
基于深度学习的对话重叠语音片段检测
2021-02-25 08:33魏金太
中北大学学报(自然科学版) 2021年1期
魏金太,高 穹
(1.河南林业职业学院 信息与艺术设计系,河南 洛阳 471002;2.中国洛阳电子装备试验中心,河南 洛阳 471003)
0 引 言
重叠语音是指在给定时刻同时说话的情况,即双重对话的讲话者多于一个.讲话者说出某些事情时,其他参与者可能表现出非竞争性承认(例如“嗯”)或反应(例如“笑”),也可能竞争性地打断他们的错误判断等[1],这在自发对话中是非常常见的.虽然重叠的频率和持续时间可能因情况而异,但在正常的自发对话期间,重叠是频繁且简短的(大多小于1 s,如图1所示),因此提高了语音的手动注释成本,对语音的自动检测提出了挑战.
在自发对话的场景中,双重对话的存在对大多数自动语音技术是不利的[2].说话人聚类系统的目标是在谈话中确定谁在说话,如果在重叠期间错过了其他发言人,则会受到惩罚,这种惩罚已成为这类系统中存在的主要错误,使得重叠言语情况成为说话人聚类识别系统的致命弱点[3].许多语音技术(如自动语音识别)依赖于由聚类识别系统产生的说话者语音分段类别[4-6].因此,以往大多数对真实语音中说话人分割聚类的尝试都是在说话人聚类识别中进行的,最常见的是针对零(即静音)、一个或多于一个同时活动的讲话者进行逐帧分类,并且已经在GMM-HMM框架[7]中得到解决,同时设计不同组合的声学特征.在早期的深度学习中,采用DNN降低其交叉相关特征进行降维[8],或者使用基于LSTM的回归器[9],该回归器在串联设置中进行各种声学特征的训练,并将其有效地用作基于GMM-HMM的检测器的附加特征.然而文献[10]报道,仅通过对回归器的输出进行阈值化,使用单层的LSTM就可以达到与GMM-HMM相当的性能.尽管如此,实际对话中的重叠检测问题仍未解决,并且在系统的精确度和召回率之间呈现出难以折衷的特性.
从真实对话中学习发现双重对话的挑战根源在于三种类别之间存在的固有的不平衡性.从表1中可以看出,在自发谈话中,具有重叠的个体片段占整体的很大一部分,由于持续时间极短,其在单帧(10 ms)中的比例最小.一些研究试图通过人为重叠语音训练来解决这个问题,如使用Pyknogram作为声学特征,报告在不同噪声条件下检测人工重叠的更好结果[11],但是其评估显示,重叠长度小于2 s的检测性能较低.此外,也有利用类似限制时间分辨率的方法,研究指出,在使用基于深度学习的方法中,检测持续时间为500 ms,100 ms和25ms 的窗口下的说话人重叠检测取得了更好的结果[12].这些研究将MFCC与其他三种声学特征相结合来训练卷积神经网络,然而,对于在实际对话中发现自然双重对话的情况,没有关于此类系统的评估报告.

表1 Fisher英语语料库(第1部分):961 h中具有不同数量同时活跃说话人的片段和帧的百分比Tab.1 The percentage of segments and frames with different numbers of speakers active in961h Fisher English Corpus (first parts)
虽然人为增加噪音可能有助于增强现实世界情景的稳健性[13],但计划语音本身与系统最终的应用环境有严重的差异.演讲者在独自说话时和在自发谈话时会表现出不同的语调、步调等,因此,对于典型的持续时间、发声和内容而言,双重会谈的特点将难以在计划的语音重叠中复制.
本文开发和评估了使用自然双重对话进行真实对话的系统,它使用基于DCNN的自动特征提取器和分类器,仅将对数尺度的梅尔顿谱图输入,避免了手工特征工程的需要.
1 提出的算法
本文系统根据同时讲话者的数量将提取的单声道音频声学特征按帧分为静音、单人及重叠3类.在32 ms的窗口(相当于256个8 kHz音频的FFT频段)中每10 ms提取一次64维的log10标度梅尔频谱图(滤波器组)用于各种基于深度学习的声学模型,这些频谱已被证明优于MFCC和纯频谱图.为了减少训练和测试条件之间的不匹配,且鉴于特征是对数比例的,作为针对卷积信道失真的测量,对所提取的特征应用倒谱均值归一化(CMN).然而,该系统是以块为单位进行的,其中大约2.5 min的连续音频块的平均向量被用于该块的所有向量中,这样可以避免语音级CMN的可靠性问题,同时也避免了无关异常值的影响.
本文所提的DCNN架构如表2所示,是VGG-net的简化版本,大约有572 K个可训练参数.所有的训练都是在统一初始化之后进行的,并且使用Adamax来优化三类输出后验概率的分类交叉熵.在构建DCNN的输入时,在特征向量已经归一化之后且创建随机化分批之前,在给定的帧之前和之后添加10帧,这些帧将被分类以向分类器提供额外的上下文信息.使用较少的上下文框架会导致结果不理想,而使用较多的帧会导致计算成本显著提高.我们改善了所有实验的特征提取和DCNN架构,这些架构使用高度模块化的语音分割框架实现,使用深度学习开源库RENNET[14],它建立在NumPy,LibROSA,Keras,Tensorflow和其他可靠的Python库基础之上.如图2所示,通过DCNN输出的帧级别的原始后验概率来生成分段通常是比较混乱的,本文使用维特比算法来解码获取时域平滑后的最终分割,并评估其影响.
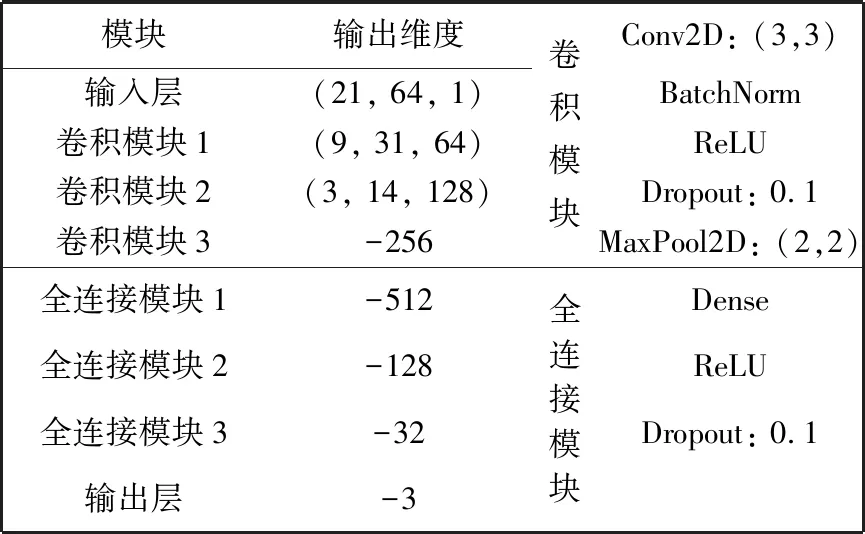
表2 DCNN的体系结构以及每个块中的层Tab.2 The architecture of DCNN and the layers in each block

图2 真实标签、原始方法结果标签以及对训练数据平衡后消除静音平滑后预测标签结果对比Fig.2 The comparison among the real label,the original method result label and the prediction label result after the training data is balanced and the mute smoothing is eliminated
2 数据集
对于检测对话中重叠语音,之前大多使用AMI,NIST RT,ICSI和其他会议语料库,虽然它们也许是某个问题的最佳场景,但由于记录条件的不一致会造成额外的挑战.此外,之前的设计只使用这些数据集的一个子集,从某种意义上来说,这个子集不足以适当地训练DCNN,同时解决类失衡问题.本文使用Fisher英语语料库(第1部分)进行研究,主要用于LVCSR研究,其基于电话的大部分会话都有自然发生的双重对话,并且可用数据的剪辑大小约961 h,使得稍后更容易实现某些简单的对比实验.然而,受计算开销的限制,我们在训练期间仅使用000组至012组,共有1299次电话记录,数据总时长约91 h,其中14%为重叠,在测试阶段使用053组至058组约200 h,其中10%为重叠.
语料库本身也存在一定的局限性,作为基于电话的对话,重叠扬声器的最大数量严格限制为两个.所有音频采样频率为8 kHz,这对高分辨率的语音质量可能是一个局限,但通过向下降低采样质量可更容易得到可靠的信号输出,而不是采取相反措施进行上采样.实际上,本文系统通过使用固定数量的滤波器组进行麦克风缩放,可以摄取任何采样率的音频.沿着相同的路线,原始音频有两个独立的扬声器声道,合并后只能用作单声道音频.虽然使用立体声音频可能会更好地提高性能,但通过支持这种最大的差异化条件,本文系统几乎适用于所有情况.
语料库的一个更相关的问题是话语边界中的相对不精确.根据文件,这些边界是由语音活动检测系统确定的,而不是后来手动调整的,但是由于这个系统的准确性并没有得到验证,实验中发现它的识别结果不是特别精确,特别是在很小的重叠区域,而且这些不准确的信息不像ASR系统那样需要对音频中的事件进行时间定位.在许多实验中已经验证了在大型数据集上训练的足够强大的DCNN可以抵御这种精度不足的情况.在本文实验中,并没有去修改这些注释,但是如果有独立的扬声器通道可用,那么改进它们可以对实验结果进行进一步的优化.
3 处理类别失衡
3.1 重新平衡训练数据
重新平衡系统在训练期间看到的数据是处理不平衡类别影响的最常见方法,它是通过少数群体的过度抽样或大多数群体的欠采样来处理不平衡类别的影响.当数据集很小时,过采样是最主要的方法,可以通过创建少数类的新例子,并使用几种方法来转换现有的例子以避免过度拟合(例如SMOTE).但是,这种转换对于音频信号来说并不简单.而且,由于数据集中样本类别的大小不一,通过选择对大数据样本类别进行欠采样,然后对类别平衡后的数据集进行评估.为此,我们均匀随机地跳过带有单个演讲者讲话的帧,使得最终的整体单人与重叠的比例为二比一.通过选择这个比率作为一种近似的方法,用于为每个说话者单独和重叠地呈现DCNN具有相对相等的帧数.
3.2 消除静音
静音或缺乏言语比任何数量的发言者的言语更容易辨别,而单独说话者产生的语音与多个说话者同时产生的语音之间的区别(即使是孤立的)是困难的,这个问题可能导致神经网络陷入陡峭的局部最小值,虽然检测静音的目标得到很好的满足,但是不能用于双方谈话检测.此外,静音检测可以通过使用比DCNN更简单的方法来完成.因此,与大多数之前的设计类似,我们尝试在训练期间基于真实标签去除所有静音帧.为了在实验的评估过程中实现时间平滑,我们基于静默的真实标签明确地将静音帧设置为完美预测.
3.3 其他
移动基于类先验的决策阈值[15]是一种流行的方法,但是这种方法的实验是不稳定和不可靠的;另一种方法是修改损失函数以纳入错误分类处罚,它相当于基于随机梯度下降的训练的朴素过采样.
4 实 验
在类别不平衡的情况下,分类精度和召回率比总体准确度等常见度量更具信息性.我们在所有类的系统级别报告这些原始和平滑分段的度量,所有评估都是在前面指定的大约91 h的对话中进行的.
在几个深度学习架构和参数的初步实验中,观察到在某些退化的情况下系统未能准确地检测重叠.而模型参数较少的情况下预测结果多为单一的说话人,通常后验概率为1,甚至在对结果进行时域平滑也不能有效提升检测的准确率.具有中等规模模型参数的常见退化情况是系统在检测静音时具有很高的鲁棒性,但不会检测到任何重叠.这个结果证明静音探测器在训练期间对静音的学习表现出对重叠检测的影响.当应用像阈值划分的检测方法时,检测到的重叠精度极低,每帧的结果似乎是随机确定的单人或重叠.
对于本文的DCNN的基准性能测量,我们在训练集上对系统进行了20次训练,无需重新平衡类别,并将保持静音作为训练目标的一部分.
如表3所示,该基线系统没有以良好的精度检测静音,证实了对检测重叠的惩罚项导致召回率偏低,这可能是由于在不同的噪音条件下来自静音的竞争增加.然而,精准度高的情况重叠表明DCNN的确发现了一些重叠的判别特征.通过从原始预测中删除不可能的短片段或填补某些空白,时间平滑改进了静音和重叠的精准度,但是也删除了一些正确预测的帧,相对地减少了重叠的召回率.

表3 在不同的策略之后分类精度和召回率Tab.3 Classification accuracy and recall rate after different strategies
然后,在相同的不平衡训练集上训练相同的DCNN 20次,删除了静音帧.在评估过程中,没有从输入中删除静音帧,在整个测试集中没有一个静音帧被检测为重叠,表明DCNN已经学习了重叠.对于原始分割,我们观察到重叠召回率的改进,但对重叠精准度的成本很高.时间平滑重新获得了丢失的重叠精准度,其对重叠召回率的成本相对于之前的实验来说相对较小,并且不会影响单人的检测性能.
通过训练DCNN 40次,对单人随机欠采样,同时也消除了静音.我们将此实验的训练次数增加了一倍,以避免单扬声器类别的不足.对测试集的评估显示了重叠的召回率得到了大的改进,但在原始预测中有大量的假阳性.然而,这些误报中的大部分都是嘈杂的、极短的,通过这些方法得到了充分的消除,平滑过程导致重叠的精准度得到实质性改善,其相对于重叠的召回率的成本更低.
5 结 论
本文展示了在真实对话中训练DCNN以检测自然双重对话,并提议使用Fisher英语语料库而不是人工重叠的数据进行训练.虽然这限制了只能以较低的采样率使用单声道音频,并且使其成为此任务技术上最困难的场景之一,但它也使得所得系统在适用性方面最为通用.然而,使用真实的谈话带来了类别失衡,这对双重对话造成了严重的不利影响,但DCNN学会了双重对话的一些独特特性.实际上,本文所提DCNN只能从相对较低级的标准梅尔谱图中自动学习这些特征,而不是之前工程中使用的手动定制特征组合.
根据以往研究,从训练目标中消除静音有助于减少双重对话的不利条件,然后通过在训练期间重新平衡类别,可以实现更多的改进.语料库的规模提供了选择欠采样作为此目的的策略.未来与该语料库合作完成此任务应该考虑使用更好的语音检测器来提高标注的精度.
我们期望一个更强大的DCNN系统结构能够表现更好,但研究也表明DCNN在利用长期时间模式方面的弱点,并报道了使用Viterbi算法对后验进行时间平滑的改进.目前,在深度学习方面缺乏全面的研究来解决类失衡问题,尤其是在与语音技术相关的任务中.因此,该任务可能是这类研究的一个很好的选择,而且有益于语音重叠情况下的言语技术.
猜你喜欢
江苏安全生产(2022年9期)2022-11-02
少儿画王(3-6岁)(2020年4期)2020-09-13
意林(2020年15期)2020-08-28
电脑报(2020年50期)2020-03-10
中国外汇(2019年7期)2019-07-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
东方教育(2018年20期)2018-08-22
科学启蒙(2017年4期)2017-04-10
南方周末(2014-01-02)2014-01-02
