
基于图卷积神经网络的高校评教文本垃圾识别模型
2021-02-14 06:25熊晗
电视技术 2021年12期
熊 晗
(重庆工商职业学院,重庆 400052)
0 引 言
高校评教系统如何准确地刻画与量化教师教书水平,学生评价是有效的信息反馈手段。然而,目前高校的学生评教未能真正达到智能化的程度。其中一个主要的困难在于,学生的评价有大量的无效、无用、甚至是干扰的评论。如何在海量的评教文本中准确地实现垃圾信息识别,使评教系统智能化,是目前项目的工作重点。
近年来,在高校研究工作中,评教内容的使用与研究有很多突破与进展。在文本垃圾识别领域,深度学习技术有着相当不错的实现效果,特别是图卷积神经网络(Graph Convolution Network,GCN)的提出,将聚合节点的邻居节点以及边的信息来更新该节点的向量表征,捕捉到文本中更丰富和细致的特征,提升垃圾分类的识别效果[1-2]。本文结合大量学生评教语料的分析与处理,使用Bert完成词嵌入,将文本特征以嵌入向量的形式输入到图网络模型中。实验证明,相较于未使用GCN模型的方法,Bert结合GCN模型有着更好的分类性能[3]。
针对收集的学校的多年评教语句初步分析,进行分类识别垃圾评教语句的难点在于:
(1)评教语句往往比较简短,使用传统的自然语言的处理框架如循环神经网络(Rerrent Neural Network,RNN)以及衍生框架很难获取到语句有效特征;
(2)部分评教语句从语言、语法上无法区分是否为垃圾评教,比如学生评价:“老师教得不错”,可能是中肯的,也可能是敷衍的复制,这种情况需要收集足够多的特征来区分[4];
(3)文本数据量巨大,每年学生评教有大量的数据产生,人工标注较为困难。
本项目将按以下两个思路进行文本图结构表示。
第一类,将每个文本作为顶点,将顶点之间的实际拓扑关系作为边条件与权值,例如文本作者与粉丝之间的关注关系,文本相互链接的关系等等。
第二类是基于文本的实体与共指关系连接构建。将文本中的实体作为节点,并把实体之间的共指同现,邻近实体连接作为边,从而使用图结构进行表示。
通过研究调查,图卷积神经网络与自然语言处理结合已经有理论基础认证,并有部分实际工作[4-5]。本文重点将结合图卷积神经网络的结构特点,使用目前前沿的Bert框架对文本词嵌入做好预处理。融合学生属性数据与评价文本的特征表示作为输入,进行下一步图卷积训练,用学生-教师-评语二部图的关系聚合各节点的特征信息,捕获局部上下文的关系,从而获取更细致的特征。最后使用分类器对文本进行分类,完成相关分类工作。
1 模型详细设计
1.1 特征表示与文本词嵌入
要得到更好的识别效果,使用的学生信息就应该尽可能地多,才能充分挖掘学生评教质量的高低,从而识别出垃圾信息。本次实验,收集的维度不仅仅局限于文本。针对学生的成绩好坏、平时作业是否喜爱抄袭、所在班级、关系紧密的同学等等信息都作为特征收集,这些信息在一定程度上可以反映出一个学生的评价信息是否质量较高,这样从一定程度上丰富了特征信息,补充了仅仅靠学生评教语句来挖掘信息的不足。比如成绩不太好、平时作业就有网上复制习惯的学生,很大可能其评教语句也是随意复制的。
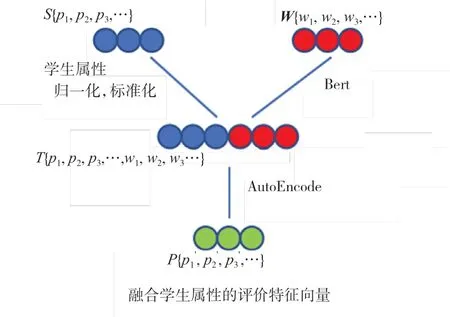
图1 多维度评价特征向量
1.2 图神经网络构架
参考图卷积在文本分类上的基本原理,设定G=
接下来,将学生的评教文本数据与评价老师的关系看做一个“学生、教师为顶点,评语为边”的二部图,如图2所示。
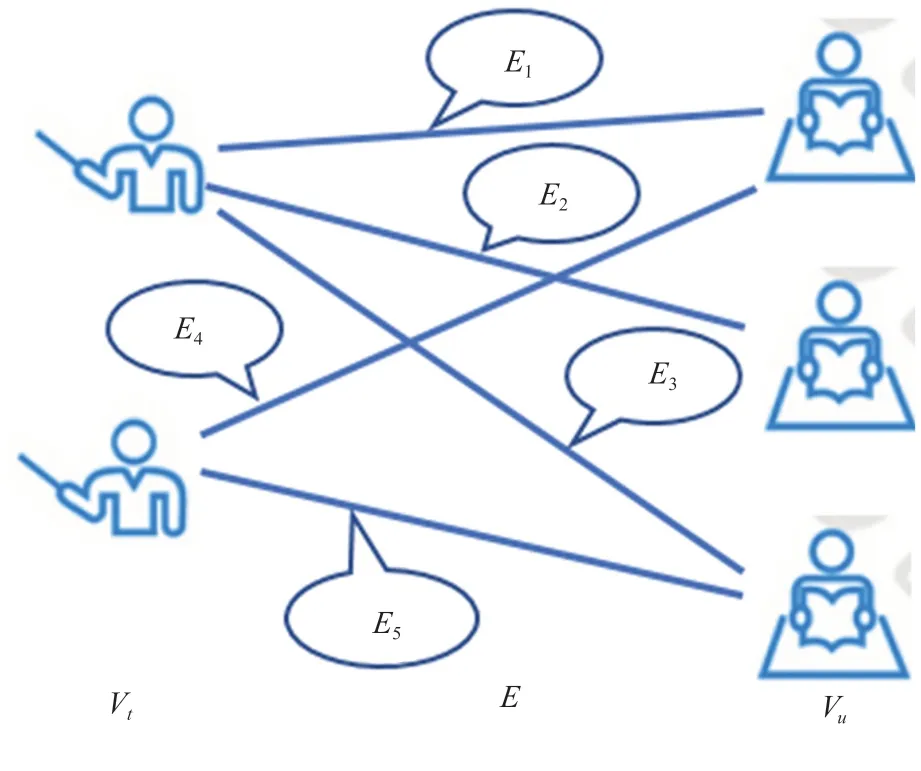
图2 学生-教师-评教二部图
按照图卷积网络的提取过程,针对图网络的领域提取特征,同时将两边的特征容纳到特征领域的提取过程中。对于边特征的更新过程为:将边E特征与二部图两侧的顶点教师Vt与学生特征Vu进行更新,更新按照两个步骤进行,即特征提取与特征融合,对应公式如式(1)和式(2)所示。
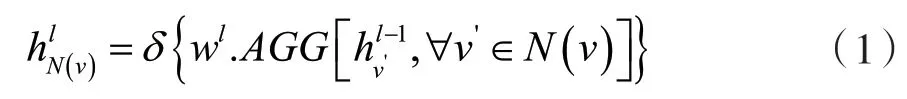
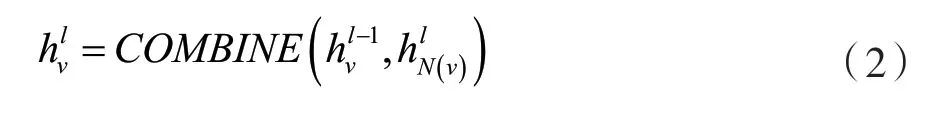
如上所述,在基于GCN的节点分类中齐次图上的任务,从最后一层嵌入节点用作分类器的输入。相反地,利用上次传播的边缘嵌入层以及该边链接到的两个节点的嵌入,将这三个嵌入连接起来进行边缘分类。根据设置的二部图设定,在同构图上基于GCN的节点分类任务中,使用最后一层作为节点分类器的输入。利用来自最后的传播层的边缘嵌入以及改变的边缘链接到的两个节点,使其链接起来作为边缘分类,整体构架分为Aggregation Sub-layer和Combination Sub-layer。其中Aggregation Sublayer使用TextCNN模型可得到:
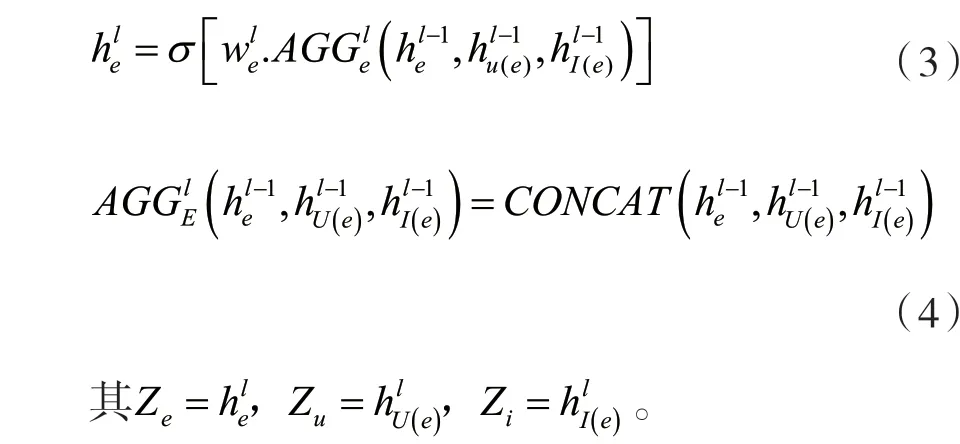
最后使用式(5)将sotfmax层接入神经网络层,对评教语句进行分类,最后选择得到概率最大的类别,判断是垃圾评价还是正常评价。
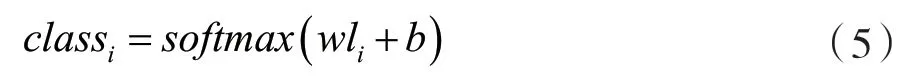
1.3 总体网络模型构架
总体流程如图3所示。
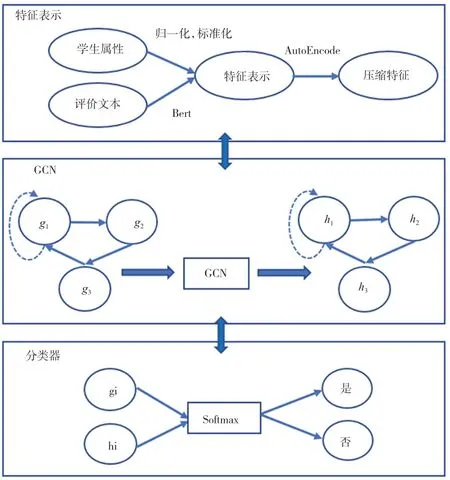
图3 Bert+GCN垃圾识别模型整体构架
2 实验与结果
2.1 实验数据与环境
数据收集重庆工商职业学院2010—2015共5年的评教数据,并且按照8∶2的比例分为训练集与测试集。针对原始数据进行清理。
对于评教数据进行如下处理:
(1)将评价过于简短如“很好”“不错”“可以”等词语删除,后续这部分词语可以作为一部分低权重的特征加入对教师评价的判断中,在本次实验中暂不考虑;
(2)删除重复过多的评价短语,这部分几乎是无意义地复制粘贴而来,对真实情况的反映意义不大;
(3)处理停用词与标点。
处理后,评教数据总量为18 986条。
对于学生的属性数据,本次选取的学生属性数据共13个维度,样例如表1所示,共收集数据11 289条。

表1 学生属性数据特征样例
2.2 实验结果分析
根据模型详细设计流程,为了测试图卷积神经网络针对选取文本的分类效果,本文选择了几种常见的自然语言处理的机器学习构架来进行比较。为了更加全面与科学地比较,本次实验选取机器学习的代表方法支持向量机(Support Vector Machine,SVM),它是常见的深度学习基本框架方法,也是目前主流的组合框架方法。数据处理阶段,统一使用数据特征的处理过程(图1过程),保证输入结构一致。后面处理过程采用如下几种框架进行比较。
(1)SVM+朴素贝叶斯。提取的是TF特征,统计出每个特征及其频次。以特征的id作为下标,频次作为数值,假设一共有n个特征,一篇文档就转化为n维的词袋向量。朴素贝叶斯法是最简单常用的一种生成式模型。朴素贝叶斯法基于贝叶斯定理将联合概率转化为条件概率,然后利用特征条件独立假设简化条件概率的计算。
(2)GBDT。GBDT是把所有树的结论累加起来做最终结论的。GBDT的核心在于,每一棵树学的是之前所有树结论和的残差(负梯度),这个残差就是一个加预测值后能得到真实值的累加量,GBDT在各类比赛中针对分类类型问题均有非常好的分类表现。
(3)TextCNN。TextCNN的最大优势是网络结构简单,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量,依旧有很不错的效果,在多项数据数据集上超越benchmark。并且网络结构简单导致参数数目少,计算量少,训练速度快。
实验结果如表2所示。
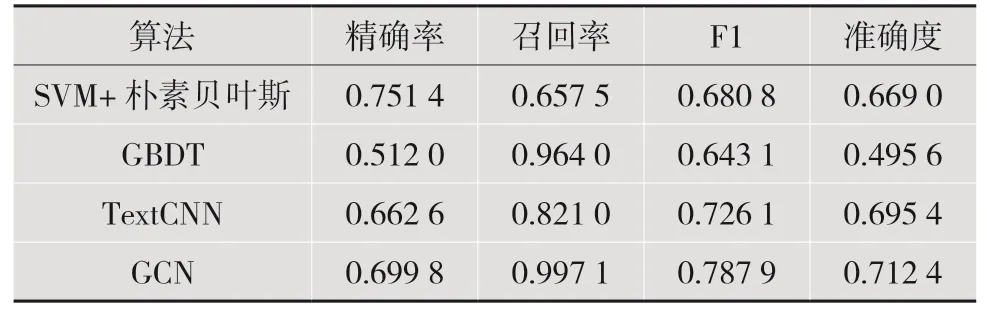
表2 评教垃圾评语识别各算法框架对比
通过实验可以看出,bert预处理的词嵌入结合GCN的网络模型,在本次实验的环境中,极大程度地获取了评教文本以及学生属性信息的相关特征信息,很好地表示在文本评价质量的分类工作中。
3 结 语
本文以目前近年来流行的图卷积神经网络框架为研究对象,结合目前收集的学校评教数据的特征进行模型设计,解决评教语句中过多的垃圾评价很难单通过语句进行判断的弱点。融入学生属性数据后,结合学生-评教-教师的二部图关系,设计图卷积神经网络模型,形成在特定场景下的一些具有图网络关系的评价语句进行研究。最后通过实验证明,在专业词汇较多、文本简短、评教文本之间有丰富连接关系且标注数据量较少的语料场景下,使用图卷积神经网络训练取得了更好的效果。
猜你喜欢
科教导刊(2023年2期)2023-02-23
北京航空航天大学学报(2021年9期)2021-11-02
新世纪智能(语文备考)(2020年4期)2020-07-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
大庆师范学院学报(2015年3期)2015-12-24
河南教育·基教版(2015年5期)2015-06-05
电视技术(2014年19期)2014-03-11
语文知识(2014年4期)2014-02-28
