
Transformer框架下面向车辆重识别的特征对齐与判别性增强
2021-02-14 06:24罗慧诚汪淑娟
电视技术 2021年12期
罗慧诚,汪淑娟
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
当前,车牌识别是确定车辆身份的一种有效手段。但在标清摄像头下,当车辆距离摄像头较远,车牌可能无法清晰成像。此外,有预谋的犯罪往往会采用一些手段(如遮挡车牌、套牌)来逃避摄像头的监控。在这种情况下,利用车牌识别来追踪目标车辆显然是不现实的。为弥补车牌识别存在的缺陷,车辆重识别概念被提出。该技术主要是利用车辆外观表现出来的特征,从不重叠相机视角识别出与给定车辆身份相同的车辆。由于其在城市安全和公共智能交通等方面具有广泛的应用前景,该技术受到了计算机视觉和多媒体领域研究者的极大关注。
虽然基于特征表示的车辆重识别方法已取得了极大的研究进展,但由于摄像头视角的差异、光照变化、复杂背景以及车辆姿态的影响,导致同一辆车在不同相机视角下表现出了巨大的外观歧义性。此外,具有相同颜色和相同车型的车辆往往不具有相同的身份,这给车辆的身份匹配带来了极大困难。为解决这一问题,本文在Transformer框架下提出一种面向车辆重识别的特征语义对齐与判别性特征表示方法。该方法首先使用预训练后的车辆姿态估计模型实现对车辆关键点的提取,然后利用关键点所具有的语义信息,根据不同图像块的坐标,设计一种特征聚集方法,将Transformer中具有相同语义属性的token划归到同一组内,这不仅赋予了token语义信息,同时也实现了特征的语义对齐,提升了特征鲁棒性与判别性。进行不同车辆图像的特征匹配,便能实现具有相同语义属性的部位进行特征的相似性度量,有利于匹配性能的提升。由于描述同一辆车的不同语义特征之间具有较强的关联关系,如果能有效利用这一关系,将进一步提升特征的质量。为此,将具有相同语义的token经过自注意力之后作为图结构的顶点特征,不同语义的token之间的相似度作为边,构建了图卷积网络来对不同语义属性的特征进一步优化。总结起来,本文的贡献包括以下3个方面。
(1)本文提出利用预训练的车辆姿态检测模型,来引导Transformer中具有相同语义token的特征对齐,实现了具有相同属性位置车辆特征的相似性度量,解决了车辆由于相机视角变化、姿态差异、光照改变、复杂背景而导致的同一车辆外观不一致的问题。
(2)提出利用不同属性特征之间的关联关系来提升特征的表示能力。为实现此目的,在经过自注意力模块的特征上,构建了图卷积网络,并以此实现了不同类别token特征的信息传递。
(3)在两个大型的车辆数据集(VeRi-776[1]和VERI-Wild[2])上的实验结果表明,所提出方法的性能优于大部分最先进的车辆重识别方法的性能。
1 方 法
1.1 概 述
本文提出的方法主要包括关键点引导的特征对齐、基于自注意力的局部特征强化以及属性特征信息传递3个部分。关键点引导的特征对齐以Transformer框架作为基线,解析车辆的关键点信息,得到精确的语义特征。基于自注意力的局部特征强化关注类别相关信息,对类别相关的特征赋予更大的权重。属性特征信息传递利用不同属性的语义特征之间的相关性,通过图卷积网络进行信息传递,提升特征的表征能力。3个模块以端到端的方式联合优化网络。本文提出的方法的整体架构如图1所示。
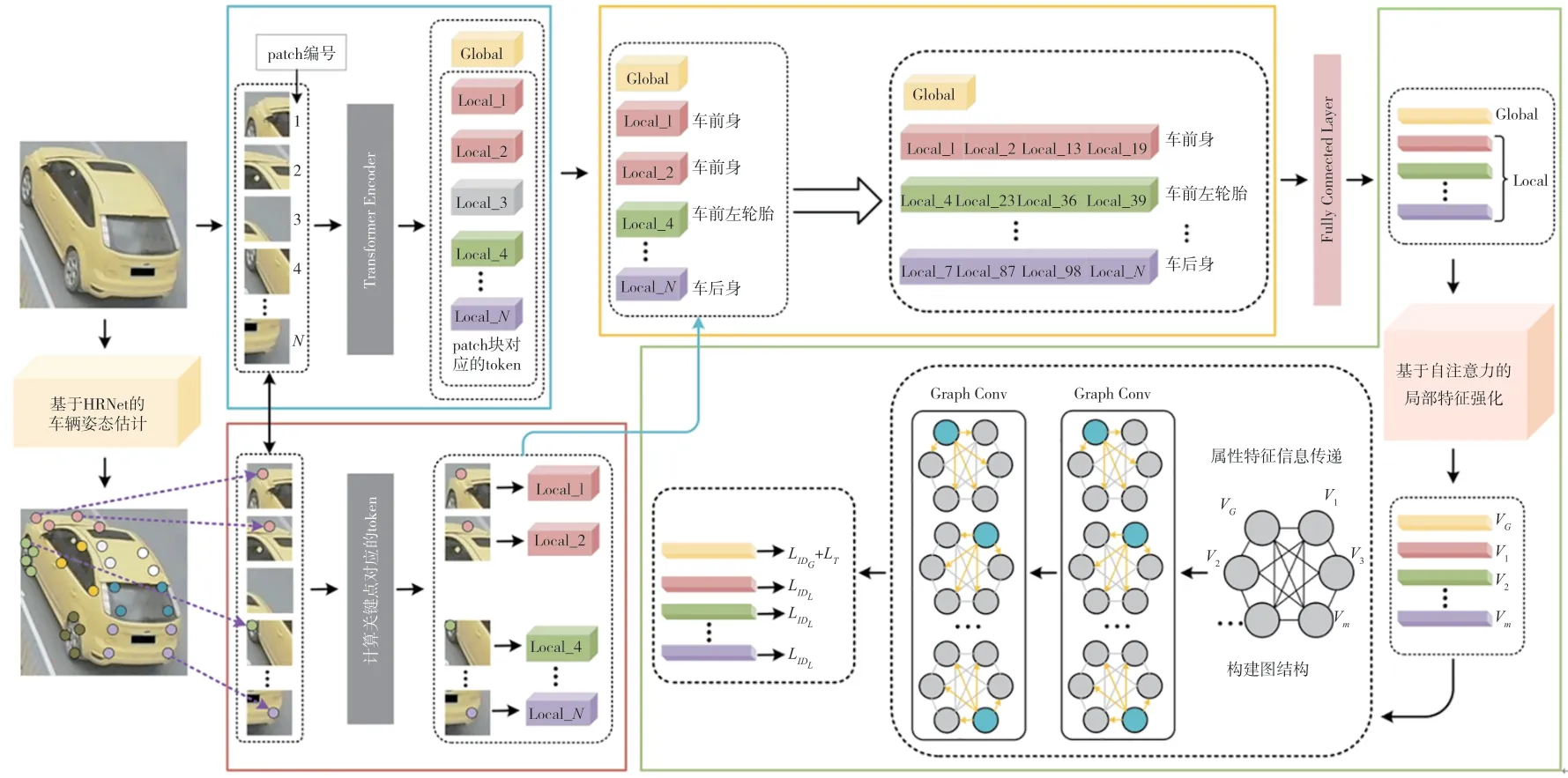
图1 Transformer框架下面向车辆重识别的特征对齐与判别性增强的网络结构图
1.2 关键点引导的特征对齐
给定一张图像x∈H×W×C,其中H、W、C分别代表图像的高度、宽度、通道数量。VIT框架使用滑动窗口的机制滑动图像x来划分为部分像素重叠的patch块,滑动的步长为S,patch的边长为P,分辨率为H×W的输入图像x被分为N个固定大小的patch块,过程如下所示:
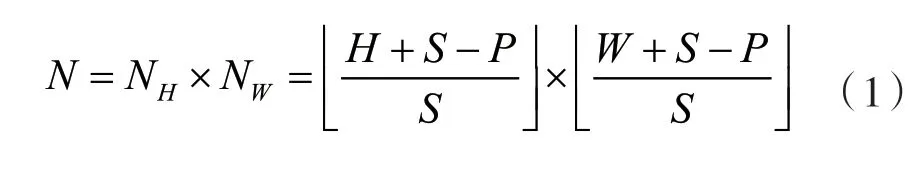
式中:NH和NW分别代表图像x高度和宽度上的patch块数量,[·]表示向下取整操作。切分后的patch块嵌入到网络的输入序列中作为局部特征表示。此外,一个额外的tokenfcls也被嵌入到网络的输入序列中,用于学习网络的全局特征表示。输入到Transformer层的输入序列的表示如式(2)所示:
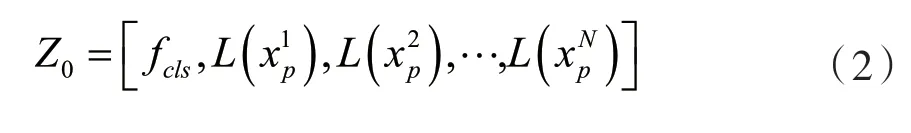
式中:Z0表示Transformer层的输入序列,L是将patch块映射到D维的线性投影,得到N个token。将输入序列送入l层Transformer层后,得到特征尺度不变的输出序列Z1。Z1可表示为:
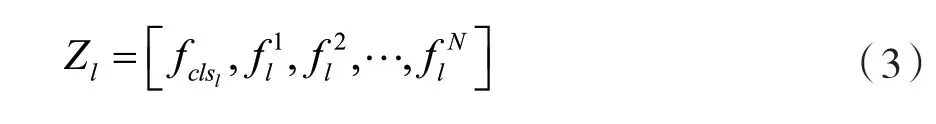
本文将N个token表示为作为网络的局部特征表示。将得到的fclsl作为网络的全局特征表示,使用多头注意力学习局部特征的分类能力。
在之前的工作[3-4]中,将车辆姿态估计模型输出的关键点信息与卷积神经网络产生的特征图结合得到局部特征。然而,Transformer模型不同于卷积神经网络,其特征提取过程不产生特征图,因此车辆姿态模型生成的掩膜数据无法直接用在Transformer产生的特征向量上。为了解决该问题,本文通过HRNet[5]预测车辆图像的关键点,由关键点坐标确定关键点对应的token。
具体来说,将x送入车辆姿态估计网络HRNet,能够得到全局特征图Fg和K个不同位置的局部特征掩模图因此可以通过式(4)得到不同位置的局部特征图。
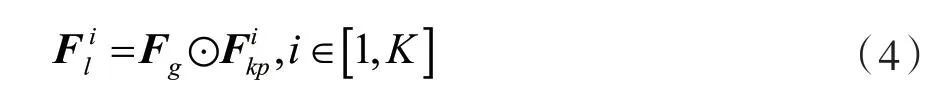
式中:表示全局特征图和一个局部特征掩模图逐元素相乘的操作,表示K个不同位置的局部特征图。
得到局部特征图后,该特征图上的最大值所在的像素点的位置坐标即为所需的关键点坐标。接着,将得到的关键点坐标在VIT框架里选择对应的token,即从VIT框架的N个token里挑选出符合关键点坐标的K个token,每个关键点对应的token编号的计算过程如式(5)所示:

式中:H和W分别代表图像x的高度和宽度表示向下取整操作,滑动的步长为S,patch的边长为P。对于token块表示它的关键点坐标,ni代表它在局部特征中 的 编 号。因此本文将K个token表示为
依据关键点对应的车身区域,可以将关键点聚合为m个车辆区域的语义特征,例如和四个token聚合后能够代表车前身。因此,将车辆相同语义区域对应的token进行聚合可以得到车辆的语义特征。其过程如式(6)所示。
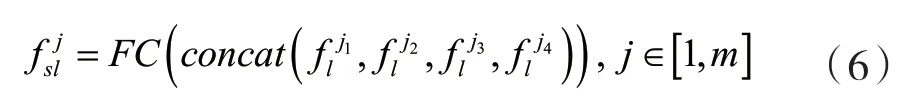
式中:concat(·)代表特征向量按通道concatation操作,FC(·)代表一层完全连接层,代表具有相同语义属性的token,代表车辆某一区域的语义特征向量。因此,能得到m个语义特征向量
1.3 基于自注意力局部特征强化
将上一个模块输出的m个语义特征向量和全局特征向量fclsl作为自注意力模块的输入fx。如图2所示,fx分别经过3个结构相同的线性嵌入的映射函数θ、φ、g,其中线性嵌入的映射函数θ的定义为:

式中:Wθ表示可学习的权重矩阵,可通过1×1卷积实现。
为了突出特征的判别性,需要探索语义特征的重要程度,过程如下所示。
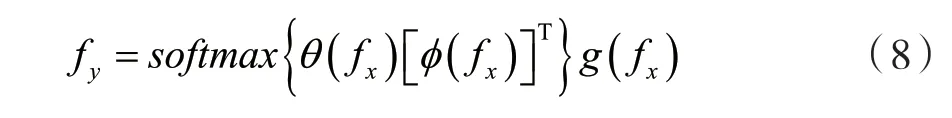
如式(8)所示,先对θ(fx)和[φ(fx)]T使用矩阵相乘的方式表示特征的相关性,再经过softmax函数对不同的语义特征分配可学习的权重,最后权重与g(fx)的积为g(fx)中关键的语义特征赋予更大的关注。
为了保留上一个模块提取语义特征能力的完整性,引入残差连接,依据式(9)将残差信息与fx结合。

式中:Wz表示可学习的权重矩阵,可用1×1卷积实现。得到的fz作为属性特征信息传递模块的输入。
1.4 属性特征信息传递
在现有的方法中,基于关键点或目标检测方法得到的语义特征通常直接按通道concatation操作进行特征融合,忽略了不同属性语义特征之间的相关性。不同属性语义特征之间的相关性可以提升特征的表达能力,例如车顶和前后挡风玻璃,车窗和车身等不同属性的语义特征间可以相互交互,提高语义特征的质量。为了利用车辆不同属性语义特征之间的关系,本文构建一个图卷积网络来对这些关系进行建模。如图1所示,其中,语义特征之间的相邻关系可由邻接矩阵A∈(m+1)×(m+1)表示,其中m+1是节点的数量。对于邻接矩阵A,如果语义特征i和j相邻,例如车顶和前车窗玻璃位置相邻,则设置A(i,j)=1。为了充分利用相邻关系,挖掘具有鉴别性的特征,图卷积模块通过使用图中每个节点向其相邻节点进行信息传播来实现关系传递。在注意力模块的后面添加两层的图卷积,其中每一层r可被描述为:

式中:A∈(m+1)×(m+1)是特征矩阵的邻接矩阵,E∈(m+1)×(m+1)是A的度矩阵,是第r-1层输出的特征矩阵,W(r-1)∈D×D是第L-1层可学习的参数,σ(·)是一个Relu激活函数。将基于自注意力的局部特征强化的输出置为初始的特征矩阵图卷积网络中节点L轮信息传播更新得到图卷积模块的输出
1.5 损失函数
经过3个模块后,得到优化后的全局特征fclsz和m个语义特征对于全局特征fclsz,通过构建身份损失LIDG和三元组损失LT来优化网络。其中身份损失LIDG是交叉熵损失,描述如下:
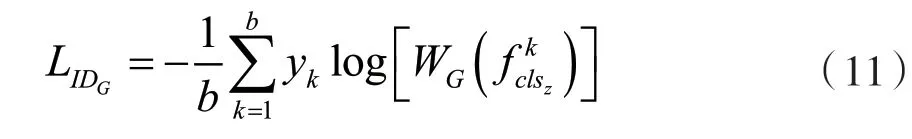
式中:b代表代表第k个样本的全局特征,yk代表车辆分类第k个样本的真实身份标签,代表全局特征分类器,代表分类器预测出的第k个样本的身份标签。
此外,本文还通过带有软间隔的三元组损失[6]使相同身份车辆图像具有高相似性,不同身份的车辆图像具有低相似性。具体优化公式如下:
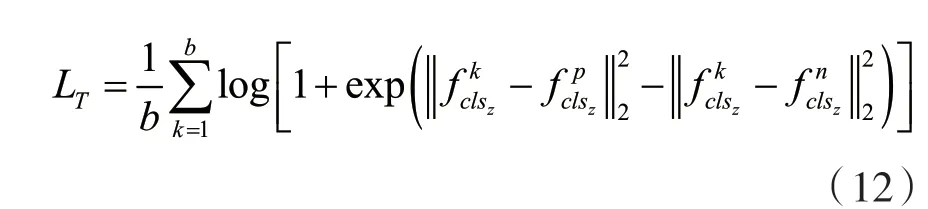

式中:b代表代表第k个样本第p个语义特征,yk代表车辆分类第k个样本的真实身份标签,代表第p个语义特征的分类器代表分类器预测出的第k个样本第p个语义特征的身份标签。
综上所述,所提出框架的整体损失函数L如下所示,通过最小化L以端到端的方式优化所提出的网络。
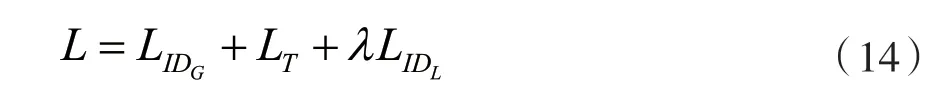
式中:λ表示超参数,表示L中调整语义特征身份损失项的权重。
2 实 验
2.1 数据集和评估指标
在两个大型的车辆重识别数据集VeRi-776和VERI-Wild上评估所提出的模型。将评估的结果与近两年最先进的车辆重识别方法进行比较。
遵循文献[2]和文献[7],本文使用平均精度均值(mAP)、Rank-1精度(R1)及Rank-5精度(R5)作为模型的评估指标。
2.2 实现细节
本节介绍实验中模型架构的详细信息。
本文使用基于VIT框架的12个Transformer层作为提取特征的主干。将基于车辆姿态估计的HRNet网络预测的36个关键点及其坐标映射到VIT框架里,得到关键点对应的36个带有不同语义信息的token。通过关键点将车辆图像划分为不同的语义区域,并将具有相同语义信息的token进行聚合,得到13个代表车辆不同区域的语义特征。之后,将Transformer层得到的全局特征和语义特征送入基于自注意力的局部特征强化模块和属性特征信息传递模块,得到鲁棒性的特征表示。最后对得到的全局特征和语义特征分别做分类损失。
2.3 与最先进方法的比较
本文将提出的方法与现有的车辆重识别方法进行比较,方法分为3类。第一类是基于深度学习的全局特征表示方法。研究人员使用深度网络从车辆的全局外观里学习视觉特征,代表性方法包括文献[8]、文献[9]、文献[10]、文献[11]的方法。第二类是多模态方法,这些方法通常利用车辆背景、车牌、时空上下文等多模态信息,方法主要是文献[12]的方法。第三类方法是车辆全局和局部特征的表示方法,由于所提的方法探索车辆的局部信息以此得到细粒度的特征,因此也与同样使用局部信息的方法进行比较。比较的方法主要包括文献[3]、文献[13-22]中的方法。比较结果如表1和表2所示,其中,“—”表示无可用数据。
在VeRi-776数据集上的对比实验:结果如表1所示,提出方法的性能在Rank-1/mAP优于最好的基于语义分割的车辆重识别方法PVEN[23]1.00%/0.64%,在Rank-1/mAP比最好的基于目标检测的车辆重识别方法Part regular[14]高2.30%/5.84%。此外,所提的方法在Rank-1/mAP上同样也优于最好的基于关键点的车辆重识别方法PAMTRI[3]3.74%/8.26%,并在VeRi-776数据集上实现了最好的性能。
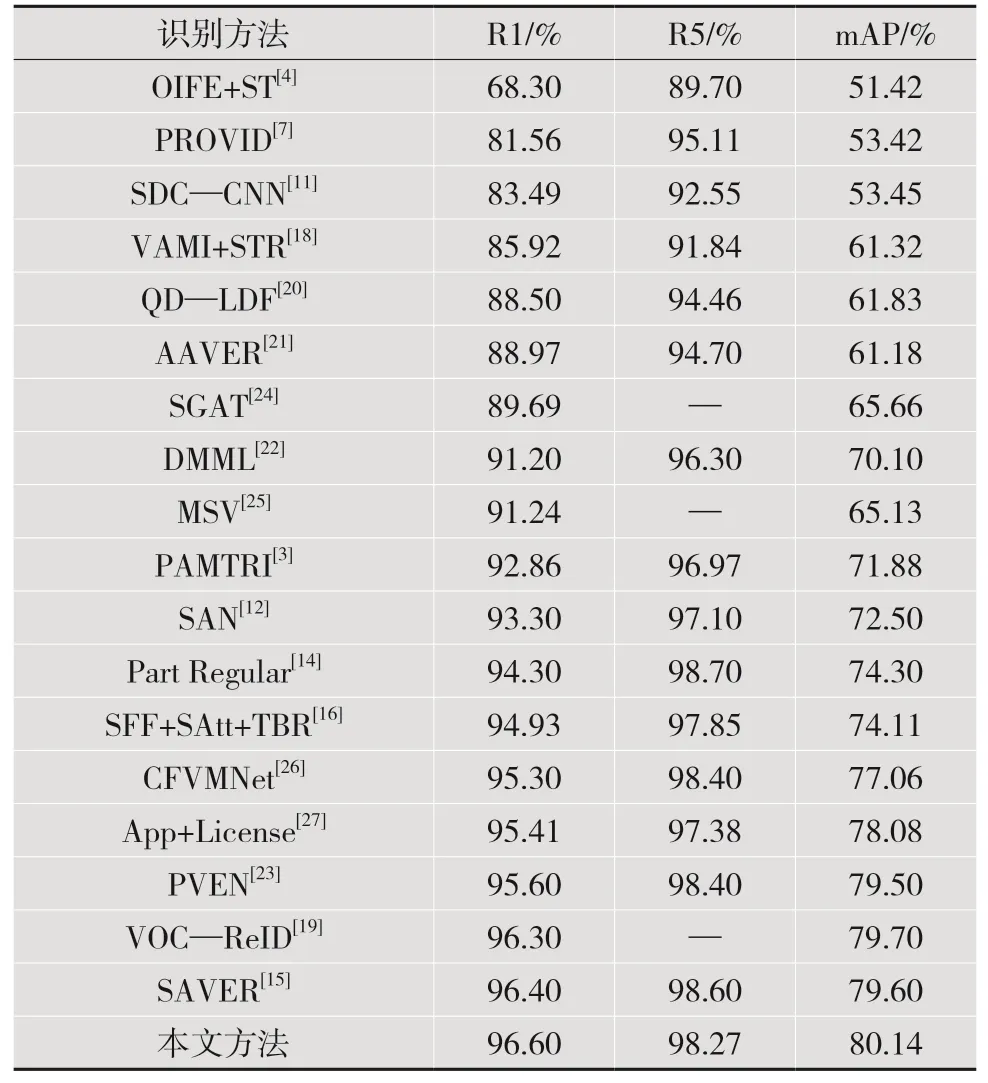
表1 在VeRi-776数据集上的对比实验
在VERI-Wild数据集上的对比实验:表2列出了本文方法在VERI-Wild数据集上与其他方法的比较结果,本文方法同样实现了最好的性能,在VERI-Wild数据集3个测试子集Test3000、Test5000及Test10000上Rank-1分别优于次优方法UMTS[13]3.05%、3.77%和4.64%。本文方法在VeRi-776数据集和VERI-Wild数据集上均实现了良好的性能,这表明了所提方法的有效性和通用性。
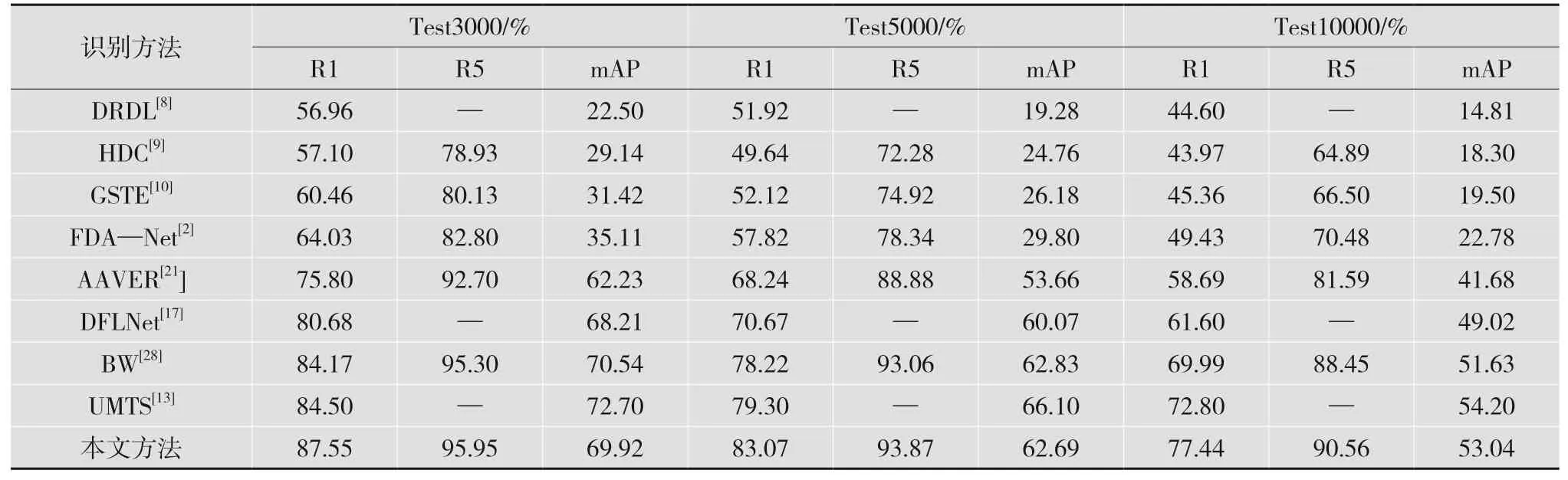
表2 在VERI-Wild数据集上的对比实验
2.4 消融实验
本节进行一系列的实验,分别验证提出的关键点引导的特征对齐(SFET)、基于自注意力的局部特征强化(SAFL)和属性特征信息传递(PGCN)3个模块的有效性。实验结果如表4所示。其中,基准方法仅用全局特征身份损失LIDG和三元组损失LT约束网络。加入任意模块后,使用全局特征身份损失LIDG、三元组损失LT和语义特征身份损失LIDL共同约束网络。在VeRi-776上进行消融实验,探究每个模块的作用。
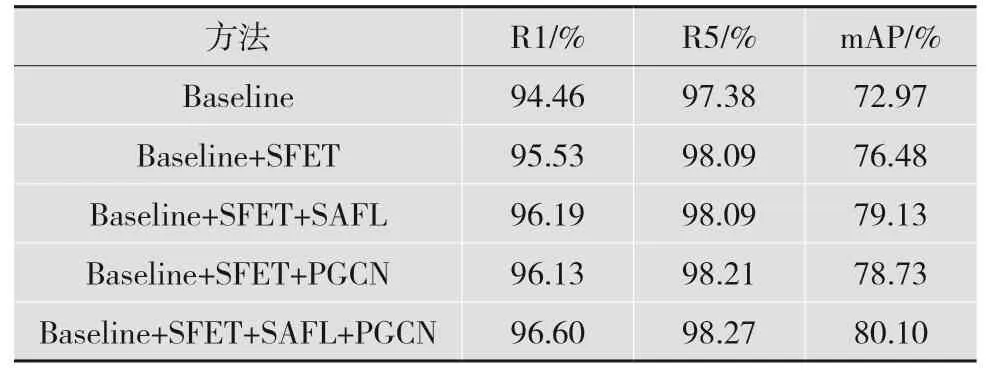
表4 消融实验结果
2.5 参数分析
本文涉及一个超参数λ,用来控制语义特征损失项。在VeRi-776进行超参数的分析,结果如图3所示,对于两个数据集,当λ∈[0,0.1]时,随着λ的增加,网络的识别率在逐步提升,然而,当网络的性能达到一个最高峰后却在不停减弱,即λ∈[0.1,1]时,随着λ的增加,Rank-1/mAP却在逐步下降,主要的原因是语义特征损失项过大,导致网络无法拟合。当λ=0.1时,本文的方法在数据集上得到最优的性能,因此根据实验结果将λ设置为0.1。

图3 超参数λ的有效性分析
3 结 语
本文提出了一种新颖的车辆重识别方法。该方法主要由关键点引导的特征对齐、基于自注意力的局部特征强化以及属性特征信息传递3个部分组成。其中,关键点引导的特征对齐模块通过一种新的关键点映射模型和Transformer基线得到细粒度的零部件语义特征,基于自注意力的局部特征强化模块为更显著的语义特征赋予更大的关注,挖掘出更具有判别性质的信息,属性特征信息传递模块为零部件的天然相邻关系建模,使语义特征间相互关联,促进了多摄像头下车辆的识别率。本文在两个基准车辆数据集上的实验表明了提出的方法在车辆重识别任务上的有效性以及对比同类方法的优越性。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
中国卫生(2014年2期)2014-11-12
电视技术(2014年19期)2014-03-11
