
融合主题模型及双语词向量的汉缅双语可比文档获取方法
2021-03-18 02:53李训宇毛存礼余正涛高盛祥王振晗张亚飞
中文信息学报 2021年1期
李训宇, 毛存礼, 余正涛, 高盛祥, 王振晗, 张亚飞
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
缅甸语属于资源稀缺型语言,故汉缅平行语料比较少。但互联网上存在一些主题相关,内容相似的汉缅双语可比新闻文档,这些双语新闻是抽取双语平行词汇、双语平行句对的重要数据资源。
获取双语可比文档的核心思想是计算双语文档的相似度,目前针对双语文档相似度的计算问题,主要有以下四类方法: ①基于词典匹配的方法,这类方法的思想是利用词典把跨语言文本转换为中间层语言计算文档相似度,例如,Steinberger等人[1]提出一种中间层语言思想,使用多语言词典EUROVOC计算英文和西班牙文的文本相似度;石杰等人[2]利用语义词典WordNet将中文和泰文文本转换为中间层语言,计算中泰文本相似度,从而得到中泰可比语料。②基于机器翻译模型方法,这类方法的思想是将源语言翻译成目标语言,计算跨语言文档的相似度,如王洪俊等人[3]提出基于统计翻译模型,计算文档互译词对数,改进Dice相似度计算方法进行双语文档相似度计算;Barrón-Cedeo等人[4]基于统计翻译模型提出CLiPA(cross-lingual plagiarism analysis)方法,根据贝叶斯原理估算两种语言文档互译的概率; Maike等人[5]将源语言文本翻译成目标语言文本,然后在目标语言空间中计算相似度,从而获取可比文档,Otero等人[6]通过维基百科中跨语言链接获得翻译等价对,从而获取双语可比文档。③基于跨语言主题的方法,跨语言主题模型的优势是可以从语义上进行匹配,计算相似度,从而获取双语可比文档,如Yuan等人[7]从维基百科上抽取汉藏实体扩展汉藏词典,利用LDA将文本映射到主题的特征空间上,然后根据新闻文本的特点计算跨语言文本相似性;Ni等人[8]提出ML-LDA (multilingual topic—latent dirichlet allocation)模型从维基百科平行语料中提取主题,每个主题可以由多种语言表示,使得多语言文档可以用统一的主题表示; Zhu等人[9]使用中文和英文两种语言的话题模型预测文档的话题结构,基于文档的语义信息对相似文档进行匹配。④基于双语词向量的方法,这类方法的思想是将双语文档各自训练单语词向量,然后共享到语义空间得到双语文档向量来计算跨语言文档的相似度,如Che等人[10]提出了一种基于双语词嵌入的双语文档相似度计算方法,训练双语文档向量,通过计算文档之间的距离来得到文档中的相似度。上述计算跨语言文档相似度的方法都取得了很好的效果,然而基于词典匹配的方法不能解决未登录词问题;机器翻译模型的方法需要建立大规模对齐语料库,并且过度依赖翻译效果;使用跨语言主题的方法需要构建双语主题模型,而构建双语主题模型需要大量的标记的双语平行语料。缅甸语属于资源稀缺型语言,汉—缅平行语料较少,汉—缅的翻译效果也不理想,因此上述方法并不适用于缅甸语这种低资源语言。针对单语主题模型和双语词向量的特点,本文提出基于主题模型及双语词向量模型,将主题模型抽取到的汉、缅主题进行表征,映射到同一语义空间,得到主题词向量,在该向量空间内使用余弦相似度方法计算汉缅主题相似度。
1 融合主题模型及双语词向量的汉缅文档相似度计算模型
1.1 融合主题模型和双语词向量的汉缅双语可比文档获取模型
LDA[11]是一种描述文档之间全局关系的方法,基于预训练BERT模型[12]是一种考虑词语位置关系以及上下文语义的模型,能够有效解决一词多义的问题。因此,本文结合这两种技术,使用更全面的向量来表示主题和文档。如图1所示,首先利用单语LDA模型抽取汉语、缅甸语文章的主题,再将抽取到的主题词进行表征,得到汉、缅单语主题词向量,利用汉缅词典将汉、缅单语主题词向量映射到共享的语义空间,得到汉缅双语主题词向量,最后计算汉缅主题的相似度。
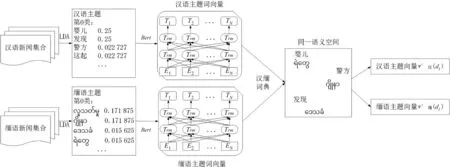
图1 融合LDA和双语词向量的汉缅双语文档相似度计算模型
1.2 基于LDA主题模型的文档主题表示
LDA模型是一种离散集合的数据聚类,能够有效地对文本中隐含的主题信息进行抽取,且有着极高的执行效率,其模型如图2所示。其中,α、β表示超参数,w表示文档中的词语,z表示文档的某个主题,N表示词语的个数,M表示文档的个数以及θ表示一篇文档中的主题分布。
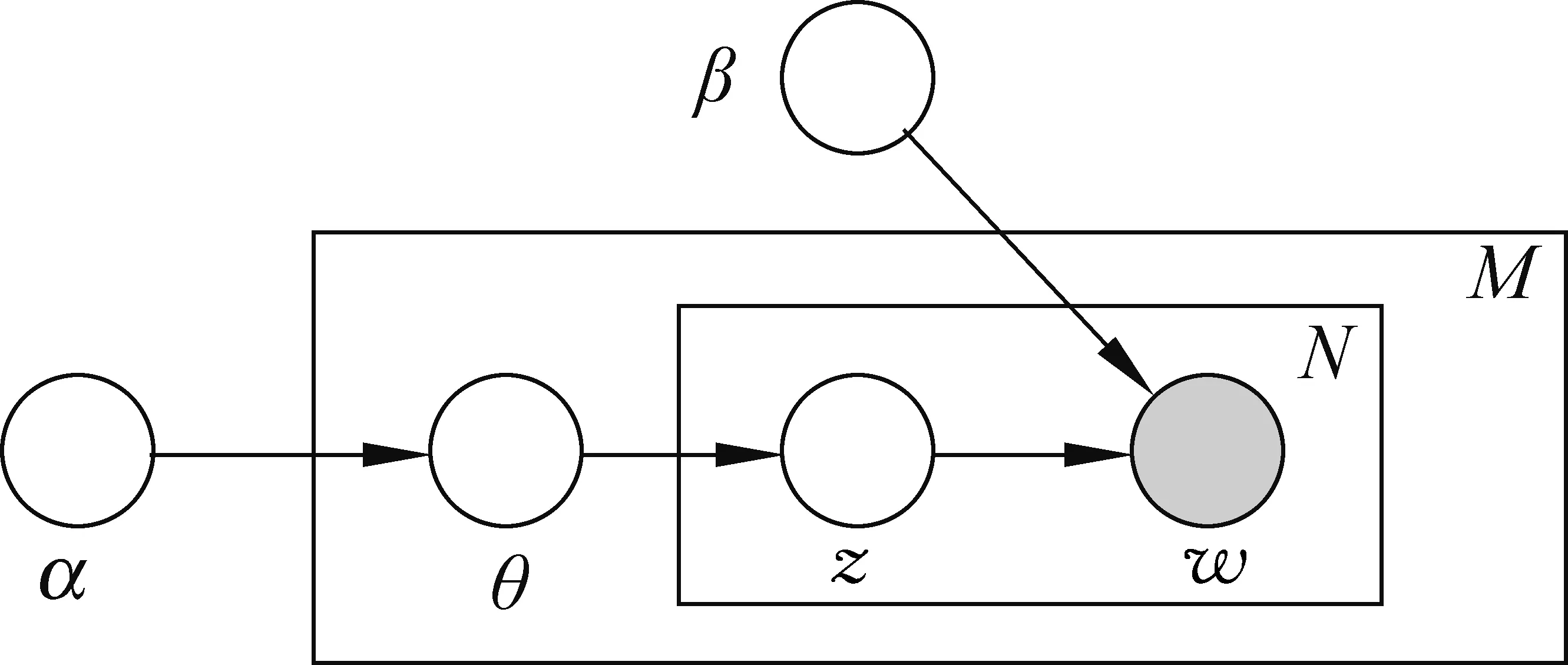
图2 LDA概率模型图
如图所示,给出汉缅新闻文章集合D汉={d1,d2,…,dn}和D缅={d1,d2,…,dn},从文本—主题分布中学习参数θ=Dir(α);然后抽取一个主题zji~Multinomidal(θ);接着从条件概率分布p(wji|zji,φ)中抽取一个词wji,p为在主题zji下的一个多项式概率分布。
在上述的一次抽取迭代中,Dir(α)表示参数为α的狄利克雷分布,其概率密度函数如式(1)所示。
其中,θ=(θ1,…,θk),α=(α1,…,αk),Γ(·)为Gamma函数,multinomial(θ)表示一个参数为θ的多项分布,其概率密度函数如式(2)所示。
其中,θ=(θ1,…,θk)。
采用Gibbs采样方法[13]来估计文本的zji的后验分布,从而得到模型参数θ。
通过上述过程最终得到汉、缅新闻文档的各自潜在的主题ti和每个主题中的单词概率,例如,
t汉1{婴儿0.25,发现0.25,警方0.022 727},
因为每个主题都会包含很多个单词,所以为了更好地生成主题向量,我们取出概率最高的m个单词进行归一化处理,重新计算每个词的权重,如式(3)所示。
其中,θi是主题模型抽取出每个主题下每个单词的概率,ωi是归一化后每个单词的权重。
在得到汉、缅主题及主题词分布后,将汉、缅主题词进行表征并映射到共享的语义空间中,得到汉缅双语主题词向量。
1.3 汉缅主题词向量共享语义空间映射
在得到主题及主题词分布后,对汉、缅主题词进行词向量训练,获得汉、缅单语词向量。由于词语的语义跟具体的上下文有密切的关系,而静态词向量生成方式,如Word2Vec[14-15],得到的词向量没有考虑词语在句子中上下文的信息,每个词语在任何场景中使用的词向量都是固定不变的值,显然无法解决一词多义的问题。而基于BERT预训练模型生成的词向量是一种动态的形式,也就是能够根据词语所在上下文的语义特征得到对应的词向量。因为BERT的设计基于Transformer[16]网络结构,能够根据当前的文本输入,分别计算Key、Query、Value向量,并基于上述向量对每个输入使用注意力机制,以获得当前输入与上下文语义的关系和自身所包含的信息,并通过多层累加和多头注意力机制,不断获取当前输入更为合适的向量表示。为此,本文采用Google开源的BERT模型来训练词向量以便能更有效地表征词语在文本中的语义特征。通过上述过程,最终得到汉语的主题词向量vt汉以及缅甸语主题词向量vt缅。
通过BERT模型训练方法得到汉语词嵌入矩阵S和缅语词嵌入矩阵T后,利用种子词典M,借鉴Artetxe等人[17]的方法,通过SVD学习线性转换矩阵W,找到最佳映射矩阵W*后,使用W矩阵对汉语词嵌入矩阵S进行线性变换,得到S′=SW,使汉语词向量跟缅甸语词向量分布在同一个向量空间,使得SiW与目标词嵌入Tj相近,如式(4)所示。
其中,Mij=1时代表缅语中的第j个单词是汉语中第i个单词的翻译。Si代表第i个源语言的词嵌入,Tj代表第j个目标语言的词嵌入。在得到最佳映射矩阵W*后,就可以将汉、缅单语词向量映射到同一语义空间中,从而获取汉缅双语主题词向量。得到汉缅双语主题词向量后,利用余弦相似度方法计算汉、缅主题词向量的相似度。
汉缅双语词向量学习过程如图3所示。

图3 汉缅双语词向量学习过程
1.4 融合主题模型和双语词向量的汉缅双语文档相似度计算
常见的相似度计算有余弦相似度、Dice系数、Jaccard系数等,考虑到余弦相似度方法在两个向量相差较大时效果要优于Dice方法,而Jaccard和Dice算法性质比较接近。故只选取余弦相似度作为本文的相似度计算方法。
通过图3的学习过程得到汉缅双语主题词向量后,我们对每个主题下取出的前m个高概率的词重新进行归一化处理,再对归一化后每个词的权重与得到的汉缅主题词向量相乘求和来计算主题向量v′j(ti),如式(5)所示。
其中,ωin表示第i个单词归一化之后的权重,v(win) 是第i个单词的词向量。
最后利用余弦相似度计算方法计算汉语主题向量和缅甸语主题向量的相似度来得到汉缅两篇文章的相似度,如式(6)所示。
其中,v′t汉表示加权后的汉语主题词向量,v′t缅表示加权后的缅甸语主题词向量。
因为本文是将汉缅文本相似度计算转化为计算汉缅每篇文章的主题相似度,相较于直接计算两篇文章的相似度计算量更小,此外计算主题相似度避免了计算一些无意义单词的相似度,可得到更好的相似度结果。
2 汉缅双语可比候选文档获取
由于目前没有公开的数据集,为了构建实验数据,我们首先从新华社中文版新闻平台(1)http://www.xinhuanet.com/爬取了中文新闻文档,并从每篇中文新闻文档的标题中提取关键字翻译为缅甸语作为查询词,再利用双语词典在新华社缅文版新闻平台(2)http://xinhuamyanmar.com/爬取缅甸语文档中包含查询词的缅甸语新闻文档集;然后,根据新闻文档里面出现的主要图片跟文本主题内容具有很大的相关性这一现象,通过人工方式选择汉缅双语文档中出现图片内容相似性高的汉缅双语文档作为候选可比文档。如图4所示,汉缅双语文档中图片内容具有很大相似性,图中一一对应的序号表达的是双语文本对齐片段,但整个新闻文本内容不完全互译。进而对候选的汉缅双语文档进行分词、去停用词等预处理,其中,汉语文档分词使用jieba分词工具(3)https://github.com/fxsjy/jieba,缅甸语分词使用昆明理工大学研发的缅甸语分词工具(4)http://222.197.219.24:8099,缅甸语停用词表如表1所示。最后, 利用汉缅双语词典统计汉缅双语候选文档标题中出现的双语互译词汇的长度比作为双语文档标题的相似性,综合考虑双语文档标题及内容的相似性作为选取汉缅双语可比文档的标准。通过以上方式最终获取了涉及科技、政治和体育相关领域的汉缅双语可比文档597对作为实验语料,具体规模如表2所示。

表1 缅甸语停用词


图4 汉缅可比双语文档实例
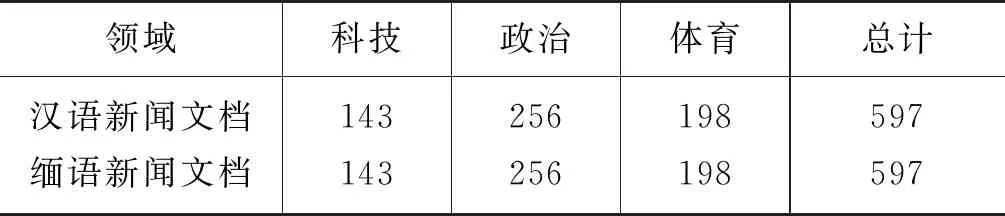
表2 数据规模
3 实验
3.1 实验数据及参数设置
本文从新华社缅文版新闻平台以及对应的中文版新闻平台共抽取涉及政治、体育和科技相关领域的汉缅双语可比候选文档597对作为实验语料。取出其中的400篇文档作为训练集,进行主题的抽取及汉缅双语主题词向量的训练,其中在训练双语词向量中,字典的大小为43 786个词,使用余下的197篇文档作为测试集,测试在抽取主题的时候不同主题数量和不同迭代次数对抽取主题效果的影响。
模型中设置LDA训练的超参数α=0.1,β=0.1,迭代次数为100,每篇文章的主题数为5;词向量维度为768。
3.2 评价指标
对于LDA的评价标准,我们使用Perplexity(困惑度)作为评价标准。困惑度的值越小,模型的表现越佳,相应的主题预测能力和新文本的预测能力就越强,困惑度的计算如式(7)所示。
其中,p(w)是指测试集中的每一个词出现的概率,计算公式如式(8)所示。
其中,p(z|d)表示的是一个文档中每个主题出现的概率,p(w|z)表示词典中的每个单词在某个主题下出现的概率。
本文采用召回率R、精确率P、F1值评估各种相似度算法的效果。F1值越大,相似度计算结果越准确;F1值越小,相似度计算结果的准确性越低,如式(9)所示。
其中,C表示相似度超过阀值且与源语言相似的文档集合,N表示所有相似度超过阀值的文档的集合,M表示所有与源语言文档相似的文档集合。
3.3 实验及结果分析
为验证本文方法的有效性,本文分析抽取不同主题数目对主题效果的影响、不同迭代次数对主题效果的影响,还通过对传统双语LDA计算文档相似度方法、使用双语词向量计算文档相似度方法、翻译模型计算文档相似度方法以及本文的方法进行对比实验,另外,我们还对不同方法在各阶段所用的时间消耗进行对比,以及不同训练词向量方式对实验结果的影响进行对比,实验设计如下。
实验一 不同主题数目下以及不同迭代次数的困惑度对比
从图5中可以看出,当主题数目为5时困惑度趋于平稳,所以迭代次数的实验主题数目设置为5;如图6所示,当迭代次数在60到100之间时,困惑度下降较快,迭代次数达到100次后模型逐渐收敛,此时抽取的主题效果最好。本文在抽取主题时,将主题数设置为5,迭代次数为100。
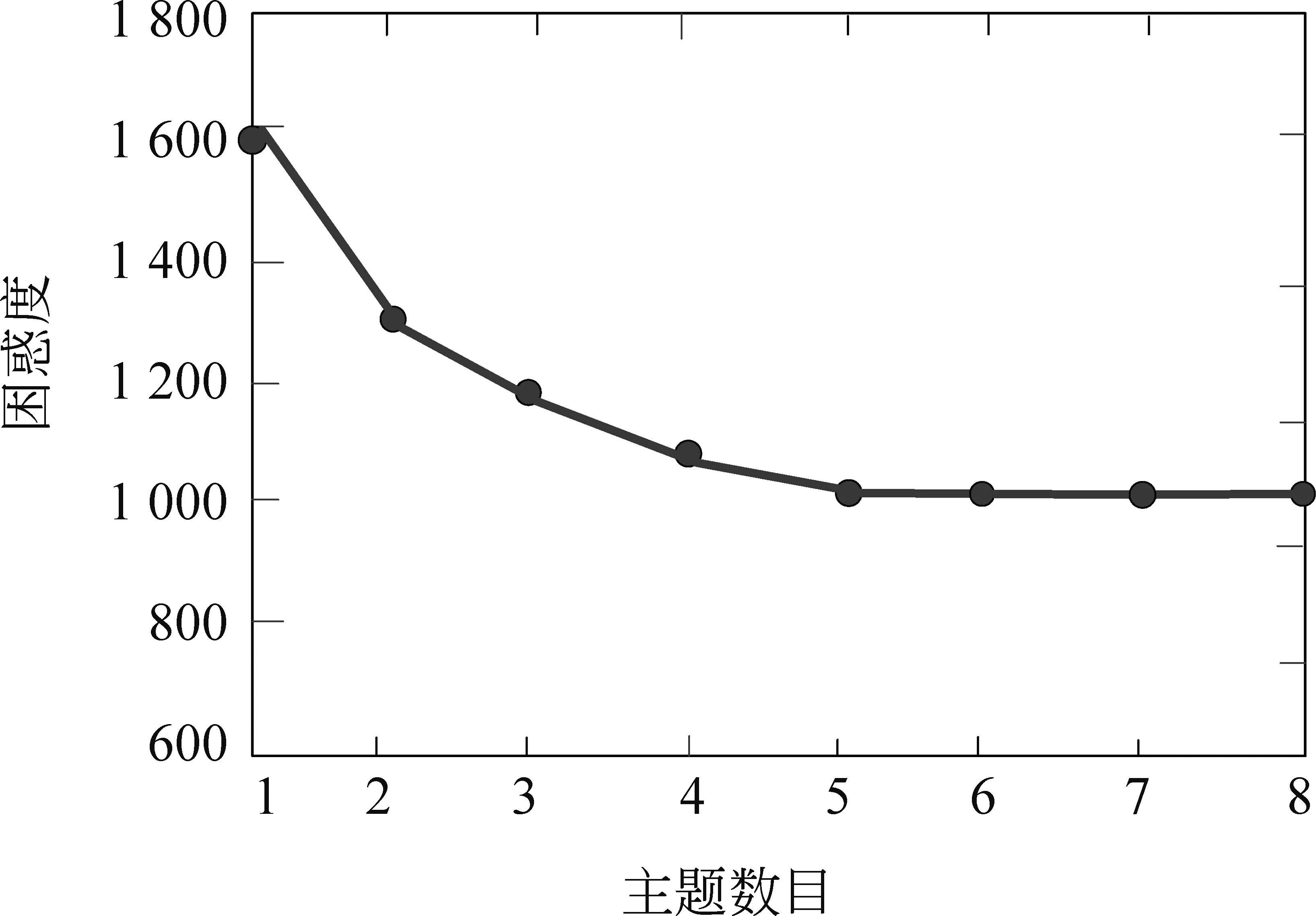
图5 不同主题数目下的困惑度

图6 不同迭代次数的困惑度
实验二 不同方法计算文本相似度的结果比较
从表3可以看出,通过双语LDA抽取主题计算文本相似度得到的F1值最低,使用双语词向量方法计算文本相似度要比使用双语LDA计算双语文本相似度的效果好,而本文方法在召回率、准确率和F1值上都取得了最好的效果。其中本文的方法获得的F1值为74.0%,比使用双语词向量计算文本相似度的方法提高了5.6%,比使用翻译模型计算文本相似度的方法提高了10.4%,比使用双语LDA计算文本相似度的方法提高了12.3%。
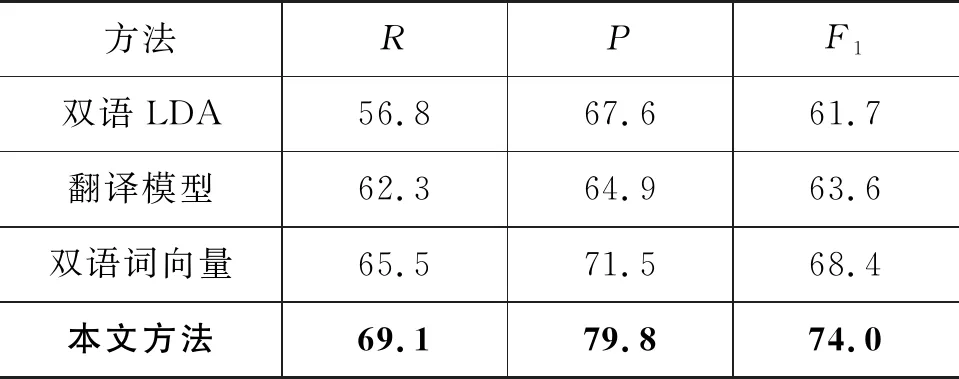
表3 不同方法计算文本相似度(%)
实验三 不同方法计算文档相似度消耗的时间
从表4可以看出,使用翻译模型方法计算文档相似度消耗的时间最少,本文方法总耗时4.33h,比使用双语词向量方法计算文档相似度的时间长,这是因为本文方法需要分别对汉语、缅甸语文档抽取主题,这就消耗了大量的时间。但是本文的方法在词向量训练和相似度计算部分使用的时间较少,这是因为我们只对抽取的主题进行词向量训练,然后对主题计算相似度,减小了计算量。

表4 不同方法计算文档相似度所消耗的时间(h)
实验四 不同词向量对实验结果的影响
为了验证不同词向量对实验结果的影响,本文对比了基于Word2Vec[14-15]、GloVe[18]、BERT[12]三种词向量生成方式下的实验,对比结果如表5所示。
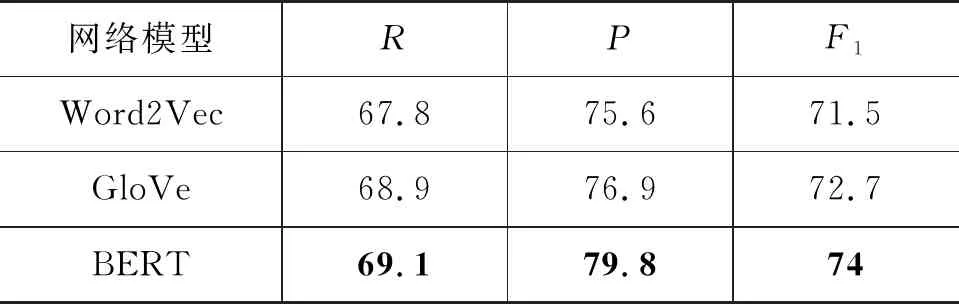
表5 不同词向量方式对实验结果的影响(%)
从表5可以看出,基于预训练BERT模型生成的动态词向量产生的分类效果明显高于另外两种静态词向量。由此可见,本文提出的基于预训练的方式生成的词向量更能准确地表征上下文环境中词汇的语义特征,有助于双语可比文档的获取。
4 总结与展望
本文提出一种融合主题模型及双语词向量的汉缅双语可比文档获取方法。将汉缅文档相似度计算转换为汉缅主题相似度计算问题。实验结果表明,本文提出的方法在准确率、召回率和F1值上均取得最好的效果,其中与使用双语LDA的方法度相比,本文方法效果提升较高,F1值提升了12.3%。下一步工作将考虑把主题词的同义词特征融合到主题模型中以提升主题的抽取效果。
猜你喜欢
歌海(2021年3期)2021-07-25
哲学评论(2018年2期)2019-01-08
视野(2016年4期)2016-03-26
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
沈阳医学院学报(2014年4期)2014-12-27
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
疑难病杂志(2014年12期)2014-04-16
