
基于多特征图像视觉显著性的视频摘要化生成
2021-04-13 01:59金海燕曹甜肖聪肖照林
北京航空航天大学学报 2021年3期
金海燕,曹甜,肖聪,肖照林,*
(1.西安理工大学 计算机科学与工程学院,西安710048; 2.陕西省网络计算与安全技术重点实验室,西安710048)
如何以最为直观且快速的方式查阅视频数据,完成像文字搜索一般的浏览效率是计算机视觉与图像处理领域的研究热点。视频摘要是对原始视频内容的高度浓缩,其将重要且具有代表性的视频内容以一种简洁的形式呈现出来,方便用户对视频的浏览和管理[1]。
2017年,刘全等[2]使用带视觉注意力机制的循环神经网络(RNN)改进了传统的深度Q网络模型,提出了一种较为完善的深度强化学习模型。2018年,郎洪等[3]提出一种鲁棒主成分分析(RPCA)优化方法,为了快速筛选与追踪前景目标,以基于帧差欧氏距离方法设计显著性目标帧号快速提取算法。2019年,张芳等[4]为准确检测复杂背景下的显著区域,提出了一种全卷积神经网络与低秩稀疏分解相结合的显著性检测方法,结合利用全卷积神经网络学习得到的高层语义先验知识,检测图像中的显著区域。李庆武等[5]针对现有显著性检测算法检测目标类型单一、通用性差的问题,提出了一种基于无监督栈式降噪自编码网络的显著性检测算法。2020年,陈炳才等[6]提出了一种融合边界连通性与局部对比性的图像显著性检测算法,得到的显著图更接近于真值图。
由于现有视频数据量过于庞大,占用内存资源较多,在浏览时比较困难。本文基于多特征图像和视觉注意力金字塔模型,提出了一种改进的可变比例及双对比度计算的中心-环绕视频摘要化方法,通过提取的关键帧快速理解视频的主要内容。本文方法不仅易于实现,还改善了传统方法的提取效果。在Segtrack V2、ViSal及OVP数据集上进行仿真实验,验证了本文方法的有效性。
1 相关工作
1.1 视觉显著性
在某一场景中,能够令人眼所引起注意的区域就是该场景中最显著的区域,场景其余部分则可能不会被人眼所注意或考虑在内。通过不同方式满足人眼的机制并遵循人眼视觉习惯所进行的检测,即为视觉显著区域的检测。
2017年,Ablavatski等[7]设计了一种改进的基于注意力的体系结构,用于多对象识别;Qu等[8]为了解决僵化的描述问题,提出了一种神经和概率框架,将卷积神经网络(CNN)与循环神经网络相结合,以产生端到端的图像字幕。2019年,Liu和Yang[9]提出了一种“前景-中心背景”显著区域检测模型,提高了显著性检测的性能。
1.2 视频摘要化
现有的大部分视频摘要都为静态视频摘要。2016年,Li等[10]开发了一种用于在Internet上搜索结果的多媒体新闻摘要的新颖方法,可发现与查询相关的新闻信息中的基本主题,并将每个主题中的新闻事件穿线以生成与查询相关的简要概述。2018年,Hu和Li[11]通过融合基于多个特征和图像质量的全局重要性和局部重要性来生成动态视频摘要。Meng等[12]选择在不同视图之间代表视频的视觉元素,使用质心共正则化方法的多视图稀疏字典选择,优化了每个视图中的代表性选择,并通过将它们针对共识选择进行正则化来强制将视图特定的选择相似。
1.3 关键帧提取中的图像特征
颜色特征作为较为常见和易于获得的信息为特征提取时所广泛采用。除了颜色以外,图像的纹理也是视频摘要化的常见特征。作为一个图像或物体表面具有的固有特性,纹理特征通过空间中的某种形式的颜色变化而产生不同的图案,并通过对图像进行量化产生特征结果。LBP(Local Binary Pattern)算子是最常见的原始特征算子之一,所提取出的特征即为图像中局部位置的纹理特征。
2 显著性检测
2.1 超像素分割预处理
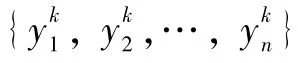
2.2 双对比度金字塔显著性检测
计算RG、BY颜色分量及亮度特征分量。其中,亮度分量Intensity=(R+B+G)/3,红-绿颜色分量RG=R-G,黄-蓝颜色分量BY=B-(G+R)/2。对已进行超像素分割的图像序列,为每一个图像特征通道构建中心金字塔与环绕金字塔的尺度空间。设每一个图像的中心金字塔为C,C={C0,C1,C2,…,CN},每一个图像的环绕金字塔为s,s={S0,S1,S2,…,SN}。本文N的值为5,即金字塔的层数为5。同样,每一个中心金字塔图像Ck都有一个与之对应的环绕金字塔图像Sk。其中,环绕金字塔图像Sk是由中心图像经过高斯平滑处理所得到。高斯平滑因子为

式中:μs为环绕金字塔图像Sk的平滑因子值;μc为用于得到中心金字塔图像Ck对应的值。因此,算法可以自由动态地调整平滑因子的值大小,产生更多的灵活性来适应系统,从而在之后的计算中得到更好的效果。
对每一个图像特征通道计算中心-环绕对比度。设中心金字塔中第i层图像为Ci,环绕金字塔中第i层图像为Si,由式(2)、式(3)分别得到正-负对比度Contrast+和负-正对比度Contrast-。

同时,将数值中所有小于0的特征值统一设为0。在得到对比度结果后,将所有特征图按照正-负对比度与负-正对比度2类进行加法求和。
2.3 光流信息提取
设像素点p(x,y)在某个时间段t内移动的距离为(d x,d y),原像素点表示为p(x,y,t),变化移动的点表示为p(x+d x,y+d y,t+d t),考虑亮度恒定的情况,得到
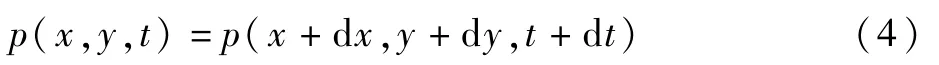
根据亮度恒定得到的公式以灰度值进行空间坐标位置求导,得到泰勒级数展开公式,进一步得
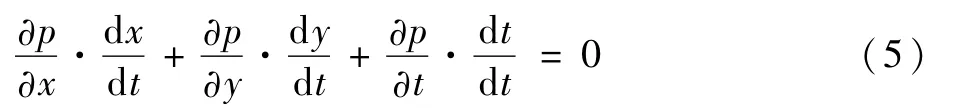
d x/d t、d y/d t分别为X、Y轴方向点以灰度信息来描述的值的变化速率,设为U、V;而∂p/∂x、∂p/∂y、∂p/∂t分别为二维图像上X、Y、t方向的偏导,设为px、py、pt,由此得到光流法公式:

px、py、pt即为根据图像序列在(x,y,t)上的差分。由于式(6)中存在2个未知变量的情况,在求得式(6)后,需要多加一个约束式来得到光流场计算结果。这里使用Lucas-Kanade光流法方式来增加约束。
2.4 前后帧图像抑制法的光流检测
在动态检测时,可能会由于经常引入不相关的背景或线条轮廓内容,对检测产生较大影响,且在融合时并不能完全削减这部分噪声。以颜色直方图方式统计前后图像内颜色的占比,设当前帧的颜色直方图为Histi,前一帧为Histi-1,若相邻2帧相似度较高,则2帧之间的相似性可以描述为

式中:j为颜色分量;N为总颜色量级数目;j∈N;D为2帧的相似性表示。
因此,构建加权函数W如下:
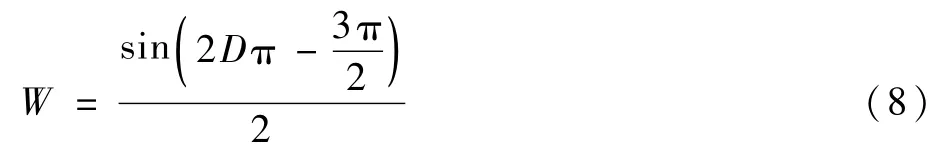
最终融合时,按式(9)进行:
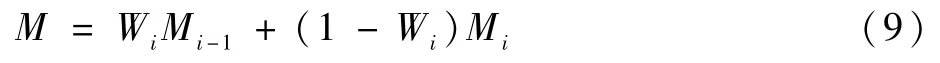
式中:Mi-1表示前一帧图像的运动显著性结果;Mi表示当前帧的运动显著性结果;M为最终运动显著图。

图1 动态显著图调整效果前后对比Fig.1 Effect comparison of dynamic saliency map before and after adjustment
图1展示了经过调整前与调整后的动态显著图效果,并用椭圆形标出了调整后产生改进的区域。
2.5 显著性图像计算及自适应融合
设Mi为运动显著结果,Ji为静态显著结果,通过difi将权重系数归一化至[0,1],如下:
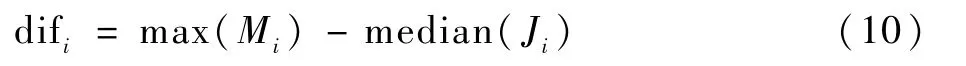
并通过式(11)完成融合:
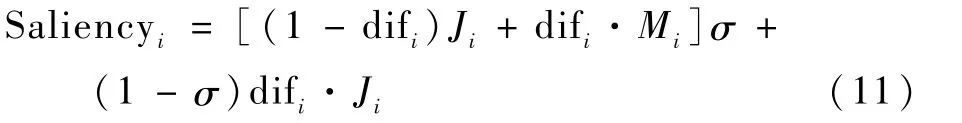
式中:σ为比例系数,本文设为0.4。
显著结果自适应融合如图2所示。

图2 显著结果自适应融合Fig.2 Adaptive fusion of saliency results
3 关键帧提取
在关键帧提取前,对连续视频图像序列进行显著性目标检测的目的是为了能够预先完成显著前景目标的提取,同时提升关键帧提取阶段的检测准确率与效果。本节主要方法内容和整体技术框架如图3所示。
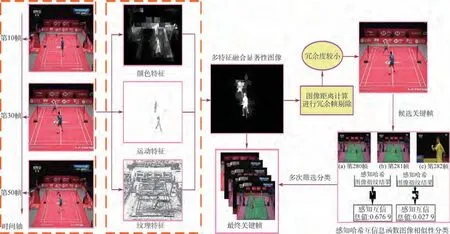
图3 关键帧提取主要方法内容和整体技术框架Fig.3 Main method content and overall technical framework of key frame extraction
3.1 LBP纹理特征提取
通过尺寸为3×3的基准检测窗口进行0、1标记,形成二进制的特征值结果,如下:

式中:g(j)为基准窗口内第j个点的灰度;g(i)为中心点对应的值。
根据旋转不变原则,最终的特征值为

3.2 显著性检测效果增强及颜色特征提取
取显著性检测结果与原始视频中同一帧图像进行对应相乘。先得到原图像R、G、B分量,设为fR、fG、fB,设当前帧显著性结果图像为F,将结果F分别与fR、fG、fB对应相乘,得到增强的显著性结果F′,如图4所示。

图4 显著性检测效果增强结果Fig.4 Enhancement results of saliency detection effect
将图像从RGB空间转化为HSV空间,再分别提取H、S、V三个分量结果,将H、S、V三通道按照16∶4∶4的等级进行量化;之后将所有的颜色分量按比例等级融合形成特征矢量,如下:

式中:Qs和Qv为量化的等级。
将颜色空间进行量化,并将量化后的颜色根据式(15)进行融合并映射,映射的像素值范围为[0,255],得到相乘图颜色信息。
3.3 哈希函数相似性计算
基于内容的感知哈希(Perceptual Hash)函数是一种用于获取图像哈希值,并用其来描述的特征相似性表示方法。根据值的对比计算,可以得到2幅图像基于汉明距离的相似性程度结果。
调整图像分辨率大小统一至32×32范围,并转换多通道图像为单通道,完成离散余弦变换(DCT)。此步是为了将图像具有的位置特征转移至频域当中,并能够对图像进行良好的压缩,且保持无损转换。基于DCT的对称变换方式,待图像转为频域下的特征编码后,反方向DCT得到原先的特征信息,具体的DCT变换如式(16)、式(17)所示。
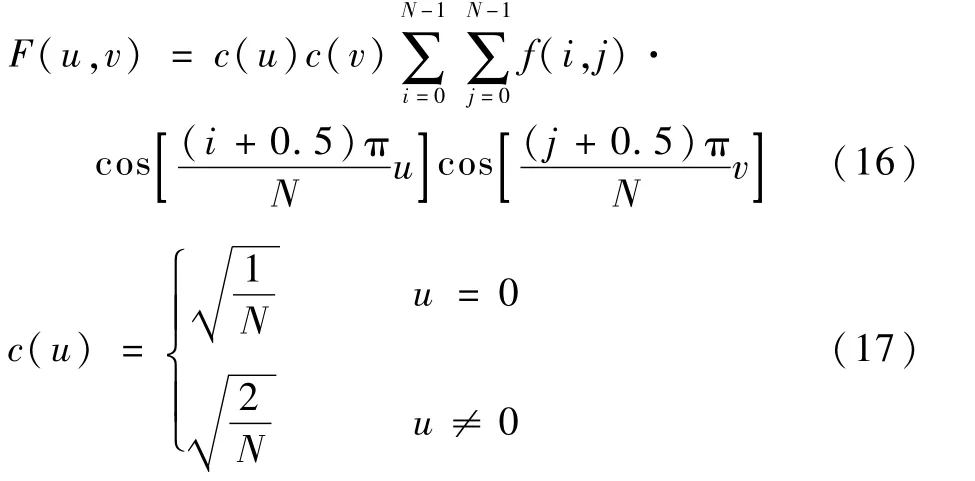
式中:F(u,v)表示DCT变换结果;N为像素点的数量;c(u)c(v)为DCT变换中的正交变换矩阵;f(i,j)为DCT变换前原始像素点的值。
在得到32×32大小的图像区域后,只取图像矩阵中左上角位置中大小为8×8区域的像素点坐标值矩阵,此部分区域可以表示整幅图像当中频率信息最低的区域。按式(18)计算图像区域内64个像素点的平均像素大小¯p′:

式中:pi为像素点大小。
计算比较像素点与¯p′的大小得到完整的pHash值,即图像的感知哈希值,并计算2个不同图像间pHash值的汉明距离。
3.4 基于哈希函数互信息计算
互信息是指在2个不同的个体中,相互之间包含对方信息内容数量多少的描述,属于信息论理论范畴,其基于熵的概念来进行2个物体的计算,公式如下:

式中:p(xi)为基于事件xi的概率数值;I(xi)为具体内容信息的量。则2个随机变量间熵对应的联合信息期望值可表示为
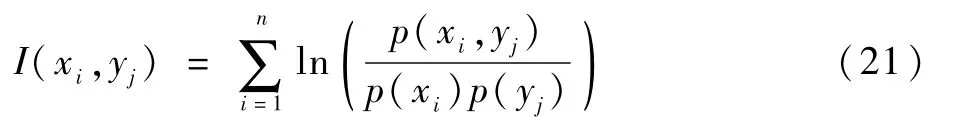
若(x,y)对应的联合分布用p(x,y)表示,对应的边缘分布用p(x)、p(y)表示,联合与乘积分布p(x,y)、p(x)p(y)相对熵的结果即为I(x,y),即互信息:

根据式(20),得到对于图像中的互信息为

本文基于感知哈希函数进行图像相似性计算,结合连续前后帧图像的pHash图像,进行相似性计算。
图3中展示了2018年羽毛球汤姆斯杯丹麦对阵马来西亚比赛视频中第280帧、第281帧、第282帧图像中的感知哈希图像结果。其中,第280帧和第281帧属于同一镜头下的相似场景图像,而第281帧及第282帧图像则发生了跳变,图中展示了这连续3帧图像的互信息值变化。
3.5 摘要化生成
将得到的所有图像的纹理信息、所有显著增强图像的颜色信息及光流法得到的光流信息进行融合,将每个特征图像对应的图像矩定义为矩阵A、B、C并按列拼接,形成融合的特征向量矩阵[A B C]。计算前后2个特征矩阵之间的欧氏距离,其距离定义为其中所有元素间欧氏距离的累加和。根据欧氏距离计算特征矩阵之间的相似性,以距离的平均值进行冗余帧剔除,小于距离平均值的帧被舍弃。
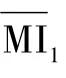
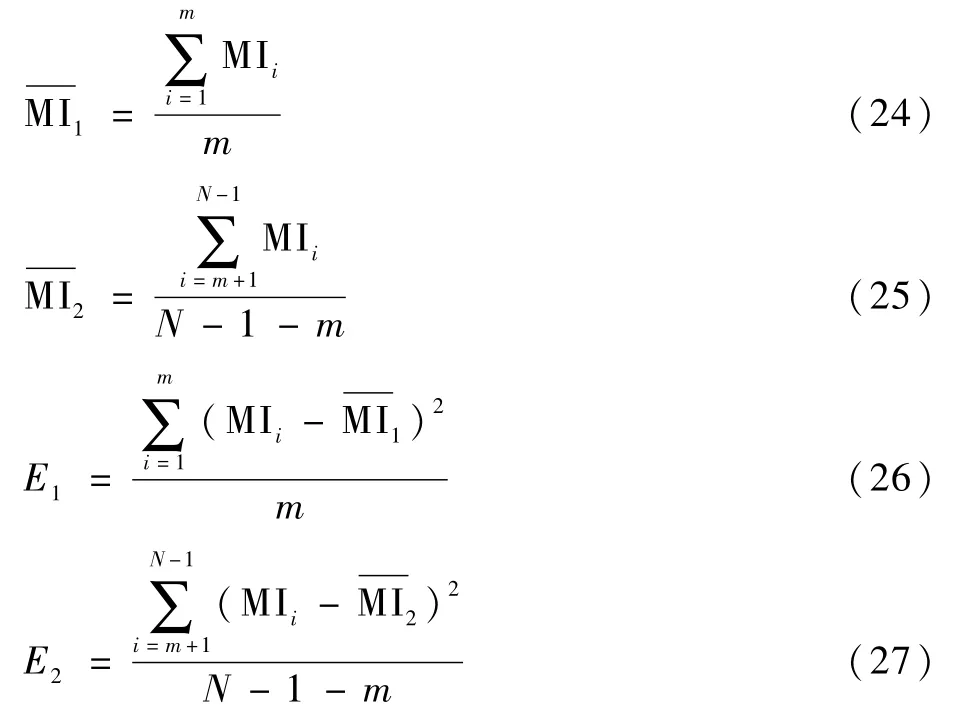
假设满足式(26)的最小I(X,Y)值为筛选分界值:
小于此值的图像帧分为一类,否则另归为新的一类,得到划分后的关键帧类别序列f2={Cluster1,Cluster2,…,Clustern}。
设已划分的2个相邻关键帧集合Cluster1与Cluster2的互信息值为MI(Clusteri,Clusteri+1),则MI(Clusteri,Clusteri+1)=
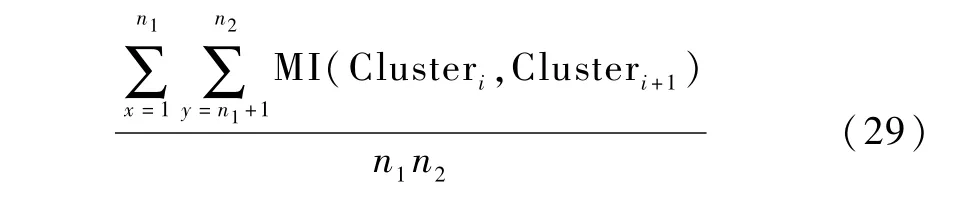
式中:n1和n2分别为关键帧类别Clusteri和Clusteri+1中图像的数量;MI为结果,即当前关键帧类别集合与关键帧类别集合的图像互信息值,定义为2个集合中所有图像与除本身之外的所有其他图像的互信息值和的平均值。
根据特定阈值进行关键帧分类结果合并。将2个集合的互信息值与阈值进行比较,合并规则与相邻图像间的筛选方式相同,最终得到经合并后一定数量的分类集合f3={Cluster1,Cluster2,…,Clustern}。最终挑选每一集合中与集合内其余图像MI相比最大的图像帧为当前集合的代表。
4 实验及分析
4.1 显著性数据集
在显著性检测的过程中,实验所使用的图像数据来源于Segtrack V2、MSRA[3]及ViSal数据集。Segtrack是一种视频对象分割数据集,同时也作为显著性检测的数据集,Segtrack V2是Segtrack数据集的扩大版本,主要包含人类奔跑、鸟类、猎豹、羚羊等动物的运动视频;MSRA则包含约5 000张图像,囊括了各类场景图像,且都包含了真值图像ground truth;ViSal则同样是用于目标检测的数据集,且其中的数据都是视频形式。
4.2 视频摘要数据集
本文所使用的数据集包括了YouTube、OVP(Open Video Project)等公共视频数据集。以运动视频为研究对象,采集了网上大量的室内羽毛球比赛运动场景视频。YouTube数据集格式为MPEG,视频分辨率大小为352×240;OVP数据集的格式包括FLV和AVI两种,类型包括新闻、动画、广告、电视剧、比赛视频等不同的场景。室内羽毛球比赛场景视频则包括2018年世界羽联年终总决赛男单决赛、2018年羽毛球汤姆斯杯丹麦对阵马来西亚、2019年世锦赛第二轮戴资颖对阵菲迪亚尼等的比赛视频,皆为MP4、1 280×720分辨格式。在运动视频的用户摘要确定过程中,选择10位同学进行人工筛选,在预先不告知内容重点的情况下,得到10位同学的关键帧摘要结果,并对这10种结果中相似的视频帧计算帧数平均值得到最终的用户摘要结果,确保用户摘要的客观及合理性。
本文对多特征融入后的距离计算剔除冗余帧的过程中,使用了欧氏距离的平均值作为剔除的阈值。但有时完全通过平均值无法剔除足够数量的冗余帧,仍然会保留一部分无用的帧,该部分图像既会对之后的检测和判断产生干扰,也会降低整体的计算时间效率。根据数据集类型的不同,在平均值的基础上加入了微调因子a,对You-Tube、OVP等数据集设置a=2.5,而对比赛视频数据集设置为a=20。
仿真实验中,人工阈值thresh可以控制最终生成的摘要所包含图像数量的多少。thresh越高,所产生的摘要图像数量越少;反之越多。经过实验分析,对YouTube、OVP等数据集设置thresh=0.5,对运动视频数据集设置为thresh=1.2,使得结果达到了最佳。
4.3 显著性检测
本文方法主要与MR[14]、SF[15]、FT[16]、GS[17]方法进行对比,实验结果如图5所示。
MR方法根据图像元素与给定种子或查询的相关性定义图像元素的显著性,将图像表示为以超像素为节点的闭环图,以提取背景区域和前景显著对象;SF方法采用基于对比度的显著性估计抽象出不必要的细节,从元素对比中得出显著性度量,以将前景和背景分开;FT方法可输出具有清晰定义的显著对象边界的全分辨率显著图,通过保留原始图像中更多的频率内容,以保留这些边界;GS方法使用背景先验来计算图像的测地线显著性区域。
从图5可知,MR方法无法有效区分物体中心和图像之间的类别差异;SF方法对于背景明亮的物体同样也会检测出来,抗干扰性较差;FT方法可以快速地检测出图中不同物体间的频谱差,但无法增加具体的细节信息,只能体现对比度信息;GS方法则与之前方法相比效果有所提升,但仍然会有较大的噪声干扰存在。本文方法不但能够准确定位目标,对于前后背景对比度差异较小的图像也能较好地区分出前景目标。本文以Segtrack V2和MSRA为数据展示显著性的F-measure柱状结果差别,如图6所示。
4.4 实验结果及分析
本文选用不同类别视频,如OVP包含的新闻或比赛场景等,并将结果与现有的几种经典视频摘要或关键帧提取算法(如OV[18]、VSUMM[19]、STIMO[20]、SD[21]、KBKS[22]等)进行对比。图7为使用公共摘要数据集中的“v20.flv”动画视频及“v101.flv”新闻视频得出的摘要化结果。
从图7可以看到,在“v20.flv”和“v101.flv”视频中,OV算法在左侧视频中的第1、4帧产生了冗余,右侧视频中第5帧图像出现了冗余,同时在左侧视频中的第2、5、6、8帧出现了检测不准确的情况,检测结果较差;而在VSUMM算法中,左右2段视频中误检的情况比OV算法相比较少,但仍有冗余的情况;在STIMO算法中,左侧视频有8帧图像命中了用户摘要结果,比OV、VSUMM 两种算法的结果要更好一些,但检测出的图片数量较多,也包含了一些冗余的图像;而在SD算法与KBKS算法中,得到的结果基本都包含了用户摘要,只有少量误检的情况,但得到的摘要数量少于真实用户标注结果,无法完整地描述视频的主要内容;在本文中左侧视频产生了13帧摘要结果,其中11帧命中了用户摘要,同时只产生了2帧冗余,在右侧视频中,得到11帧摘要结果,其中11帧命中摘要,只漏掉了用户摘要中的第3帧,表现出了良好的摘要化结果。

图5 数据集在不同方法上的显著性图比较Fig.5 Comparison of saliency maps of datasets among different methods

图6 F-measure在不同数据集上的情况Fig.6 F-measure on different datasets

图7 视频“v20.flv”及“v101.flv”在不同摘要算法下的结果Fig.7 Results of video“v20.flv”and“v101.flv”under different summarization algorithms
在图8中,以2018年世界羽联年终总决赛男单决赛及2018年羽毛球汤姆斯杯丹麦对阵马来西亚两段视频为准,进行结果分析。由于电视中的运动比赛视频分辨率较高,且会出现镜头停留时间较长的情况,一般方法较容易产生检测冗余的现象。在OV算法与VSUMM 算法中,都得到了大于用户摘要数量的关键帧,其中对于镜头产生移动,但基本内容没有产生变化的图像,2种算法都得到了不同数量的相似场景冗余帧。
在OV算法与VSUMM 算法中,左侧视频的第1、2帧及右侧的第4、5、8帧都得到了不同数量的相似场景冗余帧;STIMO算法也是相同;SD算法与KBKS算法则出现了更多;在本文方法中,左侧视频虽然得到的摘要结果数量不足,但9帧的结果中都命中用户摘要,只有漏检的情况发生,而在右侧视频中得到了足够数量的图像结果,用户摘要共13帧,其中有11帧命中用户结果,说明了本文方法的高准确性及低误检率。
为了更加直观地描述不同方法在公开数据集及室内羽毛球比赛运动场景视频数据上的表现,使用准确率、错误率、漏检率、精度、召回率和Fmeasure等指标,分别对实验数据视频依次对比,如表1所示。

图8 运动视频在不同摘要算法下的结果Fig.8 Results of sports video under different summarization glgorithms
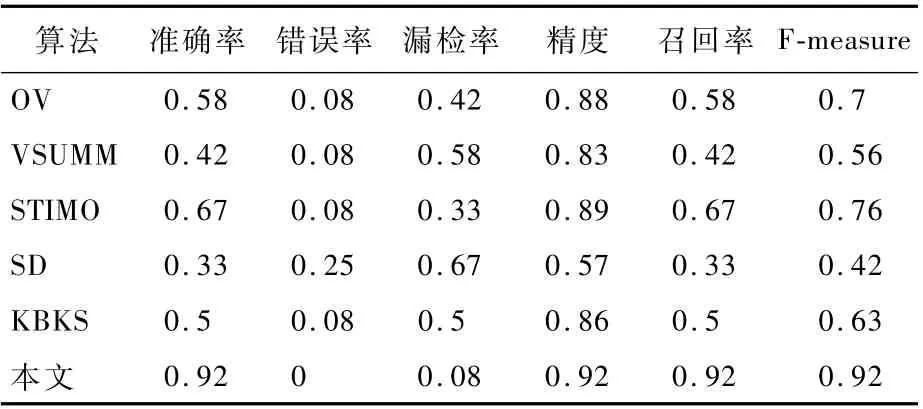
表1 运动视频在不同摘要算法下的对比Table 1 Comparison of spor ts videos under various summarization algorithms
5 结 论
本文以视觉显著性模型为基础,在中心-环绕比金字塔检测模型中融合超像素分割以加速大分辨率图像视频数据的计算,同时选择双对比度方式计算、提取图像中更多的特征信息;在计算运动显著图时,通过前后帧结果抑制的方式生成更佳的动态结果,并使用自适应方式融合得到效果良好的显著结果,良好的显著性结果也为在视频摘要与关键帧选择的过程提供了更多的图像信息。
1)在摘要化生成中,结合了显著性检测及感知哈希互信息方式进行提取。在显著性检测的基础上,利用图像的纹理及颜色等信息,对显著性检测的结果图像进行了二次特征提取并完成相邻图像之间的相似性判断,进行多次冗余帧的剔除及相似图像的类别划分,从而得到属于不同类别的、能够最大程度描述视频的结果。
2)在公共数据集及本文的运动视频数据集上进行了效果对比,验证了本文方法对视频摘要化生成的良好效果和较优表现。
猜你喜欢
现代计算机(2022年4期)2022-04-24
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
中国知识产权(2018年12期)2018-12-29
软件导刊(2018年4期)2018-05-15
中国知识产权(2017年5期)2017-05-25
电脑知识与技术(2017年3期)2017-03-27
现代电子技术(2016年24期)2017-01-19
