
基于DL-T及迁移学习的语音识别研究
2021-03-29 03:12费鸿博俞经虎
工程科学学报 2021年3期
张 威,刘 晨,费鸿博,李 巍,俞经虎,曹 毅✉
1) 江南大学机械工程学院,无锡 214122 2) 江苏省食品先进制造装备技术重点实验室,无锡 214122 3) 苏州工业职业技术学院,苏州 215104
语音识别是人机交互的一项关键技术,近年来,基于深度学习的语音识别技术取得了跨越式的发展[1-2],其在语音搜索、个人数码助理及车载娱乐系统[3]等领域得到了广泛应用. 鉴于声学建模是语音识别技术的关键,因此国内外学者对其开展了广泛研究[4-15],主要可划分为4类:(1)隐马尔科夫模型[4-7](Hidden Markov model, HMM);(2)连接 时 序 分 类[8-11](Connectionist temporal classification, CTC);(3)序列到序列(Sequence to sequence,S2S)模型[12];(4) 循环神经网络转换器[13-15](Recurrent neural network-transducer, RNN-T).
(1) 第1类基于HMM构建声学模型,用神经网络描述声学特征的概率分布,有效弥补了高斯混合模型对于语音特征建模能力不足的缺点,从而提升声学模型准确率[4]. 其中,Peddinti等[5]探索了神经网络-隐马尔可夫模型(Neural networkhidden Markov model, NN-HMM)的声学模型;Povey等[6]构建了因式分解的时延神经网络模型;刑安昊等[7]提出了深度神经网络(Deep neural network, DNN)裁剪方法,使得DNN性能损失降低. (2)第2类方法基于CTC构建端到端声学模型,无需时间维度上帧级别对齐标签,极大地简化了声学模型训练流程[8-11]. Graves[8]首次构建了神经网络-连接时序分类(Neural network-CTC,NN-CTC)声学模型并验证了其对于声学建模的有效性;Zhang等[9]探索了深度卷积神经网络-连接时序分类(DCNN-CTC)模型;Zhang等[10]构建了多路卷积神经网络-连接时序分类声学模型,使得音节错误率相对降低12.08%;Zhang等[11]提出了连接时序分类-交叉熵训练方法. (3)第3类方法旨在将声学特征编码成高维向量,再解码成识别结果. 基于自注意力模型,Dong等[12]构建了端到端语音识别声学模型. (4)第4类方法则基于RNN-T构建声学模型,该方法对CTC输出独立性假设进行优化,并联合训练声学模型与语言模型进一步提升声学模型准确率[8]. Graves等[13]首次验证了RNN-T对于构建声学建模的可行性;Rao等[14]提出了适用于RNN-T的预训练方法;Tian等[15]构建了SA-T声学建模方法并结合正则化方法提高声学模型准确率.
值得指出的是:CTC是最早提出的端到端语音识别方法,由于其建模过程简便且训练模型容易,因此得到了广泛研究[8-11],但CTC存在输出独立性假设且无法与语言模型联合训练问题[15]. 为解决上述问题,RNN-T通过引入解码网络,不仅解决了CTC输出独立性假设问题且可联合语言模型进行训练.
综上所述,本文首先基于RNN-T模型探索不同编码、解码网络层数对其预测错误率影响;其次,在上述模型的基础上结合DenseNet与LSTM网络提出了DL-T声学模型;然后,为进一步提高其准确率,提出了适合DL-T的迁移学习方法;最后,基于Aishell-1[16]数据集开展语音识别研究,其结果验证了DL-T兼具预测错误率低及收敛速度快的优点.
1 声学模型
1.1 循环神经网络转换器 RNN-T
RNN-T是由Graves等[13]提出的一种语音识别声学建模方法,该方法可分为编码网络(Encoder network)、解码网络(Decoder network)以及联合网络(Joint network)三部分[17],其模型结构如图1所示.

图1 RNN-T声学模型结构图Fig.1 Acoustic model of RNN-T
设给定序列X=(x1,x2,···,xt,···,xT)表示输入T(1≤t≤T)帧声学特征序列,对应标签序列y=(y1,y2,···,yu,···,yU),其中U(1≤u≤U)表示标签长度. 如图1所示,编码网络将输入声学特征映射为声学特征向量ft,编码结果如下式所示:

其中,fEnc(·)表示深度神经网络构建的函数,该文编码层均采用BLSTM网络,其具体计算如式(2)~(7)所示:
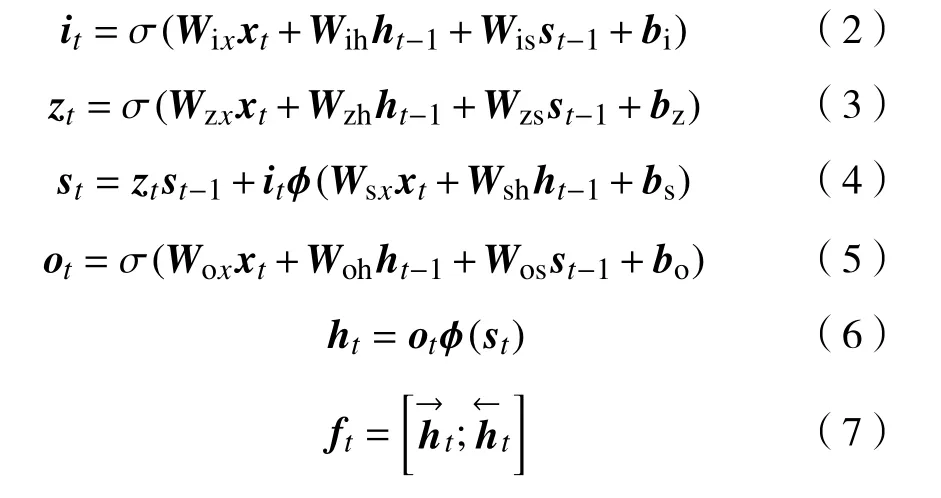
式(2)~(7)中,it、zt、st、ot、ht和ft分别代表t时刻输入门、遗忘门、中间状态、输出门、隐藏值向量和输出向量;Wix、Wih、Wis分别表示输入到输入门、输入门到隐藏值向量权值以及输入门到中间状态的权值;Wzx、Wzh、Wzs分别表示输入到遗忘门、遗忘门到隐藏值向量权值以及遗忘门到中间状态的权值;Wox、Woh、Wos分别表示输入到输出门、输出门到隐藏值向量权值以及输出门到中间状态的权值;Wsx、Wsh分别表示中间状态到输入门与隐藏值向量的权值;bi、bz、bs、bo分别代表输入门、遗忘门、中间状态和输出门偏置矩阵;σ(·)、φ(·)分别表示 sigmoid 及 Tanh 激活函数;表示拼接前向隐藏向量与后向隐藏向量得到编码网络结果ft.
如图1所示,RNN-T引入解码网络对CTC输出独立性假设进行优化,该网络对上一时刻非空预测结果进行再编码,其结果如式(8)所示:

同理,fDec(·)表示深度神经网络构建的函数,且该文解码层均采用LSTM网络,具体计算与式(2)~(6)一致,解码网络最终结果gu与ht相等.
联合网络将编码网络与解码网络组合(图1),得到组合序列,再通过Softmax函数得到下一时刻概率分布,其计算如式(9)~(10)所示:

式(9)~(10)中,ft、gu分别表示编码向量与解码向量,并将上述二者组合成联合向量wt,u,进而通过Softmax函数计算其后验概率. 式(11)表示RNN-T损失函数,其值可通过前向-后向算法计算. 其中,y*表示给定序列的标签,由于式(10)结果均可微. 因此,可通过随时间反向传播(Backpropagation through time, BPTT)算法[18]进行参数训练.
1.2 密集连接网络转换器 DL-T
DenseNet是由Huang等[19]提出的一种深度学习算法,其采用密集连接方式加强特征的信息重用,从而提升网络的性能,其模型结构如图2所示. 曹毅等[20]结合DenseNet和N阶马尔可夫模型提出了N阶DenseNet,该模型在避免梯度消失的前提下有针对性地减少了特征图层之间的连接,极大地减少了特征冗余,使得模型的收敛速度更快. 式(12)可用于表示DenseNet计算结果:
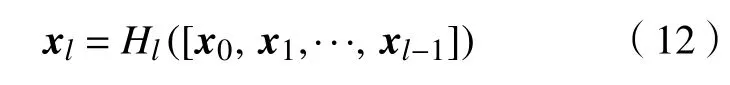

图2 DenseNet模型结构图Fig.2 Model structure of DenseNet
其中,l表示当前层数,[x0,x1,···,xl-1]表示拼接前l-1层的特征图,Hl表示拼接前l-1层特征图,xl表示第l层特征图.
受上述算法启发,首先使用DenseNet提取原始特征的高维信息,其不仅提升特征的信息重用[21],而且可以减轻梯度问题[22];然后利用LSTM网络序列建模时的优势,对提取的高维信息进行序列建模;最终构建DL-T声学模型,其具体编码网络模型结构如图3所示.

图3 DL-T编码网络结构图Fig.3 Encoder network structure of a DL-T
2 基于迁移学习的声学模型
迁移学习(Transfer learning, TL)是深度学习优化算法中的研究热点,其旨在基于源域在解决任务中获得知识进而改善目标任务的算法. 近年来,国内外已有不少学者在此领域进行深入研究[15,23-24].Tian等[15]将预训练模型作为RNN-T的初始模型,在此基础上进行再训练,使得RNN-T训练难度降低;易江燕等[23]用迁移学习方法对带噪语音进行声学建模,该方法利用老师模型指导学生模型进行训练,提高带噪语音的鲁棒性;Xue等[24]基于多任务学习理论,对声学模型进行再训练,从而降低模型的错误率.
有鉴于此,为进一步提高声学模型准确率,本文拟用迁移学习方法对声学模型进行优化. 该方法在初始模型的基础上融合优化算法重训练得到最终模型,其训练方法如图4所示.

图4 迁移学习方法结构图Fig.4 Method of transfer learning
图4中,虚线部分表示初始训练模型,其包含编码网络、解码网络及联合网络3部分,其具体工作原理如下:
(1)首先以声学特征序列X为编码网络输入;
(2)其次,用字序列y通过词嵌入[25]变换作为解码网络输入,该输入序列将高维稀疏字序列映射低维密集的特征空间,从而减少输入参数量便于模型训练;
(3)最后,联合网络将编码网络与解码网络相结合,通过softmax函数输出结果.
实线为迁移学习部分,该部分RNN-T结构与初始模型一致,将初始模型参数重训练得到迁移学习之后的模型,其计算结果如式(13)所示:

其中,Pi、Pf分别表示初始模型以及迁移学习模型的参数,其中Pi=P(ki|ti,ui),Pf=P(kf|tf,uf);Dfi(·)为本文迁移学习的优化目标,其用Pi通过参数优化得到Pf,旨在最小化Dfi(·)目标函数.
3 实验
为验证DL-T声学模型相较于RNN-T训练时收敛速度更快且具有良好的准确率,本节基于Aishell-1数据集在实验平台上开展语音识别的研究.
3.1 实验数据集
实验采用Aishell-1[16]数据集进行实验,该数据集是中文语音标准数据集,其采样率为16000 Hz,其中训练集、验证集以及测试集分别包含120098、14326以及7176条标准语料,数据总时长约为178 h,并且训练集、验证集和测试集语料间均无交叠.
3.2 实验设置
为验证DL-T兼具预测错误率低与收敛速度快的优点,基于Aishell-1数据集,论文将开展声学模型研究,其具体参数配置如下:
(1)特征提取:基于kaldi[26]语音识别开发包提取80维FBank特征,其中窗长25 ms,帧移为10 ms,然后左拼接3 帧[15],共320 维,用其作为声学模型输入. 训练阶段,对所有语料按帧由短到长进行排序,共4335个字作为建模单元.
(2)声学模型参数:本文基于Pytorch[27]构建声学模型. 初始训练阶段,优化准则采用随机梯度下降,学习率初始设置为0.001;迁移学习阶段,优化准则不变,但学习率降为0.00001. 且所有训练阶段,Linear和DenseNet网络均采用反向传播算法进行训练,LSTM模型采用BPTT算法进行优化参数. RNN-T基线模型中,编码网络设置DenseNet为4层,特征图增长率[19-20]为4,初始输入为单通道的语音特征;采用3层BLSTM模型进行序列建模,隐藏神经元个数为320;解码网络设置为1层单向LSTM网络,神经元数目为320;联合网络采用2层全连接网络,其神经元数目依次为512和4335.
(3)解码:本文采用束搜索对最后概率分布进行解码[13],解码宽度为10. 并且,采用训练集数据构建5-元语言模型对声学模型结果进行修正,初始设置语言模型权重为0.3,式(14)表示RNN-T声学模型与语言模型联合解码定义:
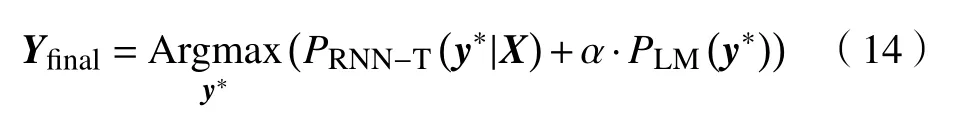
其中,PRNN-T(y*|X)与PLM(y*)分别表示RNN-T声学模型以及LM生成y*的概率,α代表语言模型权重,最终通过Argmax(·)函数将上述计算结果映射为对应的序列Yfinal.
3.3 实验结果
3.3.1 基线模型
RNN-T基线模型可为DL-T提供对比模型并能验证其声学模型的有效性. 为得到RNN-T基线模型,基于3.2中设置的初始实验参数,对基线模型中不同参数进行对比研究. 首先对编码网络中BLSTM网络的层数进行实验,得到编码阶段最优模型;其次,再增加解码网络中单向LSTM层数;最终采用最低的错误率(CER)模型作为基线(Baseline)模型,具体实验结果如表1所示.

表1 RNN-T基线模型实验结果Table 1 Experimental results of RNN-T’s baseline %
表1中Dev CER、Test CER分别表示验证集错误率和测试集错误率. 其中,“E3D1”表示编码网络中BLSTM层数为3,解码网络中LSTM网络层数为 1;“E3D1(TL)”表示“E3D1”声学模型经过迁移学习(TL)训练得到的模型;迁移学习与语言模型共同优化下,得到“E3D1(TL+LM)”声学模型.
从表1不难看出:
(1)编码网络初始设为3层,随其层数增加,模型预测错误率出现先增后减趋势,当模型编码层数为4,且解码层数为2时,声学结果达到最优,其测试集错误率降至14.54%;
(2)RNN-T经过重训练可使得声学模型错误率降低1.80%~6.13%,验证了迁移学习可进一步提高RNN-T声学模型准确率的结论;
(3)语言模型和声学模型联合解码使得RNN-T的效果得到极大提升,相较于文献[15],“E4D2(TL+LM)”声学模型在验证集与测试集的预测错误率分别相对降低9.87%和9.90%,模型的错误率降至10.65%.
综上可得:(1)“E4D2(TL+LM)”为本文构建的RNN-T声学模型,其错误率最低,选其作为基线模型具有合理性;(2)迁移学习可进一步降低初始模型错误率,通过插入语言模型可使得模型达到最优.
3.3.2 DL-T实验结果
为验证DL-T声学模型相较于RNN-T训练收敛速度快、预测错误率低. 基于3.2节设置DL-T初始参数训练声学模型,并与3.3.1节中RNN-T的实验结果进行对比,其实验损失函数曲线与错误率曲线如图5、图6所示.
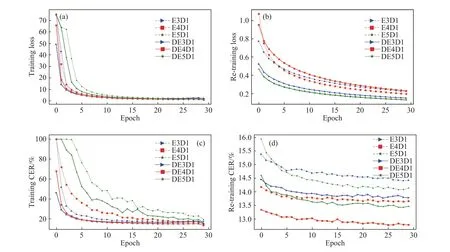
图5 基线模型实验曲线图. (a)初始训练损失值曲线图;(b)迁移学习损失值曲线图;(c)初始训练错误率曲线图;(d)迁移学习错误率曲线图Fig.5 Curves of the baseline model:(a) loss curve on initial training stage; (b) loss curve on transfer learning stage; (c) prediction error rate curve on initial training stage; (d) prediction error rate curve on transfer learning stage

图6 DL-T实验曲线图. (a)不同声学模型初始训练损失值曲线图;(b)不同声学模型迁移学习损失值曲线图;(c)不同声学模型初始训练错误率曲线图;(d)不同声学模型迁移学习错误率曲线图Fig.6 Curves of the DenseNet-LSTM-Transducer: (a) loss curve of different acoustic models on initial training stage; (b) loss curve of different acoustic models on transfer learning stage; (c) prediction error rate curve of different acoustic models on initial training stage; (d) prediction error rate curve of different acoustic models on transfer learning stage
图5中,“DE3D1”表示编码网络为DenseNet-LSTM结构(DenseNet结构与3.2节参数一致),其LSTM层数为3,解码网络中LSTM网络层数为1的DL-T声学模型. RNN-T以及DL-T实验结果分别用虚线、实线表示. 图5(a)和 5(c)分别表示初始训练阶段损失值曲线与错误率曲线,图5(b)和5(d)分别表示迁移学习阶段损失值曲线与错误率曲线.
从图5(a)及 5(b)可看出:(1)随着迭代次数的增加,声学模型逐渐趋于收敛,损失值最终收敛到一个固定范围内;(2)在初始训练阶段,DL-T收敛速度相较于RNN-T更快;在重训练阶段,RNN-T声学模型损失值减小至0.25左右,DL-T可减小至0.15以下,证明了DL-T相较于RNN-T训练收敛速度更快.
从图5(c)与 5(d)可看出:(1)随着迭代次数的增加,声学模型预测错误率逐渐降低,最终降至12.0% ~ 15.0% 范围内;(2)初始训练阶段,RNN-T 与DL-T预测错误率曲线均呈下降趋势,但DL-T错误率相较于RNN-T低;重训练阶段,RNN-T预测错误率降至13.5% ~ 15.0%范围内,DL-T预测错误率最低降至13.0%以下,该结果进一步验证了DL-T可显著降低声学模型预测错误率. 其具体实验结果如表2所示.

表2 DL-T实验结果Table 2 Experimental results of DL-T %
表2为实验具体结果,本文为得到最优DL-T声学模型. 首先,DenseNet与解码网络层数不变,分析编码网络中不同BLSTM层数对于DL-T的影响,从表2可得出,“DE4D2”为最优的DL-T声学模型. 然后固定编码网络不变,探索不同解码网络层数对模型的影响,从表2可得,当其层数为2时,模型达到最优,即为“DE4D2”模型,最终在测试集错误率可达13.45%. 从表2可得以下结论:(1)迁移学习对于DL-T效果显著,使得模型的错误率降低0.90%~3.08%,再次验证了其对于模型训练的优越性;(2)语言模型的线性插入可进一步降低声学模型的错误率,最优声学模型错误率降低至10.34%;(3)必须指出的是:本文提出最优的DL-T声学模型相较于SA-T声学模型[15],在验证集和测试集上的预测错误率分别降低4.45%、1.15%,其相较于LAS声学模型[28]在测试集上,错误率相对降低2.08%,证明了DL-T擅长声学建模.
为分析RNN-T与DL-T的训练与识别复杂度,分别选用“E4D2”与“DE4D2”两种代表性声学模型对其单轮训练时间与单句解码耗时进行实验分析. 实验结果表明:(1)“E4D2”与“DE4D2”单轮训练时间分别约为150 s和155 s,“DE4D2”相较于前者单轮训练时间只增加约5 s,说明DL-T对 RNN-T训练时间影响较小;(2)“E4D2”与“DE4D2”单句解码耗时分别约为910 ms与915 ms,“DE4D2”相较于前者单句解码耗时仅相对增加0.55%,实验结果进一步验证了DL-T对于识别复杂度的影响较小.
为进一步验证不同语言模型权重对于声学模型结果的影响,表3给出了不同语言模型权重对于模型“DE4D2”的影响,语言模型的权重分别设置为0.2、0.3和0.4. 从表3实验结果可得出,当权重值为0.3时,声学模型的错误率最低,达到10.34%,声学模型结果为最优.
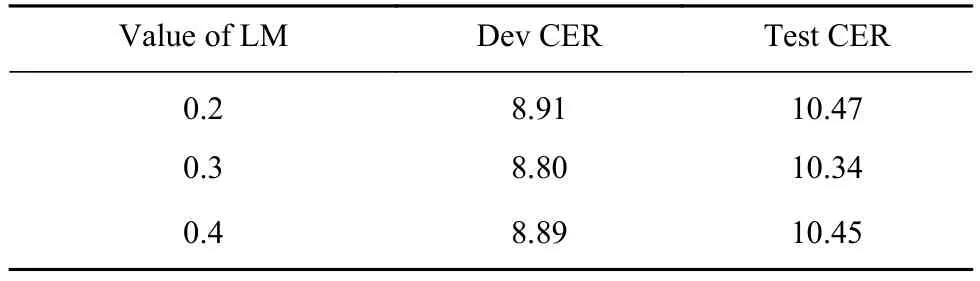
表3 不同语言模型对声学模型的影响Table 3 Effects of different language model weights on the acoustic model %
值得指出的是:综合表1、表2与表3实验结果可得出,DL-T相较于本文RNN-T基线模型,在验证集、测试集错误率分别相对降低3.61%和2.94%,进一步验证了DL-T相较于RNN-T可显著降低其预测错误率,其最优模型的具体训练过程曲线图如图6所示.
为进一步展示最优声学模型实验过程,图6(a)~6(d)展示了“E4D1”、“E4D2”、“DE4D2”三种不同声学模型的不同实验结果,其中模型“DE4D2”为本文最佳结果,模型的最终错误率降至10.34%.图6(a)、6(c)表示初始训练结果,图6(b)、6(d)表示迁移学习结果. 由图6(a)与图6(b)可以得出:(1)随着迭代次数增加,模型趋于收敛,最终损失值收敛在 0.05~0.40范围内;(2)“DE4D2”模型在初始训练时相较于其他模型收敛速度最快,再次验证了DL-T可有效解决RNN-T收敛速度较慢的问题.
从图6(c)与图6(d)可以得出:(1)三种声学模型错误率总体呈下降趋势,其错误率最终降到10.0%~14.0%区间;(2)结合表1与表2结果可知,“DE4D2”相较于“E4D1”、“E4D2”在测试集上错误率降低2.73%和0.31%,再次证明本文提出的DL-T模型可显著降低模型错误率.
综合表1~表2、图5~图6可得以下结论:
(1)从表1与图5可得出:论文构建的RNN-T基线模型相较于文献[15]基线模型,其验证集与测试集预测错误率分别降低9.87%、9.90%,证明了本文构建的基线模型的有效性;
(2)基于图5及图6可得出,DL-T模型收敛速度相较于RNN-T模型更快,其值收敛于0.01~0.4范围,验证了DL-T可有效改善RNN-T收敛速度;
(3)从表1与表2可得出,DL-T相较于RNN-T基线模型在验证集及测试集错误率分别相对降低3.61%、2.94%,其最终错误率降至10.34%,表明DL-T可降低声学模型预测的错误率;
(4)值得指出的是:“DE4D2(TL+LM)”模型相较于SA-T模型[15],在验证集和测试集上分别相对降低4.45%、1.15%,且其相较于LAS模型[28]在测试集上预测错误率降低2.08%,进一步证明了DL-T可显著降低声学模型错误率及其对于声学建模的优越性.
4 结论
以 RNN-T 端到端语音识别声学模型为研究对象,针对其在语音识别时存在预测错误率高、收敛速度慢的问题,提出了 DL-T 声学模型及适用于 DL-T 的迁移学习方法.
(1)在研究RNN-T声学模型的基础上,搭建了该声学模型系统.
(2)提出了一种DL-T声学建模方法,通过在编码网络中融入DenseNet网络结构,其不仅能提取语音高维特征便于序列建模,又可加快模型训练的收敛速度.
(3)提出了一种适用于DL-T的迁移学习方法,该方法主要在初始模型上重训练得到更优声学模型,其可显著地提升声学模型准确率.
(4)基于Aishell-1开展了语音识别的研究,结果表明,相较于文献[15]基线模型RNN-T,DL-T在验证集及测试集预测错误率分别相对降低13.13%、12.52%,且其相较于SA-T、LAS声学模型测试集预测错误率分别相对降低1.15%、2.08%,进一步证明了DL-T可提升声学模型训练收敛速度.
论文研究内容对以 RNN-T 构建的语音识别声学模型在模型优化、理论研究与工程应用等方面均具有一定的指导意义.
猜你喜欢
中国石油石化(2022年12期)2022-07-16
家庭影院技术(2020年6期)2020-07-27
中国外汇(2019年19期)2019-11-26
新课程·上旬(2019年1期)2019-03-18
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
教师·中(2017年3期)2017-04-20
