
基于改进K-means算法的工件表面缺陷分割算法研究
2021-03-30 02:10李云飞
湖南工程学院学报(自然科学版) 2021年1期
李云飞
(安徽大学 江淮学院 理工部,合肥230031)
0 引言
随着我国现代化制造业的不断发展及其社会需求量的持续增长,用户对产品的质量要求也越来越高.工件在实际生产过程中,由于受到设备条件、生产工艺以及材料本身因素的影响,导致工件表面产生不同类型的缺陷,如划痕、缺损、凹坑、点伤等缺陷.而工件作为工业设备最重要的组成单位,它对工业产品的使用安全起到非常重要的作用,工业产品能否得到安全的使用主要取决于工件表面质量是否良好.因此,如何对工件表面进行有效的缺陷检测成为了该领域中一个亟待解决的问题.目前,对于工件表面的缺陷检测,大多数工厂采用传统的人工目测法来检测.这种检测方法虽简单易行,但也存在着较大的局限性,首先该方法对于工人的工作经验要求较高,而且在长时间的检测下容易使人产生视觉疲劳及受人主观因素的影响,具有人工成本高、效率低、稳定性差以及耗时长等缺点.
本文通过对图像处理技术、机器视觉技术以及工件表面缺陷检测技术的学习与研究,提出了一种能够准确快速检测出工件表面缺陷的算法,可以满足当前国内一些企业在工件产品缺陷检测技术方面的需求,这不仅提高了产品和生产线的自动化程度,而且实现了在线检测技术的信息集成化,具有检测效率高、成本低的特点,对国内的工业生产领域以及产品缺陷检测领域有着极大的意义.
1 基于改进的K-means算法的工件表面缺陷分割算法
1.1 基于改进的K-means聚类的工件表面图像分割算法
K均值聚类分割算法由阈值分割算法衍生而来,其实质是将待分割图像中的某些参数包括图像纹理、图像灰度以及其他参数共同组成多维空间中的特征矢量,并根据多维空间中的特征向量值对像素进行分类.聚类分割算法的具体过程为:将待分割图像平面中的像素投射到特征空间并对应成相应的点,根据在特征空间中不同目标对象差异的特征变量,特征空间中的点会呈现成团成簇的分布形态,然后根据成团成簇的现象在特征空间中进行特征空间分类,最后映射回原图像平面,得到分割后的图像.由此可见,聚类分割算法将图像平面的像素映射到了一个多维空间,克服了一维空间和二维空间研究问题的局限,但是该方法实时性差、计算量大.针对聚类分割算法存在的这些不足,一些学者们提出了基于图像分层的聚类分割算法、基于小波特征的聚类分割算法等,本文将结合自适应人类优化算法对K-means聚类算法进行优化改进.
1.1.1 K-means聚类算法原理
K-means聚类算法是无监督学习也是基于划分的聚类算法,与随机森林算法、逻辑回归算法、支持向量机等的分类监督学习算法有所区别,Kmeans聚类算法处理数据速度快、伸缩性好,而且在处理数据过程中仅需要变量X就能进行后续的分类工作,Y变量对其没有影响,该算法也是各类数据处理中最为流行的算法之一.K-means聚类算法是基于欧氏距离针对距离较近的对象进行划分,结合阈值分割和标记过程,通过比较相似对象划分到同一聚簇,是一种常用的基于全局的聚类划分方法.K-means聚类算法通常用于图像分割,则算法步骤如下所示:
第一步:定义一个等距离方法,并初始化聚类中心,公式如式(1)所示:
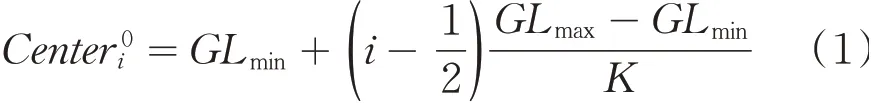
其中i=1,2,…,K,Centeri0表示第i类的初始化聚类中心,GLmax、GLmin分别表示最大和最小灰度值.
第二步:分配各样本点到相似的聚类集合,样本分配可根据(2)式分配:
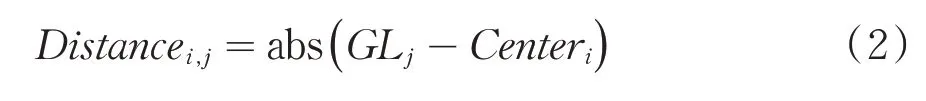
其中i=1,2,…,K,j=1,2,…,N,Distancei,j表示第j个像素点到第i个像素点的聚类中心的距离,N为样本空间中像素点的数量.
第三步:由步骤二得到聚类结果,得到更新后的聚类中心位置.公式如(3)所示:

其中i=1,2,…,K,Ni为步骤二中被分配到i类中的像素点的个数.
第四步:当聚类中心发生变化,可重复步骤二,直至循环结束.
第五步:第K-1类和K类聚类中心的均值被作为分割阈值,公式如(4)所示:
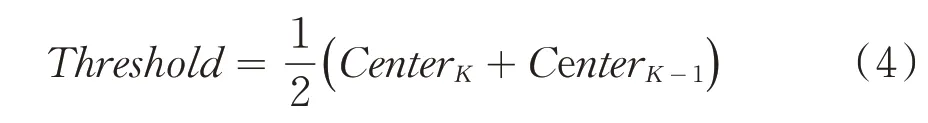
1.1.2 自适应人类学习优化算法
自适应人类学习优化算法是一种基于全局优化的群智能算法,2015年由Wang等人最早提出.该算法可以通过模拟人类的学习行为机制对其需要解决的问题进行寻优.自适应人类学习算法可依据要求参数设置少、收敛速度快、全局寻优能力好,不容易陷入局部最小值.该算法包括三种学习策略:随机学习策略、个体学习策略、社会学习策略.
自适应人类学习优化算法利用二进制编码,每个个体可用一串二进制码表示.每个个体随机初始化为包含“0”和“1”的二进制码,该二进制码就是代表人类想要学习的知识.在人类学习最初知识的时候,由于人类没有任何的先验知识,所以在刚开始的时候,人类的学习过程通常是一个随机学习和选择的过程,随机学习策略正是模拟人类学习机制的一种策略.则随机学习策略可用(5)式表示:
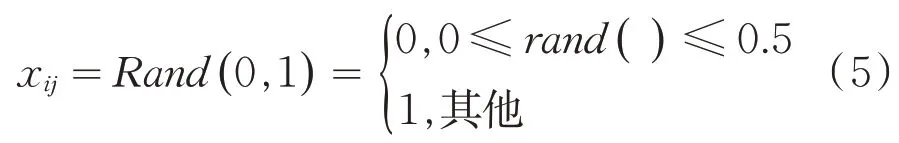
其中rand()表示一个0到1之间的随机数.学习知识的过程可以理解为:个体学习表示人类对外界的激励做出反应.在这个学习过程中,人类因积累了知识和经验具有了先验知识,并利用先验知识来避免错误,以此来提升自身的学习能力.则人的知识库IKD(individual knowledge database)可用式(6)表示.
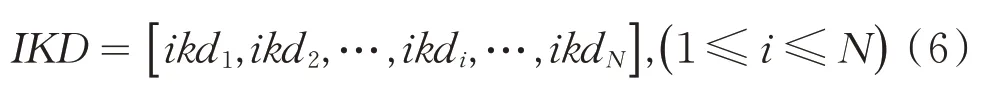
虽然人类可以通过自身的先验知识来解决困难,但是当问题较难时,解决问题的时间就会变长,人类的学习过程将会变慢.在社会环境中,可通过社会学习从集体经验中学习,可以极大地提高学习效率并快速解决困难,集体学习的经验就代表知识库SKD(social knowledge date).SKD可用公式(7)所示.
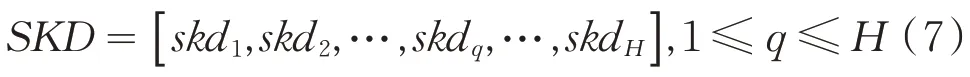
于是个体整个的学习过程包括随机学习策略、个体学习策略、社会学习策略,则整个学习过程可
用公式(8)所示.
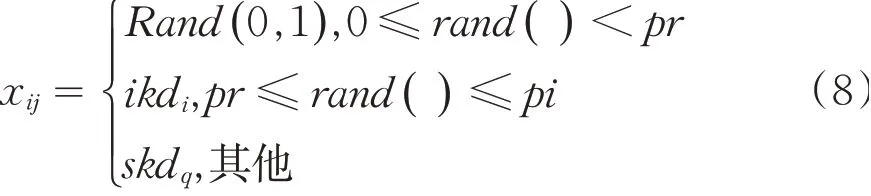
其中pr表示随机学习的概率,( pi-pr)代表个体学习的概率,( 1-pi)代表社会学习的概率,由式(8)可以看出,参数pr和pi对于随机学习策略、个体学习策略、社会学习策略有着非常重要的作用,因此针对问题的难易程度可以适当地调节参数pr和pi.本文为了提高算法的运行效率和减少参数的设置,将采用的自适应策略如公式(9)和(10)所示.
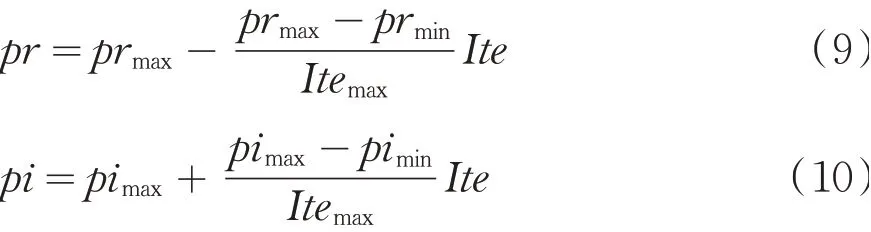
其中prmax和prmin分别表示pr的最大值和最小值;pimax和pimin分别表示pi的最大值和最小值;Ite表示当前的迭代次数;Itemax为最大迭代次数.
1.1.3 改进的K-means聚类的工件表面图像分割算法
为了将自适应人类优化算法的优点和Kmeans聚类算法的优点充分地应用,本文将利用自适应人类优化算法对其进行全局搜索,这样自适应人类优化算法就可以无限接近全局子空间,待该算法达到收敛之后,为了呈现出更好的聚类效果,将利用K-means聚类算法进行局部搜索.针对自适应人类优化算法,由于每个粒子的适应度值利用聚类误差平方和计算.若粒子数为n,fi表示第i个粒子的适应度值,则当前粒子适应度的平均值如公式(11).

自适应人类优化算法的收敛速度可由粒子适应度的方差决定,则可用公式(12)表示.

在自适应人类优化算法更新迭代的过程中,随着每一次的迭代更新,粒子的适应度也逐渐达到一个平稳的状态,此时在一个确定的区域内会有一个方差,所以在这种情况下有最优解,此时可采用Kmeans聚类算法进行局部寻优,则改进的K-means聚类的工件表面图像分割算法流程图如图1所示.
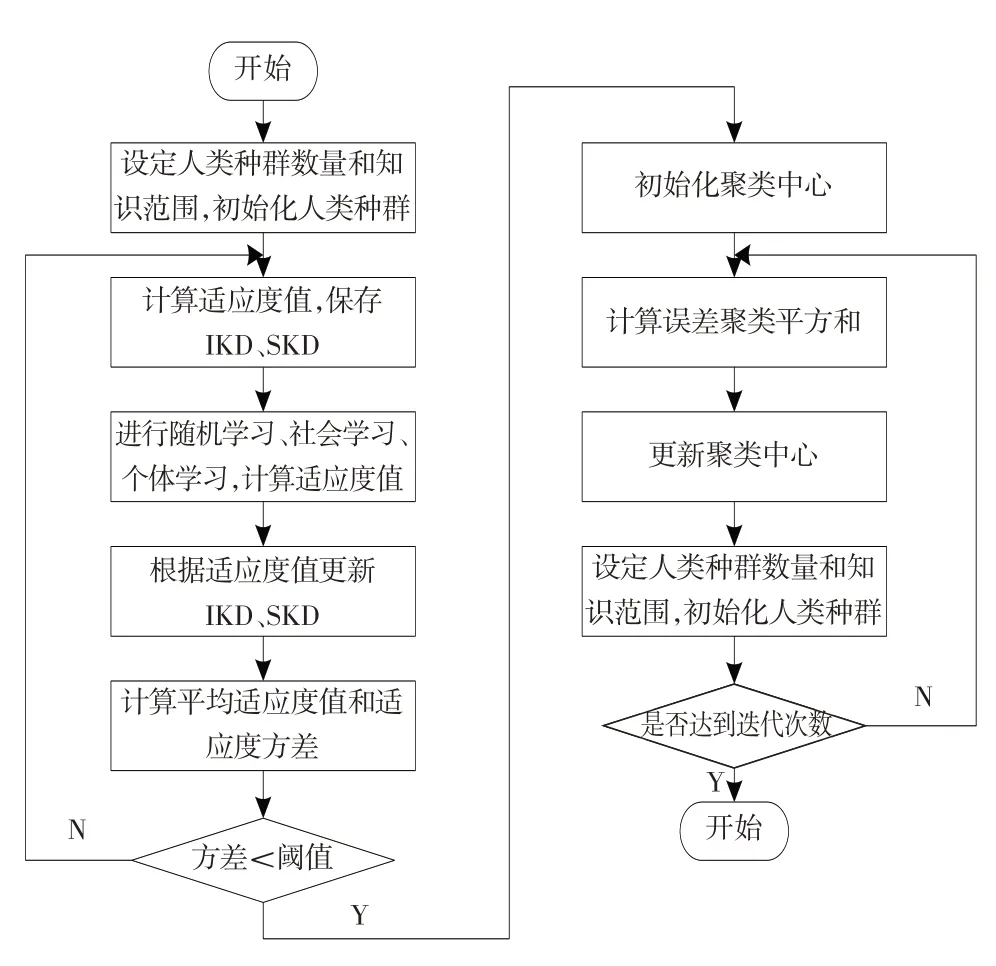
图1 基于改进的K-means聚类的工件表面图像分割流程图
1.2 形态学处理
经过本文改进的K均值聚类分割算法得到的分割图像,受环境等因素的影响会存在各种干扰,包括小面积的连接区域以及其他杂质.因此需要对分割之后的图像进行形态学处理,使得工件缺陷边缘变得光滑连续,并填补分割目标的内部空洞,将最终分割出的二值图像映射回原图像.本文主要用形态学运算中的膨胀运算和腐蚀运算对分割后的图像进行处理.形态学处理流程图如图2所示.

图2 形态学处理流程图
(1)结构元素
在待处理图像进行形态学处理操作时,需要结合一定的结构特点进行处理.操作过程为:首先选定一个原点,然后持续移动该点并将其和初始图像开始运算,进而可以过滤图像当中杂余部分.结构元素的选定直接影响着整个处理过程的结果.通常情况下,结构元素选择范围很小,与初始图像存在较大的区别.
(2)图像腐蚀
图像腐蚀的作用就是使得区域从周围向内缩小,应用给定的结构元素s( x,y)对输入图像f( x,y)进行灰度腐蚀,图像腐蚀的定义如式(13)所示:
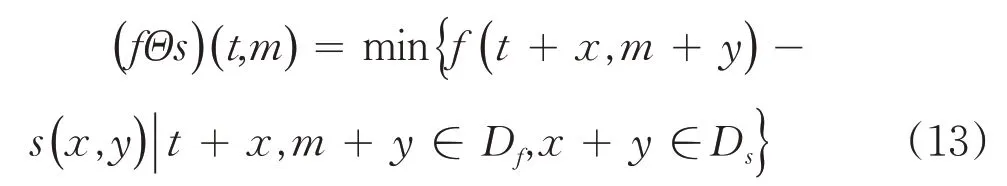
其中Df、Ds分别表示f和s的定义域.
(3)图像膨胀
图像膨胀的作用就是使得区域从周围向外扩大,应用给定的结构元素s( x,y)对输入图像f( x,y)进行灰度值膨胀,图像膨胀的定义如式(14)所示:
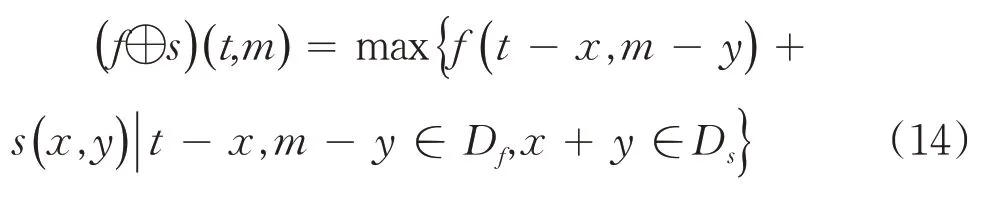
其中Df、Ds分别表示f和s的定义域.
对于经过腐蚀操作和膨胀操作后的工件分割图像,本章对其进行区域填充最终获取完整的图像工件区域的分割图像.最后将分割出的图像映射回原图像,即可准确提取出输工件图像中的缺陷区域.
原图与膨胀操作图如图3所示.

图3 原图 膨胀操作图

图4 原图 腐蚀操作图
1.3 工件面缺陷分割实验与分析
1.3.1 扣式电池图像缺陷检测
为了验证本文改进的K-means算法的有效性,采用256×256的扣式电池图像验证聚类效果,选择四个不同的分类数对扣式电池灰度图像进行分割,分别为k=2,k=4,k=6,k=9.则基于改进的K-means聚类算法的分割效果如表1所示.
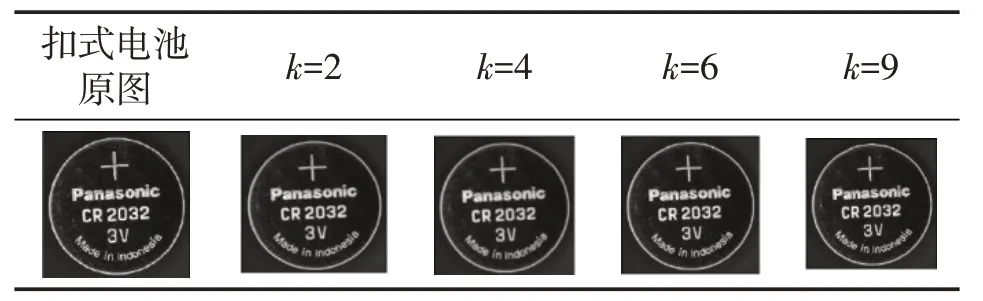
表1 不同k值下的分割效果
从表1中可以看出,随着聚类中心k值的增大,图像的分割效果越差,所以本文选择k=2时,对工件图像进行分割,则本文基于改进的K-means聚类的工件表面缺陷分割算法所设置的参数如表2所示.

表2改进的K-means聚类的工件表面缺陷分割算法参数
本文选择扣式电池常见划痕缺陷为代表,并对其进行分割提取实验,实验结果图如图5(a)~图5(c)、图6(a)~图6(c)所示.
其中图5(a)~图5(c)表示划痕缺陷通过基于阈值的分割算法以及基于区域生长的分割算法的实验结果图.从图中可以看出,缺陷图像的区域生长分割效果相比较于阈值分割效果更能有抑制图像中的噪声,且能够获得连续的目标缺陷区域,但是分割后的图像仍然存在噪声,不能够获取完整的缺陷区域,效果不够理想,计算复杂度也增加了.

图5 划痕原图、基于阈值和区域生长的分割图像

图6 划痕、K-means聚类分割以及改进的K-means聚类分割结果图
图6(a)~图6(c)表示划痕缺陷类型通过基于K-means聚类分割以及改进的K-means聚类的分割算法的实验结果图.由实验结果可知,改进的Kmeans相比于阈值分割、区域生长分割以及基于Kmeans聚类分割算法,对于缺陷目标区域的分割更为完整,能够保护感兴趣区域的重要细节.
1.3.2 滤网图像缺陷检测
本文所选择样本集大小为300,其中表面缺陷类型分为三种,包括划痕、残缺、擦伤等.样本如图7所示.

图7(a)划痕

图7(b)残缺

图7(c)擦伤
经过本文的算法后,测试后的结果如表3所示.
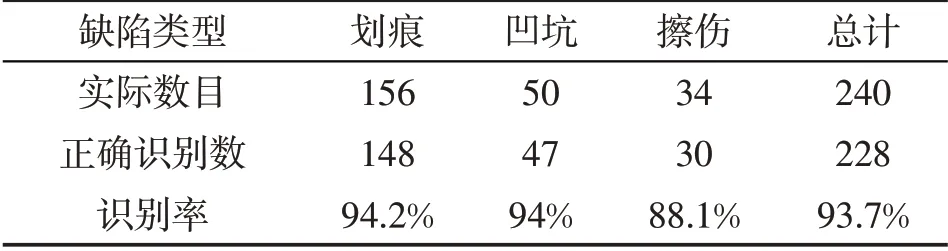
表3 测试结果
本文通过对基于BP神经网络算法、BP_CLPSO算法以及本文的基于改进的K-means算法进行试验仿真,则这三种算法的分类正确率如表4所示.由表4可知,经过本文改进K-means算法分类精度率较高.

表4 BP神经网络、BP_CLPSO以及本文算法的分类正确率
2 结论
本文通过分析比较基于阈值的图像分割方法和基于区域生长的图像分割提取算法对工件表面缺陷的分割提取效果,分析现有算法的不足之处,提出了一种基于改进的K-means聚类工件表面图像分割方法,该算法利用自适应人类优化算法的全局搜索能力,快速逼近全局最优聚类中心,然后将AHLO学习优化算法输出的聚类中心作为Kmeans聚类算法的初始聚类中心进行迭代寻优.由于在分割过程中受各种因素的影响,分割处理后的图像会存在一些噪声的干扰,所以为了消除这些因素的干扰需对分割后的图像进行形态学处理.基于此,本文利用形态学的膨胀运算和腐蚀运算进行分割后处理,最终获取完整的工件表面缺陷区域.实验表明,本文改进的K-means聚类分割算法能够较理想地分割出工件表面的缺陷,具有分割精度高且能够达到工件表面缺陷检测的目的.由于受各种因素的影响会存在一定的干扰,分割结果图像中可能包含小面积的连接区域以及其他杂质,所以需要对分割提取出的工件缺陷图像进行形态学处理,使其工件缺陷边缘变得光滑连续,并填补分割目标的内部空洞,将最终分割出的二值图像映射回原图像.
猜你喜欢
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
作文成功之路(高考冲刺)(2021年11期)2021-12-21
智能制造(2021年4期)2021-11-04
辽宁师专学报(自然科学版)(2021年1期)2021-07-21
内蒙古教育(2021年22期)2021-03-08
杭州电子科技大学学报(自然科学版)(2020年3期)2020-06-08
甘肃教育(2020年21期)2020-04-13
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
