
基于深度学习和图匹配的接线图检测与校核
2021-04-13 01:59李昊王杉耿玉杰王黎孙文昌苗纯源
北京航空航天大学学报 2021年3期
李昊,王杉,耿玉杰,王黎,孙文昌,苗纯源
(1.国网山东省电力公司青岛供电公司 电力调度控制中心,青岛266002;2.国网山东省电力公司 电力调度控制中心,济南250001;3.山东大学(青岛)计算机科学与技术学院,青岛266237)
在电力领域,传统的厂站一次接线图图纸绘制和管理工作对电网工作人员有很高的要求,如需要对电网历史及当前厂站设备非常熟悉且有丰富的工作经验等,其面临着两方面的问题:①缺乏科学可校核的参考标准,很有可能导致厂站接线图缺乏规范,进而含有潜在风险。②由于网络新建、旧线改造、方式变更、检修等原因导致主接线的元件组成、连接方式经常发生变化,要做到厂站接线图的实时更新需要付出高昂的人工成本和管理成本。针对以上问题,其对自动化的需求越来越迫切。
电网主接线图是电力系统分析的基础,其广泛用于电力系统中,如潮流计算、短路电流计算、可靠性分析、电网调度自动化等。考虑到高昂的人工管理成本,不少学者开发了电力系统专用的图形编辑软件,使得电气工程图生成效率大大提高,但其仍然依靠人工编辑,并且大部分图形的生成、维护和更新都还是人工进行,电力工作人员使用CAD等绘图软件绘制人工维护的厂站一次接线图,并进行人工校核,导致图纸绘制及一次接线图和人工一次接线图的校核缺乏规范性。因此,厂站接线图自动检测、维护和智能校验仍然是国内外众多学者不断深入研究的课题。
针对现存问题,本文提出了一种厂站接线图自动检测、识别和校核算法,实现了厂站一次接线图的自动校核。算法分为2部分:①对厂站接线图中的元器件、文字和拓扑关系等利用改进的深度学习和数字图像处理相关的检测和分类算法进行目标定位和识别。②基于图匹配算法对电子厂站一次接线图和人工维护的厂站一次接线图进行元器件和拓扑关系匹配校核。
本文研究的内容突破了传统人工识别、人工校核的方式,基于人工智能和数字图像处理技术实现厂站一次接线图的自动识别、自动校核,对接线图中电器元件的名称、坐标、拓扑连接关系等进行精准识别和校核。本文研究的内容不仅可以应用于厂站接线图的自动识别、自动校核,也可以为其他领域的线路图识别、校核任务提供思路。本文研究内容成果投入运行后,可以有效地提高图纸绘制速度、准确度和标准化程度,广泛应用到调控云的基础数据输入,为电力行业引入计算机领域的前沿技术,促进电力智能化的发展,切合泛在电力物联网的建设要求。
本文的主要贡献如下:①将目标检测和识别算法应用到了电力厂站一次接线图上,并且提出了一种多尺度融合的改进方式,实现了较高的检测和识别准确率;②基于改进的图匹配算法对厂站一次接线图和人工维护的厂站一次接线图进行匹配校核,解决了接线图电器元件标号顺序的问题,实现了较高的匹配校核准确率;③标注了一个小型电力厂站一次接线图电器元件数据集。
1 相关工作
关于电力图纸的自动绘制,早期的大多研究内容集中在基于地理信息技术平台的图形自动生成算法方面,主要是基于数据库或空间数据引擎,实现数据搜索,进行拓扑分析和图形自动绘制[1]。部分学者以典型接线形式的图形编排为依据,提出了一种根据设备连接信息自动生成接线图的经验方法,即借助于Oracle数据库提供的一套基于结构查询语言(SQL)的方案和函数(Oracle Spatial)的网络分析功能,对公共信息模型(CIM)数据中有关设备信息进行提取、编排实现厂站图的生成[2],该方法有利于系统集成,但模板匹配算法依赖性强,不易扩展。后来又有部分学者提出了基于存量图形自动生成厂站接线图的原理。从基于CIM/G的拓扑分析出发,给出了存量图形特征识别、特征提取及建立图形特征库的方法,结合特征评估,获取厂站接线图特征单元,并在特征单元的基础上完成厂站接线图的生成与绘制[3]。部分学者提出了通过采用节点布局的数学模型和线路走线寻路的函数算法来实现图形布局[4],该算法可保证线路完全不相交,但这使得线路严重弯折,有时甚至无法完成连线工作。
国内的几大电力自动化系统供应商在厂站一次接线图自动生成和校核方面都进行了一定的尝试,但能够成熟应用的产品不多见。河北电网曾率先研发了一种基于典型接线方式的智能系统来实现厂站图自动生成的软件[5]。基于厂站主接线图是有规范的且接线类型有限,朱永利等[5]提出了一种表示厂站拓扑结构的框架,接线图的整体布局思想为:先画面上下划分,分割轴线作为主变中心;之后布置母线,再布置变压器,最后布置线路等的布局,基于经验规则归纳了20多种常见的接线类型,并利用这些规则进行各种接线类型母线和相关的特殊支路(如母联、旁母、分段)的处理;主变布置有十几种规则[5]。遗憾的是,该方法没有考虑到变电站的数据统一建模,同时,其是基于经验进行预知的布局布线,是一种穷举试错的智能绘图方法,然而由于变电站规模不一,拘泥于细节的接线方式十分繁多,该方法的规则数量十分庞大。之后,华中科技大学将SVG图形格式引入到了变电站图形系统中,改进了朱永利等[5]的方法,并取得了很好的效果,但仍需要在作图过程中定义图元之间的连接关系,工作量依然很大。
经过多年的发展,各研究机构已经开始尝试将人工智能技术和图像处理技术应用于工程设计图纸的分析与处理。例如,黄若航[6]利用基于Inception ResNetV2和Faster R-CNN算法的深度学习网络,对经过预处理的热力管道工程设计图进行特征提取、目标定位和目标分类,得到一个基于工程图纸元件数据集的目标检测模型,之后利用光学字符识别技术(OCR)对目标检测模型识别出的图纸区域进行数据提取。同时,电力系统基于人工智能技术已做出多种技术创新,并取得了一定的效果。例如,尹思宇[7]在智能变电站的建设中,为解决海量电力设备红外图像数据的智能检测问题,对红外图像进行预处理,分离出存在缺陷的电力设备,以深度学习为理论基础提出了一种基于深度学习的电力设备红外图像缺陷识别分类的算法,进一步证明了基于人工智能的厂站一次接线图自动生成、自动校核技术的可行性。
2 关键实现技术
为了实现人工维护的厂站一次接线图自动校核,需要先进行厂站一次接线图的自动识别,再进行匹配校核。实现厂站一次接线图的自动识别,又分为接线图中的电器元件识别,接线图中的文字信息识别,接线图中的连接线识别、拓扑连接关系识别3部分。具体流程如图1所示。
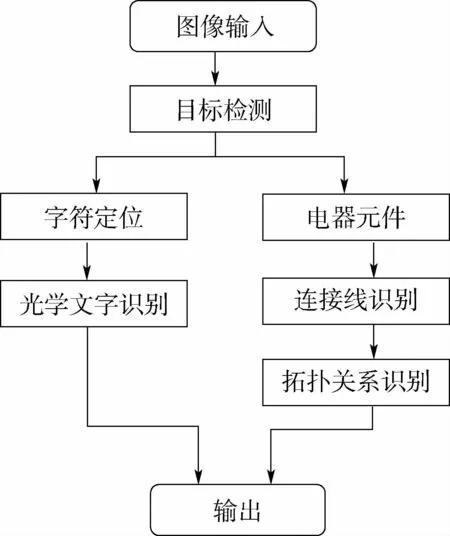
图1 厂站一次接线图识别流程Fig.1 Identification flowchart of primary wiring diagram of plant and station
2.1 厂站接线图中的电器元件识别
电器元件的识别是图纸拓扑关系识别的基础,其准确率关乎厂站接线图自动生成和自动校核的精度。针对厂站一次接线图中电器元件的检测识别问题,经过分析发现,图纸中各电器元件有以下特征:具有规定的形状且接线图中常出现的有17种类别;部分电器元件过小且形状相似度极高;分布位置不定、方向不定、大小不一。要想做到厂站接线图的准确识别,要求模型能够精确找到元件所在位置并准确识别其类别。
2.1.1 基于YOLO的目标检测算法
本文先采用One-Stage检测的深度学习模型YOLOv3[8]来进行元器件的检测识别。由于厂站接线图的分辨率过大,直接将其作为网络输入会导致小目标的检测效果较差。针对此问题,本文考虑将厂站接线图切割成4份后进行目标检测。将厂站接线图输入网络,利用darknet-53[8-9]深层网络来提取目标的特征,引入3个不同尺度的特征图预测应对目标形状的变化问题,优化提升目标检测准确率和位置精度,再将4份检测的结果进行拼接,得到电器元件的类别和坐标等属性信息。其坐标信息公式如下:

式中:tx、ty、tw和th为模型的预测输出;cx和cy为网格单元的坐标;σ表示Sigmoid函数;pw和ph表示预测前bounding box的大小;bx、by、bw和bh为预测得到的bounding box中心的坐标和尺寸。
对于超大分辨率的厂站接线图来说,由于元件众多且大小相差较大,直接使用YOLOv3来进行检测效果欠佳,故而进一步考虑基于多尺度融合的检测算法。
2.1.2 基于Faster R-CNN的多尺度融合检测算法
Faster R-CNN[10]作为一种Two-Stage目标检测算法,先使用特征提取网络提取输入图像的特征图,用于RPN(Region Proposal Network)和全连接层共享。再使用RPN网络生成候选区域。在Faster R-CNN算法中,ROI(Region of Interest)池化层收集输入的特征图和候选区域,综合这些信息后对候选区域提取特征图,送入全连接层判定目标类别。最后利用候选区域的特征图计算候选区域的类别,并通过回归获得检测框的精确位置。
对于超大分辨率的厂站接线图,为使算法适用于不同尺度的电器元件,本文提出了一种多尺度融合的检测算法。使用整张接线图和其分割4份后的小图构建的数据集分别训练出对应的Faster R-CNN模型,即大图模型和小图模型。对于大型的电器元件,大图模型有更好的检测效果,而对于细小型电器元件,则容易出现错检和漏检的现象。通过计算两者结果的交并比(IoU)来融合2种模型检测的结果,使用小图模型检测后的细粒度的结果去弥补大图模型的错检和漏检,有效实现了对厂站接线图中大小不一的电器元件的精准检测和识别。图2对目标检测的模型框架进行了展示。
2.2 厂站接线图中的文字识别
厂站接线图中的信息复杂,字符信息是接线图中信息提取的重中之重。厂站接线图中的文字信息字体多样、长度不同、位置多变、方向不定,字符也不局限于字母和数字,还有各种器件标识、说明等,个别地方也会出现线条密集、字符与线条黏连等情况,想要利用通用的光学文字识别模型直接来检测厂站接线图中的文字信息难度极大,效果不佳。因此,需要研究针对厂站接线图的特定光学文字识别模型,以提升文字信息的识别准确率。
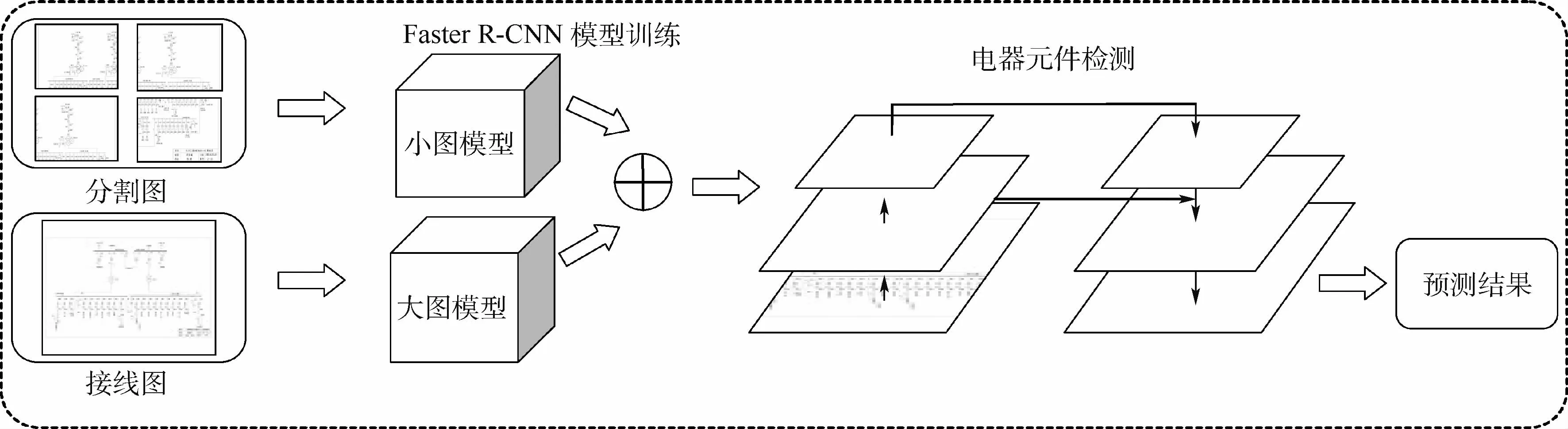
图2 厂站接线图多尺度融合检测算法Fig.2 Multi-scale fusion detection algorithm for wiring diagram of plant and station
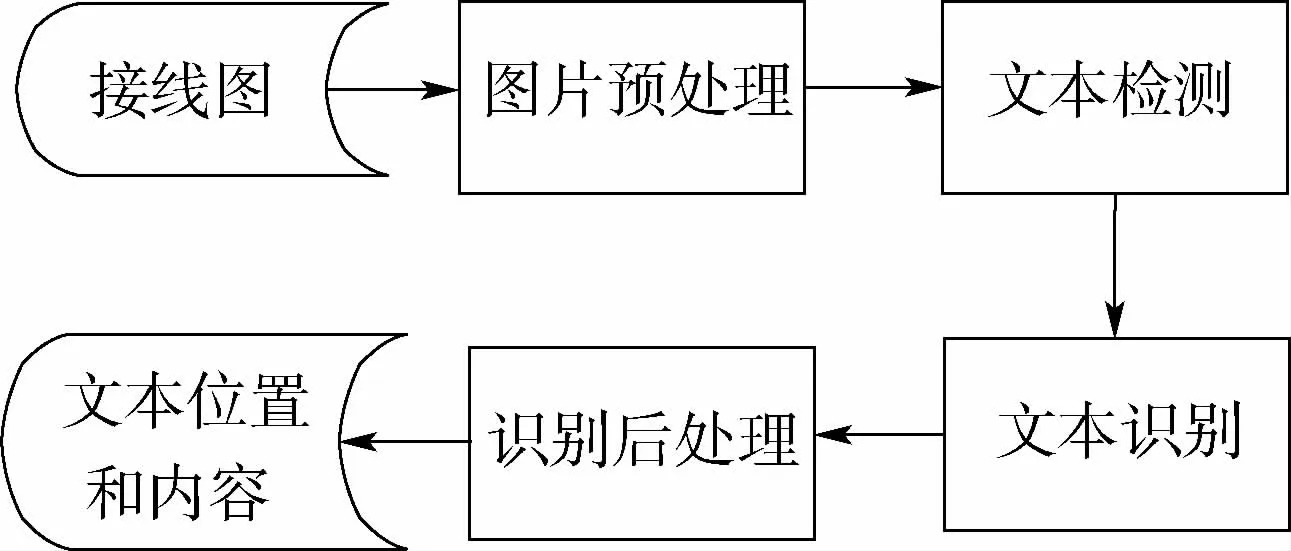
图3 厂站接线图文字识别流程Fig.3 Text recognition process of wiring diagram of plant and station
厂站接线图光学文字识别的流程如图3所示。先对厂站接线图进行图片预处理,使图片有助于后续的文字识别,再进行文字检测定位,获取图片中所有的文本框的位置坐标,之后进行识别前处理和文字识别部分,最终对识别的内容进行后处理,以提高识别的准确率。
2.2.1 基于Two-Stage的文字识别算法
先采用Advanced EAST[11]模型对文本区域进行检测,再采用Tesseract OCR[12]模型对检测出的文本区域中的文本信息进行识别,即文字检测和文字识别相分离的两阶段算法。由于厂站接线图是大分辨率图片,采用分割为4份的做法来提高文字识别的准确率。在识别出结果后再进行合并。
Advanced EAST以VGG16[13]作为网络结构的骨干来提取特征图,之后将提取的特征图采用U-Net[14]的算法进行合并,最终输出检测出文本框的置信度和坐标信息。Advanced EAST算法对于长文本和方向不定的文本区域有着较好的检测效果。
Tesseract OCR识别过程分为2步:单字切割和分类任务。对检测出的文本区域内的文本通过字符单元分割出单个字符。之后对每个字符进行分析,采用自适应分类器对分割出的字符进行分类。实现了对厂站接线图中拥有字体多样、长度不一、方向不定等特点文本的准确识别效果。
2.2.2 基于端到端的文字识别算法
端到端的文字识别模型融合文本检测和文本识别2个过程,简化文字识别的处理过程,同时加快识别速度。采用Attention-OCR[15]进行端到端的文字识别。在厂站接线图输入到Attention-OCR网络之前,对文字区域使用Cascade R-CNN[16]模型进行文字分割。
Cascade R-CNN作为两阶段R-CNN检测的多级扩展,通过级联不同的IoU阈值检测模型挑选对应质量的样本进行训练和回归。使用Cascade R-CNN进行厂站接线图的文本区域检测,并根据其检测出的结果分割出厂站接线图中的文字用于Attention-OCR的文本识别。Attention-OCR主要利用了spatial attention[17]进行端到端的文字识别。通过卷积网络提取特征并融合为一个大的特征矩阵f。计算图片中文本的spatial attention值αt,其值越大代表该区域为文字区域的概率越大。通过αt抽取特征矩阵f中的文本区域特征,后续送入循环神经网络(RNN)进行文本识别。
不同时间进行空间位置的加权公式如下:

式中:i和j为空间位置;t为RNN的时间维度;c表示特征图的通道;ut,c为根据注意力模型给出的权重对不同位置的特征加权后的特征向量,作为模型的输入。
网络在时刻t的预测输出字符最终为ct,其推导过程如下:

式中:xt为RNN在时刻t的输入;ct-1为前一刻的预测字符;st为时刻t的RNN隐藏层的值;^ot为结合RNN输出ot和注意力特征向量ut的时刻t的预测输出;Wc为时刻t-1 RNN权重矩阵;Wo为时刻t RNN权重矩阵;Wu为注意力特征向量的权重矩阵。最终通过计算得出预测的字符ct。
由于厂站接线图的分辨率过大,影响算法的处理速度和精度,同样对厂站接线图进行分割处理。将图片分别切成4份和9份,由于图片切割成4份后的切割处容易造成文本信息的缺失,而切割为9份则计算耗时较长。为了提高识别的准确率和速度,如图4所示,考虑使用切成9份后的第2、4、5、6、8这5张图片的信息来进行弥补。具体为使用Attention-OCR对5张图片进行文字识别,根据其识别的结果和切割处的文本进行交并比的判断来决定是否添加该图片的信息,以对切割处遗失的信息进行增补。
得到初步识别结果后,根据先验知识对结果进行后处理,以提高识别的准确率。
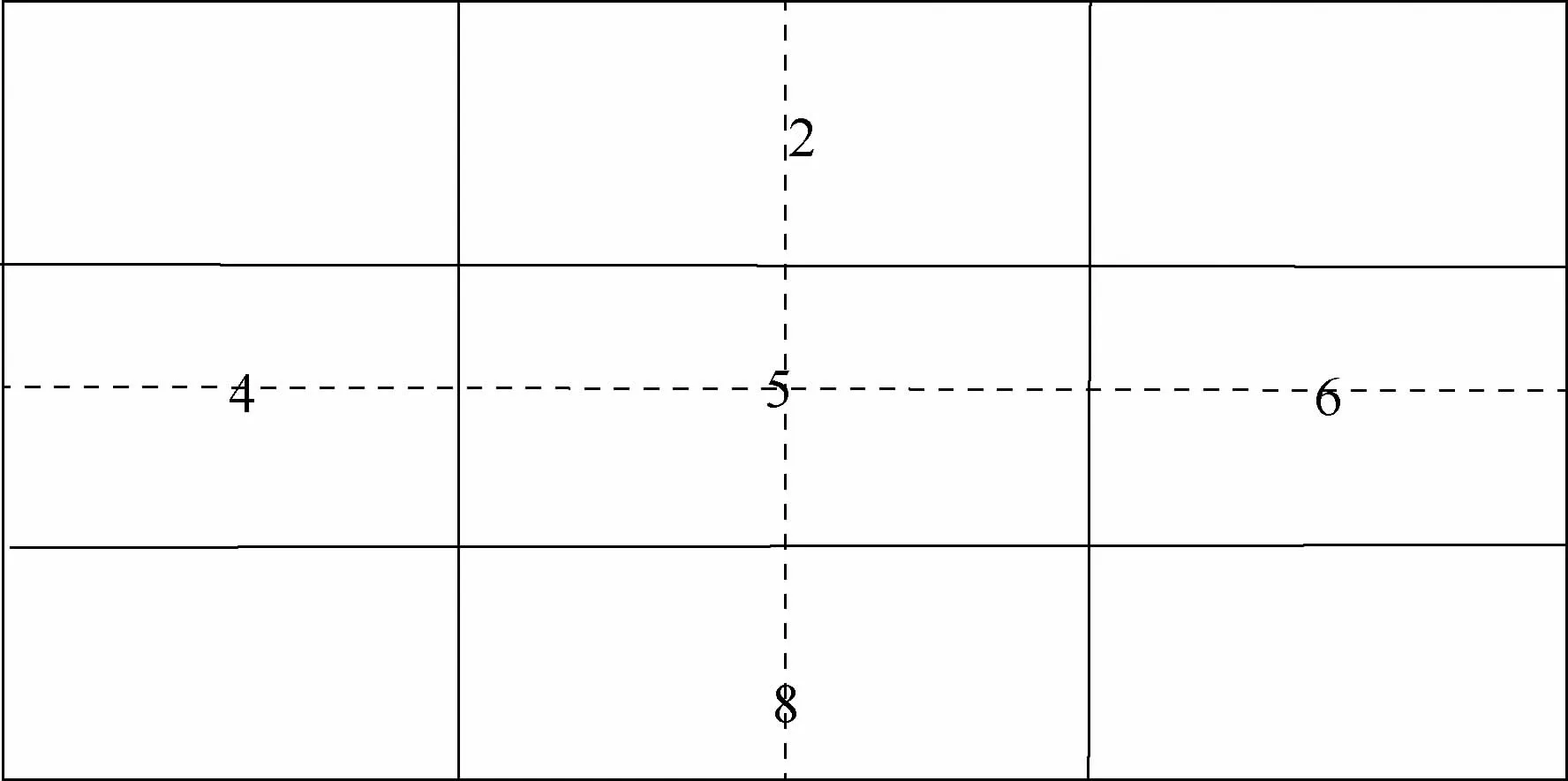
图4 厂站接线图文字识别分割Fig.4 Text recognition segmentation of wiring diagram of plant and station
2.3 厂站接线图中的连接线、拓扑关系识别
在之前的基础之上,可以得到厂站接线图中所有电器元件的个体信息,但是元件与元件之间的连接关系却无法得到,想要获取整幅图像的拓扑关系,需要依据元件之间的连接关系,因此,需要进行连接线识别及拓扑关系识别来找到元件与元件之间的联系,完成厂站接线图的识别任务。
关于厂站接线图拓扑关系识别的工作,主要思想为:利用OpenCV的轮廓跟踪技术[18],检测出每段连接线所连元件,进而得到每个元件的连接关系。使用数字图像处理技术,并与目标检测技术相结合,对厂站接线图进行拓扑连接关系检测。
首先,对目标检测的结果进行提取,将厂站接线图目标检测获取到的各电器元件的位置、种类等信息保存至文件中。然后,对文件进行预处理,为区分开多个同种类部件,对同名元件赋予id属性,并提取出各元件的位置和种类信息。
之后对厂站接线图进行图像预处理。使用高斯滤波平滑处理去除厂站接线图中的无用信息和噪声。通过灰度转换将厂站接线图由三通道图像转换为单通道图像,提升对接线图的处理速度。最终通过二值化处理使线条轮廓更加清晰,提高后续检测的精确度及效率。其中,高斯滤波平滑处理中高斯函数的公式如下:

式中:(x,y)代表像素值的坐标信息;θ为正态分布的标准偏差。
对厂站接线图数据的特征进行预处理即去除图像中的目标元件,只保留除图元外的其他像素信息,以便后续提取出元件间连接线的轮廓信息。
针对电力厂站接线图像素信息的特点,使用轮廓跟踪算法,将提取后的各轮廓坐标信息保存。同时,对保存的各轮廓进行筛选判断,只保留与目标元件连接的连接线轮廓信息。即比较轮廓信息和提取的目标检测的结果,只保留符合如下公式条件的轮廓坐标信息,并删去进行判断后不包含任何坐标信息的轮廓:
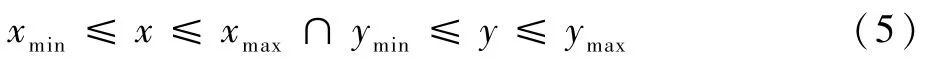
式中:xmin、xmax、ymin和ymax为目标检测的坐标信息;x和y为各轮廓坐标信息。
最终根据提取的连接线外轮廓坐标信息和电器元件的种类、位置信息,解析出各连接线的连接关系,将连接线的连接关系转换为元件的拓扑连接关系。
2.4 人工维护的厂站一次接线图自动校核
本模块将厂站一次接线图和人工维护的厂站一次接线图的拓扑检测结果进行提取,将元件的连接关系进行抽象,抽象成2张无向图,再通过子图同构匹配算法对2张无向图进行匹配,得到2张图的映射关系,来对手工图的错误进行核验。同时,通过提取拓扑检测时的线条轮廓序号来确定每个元件连接的相对位置关系,从而解决了2张图在拓扑关系检测时的序号命名问题。最终将子图匹配算法与节点遍历匹配方法的结果进行对比,验证本文方法具有更高的准确率。
2.4.1 子图匹配算法
将2张图抽象化为无向图后再进行匹配,最常见的方法是将2张图中的节点进行遍历,并根据节点值进行一一匹配,这种遍历方法在数据规模较大时,时间开销过大,并且不能很好地反映2张图之间的拓扑关系。
在对厂站一次接线图进行核验时,使用的是子图匹配算法,子图匹配是无向图中一种常见且实用的查询方法,其优势是:可以很好地利用节点间的连接关系,并可以大大减少遍历所需的时间消耗。这里采用的子图匹配算法是VF2算法[19],其是一种子图同构算法,子图同构算法用于识别图中节点对之间的结构关系,属于精确匹配。Foggia等[20]对Ullmann、SD、Nauty、VF和VF2等算法进行了比较,认为VF2算法对稀疏图或小型图的效率较高,对于二维网状的规则图,VF2算法的效率明显高于其他算法。由于厂站接线图的结构属于规则图,本文采用VF2算法会有更好的效率[21]。VF2算法通过在深度优先的搜索过程中利用高效剪枝的方法实现了子图匹配,最优情况下时间复杂度为Θ(N2),最差情况下时间复杂度为Θ(N!N)[22]。
由于原始的VF2算法对于检测结果没有很好的容忍度,需要检测精度足够高时才会有效,对VF2算法进行改进,将查询图划分为若干个不同的子图,将划分的子图分别与原图进行匹配。其中,划分的子图数量取决于前一步的拓扑关系识别得到的拓扑关系条目数。
2.4.2 接线图校核过程
1)将2张图(target与query)拓扑结构检测的结果进行提取,将不同的元件命名为不同的节点,根据节点间的连接关系抽象为2张无向图。
2)将query图划分为若干个子图,所有子图合并为一整个查询图集(querySet)。
3)提取在拓扑关系检测中得到的线条轮廓序号,分别确定每个元件的相对位置关系。
4)使用VF2算法对querySet中的每一个子图与target图进行一一匹配,根据匹配的子图数计算2张图的匹配率。
5)将匹配率与最初设定好的匹配率阈值进行比较,若超过则手工图无误;若未得到2张图的映射关系或匹配率未达到阈值,则手工图有误,2张图不匹配。
2.4.3 分析与总结
本模块主要对2张图的拓扑关系进行匹配,来辅助手工图的核验工作,其中使用了VF2算法来对2张接线图进行图匹配。本文对算法进行了改进,解决了原VF2算法对数据容忍度差的问题;提取了拓扑检测时的线条轮廓序号信息来确定每个元件的相对位置关系;解决了2张图中元件序号命名不统一的问题。最终将该方法与传统的遍历方法进行对比,可以看出准确率有明显提升。
3 变电站一次接线图数据集构建
本文的数据集是选取某供电公司部分变电站的一次接线图和人工维护的一次接线图作为研究样本。
3.1 数据集整理及标注
数据集共有93张变电站一次接线图,其中电子图79张,人工图14张,在图5和图6中展示了电子图和人工图的样例。对数据集图片进行人工标注,标注为pascal voc格式。标注的内容是厂站一次接线图中的电器元件类型和电器元件位置。通过数据标注软件labelImg对图片中各类电器元件进行标记框选,整理为xml文件作为接线图图片训练的标签。标注类别共17类,分别为避雷器(blq)、变压器(byq)、电抗(dk)、电力电感器(dldgq)、断路器(dlq)、电容(dr)、刀闸(dz)、隔离手车1(glsc1)、隔离手车2(glsc2)、接地(jd)、接地刀闸(jddz)、母线(mx)、电压互感器(pt)、熔断器(rdq)、所变(sb)、手车开关(sckg)、忽略部件(ignore)。数据集大约共有11 500个标注框。
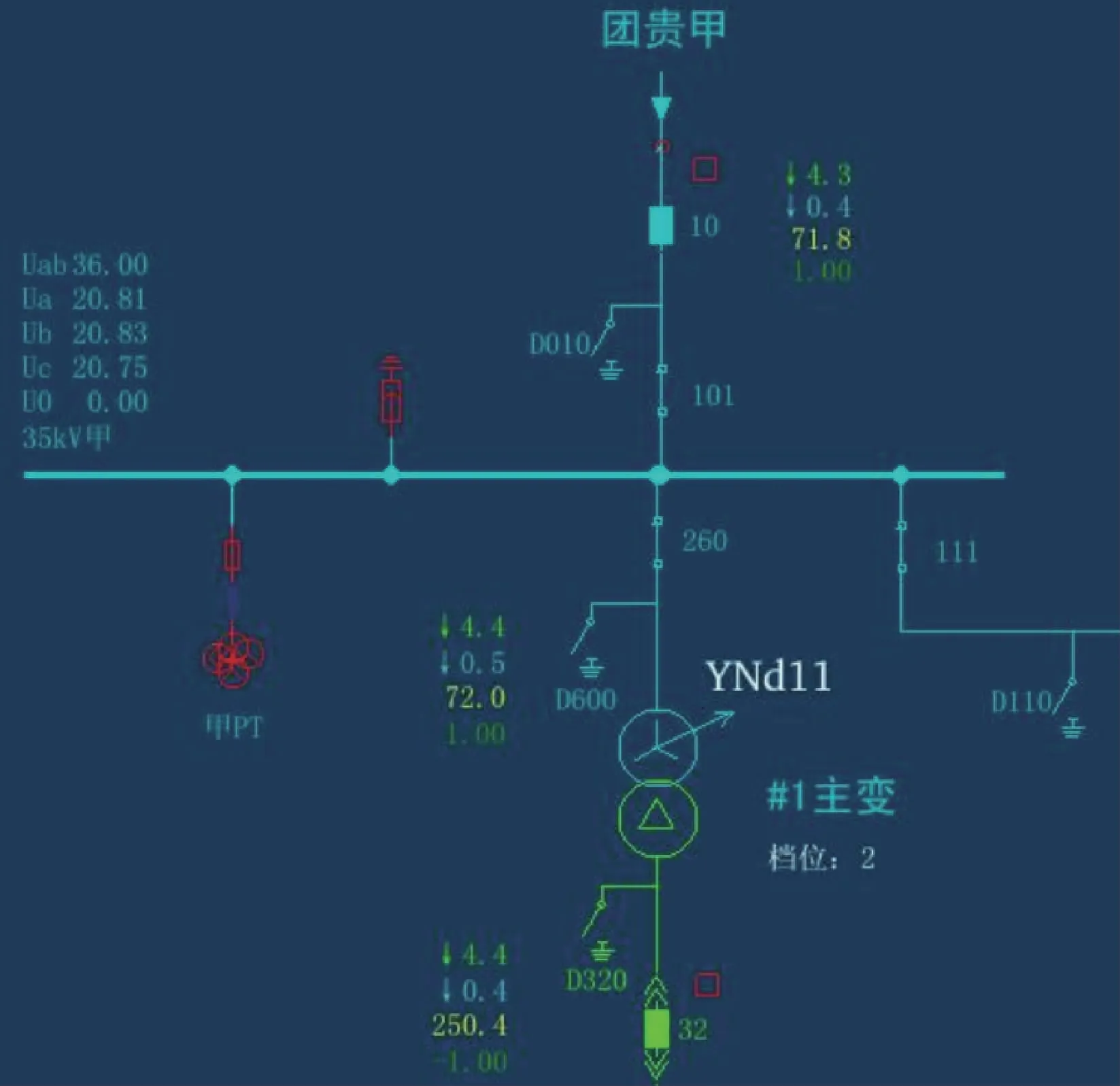
图6 人工图示例Fig.6 Example of manual wiring diagram
3.2 数据集处理
标注好的数据集,厂站一次接线图分辨率过大需要做分割处理,因此对于数据集中的接线图,采取分割图片及其对应xml文件的方法构建出新的分割图数据集。其中,分割图数据集共有316张电子图和56张人工图,类别是和接线图相同的17类。因此,数据集可以分为2部分,即接线图原图数据集和分割图数据集,以便应用于改进的检测算法中。
4 实验结果与分析
实验环境包括:Ubuntu 16.04.6 LTS操作系统、NVIDIA TITAN XP 显 卡、12196MiB 显 存、CUDA10.1、OpenCV2.4.9等。
4.1 厂站一次接线图电器元件识别的实验结果
厂站一次接线图中的电器元件识别部分分别采用基于Paddle深度学习框架的YOLOv3算法和基于Tensorflow框架的Faster R-CNN模型。
对于厂站一次接线图中的电子图,采用2种数据集的形式,分别为接线图原图数据集和每张接线图分割为4份后的分割图数据集。对于YOLOv3,直接使用分割图的数据集进行训练,训练集244张,测试集72张。对于Faster R-CNN模型,先采用原图数据集进行训练,其中训练集63张,测试集16张;再采用多尺度融合的检测算法,使用分割图的数据集训练出小图模型,并将两者的结果进行融合。
由于电子图和人工图略有差异,为了提高核验的效果,需对模型进行finetune,使其更加适用于人工图的电器元件检测。对于大图模型,采用11张人工图作为训练集,3张作为测试集。对于小图模型,采用44张分割的人工图作为训练集,12张作为测试集。在基于训好的电子图的模型权重条件下,使用较少的人工图数据集进行finetune。为了防止过拟合,使用更低的学习率0.0001进行训练。
在训练的过程中,初始学习率设为0.001,momentum设为0.9。YOLOv3使用darknet-53的预训练权重,Faster R-CNN选择ResNet101的预训练权重。YOLOv3在迭代140 000 epoch后,loss趋于稳定。Faster R-CNN在迭代100 000 epoch后,loss趋于稳定,数值在0.3左右,finetune迭代70 000 epoch后loss稳定在0.3左右。表1为YOLOv3和Faster R-CNN实验结果的对比,采取的评判标准是检测准确率。将IoU大于0.5且类名正确的样本视为正样本,通过计算正样本和总样本的比作为检测准确率。其中,17种待识别的器件在数据集中的数量分布并不均衡,表1中的平均检测准确率是通过计算测试集中图片的所有种类器件正样本和总样本中的比得来的。虽然YOLOv3的检测准确率结果中有7种器件优于Faster R-CNN融合算法,如隔离手车、所变、电压互感器等器件,但这些器件在接线图中出现的频率并不高,所以YOLOv3的检测效果并不如Faster R-CNN融合算法。根据得出的平均检测准确率结果可以看出,多尺度融合后的Faster R-CNN算法效果最佳。
4.2 厂站一次接线图文字识别的实验结果
厂站一次接线图中的文字、数字识别部分分别采用了2种方法。两阶段的识别方法有Advanced EAST和Tesseract OCR。端到端的识别方法有Attention-OCR方法。
首先,采用Advanced EAST模型和Tesseract OCR模型。采用标注文本框的数据集训练基于Keras框架的Advanced EAST模型;获取出接线图文字区域图片,通过jTessBoxEditor对文字图片中的每个字符进行标注,使用Tesseract OCR构建接线图的专属字库。
然后,采用端到端的Attention-OCR方法,其基于Tensorflow框架,其中Cascade R-CNN采用ResNet101-FPN作为骨干网络,预训练权重来自ICDAR2017RCTW[23]数据集。Attention-OCR使用InceptionV4[24]作为骨干网络,预训练模型由ImageNet数据集得来,之后通过多个包含不规则多方向的文本数据集(如LSVT、COCO-Text、ICDAR2017等)训练模型。
表2为2种方法的结果对比。文本区域检测采用目标检测的评判标准,以IoU大于0.5的样本判断为正样本。文本识别部分以每一个字符的准确率作为评判标准。可以看出,无论是文本区域检测还是文本识别,Attention-OCR方法的效果都要优于Advanced EAST和 Tesseract-OCR 的结果。

表2 文字识别实验结果对比Table 2 Comparison of text recognition experiment results
4.3 厂站一次接线图拓扑关系识别的实验结果
厂站一次接线图拓扑关系识别主要采用的是图像处理技术,其拓扑关系识别的准确率较为依靠电器元件识别的准确率。对于电子图和人工图,在进行图像预处理的过程中选择了更加适用自身的不同参数。对每张测试图片的拓扑关系进行人工标注,在对测试图片进行拓扑关系准确率计算后得出准确率约为87.7%。其具体情况如表3所示。

表3 拓扑关系识别测试结果Table 3 Test results of topological relation recognition
4.4 厂站一次接线图自动校核的实验结果
人工维护的厂站一次接线图自动校核技术采用的是子图匹配算法,选用的子图匹配算法是VF2算法。由于子图匹配算法本身存在对数据容忍度差的问题,因此对算法进行了一定程度的改进。通过自动校核技术来对接线图及其对应的人工图的人工校验提供辅助,输入为2张图的拓扑关系识别结果,输出为2张图的匹配率。这里没有使用改进前的VF2算法的匹配结果,因为原VF2算法用于拓扑关系匹配时,只能用于判断查询图是否为目标图的子图。由于拓扑关系识别不能完全精准地还原2张图的拓扑关系,一旦有一个节点不匹配,VF2算法输出的结果便是0,这也是对VF2算法进行改进的原因之一。从测试数据中挑选出4组清晰且完好的测试图,分别对这4组数据进行测试,分别使用遍历的方法及改进的VF2算法2种方法,通过计算匹配的子图数与总子图数的比例得到其对应的匹配率,结果如表4所示。可以看出,改进的VF2算法在8组数据上的匹配率均在50%以上,明显高于遍历方法匹配的结果。将匹配的阈值设定为0.6,即匹配率超过该阈值则判定这一组电子图与人工图正确匹配,否则将判定为错误匹配。此时,改进的VF2算法对于厂站一次接线图的自动校核对数据有更好的稳定性和更好的准确率,其准确率为62.5%,而遍历方法的准确率较低只有25%(即8组结果中只有2组的匹配率高于阈值0.6)。
将电子图和人工图的匹配结果可视化,绿色框表示匹配部分,未匹配的元件在原图中用红框的形式标出,匹配可视化结果如图7和图8所示。
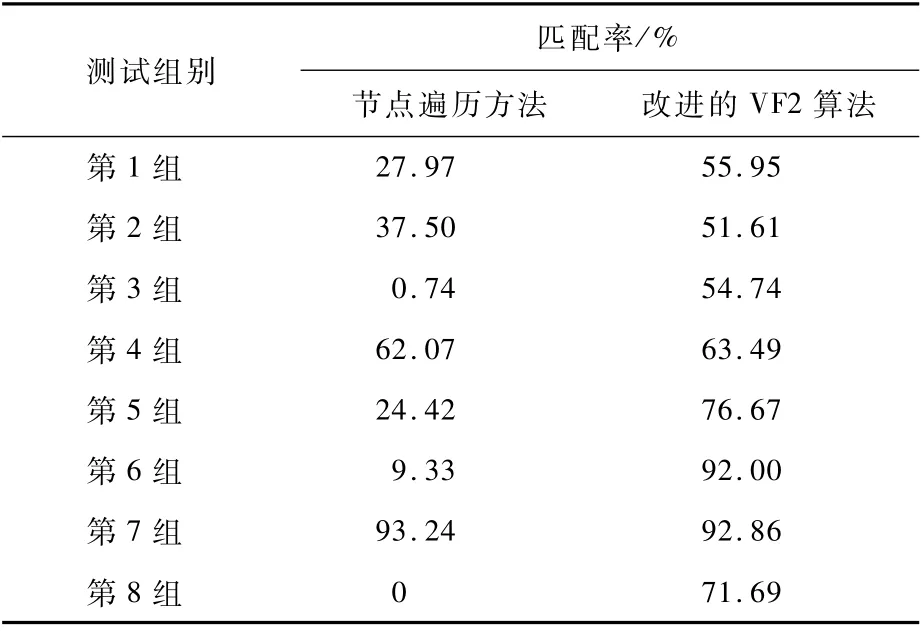
表4 两种方法的匹配率结果Table 4 Matching rate results of two methods

图7 电子图匹配结果Fig.7 Matching results of electronic wiring diagram
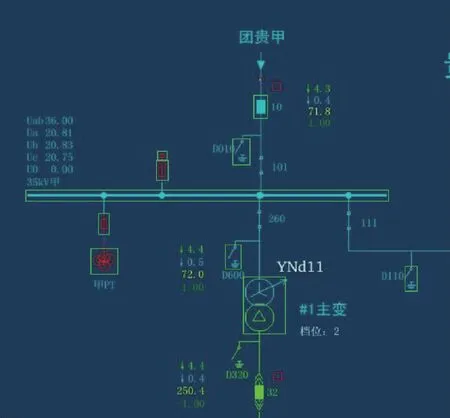
图8 人工图匹配结果Fig.8 Matching results of manual wiring diagram
5 结 论
1)本文实现了厂站一次接线图的自动识别和自动校核,极大提高了电力厂站一次接线图绘制和管理工作的自动化程度。
2)对厂站一次接线图中电器元件的目标检测、文字识别和拓扑关系检测均可达到较高的准确率。
3)改进的VF2算法相比于节点遍历的匹配方法,可以提高37.5%的准确率,大大降低了人工干预的成本。
目前,对于厂站一次接线图的自动识别和自动校核工作仍有些许不足。对接线图电器元件的目标识别和文字识别仍需继续提高准确率。对接线图的拓扑关系识别及自动核验需要加快对图片的处理速度,提高厂站一次接线图的自动识别和自动校核的效率。未来将及时关注最新的目标检测、文本检测和文本识别等算法的发展,改进方法提高检测和识别的准确率。对于拓扑关系识别和自动核验,将继续改进算法提高对检测结果的容忍度,提高识别和核验的效率。
猜你喜欢
军事文摘(2022年8期)2022-11-03
汽车实用技术(2022年11期)2022-06-20
机械科学与技术(2022年2期)2022-03-30
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
哈哈画报(2021年11期)2021-02-28
健康体检与管理(2021年10期)2021-01-03
科学与财富(2017年22期)2017-09-10
家教世界·创新阅读(2016年9期)2016-05-14
