
基于序列模型的单文档标题生成研究
2021-03-18 02:53焦利颖俞晓明程学旗
中文信息学报 2021年1期
焦利颖,郭 岩,刘 悦,俞晓明,程学旗
(1. 中国科学院大学,北京 100049;2. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190)
0 引言
正文单句摘要是在摘要的长度上对生成的句子做了限制,即只有一个句子,标题往往在新闻中指的是对其内容加以概括或评价的简短文字,在长度上也和一句话相当。本文把新闻的标题作为单句摘要生成的标签,把单句摘要看作新闻的标题,因此本文对标题和单句摘要两者概念不作区分,以下内容中均使用“标题”这一概念,本文研究让程序为单文档自动生成标题。
标题生成有巨大的应用价值和广泛的应用前景,例如电子邮件的摘要自动生成、移动设备中的文本压缩等,尤其适用于解决标题党新闻问题。如图1所示,标题党新闻指网络中故意用较为夸张、耸动的文章标题以吸引网友点击观看文章或帖子的人,特别是与用实际上与内容完全无关或联系不大的文字当标题者[1]。如果能够为这样的标题党新闻自动生成言简意赅的新标题,用于替代原有标题,则可以达到为用户提示实质性信息的目的。
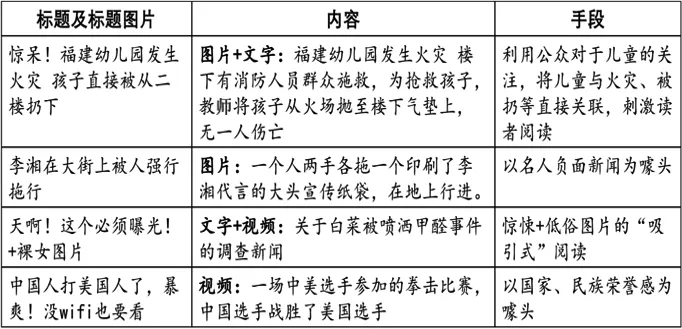
图1 标题党新闻统计示意图
标题生成方法分为抽取式和生成式两种。抽取式方法把原文档的词语或者句子作为标题生成的候选词项,使用句子压缩、拼接等方法合成标题。由于标题具有高度概括的特点,抽取式方法无法得到信息量较高的标题。
相比抽取式方法,生成式方法更适合标题生成。目前主流的生成式方法主要流程包括: 截取新闻文章的首段作为输入,使用新闻标题作为标签,构造一个大型的标题训练数据集;使用序列建模方法结合注意力机制,训练得到标题生成模型。使用序列建模进行标题生成建模,省去了人工构建特征的繁琐工作,完全基于训练数据学习词语的嵌入表达和权重参数。但是序列模型的建模特点对输入文本的长度有一定的限制,因此已有方法大多使用新闻的首段内容作为输入来训练摘要生成模型,但这样不能充分利用新闻信息。例如,CNN和NY Times等权威新闻网站,刊登的新闻报道篇幅较长,句子和词语数量较大,如果只使用首段内容作为训练模型的有效输入文本,忽略了新闻文章本身大部分的文本信息,会对生成的标题所涵盖的信息量造成一定程度的损失。但如果使用整篇文章作为训练模型的输入,则会大大增加模型的复杂度和训练难度,甚至会导致模型性能的下降。为了更多地使用新闻信息,本文提出一种基于关键信息指导的新闻标题生成算法。
算法中的关键信息不仅包括主流方法中通常使用的新闻首段句子,而且包括新闻后续内容中有实质信息的句子,以及句子中的重点词语。首先获取关键信息,即从句子层级和词语层级获取新闻的关键信息;然后使用获取到的关键信息指导标题生成,即使用广泛应用于自然语言生成的基于注意力机制的编码解码模型,在解码端计算注意力分布时把上一步获取到的关键信息考虑在内,从而使模型既能够考虑原文档的单词,又能考虑人工提取的关键信息。最后通过实验验证了算法的有效性。实验结果表明,在一定长度内尽可能多地使用新闻内容对新闻标题生成的效果有显著提升。
1 研究现状
Radev等人首次对摘要做出定义[2]: 摘要是由一个或多个文本生成的另一个文本,能够传达原始文本重要信息,长度不超过且通常远小于原文本的一半。文档摘要生成是自然语言生成任务中的一个子领域。文档摘要按照输入的文档数目可以分为单文档摘要和多文档摘要;按照生成摘要的长度,单文档摘要又可以分为标题生成和多句摘要生成。本文重点研究单文档摘要的标题自动生成。标题生成属于文本摘要生成任务,生成的摘要是一个句子。
标题生成的方法有抽取式和生成式两种。早期的做法集中在抽取式方法,从统计概率角度进行关键短语、句子或者段落的抽取。新闻标题生成可以从原文档抽取第一句作为标题,该方法一般作为基准方法与其他方法进行比较。抽取式方法存在的问题是无法生成比抽取出的最小跨度文本更短的连贯摘要,例如若抽取的是句子,则无法得到比最短句子长度小的标题[3]。后续的标题生成研究更多关注生成式方法。有的方法从原文档中选取一组包含重要信息的句子,然后利用句子压缩技术实现标题生成[4-5]。还有的方法提取一组包含原文档信息的短语,然后利用句子合成技术进行标题生成[6-7]。
抽取式和生成式标题生成各有优缺点。抽取式方法可以生成可读性更高的标题,因为最终标题是通过抽取并拼接出人类直接书写的句子得出的。然而由于原文档句子重点信息分布稀疏,高度概括的词语提取较为困难,因此抽取式方法得到的标题信息量较少[8]。相比之下,生成式方法得到的标题长度较短,且具有高度概括的特点,因此吸引了更多研究者的关注。但是生成式方法使用短语作为基本处理单元,通常仅基于一组语法信息较少的句子生成标题,所以句子合成的结果仍然不够准确[9],即生成式方法难以确保生成标题的语法正确性。因此生成式方法仍然需要投入更多的研究。
神经网络的深度学习建模方法让自然语言处理任务进入新阶段。由于语言本身具有时序特性,因此比较适合序列建模[10]。基于数据驱动的序列建模省去了人工构造特征的过程,大大简化了人工的干预。在机器翻译领域,结合注意力机制的神经网络翻译序列模型取得了较好的效果[11-12]。与机器翻译相同,摘要生成也属于自然语言生成任务的范畴,是从源句子到目标句子的一种转化,因此有的研究者提出借鉴基于神经网络的机器翻译方法,使用带有注意力机制的序列模型先对新闻编码,然后解码,最后生成新闻标题的研究工作,取得了较好的效果[13]。文献[14]利用语义信息,结合基于注意力机制的编码解码模型,提升了标题生成的质量。同时,标题生成过程中外部信息也起到一定的辅助作用,文献[15]认为某个话题下的文章标题有一定的格式,比如经济话题下的文章标题是因果关系,社会事件话题下的文章标题包含时间、地点等,因此作者把话题信息融入到标题生成的序列模型中,生成了话题集中的标题。可见在标题生成方面,如何利用更多的新闻信息来提升标题生成的质量,仍有较大的研究空间。
2 基于关键信息指导的标题生成
2.1 问题描述
本节使用形式化的语言对问题进行描述。如表1 所示,文档d是一个句子序列{s1,s2,…,sn},si对应原文档中的第i个句子,这里的句子按照英文的语法进行分句。任意第i个句子是一个词语序列{wi1,wi2, ...,wim},wij对应第i个句子中的第j个词语。从定义中不难看出,一篇文档包含词语级别和句子级别两个层次结构。为了统一规范,本文后续符号如果和上述问题定义中相同,那么这些符号含义和上述形式化定义中的含义保持一致。

表1 标题生成形式化定义
本文任务的输出是只有一个句子的标题,并且输出的句子和原文档中的句子没有重复,在词语级别上可能存在部分交集。文献[4]指出: 输出的句子t需要描述新闻文章的主题或者新闻文章的事件。在如图2所示的一篇新闻中,加黑标识的标题表明了新闻的主旨,即关于华为公司,同时又表明本篇作者对华为公司崛起这一事件的否定消极态度。上述分析表明图2的标题完整起到了传达主旨和态度的作用,是一个典型的合格标题(新闻观点不代表本文作者立场)。标题生成的目标是至少要体现一篇新闻的叙述主题,或者叙述关键人物,这种主题或者人物往往是一个词语或者短语,并且这种词语或者短语通常是新闻中的原词语,比如图2中的“华为”便是本文的关键主语。

图2 新闻页面示意图
已有的标题生成方法大多使用新闻文章的首句内容进行标题的生成,存在一定的缺陷。从表1形式化定义看出,如果只使用新闻的首句内容,那么在模型的训练过程中,实际的模型输入从{s1,s2,s3,…,sn}截取成为{s1,s2,s3},图1所示的内容中如果只是用第一句作为输入,那么第一句的词语个数仅比标题的词语个数多了两个,虽然新闻的第一句体现了新闻的主旨,但是没有体现新闻作者的观点,新闻作者的观点在第二段中的某些词语比如“naked”(赤裸裸的)和“questionable”(可疑的)等有所体现,这些词语表明新闻作者的负面观点。
从上述例子可以看到,被截取的新闻内容和标题信息相关,并且对标题做了进一步的阐述,但是在模型训练中并没有使用,导致生成的标题所覆盖的信息量有所损失。本文重点解决该问题。
2.2 算法思路
为了满足序列模型能够处理的文本长度的限制,同时在模型训练过程中能够捕获到更多的新闻内容,算法中要解决的关键问题是如何更多地获取和使用新闻信息。新闻有词语和句子两种不同的层次,因此关键问题可以细化为三个: 如何分别获取句子级别和词语级别的关键信息,以及如何使用这些关键信息。下面详细阐述对这三个关键问题的解决思路。
2.2.1 句子级别关键信息的获取
句子级别关键信息包括新闻首段句子,以及新闻后续内容中有实质信息的句子。可以采取以下三种候选方式获取句子级别的关键信息。
(1) 句子级别关键信息获取的候选方式
第一种: 直接使用新闻的首段内容作为句子级别的关键信息,本文称其为lead_para方式。
现有算法使用首段内容作为输入,训练标题生成模型,这种方式也是当前主流方法使用的策略。一篇新闻通常在首段中进行整体的阐述,让读者最快地根据新闻标题以及首段内容获取新闻的主要信息和新闻本身传达的观点。因此使用新闻首段内容获取句子级别的关键信息是很直观的想法
第二种: 尽可能截取实际训练中最大编码长度的文本作为句子级别的关键信息,本文称其为leadk方式。
这种方式是从编码模型实际计算角度出发,考虑到编码模型需要设置最大编码长度,因此存在首段内容超过编码长度或者小于编码长度的情况,当编码内容长度超过编码时间步长时,直接截取超出的内容,反之则在缺失的句子后面拼接上固定填充词。这样做可以在编码时充分利用新闻信息。
第三种: 使用无监督的图排序方法,从新闻中选择关键句子并进行排序,得到句子级别的关键信息,本文称其为text_rank_k方式。
TextRank算法[16]基于PageRank网页重要性评价算法,用于文章的抽取式摘要和文章的关键词提取。text_rank_k方式对新闻使用TextRank算法进行句子重要性的排序,然后根据句子重要性截取最大编码长度的词语子序列。
(2) 句子级别关键信息获取方式的选择
本节将从上述三种候选方式中选择最优的一个作为本文算法使用的句子级别关键信息。我们使用如图3所示的网络结构[17],分别使用上述三种句子级别的候选关键信息作为输入,训练得到一个标题生成模型,以模型的性能好坏为标准选择相对最优的句子级别关键信息获取方式。
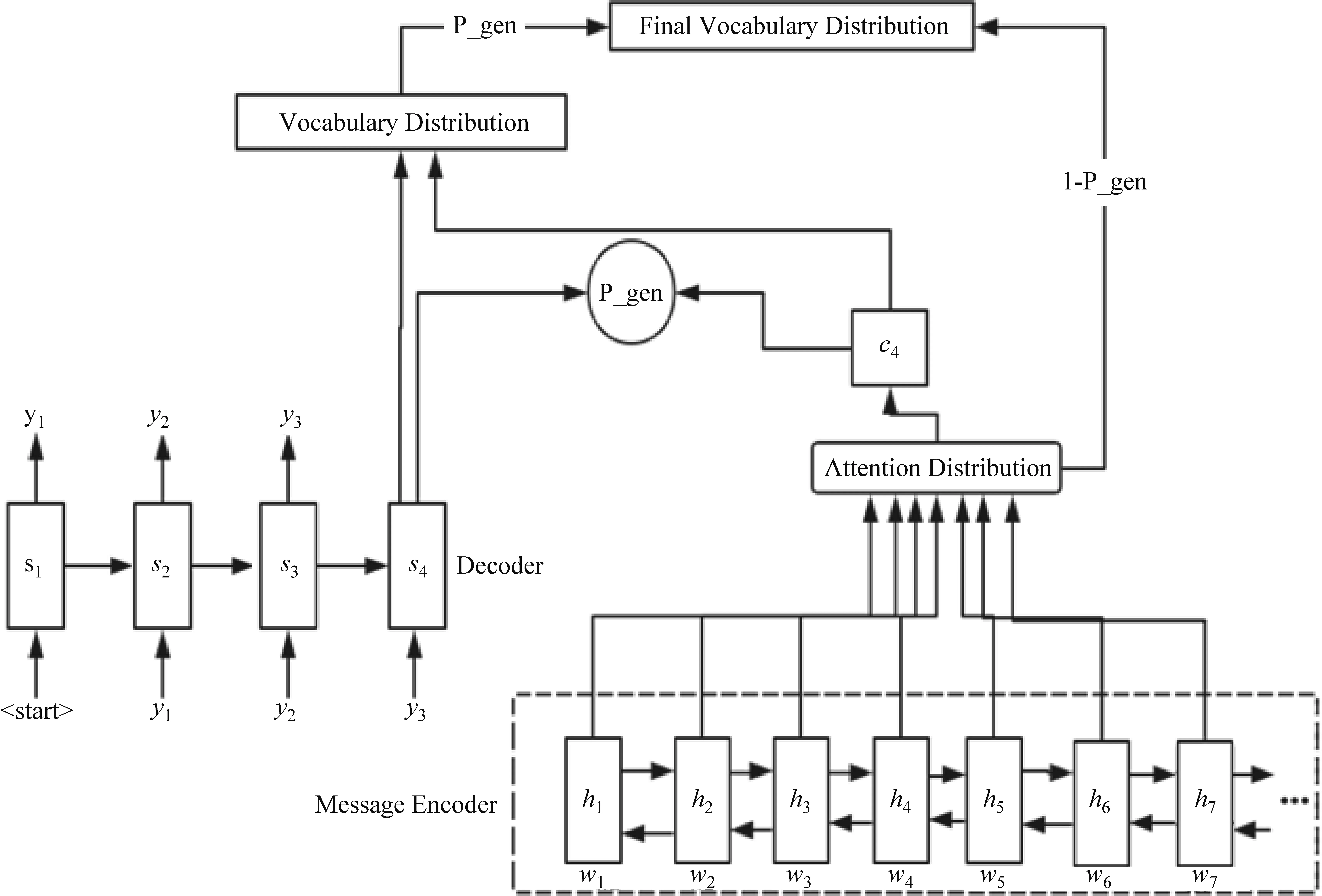
图3 结合复制机制与注意力机制的编码解码模型
图3所示的网络结构使用的是结合注意力机制和复制机制的编码解码模型。其中,编码部分和解码部分是两个序列模型。编码部分使用双向编码,解码部分使用单向解码。注意力机制模块的作用是在每一个解码时间步生成对应的上下文向量(context vector),从而在第t时间步解码时生成依赖特定编码时间步的编码隐向量。复制机制模块的功能是解决无法生成词汇表外词语的问题,在解码时,可以生成存在于输入文本但是在词汇表以外的词语,这部分词语称为文中词汇表外词语(words in article but not in vocabulary)。复制机制使模型生成更多的词语,提升了模型性能。
实验结果表明,第二种方式leadk能够达到相对较好的效果。因此,本文提出的标题生成算法中,使用实际训练中最大编码长度的文本作为句子级别的关键信息。
2.2.2 词语级别关键信息的获取
本文从整篇新闻文档中提取关键词语,作为词语级别的关键信息,提取方式使用TextRank算法。关键词抽取的计算方式与句子排序类似,都是无监督的图排序方法。需要构建一个图网络,然后对图中顶点进行排序。和句子排序相比,关键词抽取的不同之处在于其是一个无向无权图,图中顶点是一个语义单元,两个顶点之间根据在一个固定窗口下是否共现判断是否存在边。首先对词语词干化,对每一个词语进行词性标注,只使用名词和形容词,过滤掉其他词性的词语。为了避免图的过大增长,我们使用单个词语作为一个候选语义单元,作为图中的一个顶点。这里使用单词作为图的顶点。每一个顶点的初始权重设置为1,迭代直至收敛。根据节点最终得分降序排列,取top-T的顶点,这里T=10。
2.2.3 关键信息的使用
本节介绍如何把上述获得的关键信息用于新闻标题的生成。
我们在对句子级别关键信息进行编码的同时,增加对词语级别关键信息的编码步骤,从而能够在解码生成标题的词语时,额外考虑到词语级别的关键信息对生成内容的指导作用。使用的网络结构如图4所示。
我们使用句子级别关键信息和词语级别关键信息作为输入,用于新闻标题生成模型的训练,因此不同于表1,标题生成的形式化定义如表2所示。

表2 标题生成形式化定义
图4中的双向编码的序列模型,使用的是LSTM计算单元。注意力机制和目标函数与句子级保持一致,这里不再赘述。不同于直接用关键词语编码向量kj计算生成概率[18],图中对关键词语序列{x1,x2,…,x5},类比注意力机制在解码时上下文向量c4的计算方式,获取关键词向量o4的所有关键词权重计算如式(1)所示。
其中,si-1是上一个解码时间步的输出,hT是新闻信息最后一个编码时间步的结果,我们通过使用输入信息的最终编码结果,强化了输入信息相关的关键词语,使得最终的关键词编码和输入信息更加相关,最终的关键词编码结果类似注意力机制的上下文向量计算方式,即每个隐状态向量的加权和。
把式(2)的计算结果oi用于改进复制机制和生成词汇表词语方式,计算当前解码操作下,从词汇表选择词语的概率,计算如式(3)所示。

(3)
词汇生成概率计算方式如式(4)所示。
Pvocab(w)=softmax(V′(V[st,ct,ot]+b)+b′)
(4)
2.3 算法描述
基于上述算法思路,本文提出一种基于关键信息指导的标题生成算法。该算法的流程如图5所示。
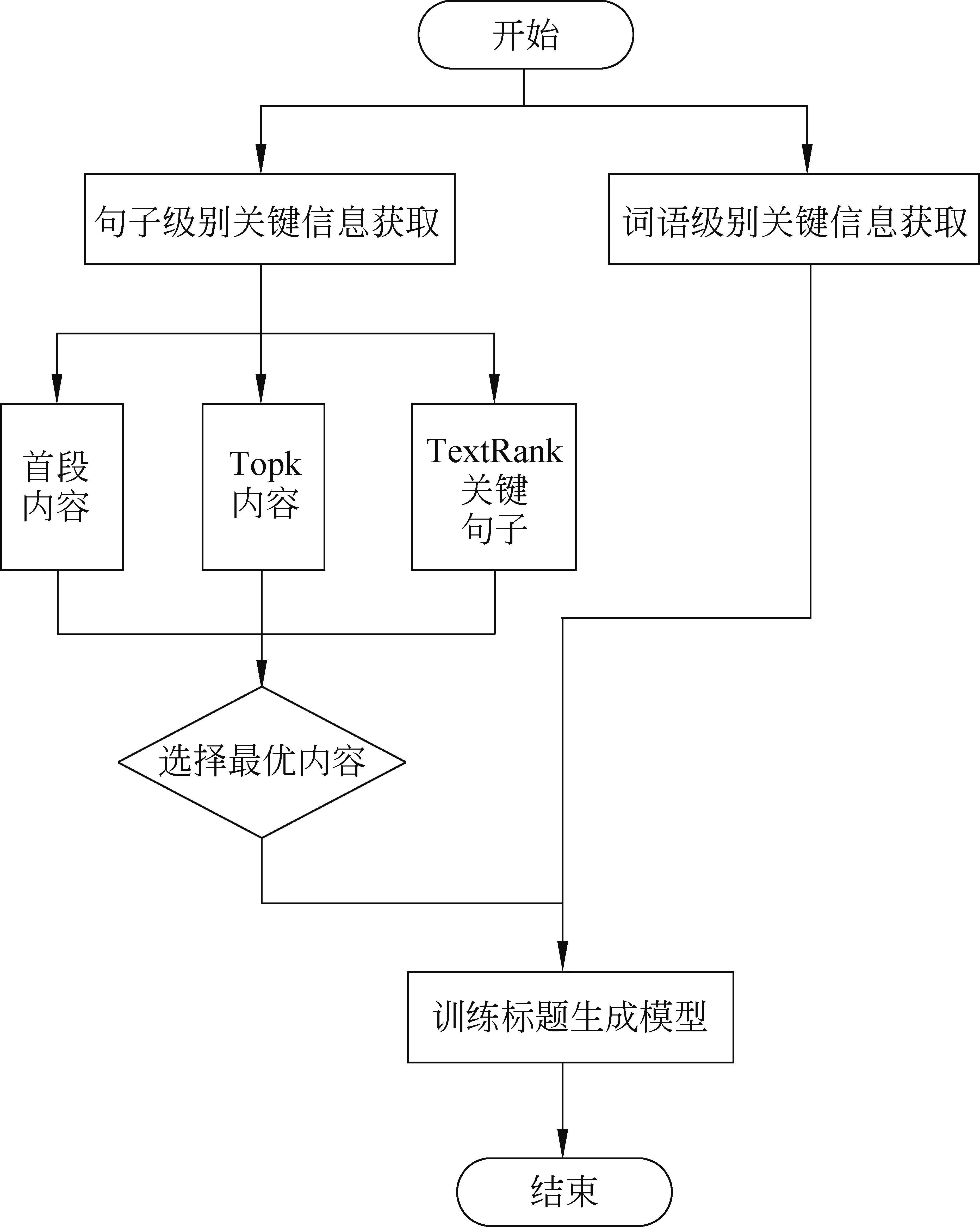
图5 基于关键信息指导的标题生成算法流程图
输入: 一篇新闻文档
输出: 新闻标题生成模型
操作步骤:
(1) 获取句子级别关键信息: 从新闻的首句扩展到前k个句子,作为句子级别的关键信息。
(2) 获取词语级别关键信息: 从新闻文档中提取新闻的关键词语,得到一个词语序列,作为词语级别的关键信息。
(3) 生成模型: 把上述两步的关键信息作为输入,训练标题生成模型。
3 实验
3.1 数据集
实验采用的数据集从纽约时代报刊数据集中获取。纽约时代报刊数据集中共包含180万篇新闻,我们首先从中随机采样四分之一,得到大约45万篇新闻,然后从中过滤掉标题长度小于3或者大于15,并且文本长度小于20或者大于2 000的新闻,最后从过滤后的数据集中随机选择2 000篇新闻作为验证集和测试集。
本实验的数据集统计信息如表3所示。可见新闻标题平均长度(title: avg token)只有8个词语左右,其中标点符号也包含在内。另外,首段信息的平均长度(lead avg token)只有80个词语左右,相比于我们在训练模型中的最大编码长度取值100时,把编码长度内的所有数据进行编码,少使用了接近20个词语。
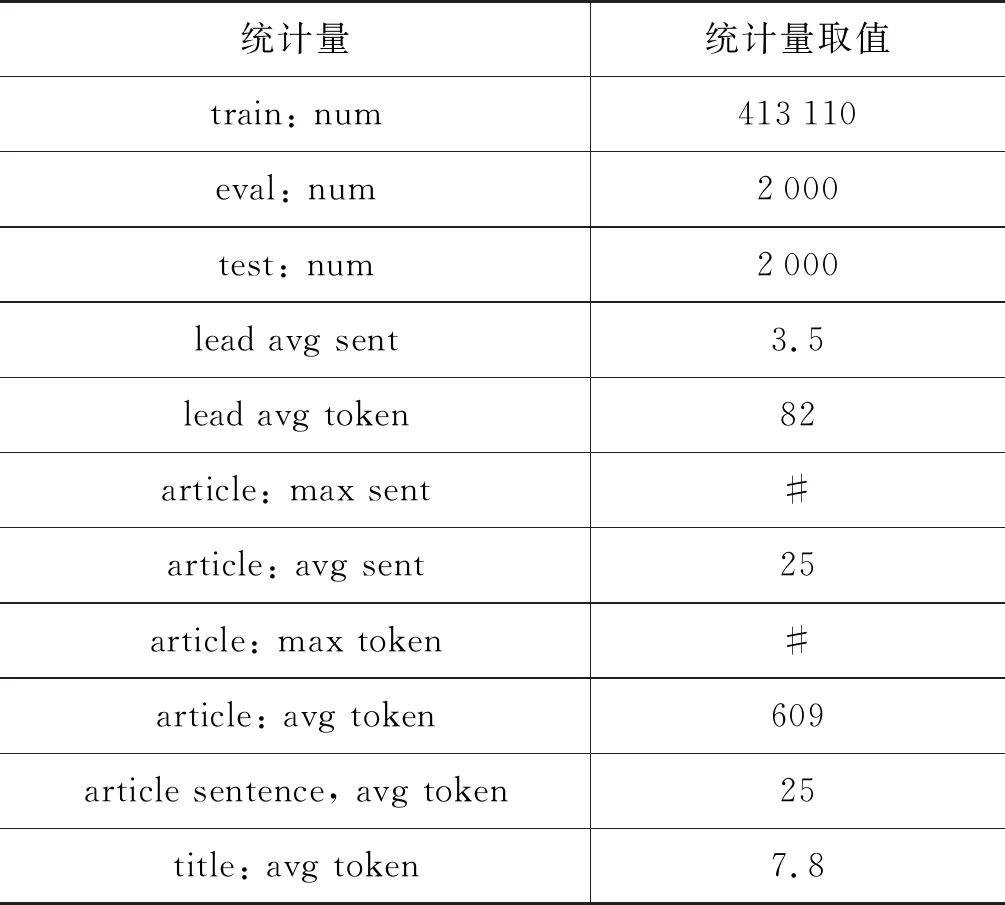
表3 数据集统计信息
3.2 句子级别关键信息获取方式的选择
为了选择相对最优的句子级别的关键信息,我们设计了实验,把三种句子级别的关键信息分别用于标题生成模型的训练,对比其生成的结果。
按照2.2节所介绍的的三个步骤,分别从原文档中抽取出三种类型的数据,因为评级摘要生成质量的ROUGE指标本质是计算文本的召回情况,所以接下来我们统计抽取的数据中标题词语的召回数目和召回率,统计结果如表4所示。leadk方式表示取文章前k个词语构成的句子序列,这里k=100。text_rank_k表示使用textrank算法按照句子重要性从高到低排序后,取前k个词语构成的序列,这里k=100。从表4可以看到,leadk方式,即直接取文章词语序列的前k个构成的子序列,召回标题中的词语数目最多。这个统计结果说明新闻标题更容易受到新闻前面句子的影响,首段内容包含的信息较多,但是有一定的信息丢失,第二段的起始信息对标题生成也有重要指导作用。
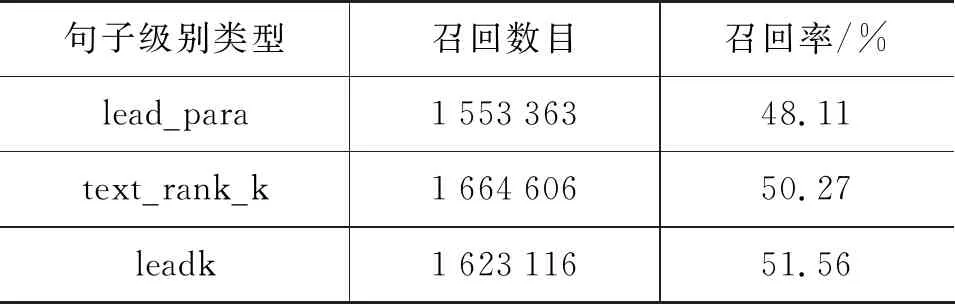
表 4 三种句子级别信息对标题词语召回统计
使用上述三种方式获取的重点句子构建<文章,标题>对,这里使用同一种模型,模型如图3所示。模型采用注意力机制结合复制机制,各自训练至收敛,对比标题生成性能,结果如表5所示,表中的句子级别类型与表4中的保持一致。从表中可以看到直接取文章前100个词语构成的句子训练出的标题得分最高。同时也可以看到,得分高低和表4的召回率呈现正相关。这个结果说明不同的句子级别包含有不同的信息量,并且对标题生成效果会产生一定的影响,其中包含更多内容的输入信息具有更好的生成效果。

表5 三种句子级别信息的标题生成结果
分析实验结果,我们选择尽可能截取实际训练中最大编码长度文本的leadk方案,作为句子级别的关键信息获取方式。
3.3 关键信息的使用效果验证
为了验证在基于序列模型的标题生成过程中使用关键信息的效果,我们设计了实验,即把3.2节中选出的句子级别关键信息,以及词语级别的关键信息用于标题生成模型的训练,对比算法是把新闻第一句直接作为标题的生成方法,本文称其为lead1。
按照2.2.2节说明的步骤获取每一篇新闻的关键词语序列,结合2.2.1节中的leadk句子,构成<新闻-关键词,标题>的训练数据集合。然后按照如图4所示网络结构图训练基于关键词指导的标题生成模型,该模型的标题生成效果如表6中的leadk_with_key_word所示。使用leadk句子级别信息训练出的模型性能和lead1句子级别信息相比,有了较大的提升。同时在leadk句子级别信息基础上,使用关键词语序列作为额外的输入,对标题的生成有一定程度的改善。
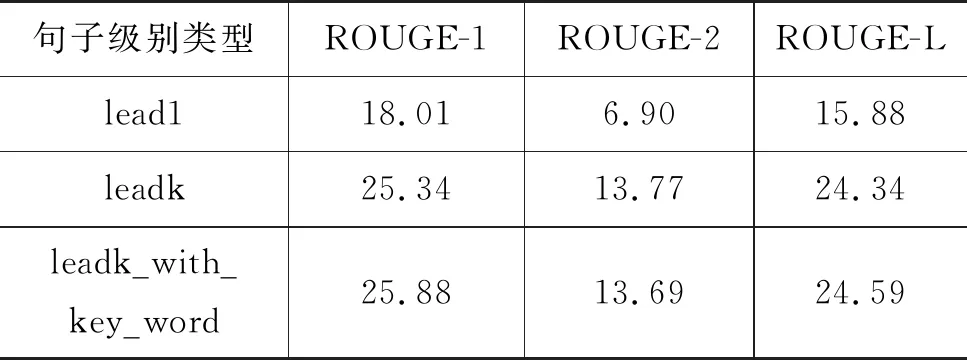
表6 标题生成评估结果
4 结论与展望
为了解决标题生成中数据使用率不高的问题,本文提出基于关键信息指导的标题生成算法。实验表明,在基于序列模型生成标题时,在一定长度内尽可能多地使用新闻内容能够有效提升新闻标题生成的效果。下一步工作将尝试层次编码的方案,对新闻进行更高程度的压缩,从而生成概括程度更高的标题。
猜你喜欢
中老年保健(2022年1期)2022-08-17
客联(2022年3期)2022-05-31
基层中医药(2021年8期)2021-11-02
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
中国新闻周刊(2021年26期)2021-07-27
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
信息安全研究(2016年4期)2016-12-01
