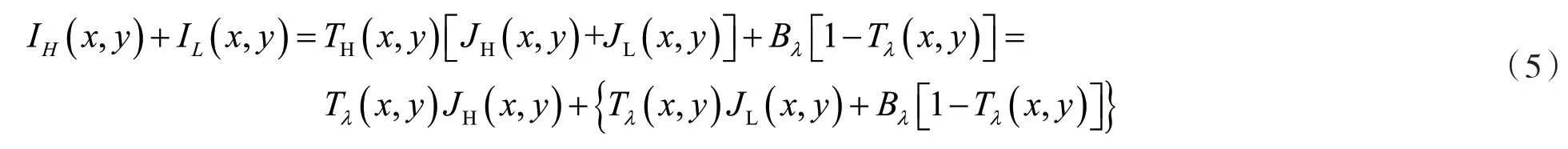
之后增强后的式(5)就可以表示为以下两部分:
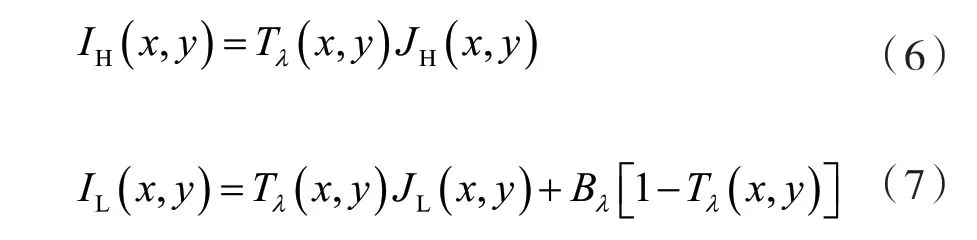
式(6)、式(7)分别代表高频和低频分量的物理模型。
将两部分增强处理后经过端到端的压缩学习网络传输,最后生成接近真实情况的水下图像J(x,y)。
端到端的视频压缩学习方法由视频编码标准[17-18]驱动,利用了运动补偿来减少空间冗余度,两个压缩网络分别对运动和残余信息进行压缩。总体网络框架如图2所示,各个模块及其功能如下。
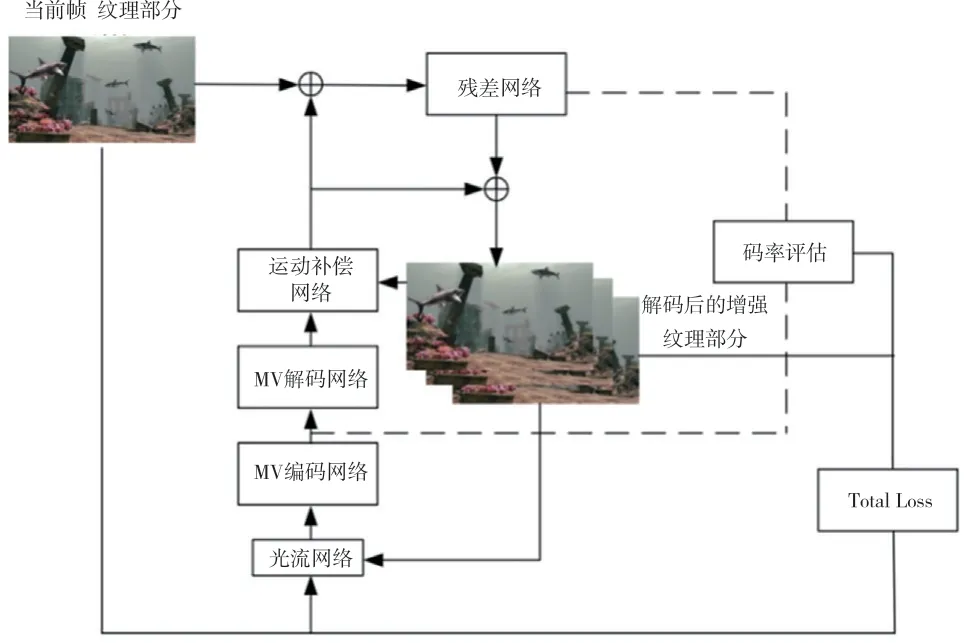
图2 压缩学习传输网络框架
2.1 运动估计
利用光流法[19]来对当前视频帧以及当前帧的前一帧进行运动估计,光流法较大的接受域有利于视频压缩网络有效地处理较大的运动。视频压缩框架的光流网络是一个5级的金字塔网络,每一层包含5个卷积层,角形大小为7×7,每层所包含的滤波器数量分别为32、64、32、16、2。
2.2 运动压缩
运动估计后,本文的方法采用自动编码器[20-21]来对其进行压缩,编码器含有4个卷积层和与之对应的上采样,前3个卷积层采用逆GDN[20]激活函数,滤波器的大小设置为3×3。运动压缩网络中,解码器最后一层和其他层的滤波器数分别为2、128,以此来重建出运动向量,实现编解码用于运动压缩。由于使用了因子分解的嫡模型[20],本文的方法对输入和输出图片的分辨率要求较低,只需要输入16的倍数的高度和宽度的图片即可。并且,本文使用的因子分解的嫡模型替换了原先的超先验模型,但是在性能上并没有下降。
2.3 运动补偿和残差压缩
根据文献[20]所述,参考帧先被压缩运动处理,运动补偿网络以参考帧、被压缩运动处理后的参考帧以及压缩运动作为输入,来生成对应的运动补偿帧,本文的框架则符合文献[20]中的架构。所有层的滤波器都被设置成3×3的大小,最后一层以及其他层的滤波器数量分别为3和64,并都有步幅为2的上下采样。运动补偿后,可以通过作补偿参考帧与当前原始帧的差来得到残差。在端到端视频压缩框架中,本文运用与运动压缩相同的方法来进行残差压缩,唯一不同的是,因为残差比运动包含更多的信息,在运动补偿中,将滤波器的大小设置为3×3,而在残差压缩中,将滤波器大小设置为5×5,这样可以容纳产生的较大的比特率,并且更大的滤波器提高了自动编码器的性能。最后,将残差添加到补偿后的参考帧中,传输后增强的边缘部分和纹理细节部分,经过卷积和计算后得到最终重建的水下视频帧。
3 实验与性能
基于结构分解的水下视频帧增强网络,使用Matlab和PyTorch平台进行实验训练,数据集采用真实描述水下情况的水下视频数据集shark、UMD RAM Qudo Uuderwater Vision以及Brackish数据集来进行,数据集包含大量的1 920×1 088分辨率的水下鱼类、人及其他物品的视频帧。首先利用Matlab将数据集中分解得到的视频帧分解成结构分量增强,而后在PyTorch平台上对两个结构分量增强后的部分进行压缩学习和传输后合成最终的视频帧。增强处理后的视频帧分为7个视频帧一组进行训练,测试集所用部分不在训练集中。
实验采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)来评估压缩传输后重建的水下视频帧的质量,bpp代表每个像素的比特,重建后的结果与H.264和H.265的结果进行比较,如图3所示。结果表明,本文的方法在传输水下视频的时候性能优于H.264的结果,略差于H.265,但是在bpp较高的情况下性能接近。
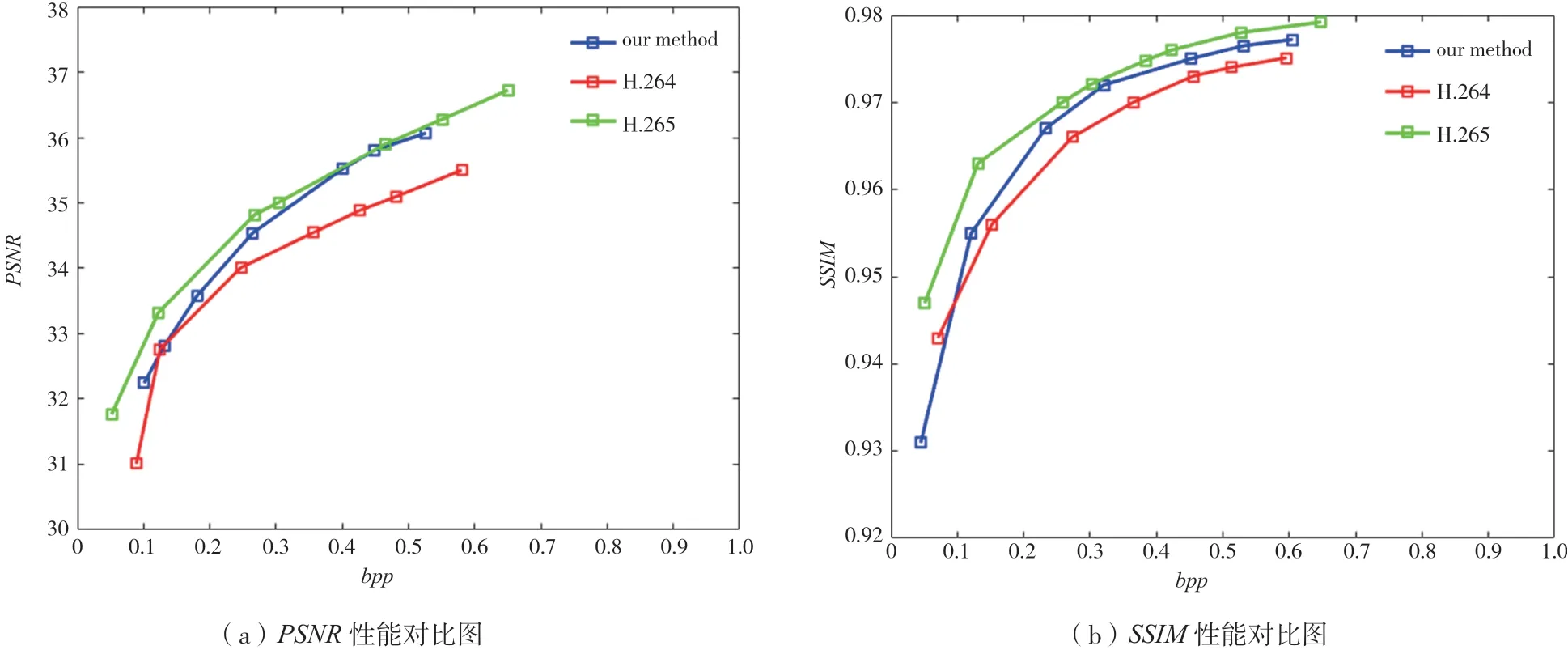
图3 本文方法和H.264与H.265的性能比较
4 结 语
由于水下的恶劣环境与条件,水下视频传输受带宽较低和时延长等因素的干扰,水下视频帧由于光照条件差、杂质较多等诸多因素产生噪声和伪影,使得采用传统方法传输的水下视频帧内容中感兴趣区域和目标模糊、不容易被识别,导致重建还原效果欠佳,无法得到真实清晰的水下视频帧。为了改善水下视频压缩传输质量,本文提出了一种基于结构分解的水下视频压缩学习传输方案,使得压缩传输后的水下视频在视觉感官等方面有了较好的性能提升。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
家庭影院技术(2020年12期)2021-01-18
含能材料(2021年1期)2021-01-10
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
电子制作(2018年18期)2018-11-14
Coco薇(2017年8期)2017-08-03
家庭影院技术(2017年12期)2017-02-06
工业设计(2016年8期)2016-04-16
Coco薇(2015年5期)2016-03-29
