
基于树形语义框架的神经语义解析方法
2021-03-18 02:52赵睿卓高金华孙晓茜沈华伟程学旗
中文信息学报 2021年1期
赵睿卓,高金华,孙晓茜, 徐 力,沈华伟,2,程学旗,2
(1. 中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学 计算机与控制学院,北京 100049)
0 引言
语义解析的目标是将自然语言表达映射为机器可理解的逻辑表达,使得人类和机器能够更加方便地进行交互。语义解析在问答、指令解释和代码生成等自然语言理解任务中均有重要的应用。为了适配不同的应用需求,目标逻辑表达的形式也不尽相同。常见的逻辑表达包括FunQL、λ演算和以SQL查询和python代码为代表的编程语言等。考虑到λ演算的表达能力和灵活性,本文采用λ演算作为目标逻辑表达的表示形式。
早期的语义解析方法[1]通常采用词典和包含一系列组合规则的语法共同作用的方式生成逻辑表达。对于一个给定的自然语言表达,该类方法先根据词典和语法规则产生目标逻辑表达的备选集,再学习一个打分函数来对备选集中的逻辑表达进行打分,并将得分最高的逻辑表达作为最终的解析结果。然而,词典和语法通常被限制在一个特定领域并且训练过程需要大量的特征工程。随着深度学习的发展,越来越多的结合深度神经网络的神经语义解析方法[2]被提出。该类方法通常采用编码器—解码器框架,将自然语言表达作为输入,逻辑表达作为输出,以端到端的方式进行训练,在语义解析任务上取得了目前最好的效果。
神经语义解析方法面临的关键挑战在于如何捕获蕴含在自然语言中的组合语义。大部分现有的工作从语法的角度切入,通过在序列化解码器中引入语法限制或者模板限制来建模组合语义。然而,此类方法引入的语法或者模板是领域特定的,不能覆盖所有的自然语言输入。还有一类工作提出,使用树形结构的解码器来更好地建模逻辑表达的层次化语义结构。虽然这类模型相比于简单的序列化解码器取得了更好的效果,但是其忽略了语义相似的句子通常有相同语法结构的事实,如图1(a)所示。文献[3]提出了一个由粗到精的解码框架来捕获不同层次粒度的语义。该方法将逻辑表达分为包含高层次语义的语义框架(Sketch)表示和包含细粒度语义的语义细节。然而,该方法提出的高层次语义框架仍然是用序列化的方式解码生成的,不能很好地建模语义框架的层次化结构,如图1(b)所示。

图1 自然语言与逻辑表达示例(a) 是两个自然语言表达和它们分别对应的的逻辑表达;(b) 展示了两个逻辑表达共同的语义框架和树形结构。
本文提出生成树形语义框架来更好地建模逻辑表达的组合语义,该模型包含两个阶段。第一阶段使用一个树形结构的解码器自顶向下地生成自然语言的语义框架,第二阶段结合生成的语义框架和自然语言输入来解码得到最终的逻辑表达。该模型有两个优点。首先,采用语义框架作为中间形式,使得相似的逻辑表达能够在不同的语义层次上共享相同的语义框架。其次,树形结构的解码器能够保证语义框架中不同组成部分的解码独立性,进而生成更好的语义框架。大量的实验结果表明,该模型能够更准确地生成语义框架,并且在语义解析任务中取得更好的效果。
1 相关工作
在语义解析发展的数十年中,很多不同的方法被先后提出。现有的大部分方法主要采用监督学习的形式,通过自然语言句子和对应的逻辑表达来训练得到语义解析器。早期的方法通常以词典和包含一系列组合规则的语法为基础生成逻辑表达。对于一个给定的自然语言句子,这类方法首先根据语法和词典生成目标逻辑表达形式的备选集,再训练一个打分函数对备选集中的逻辑表达进行打分排序,并将得分最高的逻辑表达作为最终的解析结果。常见的语法规则包括组合类型语法(CCG)[4]、同步上下文无关语法(SCFG)[5]、基于依存的组合语法(DCS)[6]等。然而,这类方法中的语法和词典通常只能用于特定的领域或者特定的逻辑表达形式,并且训练的过程需要大量的特征工程。相比之下,本文提出的模型以端到端的方式运行训练,不需要进行特征工程,并且能够灵活地迁移到不同的领域和逻辑表达形式。
最近,基于深度神经网络的编码器—解码器模型已被广泛应用到语义解析任务中并取得了较好的效果[7]。这些方法的关注点集中在建模逻辑表达的语法结构。一些工作通过引入先验知识来限制解码器的输出,包括语法规则和逻辑表达模板等。文献[8]把语法规则作为解码器的输出空间,文献[9]设计了一个语法限制的解码器来生成抽象语法树(ASTs),文献[10]将解码过程设计为对预定义SQL模板进行填槽。然而,预设的语法规则和逻辑表达模板很难覆盖整个输出空间,限制了该类方法的实际应用场景。此外还可通过设计结构化的解码器来捕获逻辑表达的语法结构。文献[7]提出一个层次化的树形结构解码器来建模逻辑表达的组合结构。文献[3]提出一个由粗到精的解码框架来建模不同粒度的语义。该方法首先生成一个粗粒度的语义框架(sketch),再将该语义框架用于指导最终逻辑表达的生成。
我们的模型也采用语义框架来建模逻辑表达的组合结构。与之前工作不同的是,该模型通过一个树形结构的解码器自上而下地生成语义框架。树形结构的解码器能够层次化地捕获组合语义并且保证解码过程中不同组成部分的独立性,进而更好地生成语义框架。
2 问题定义
语义解析任务的目标是基于自然语言输入和逻辑表达来训练得到最终的语义解析器。给定自然语言句子表达X=x1,…,x|x|和其所对应的逻辑表达Y=y1,…,y|Y|,语义解析任务的目标是建模条件概p(Y|X)。
这个概率被分解为以下两个部分,如式(1)所示。
其中,S=s1,…,s|S|代表输入句子的语义框架。第一个阶段以概率p(S|X)生成语义框架S;第二个阶段在输入X和语义框架S的指导下以概率p(Y|X,S)生成最终的逻辑表达。语义框架是以自上而下的方式生成的,概率p(S|X)可以分解为如式(2)所示。
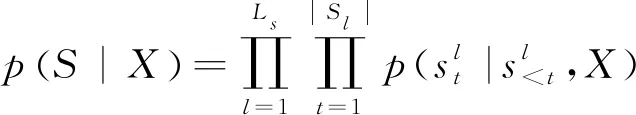
(2)


(3)
其中,y 本节主要介绍我们所提出的两阶段模型以及其训练和推断过程。 模型流程包含两个阶段: 语义框架生成和逻辑表达生成(图2)。在语义框架生成阶段,使用一个序列化的编码器来编码自然语言句子,并通过一个树形结构的解码器生成对应的语义框架;在逻辑表达生成阶段,将生成的语义框架编码成向量,并与输入句子的编码向量一起作为最终逻辑表达生成的指导信息。 图2 模型整体流程示意图左半部分表示树形结构语义框架的生成过程,右半部分表示给定语义框架下逻辑表达的解码过程。 语义框架生成部分包括一个编码器和一个树形结构的解码器。编码器把输入的自然语言句子转化成向量表示,然后由解码器生成对应的语义框架。 3.2.1 自然语言句子编码 我们采用带LSTM单元的双向循环神经网络作为输入部分的编码器。每个词的表达是对应的前向和后向LSTM单元的状态合并。对于第t个词xt,它首先由xt=WXo(xt)被映射成一个向量,其中xt代表xt的n维向量表示,o(xt)是一个代表词xt索引的one-hot向量,WX∈Rn×|VX|是词典VX的表示矩阵。在得到了xt的词向量之后,它的表示et由两个方向的隐状态向量合并得到,计算如式(4)~式(6)所示。 3.2.2 语义框架解码器 为建模语义框架的层次结构和组合语义,本文采用树形结构的解码器来生成语义框架。 该解码器先将语义框架转化为层次化的树形结构形式。我们引入一些特殊的符号来刻画语义框架的层次化结构。如图3所示,非终止符“ 图3 语义框架解码器示意图虚线框中展示了树形解码器的模型实现细节 解码器以自上而下的方式逐层生成语义框架。它首先顺序地生成树形结构语义框架的最顶层,直到“”符号生成。如果中途产生“ (7) 上下文向量如式(8)所示。 (8) 其中,W0∈R|VS|×n,W1,W2∈Rn×n,b0∈R|VS|均为参数矩阵。 逻辑表达生成主要基于自然语言输入X和第3.2节得到的语义框架S。给定X和S,逻辑表达缺失的细节需要被填补,我们同样也用编解码的框架来实现。 3.3.1 语义框架编码 本文采用和自然语言编码器一样的结构来编码语义框架。编码器将语义框架S编码成向量{α1,…α|S|}。 这些向量和由自然语言编码器得到的向量{e1,…e|X|}共同指导逻辑表达的生成。 3.3.2 逻辑表达解码器 逻辑表达中的词是由循环神经网络序列化生成的。在生成逻辑表达中第t个词yt时,其隐状态vt由式(11)、式(12)所示。 模型的训练目标是最大化给定自然语言输入下生成逻辑表达的对数似然。根据式(1),该似然可以分成语义框架似然和逻辑表达似然两部分,如式(13)所示。 (13) 其中,D是训练对的集合,每一个训练对包含一个句子和对应的逻辑形式。 本文在三个数据集上进行了实验,并将我们的方法和多个现有方法进行了对比。本节将介绍实验使用的数据集、模型的参数设置以及实验结果和分析。 本节简要介绍实验中使用的3个语义解析数据集。 JOBS 该数据集包含640个工作列表数据库的查询。每对训练样本包括一个自然语言问题及其对应的Prolog风格的查询。我们的训练—测试数据分割和文献[4]一致,其中500个实例用于训练,剩下的用于测试。为了避免低频词或未登录词带来的学习问题,我们在三个数据集上进行了参数替换[7]。在该数据集上,变量值“company”、“degree”、“language”、“platform”、“location”、“job area”和“number”都被识别并替换成特定的符号。 GEO 该数据集包含了880个美国地理数据库的查询实例。它被拆分为包含680个实例的训练集和包含200个实例的测试集。该数据集采用λ演算作为目标逻辑表达形式。在该数据集上,变量值“city”、“state”、“country”、“river”和“number”被识别并替换。 ATIS 该数据集包含5 410个对于航班预定系统的查询。数据被分割为4 480个训练实例和480个验证实例以及450个测试实例。该数据集也采用λ演算来作为目标逻辑表达形式。类似地,变量值“date”、“time”、“city”、“aircraft”、“airport”、“airline”和“number”在这个数据集中被识别并替换。 在模型训练过程中,逻辑表达需要被转化为对应的语义框架。省去低层次的参数和变量名信息,同时保留谓语、操作符以及组合信息。此外,本文中的语义框架和文献[3]不同。他们的方法所生成的谓词包含左括号,但是本文中所有谓词都保持原来的形式。这个区别在于本文所提模型能自上而下地生成层次化的语义框架,可以避免产生括号不配对等存在语法错误的语义框架。 预处理实验采用和文献[7]相同的数据预处理方式。首先根据第4.2节中描述的方法标注语义框架,然后按照第3.2节中描述的方法将其转化为树形结构。 参数配置在JOBS和GEO数据集上,模型的超参通过在训练集上的交叉验证得到,而在ATIS数据集上则是通过模型在验证集的表现来选择超参数。隐状态向量和词向量的维度从{250,300}和{150,200,250,300}中选择,dropout rate从{0.3,0.5}中选择。标签平滑参数设置为0.1。模型采用GloVe预训练词向量作为初始化。训练过程采用RMSProp作为优化器,并且从{0.002,0.005}中选择学习率。为了避免梯度爆炸的问题,参数梯度被限制小于5。Batch大小设置为64。 评价指标我们选取逻辑表达的准确率作为评价指标。准确率是指自然语言句子被正确地解析成它们的逻辑表达的百分比。 在三个数据集中,我们选择了一些之前构建的系统和方法来验证模型效果,结果分别在表1、表2、表3中展示。注意DCS+L,KCAZ13和GUSP是在问答的设定下进行实验,因此本文报告的准确率是生成正确答案的百分比。可以看到,神经语义解析方法普遍比之前统计学习的方法效果好。相比于现有的深度学习模型方法,本文提出的两阶段模型能够建模语义框架不同层次和粒度的语义,而SEQ2TREE和Seq2Act只用了一层的解码器,不能够捕获不同层次的语义。总的来说,本文提出的模型在JOBS和ATIS数据集上得到了最好的结果,在GEO数据集上和目前最好的效果相当。这些结果也表明了模型的有效性。 表1 JOBS数据集的准确率 表2 GEO数据集的准确率 表3 ATIS数据集的准确率 我们进一步分析了语义框架生成的准确率来解释效果提升的原因。分别将本文模型和Coarse2fine模型生成的语义框架与标准答案进行比对,并将两个模型的生成准确率记录在表4中。Coarse2fine用序列化的方式生成语义框架,而我们采用了树形结构的解码器。在JOBS、GEO、ATIS三个数据集上,本文所提模型的生成准确率都明显优于Coarse2fine模型。这说明树形结构解码器能够更好地捕获语义框架的层次化结构,在语义解析任务上取得更高的准确率。 表4 语义框架的准确率 我们通过一个例子说明树形结构的语义框架能够更好地描述逻辑表达组合语义的原因。给定一个输入句子“whatistheearliestarriveflightfromci0toci1”,树形解码器通过两个轮次生成语义框架。在第一个轮次,模型生成语义框架的最顶层“argmin#1 此外,对于这个例子,我们发现Coarse2fine[3]模型错误地将语义框架中的“arrival_time@1”生成为“departure_time@1”。这是因为在训练数据中,大部分查询都是在问询航班离开的时间,使得序列化解码器在生成语义框架时更倾向于生成 “departure_time@1”。相比之下,本文使用的树形结构解码器在不同解码层生成序列“andflight@1from@2to@2”和“argmin#1 本文中,我们提出生成树形结构的语义框架来更好地捕获自然语言表达中蕴含的组合语义。首先使用树形结构解码器自上而下地生成语义框架,再将生成的语义框架与自然语言句子结合来指导最终逻辑表达的生成。树形结构解码器能更好地捕获语义框架的层次化结构,进而生成更精确的语义框架。实验结果显示,模型在语义框架生成和逻辑表达生成这两阶段的准确率都有所提升。此外,我们通过案例分析进一步说明了树形结构语义框架的好处。未来工作方面,我们将研究小标注样本下的语义解析问题。3 模型
3.1 模型概览

3.2 语义框架生成
”符号和“<(>”符号被分别用来标识解码顶层语义框架和各级子树的起始状态,“”符号被用来标识解码过程的终止。
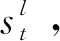

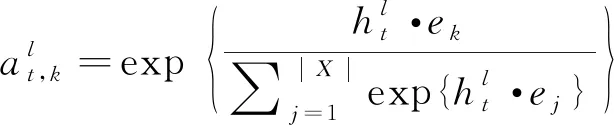


3.3 逻辑表达生成
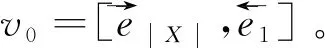

3.4 模型训练和推断


4 实验
4.1 数据集
4.2 语义框架标注
4.3 实验设置
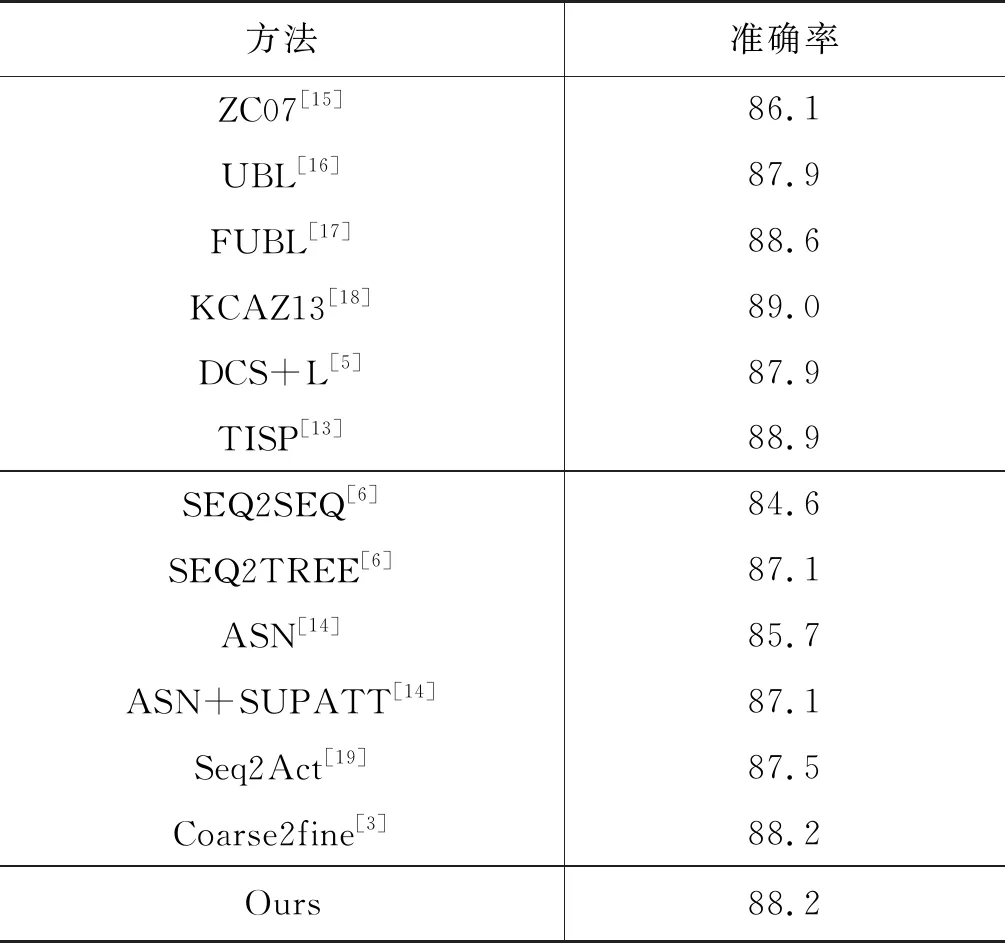
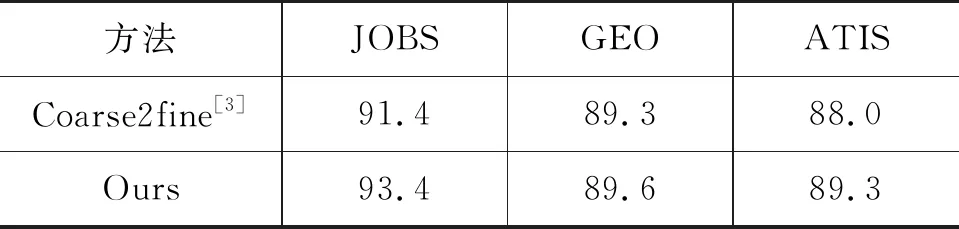
4.4 实验结果分析


4.5 树形结构的语义框架分析
5 总结与展望
猜你喜欢
中国石油石化(2022年12期)2022-07-16
河北果树(2022年1期)2022-02-16
小学生必读(低年级版)(2021年10期)2022-01-18
烟台果树(2021年2期)2021-07-21
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
