
基于对抗和迁移学习的灾害天气卫星云图分类
2021-04-13 01:59张敏靖白琮张敬林郑建炜
北京航空航天大学学报 2021年3期
张敏靖,白琮,2,*,张敬林,郑建炜,2
(1.浙江工业大学 计算机科学与技术学院,杭州310023; 2.浙江省可视媒体智能处理技术研究重点实验室,杭州310023;3.南京信息工程大学 大气科学学院,南京210044)
全球75%经济损失源于灾害天气,每年约1万多人因恶劣天气而死亡[1-2]。灾害天气,包括台风、强对流和沙暴,严重威胁人民生命财产安全,监测灾害天气的形成发展过程是气象灾害预测预报的基础。通过观测卫星云图进行监测是重要的手段之一,因为地球的大部分地区被云覆盖,各种天气现象总是和云有着密不可分的联系。卫星云图是由气象卫星自顶而下观测云层覆盖和地球表面的图像,可以用来识别不同的天气状态,评估其强度和未来发展趋势等,为天气预报和灾害天气预测提供全天候的依据。本文聚焦于卫星云图中的灾害天气分类问题,即在卫星云图数据中分类出带有热带气旋、温带气旋等可能带有灾害天气的云图。但是在实际的卫星云图中,往往是非灾害天气类别的图片占据了原始数据的大多数,而各个灾害天气的数量相对较少,数据呈现了不平衡的分布形态。这样的数据分布使得分类器在进行训练的时候,会比较关注占据数据大多数的非灾害天气样本,故而虽然总体的分类精度高,但是如热带气旋、温带气旋等这些对于实际研究非常具有指导意义的类别,并没有从分类器中得到很好的区分。因此需解决卫星云图灾害天气分类中类间不均衡的问题,才能较好的将各个灾害天气从非灾害天气中区分出来。
图片数据的类间不平衡问题,近年来一直是一个研究的热点[3]。图片数据的类间不平衡是指在分类问题中不同类别的训练样例数目差别很大的情况。这一情况与实际生产生活中的数据分布情况相似,非常具有研究的意义和必要性。2012年Krizhevsky等[4]在ILSVRC-2012[5]比赛中获得了冠军,成功的将深度学习应用于图片分类的问题上[3,6-7],至此之后各类深度学习的框架模型开始涌现。但是研究者主要关注平衡数据分布的数据集,关于长尾分布数据的研究并未深入。尤其是在卫星云图的灾害天气分类问题的研究上,由于原始数据获取和处理的成本较大,相关的分类研究还较少。灾害天气分类问题中类间不平衡问题较为突出,故而本文对不平衡的卫星云图灾害天气分类问题展开研究。
本文针对不平衡卫星云图灾害天气分类,聚焦数据和算法混合的思路,提出了一种结合生成对抗学习(GAN)和迁移学习(TL)的分类训练模型框架,对云图数据分别进行过采样和欠采样处理,并采用迁移学习进行灾害天气云图的分类。通过在自建的LSCIDWS-S大尺度卫星云图数据集进行实验,证明了所提框架的有效性。本文的主要贡献如下:
1)提出了一个GAN+TL的训练模型框架。该框架是针对不平衡卫星云图灾害天气所设计的分类框架,主要由数据平衡化处理模块和图片分类2个模块组成。
2)在该框架中,GAN用于高质量的图片生成,代替传统的简单复制的过采样方法,同时结合了欠采样,对原始不平衡的数据分布进行了均衡化的处理。在卷积神经网络(CNN)分类训练过程中引入了迁移学习的方法,使得整体的分类性能在原有的基础上得到了进一步的提升。
3)实验结果表明,分类器整体的分类性能得到了一定的均衡。这对于实际研究有一定的借鉴意义,即更受到实际应用所关注但容易被分类器忽略的灾害天气样本的正判率得到了一定的提升。
1 相关工作
1.1 生成对抗网络
生成对抗网络(Generative Adversarial Networks,GANs)是在2014年,由Goodfellow等[8]提出。GANs的基本思想是源于博弈论中的零和游戏。它的网络结构由一个生成器(Generator)和一个判别器(Discriminator)组成,生成器的作用是为了尽可能地去学习数据的真实分布情况从而生成数据,而判别器的作用是判断输入的数据是来源于真实的数据还是由生成器生成的,二者之间不断的进行优化从而达到相对平衡。根据生成对抗网络有生成样本的这一特点,DCGAN(Deep Convolutional GAN)[9]为首个将CNN与GAN相结合以生成相应的图片样本,但是生成的图片质量不高并且不稳定。2020年,NVIDIA研究人员发布了StyleGAN2[10],该网络设计了具有非常规的生成器架构,从而可以生成高质量的图片,并且训练过程较为稳定。本文所提方法中的GAN的设计就引用了该网络结构,从而可以生成相对质量较高的过采样样本。
1.2 图片分类中的类间不平衡问题
关于图片数据类间不平衡的研究主要可以分为3层次:数据、算法和数据算法的两相结合[3,11]。关于数据层面的研究主要是对原始不平衡的数据进行均衡化的处理,把不平衡的数据转化为相对平衡的数据再加入模型中展开之后的训练。Hensman和Masko[11]提出了提升样本的解决思路,主要是对样本中数量较少的类别,对其进行简单的复制从而达到扩充样本数量的效果,该方法虽然简单但是性能提升有限。基于算法层面的改进,主要是对损失函数的重新设计以及学习方式的改进。Wang[12]等提出了MSFE(Mean Squared False Error Loss)函数,该损失函数可以很好的平衡大样本和小样本之间的关系,从而也可以达到较好的分类性能。数据与算法的结合则是一种数据和算法混合的方法,如He[13]等提出的LMLE(Large Margin Local Embedding),该方法采用了5倍抽样法和THL(Tripleheader Hinge Loss)这一损失函数。本文所提框架是结合了数据和算法混合的方法,在数据层面上进行了包括对原始数据欠采样和引入了StyleGAN过采样的数据均衡化处理,而在算法层面则引入了迁移学习的思想。
1.3 迁移学习
迁移学习是把源域的知识迁移到目标域的学习方法,可使得目标域能够取得更好的学习效果。在深度学习中,神经网络从一个任务中学习到的知识可以应用到另一个相关的独立任务当中。在类间不平衡问题的处理上,迁移学习可以对相对平衡的数据集中训练出的模型进行迁移学习,该模型较好的学习到少数样本的类别特征,因而取得了不错的效果,如Lee等[14]提出了二阶段的训练方法;Kang等[15]提出了CRT(Classifier Retraining)方法,该方法是使用类平衡采样的数据对分类器进行重新训练,故而本文中的分类模块也会引入迁移学习这一思想。结合卫星云图灾害数据的实际情况,本文中所采用的迁移学习的思路是将原始数据集训练处的结果迁移到均衡化处理后的数据,该过程主要是为了在提升各个少样本的天气类别分类精度的基础上,尽可能的保留原始数据中非灾害天气这一类别的精度。
2 本文所提方法
本文提出了一个基于GAN+TL的卫星云图灾害天气分类的框架,如图1所示。该框架主要分为2部分,一个是数据均衡化处理模块,另外一个是图片分类模块。在数据平衡化处理模块中首先是对原始不均衡的数据分布进行处理,处理之后得到一个相对较为均衡的数据分布情况。数据处理的过程采用不同的手段,对多数据样本的类别进行欠采样,对少样本的数据进行过采样。具体来讲,过采样的方法是采用生成对抗网络,对数据样本进行扩充。而欠采样是将样本根据设定的阈值进行缩减。在图片分类模块,首先在原始数据分布的数据集进行训练,之后将训练出来的模型迁移学习到类别较为均衡分布的数据集上要进行训练的模型上。
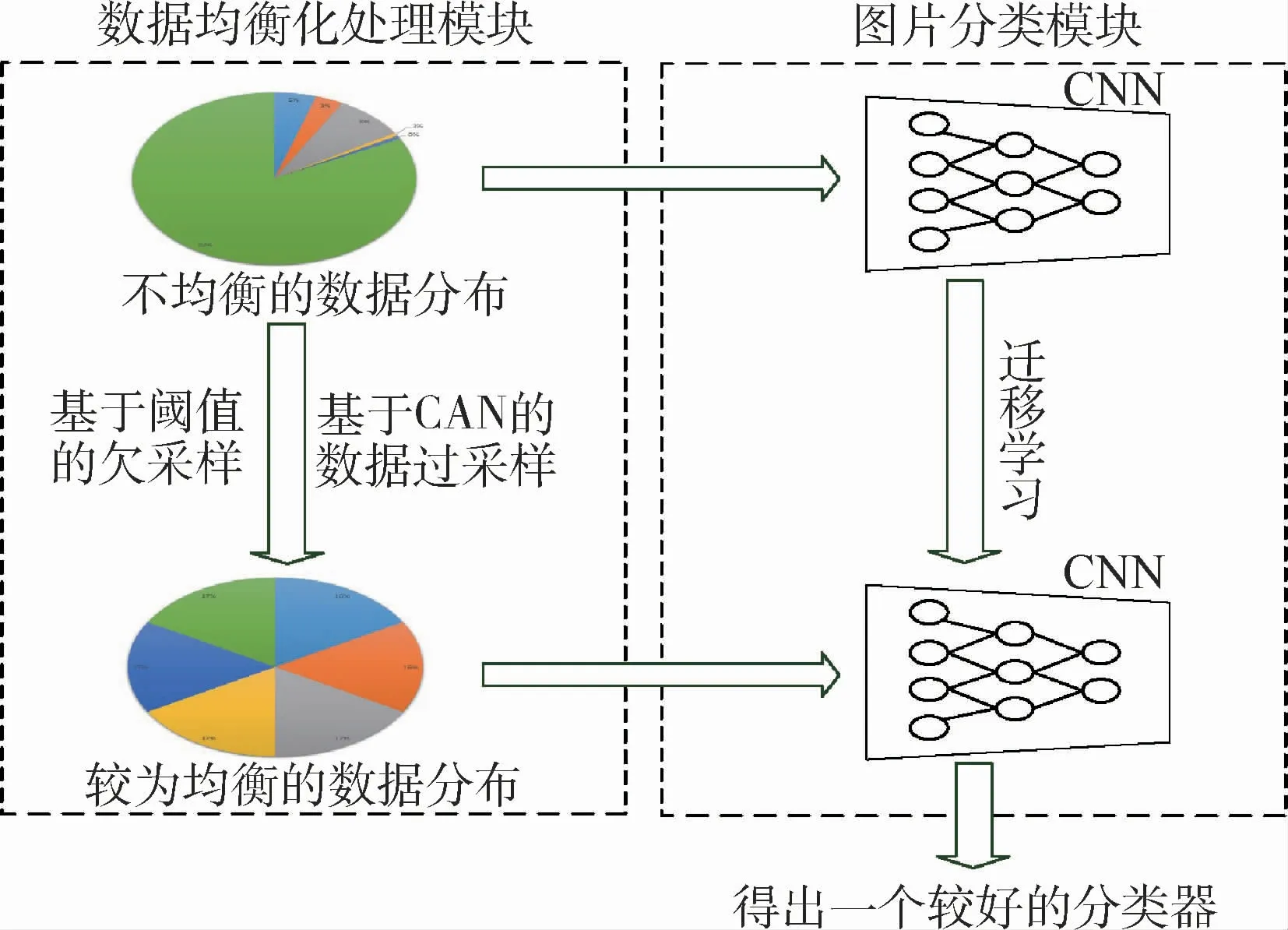
图1 处理气象卫星中类间不平衡的模型框架图Fig.1 Model framework for handling imbalance between classes in meteorological satellites
2.1 数据均衡化处理模块
数据均衡化处理过程的具体细节如图2所示,图2(b)为理想数据分布,是现如今深度学习分类中所研究的大多数数据分布的情况,各个类别的数据量基本相近,而且也取得相对较好的分类性能。本文数据处理模块的主要目的是将原始数据集的分布趋向理想数据分布的方向进行改进,这样可以把数据不均衡的问题转化为数据均衡化处理的问题。数据均衡化的过程分为基于阈值N的欠采样和基于GAN的过采样,具体细节如下:
步骤1 基于阈值欠采样。在均衡化处理的过程中,首先根据各个类别之间的数量关系,设置一个较为合理的阈值N,然后根据这个阈值,对样本数据量大于这个阈值的类别进行数据随机丢弃的处理。本文采用的是去掉样本数量最多类别的数量和样本数量最少类别的数量,然后取剩下类别的样本数量计算平均数的方法确定阈值。具体实现如式(1)所示,Xtotal为数据集中包含的总数量;Xmax和Xmin分别为类别数量最大和类别数量最小的数量,n为数据集中的类别数量。确定好阈值之后,对于样本数量大于该阈值的类别,进行随机欠采样,使得类别的数量达到阈值为止,此时的数据分布如图2(c)所示。
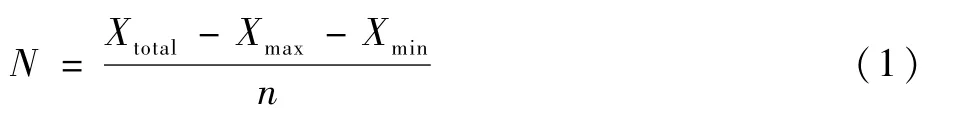
步骤2 基于GAN的过采样。在完成数据欠采样的操作之后,对相应的样本数量少的类别进行过采样。本文提出以StyleGAN2为基础网络基于GAN的过采样方法。即首先把StyleGAN2在进行过采样的类别数据上进行训练,之后用训练好的生成器生成相应类别的数据并加入到已经完成欠采样操作的数据集中,此时的数据分布如图2(d)所示。图3为GAN设计的核心思想流程,G(z)fake为随机化的初始噪音,G为生成器,用来生成图片;D为判别器,用于判别生成图片的真假;Datareal为本框架结构中要进行数据增强的部分;real和fake表示经过判别器判断生成的数据为真还是假。

图2 不同方法对应数据分布情况的百分占比示意图Fig.2 Schematic diagram of data percentage proportion of data distribution corresponding to different methods
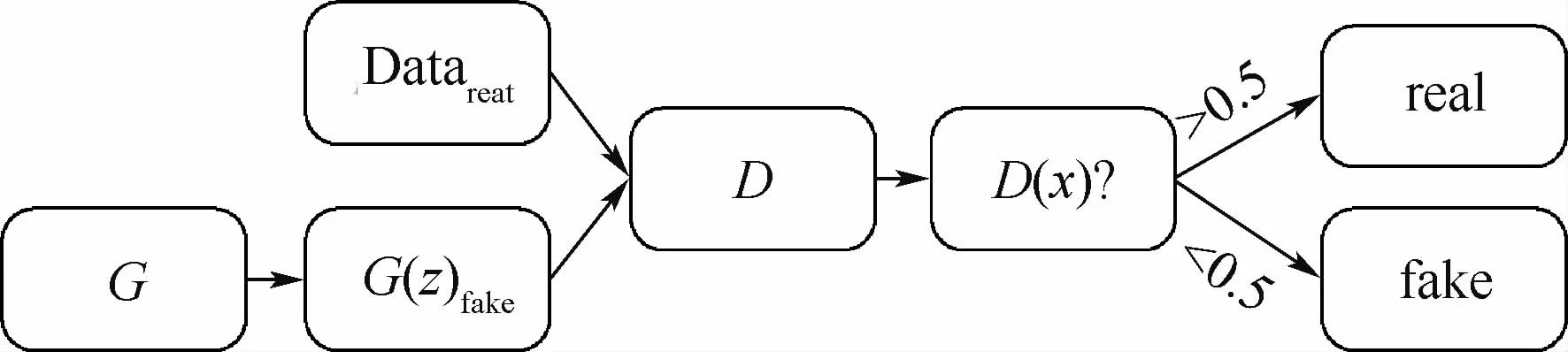
图3 GAN的核心思想Fig.3 Core idea of GAN
StyleGAN2也是在该思想流程上的改进,可以生成更加高质量的图片。因为本文中所用的LSCIDWS-S数据集,原本就是高质量的卫星云图,故而本文选择了StyleGAN2作为GAN数据平衡化处理模块中的基础网络。StyleGAN2主要在消除图片伪像上进行了进一步的改进,图片的伪像就是生成图片中图像上呈现出的类似于水滴的特征,该算法将改进的方向定位到了AdaiN的运算中,该算法的特点可分别归一化到每个特征图的均值和方差。具体的修改细节如下:首先对每个输入特征图的尺度根据调制卷积操作进行相应的调整,如式(2)所示,w和w′分别为原始权重和调制权重;si为与第i个输入特征图对应的比例;j和k分别为特征图和卷积的空间下标。式(3)为完成相应调制卷积操作之后的输出权重(调制权重)的标准差。式(4)表示式(2)中σj固化到卷积权重中去,ε为很小的数值,是为了确保被除数不为0。
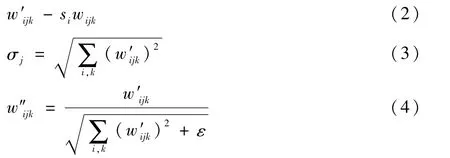
3.2 图片分类模块
在完成数据均衡化处理之后,进入分类训练的模块,流程如图4所示。先根据原始不均衡的数据集训练出一个模型,再将不均衡分布数据训练出来的模型进行迁移学习,即把上述训练得到的模型权重初始化到较为均衡分布的数据集的分类模型上。采取这样二阶段训练的目的,主要是为了解决,均衡化后的数据分布所训练出的模型会丢失较多关于原样本数量较多类别特征信息的问题。故而能在牺牲样本数量较多类别的分类精度的前提下,提升其他各个类别的分类性能。同时二阶段训练的处理方法,也使得原始不均衡的数据分布和后处理的较为均衡的数据分布之间建立相应的关联。2个模块之间的相互关联,使得整个数据处理和之后的图片分类过程形成一个闭环,也使得分类器的性能达到相应的稳定和平衡。对应算法步骤如下所示:
算法1 图片分类框架算法。
输入:原始训练集Xtrain,均衡化处理后的训练集X′train,模型训练的次数m。
输出:对测试集Xtest的分类结果。
1.随机初始化用于迁移学习的网络参数Mt
2.Repeat
for i=1 to m do
根据网络预测结果与真实的标签进行损失计算
反向传播更新网络的参数Wt
3.获得迁移学习的模型Mt
4.用模型Mt初始化分类模型Mc的参数
5.Repeat
for i=1 to m do
根据网络预测结果与真实的标签进行损失计算
反向传播更新网络的参数Wc
6.完成最终分类模型Mc的训练
7.将待预测的样本输入Mc获得最终分类结果
本文在图片分类模块中采用ResNet101作为训练过程中的基础模型。这主要是因为本文的数据集原始数量大,希望可以用深层次的网络取得较好的性能,但大量研究表明,随着网络深度的增加,会出现梯度爆炸,导致无法收敛这一问题。而残差思想的提出[13]可以使得网络的性能不随网络深度的增加而退化,因此本文选择ResNet101作为分类模块中的基础模型。

图4 分类模块训练的流程图Fig.4 Flowchart of classification module training
以上2个模块的结合,构成了灾害天气卫星云图的分类框架,并充分考虑了数据中的不平衡问题。
3 实验结果及分析
3.1 数据集
因目前没有公开可用的云图数据库,本论文实验数据集采用自建的数据集,称之为LSCIDMR-S(Large-scale Satellite Cloud Image Database for Meteorological Research System)。LSCIDMR-S是以葵花-8号气象卫星为数据来源建立的一个大尺度静止气象云图的单标签数据集。该数据集的数据采集时间跨度为1年,包含了温带气旋、热带气旋、锋面、西风急流、降雪、高冰云、低水云、海洋、沙漠、植被和其他总共11个类别总计104 390张图片,图片的原始大小为1 000×1 000像素。在本文中,因主要聚焦于灾害天气的分类识别,故将高冰云、低水云、海洋、沙漠、植被和其他合并为非灾害天气类别,图5为数据集中的部分云图示例,表1为数据集中各个类别的分布情况。重新划分后的数据不平衡比率(Imbalanced Ratio,IR)为137.25。IR为衡量数据集不均衡程度的一个指标,其具体计算如式(5)所示,是数据量最多的类别的数量和数据量最少的类别的数量比例,一般大于10认定为类间不平衡的数据集[3,7]。Ci为第i个类别对应的类别数量。

图5 LSCIDMR-S数据集的部分示意图Fig.5 Partial schematic of LSCIDMR-S dataset

表1 LSCIDMR-S处理之后的数据分布情况表Table 1 Data distribution of LSCIDMR-S after processing

3.2 评估方法
本文中的实验评估方法采用分类中通常使用的总体精度(Overall Accuracy)和各个类别的分类精度(Category Accuracy)进行评估。总体精度是指预测正确的标签数量和待预测的总标签数量的比例,这一指标只能笼统的评价模型的整体性能。对于长尾数据集的分布,单一的总体精度还不足以充分的体现这一模型与实际问题的贴合程度。单一的总体精度的虚高并不能很好地表示模型的性能很好,很有可能是因为数据集中占据绝大多数类别的单个类别的性能好。比如本文中的非灾害天气类别这一类别,占总数据集的82.69%,如果总体精度达到了80%,也很有可能只是单一的非灾害天气类别这个类别的精度高而已。而在实际的长尾分布数据集当中,占数据量少的类别往往更是应该关注的对象。故而占样本数量较少的温带气旋、热带气旋、西风急流、锋面和降雪,它们单个类别的分类精度对于实际问题的研究更加有意义,故而本文还采用各个类别的分类精度。
总体精度和单个类别的精度能从数值上说明一个模型的整体性能。于此同时本文还采用了ROC曲线作为评估指标[9],该曲线可视化了正确分类的阳性样本与阴性样本之间的关系,故而ROC曲线是衡量模型在不均衡数据集中性能的一个重要指标。ROC曲线通常用于二分类的研究,横坐标为假阳性(特异度),纵坐标为真阳性(灵敏度)。本文为将其扩展到多分类问题上,首先对输出进行二值化,然后分别进行如下操作:①对每个类别绘制了一个对应的ROC曲线;②Micro-average通过把多分类问题转化为二元预测来绘制ROC曲线;③Macro-average用于多分类的评估方法是对每个标签给予相同的权重,实现宏观的平均,最后将同一个类别的数据汇总到1张ROC曲线上。ROC曲线下方与坐标轴围成的面积被定义为AUC(Area Under Curve),表示预测的正例样本排在负例样本前面的概率,这个面积的数值通常介于0.5~1之间,数值越大,表明分类方法的性能越好。
3.3 参数设定
本文实验均在一个配备了32 GB内存和3.6-GHz Inter(R)Core i9-9900K CPU处理器及GeForce RTX 2080Ti显卡的工作站上进行。
对于数据集的训练集和测试集按照9∶1的比例进行划分。对于数据集欠采样的部分,按照数据均衡的方向调整,设置了阈值N=3 826,该阈值根据训练集中去掉了类别中数量的最大值和最小值取均值。然后对数据量超过这个数值的类别的数据进行随机丢弃直到数据数量达到3 826。对于数据过采样部分,是基于数据欠采样的基础上对数据再进行进一步的处理,对于类别数量较少的锋面和西风急流扩充k倍,默认为1,相应的数据数量分别为571和766。对于参数,按照0.5的步长设置进行了相应的参数实验。
使用StyleGAN2生成的图片大小为256×256像素。分类模型中的各个超参数分别设置为learning rate=0.001,momentum=0.9,batch_size=64,图片统一为256像素×256像素。每个模型都训练20次,保留总精度最高的模型,进行指标计算。
3.4 实验结果及分析
针对本文所提GAN+TL框架,设计对比实验证明所提模型方法有效。分别为:采用未经过任何处理的原始数据进行训练与分类的Base方法;对原始数据按照对超过阈值的类别进行随机欠采样处理后的Base_under方法;在Base_under的基础上对Base进行迁移学习的Base_under_t方法;Base_under_over是对原始数据集进行按阈值随机欠采样之后的基础上,再对原始数据集中样本数量较少的类别进行机械复制的过采样方法;Base_under_over_t是在Base_under_over方法的基础上对Base进行迁移学习的结果;之后的Base_under_gan相比于Base_under_over是用生成对抗网络来代替传统的复制对数据进行过采样,从而使得数据分布达到一个较为均衡的状态;最后的Base_under_gan_t也是本文所提的GAN+TL框架,即在Base_under_gan的数据处理基础上对Base训练出的模型进行迁移学习。接下来的实验分析中,也将主要从数据平衡化模块和图片分类模块分别展开分析。
首先是数据均衡化,表2为不同方法所对应的数据分布情况和相应的数据不平衡系数。可知,原始数据集的数据不均衡系数达到137.25。而经过本文所提数据均衡化处理之后,数据不平衡系数降到了3.35。图2为不同方法对应的数据分布情况的百分比占比示意图,图2(a)为数据的原始分布示意图,图2(b)为大多数研究中数据理想的均衡分布图,图2(c)和图2(d)分别对应了不同数据均衡化处理的过程。图6为基于GAN的数据过采样的部分结果示意图,以西风急流为例,图6(a)为原始数据集中西风急流的部分示意图,图6(b)为基于GAN生成的数据样例,从图片中可以观测到StyleGAN2,可以较好地学习到图像的轮廓、纹理、颜色等特征。虽然伴随着一定的噪音,但是从表3的实验结果中可以观察到,StyleGAN2生成的图片信息能够较好地学习原图像的特征。

表2 各方法对应的数据分布及数据不平衡系数Table 2 Data distribution and data imbalance degree corresponding to each method

图6 基于GAN的数据过采样生成的图片Fig.6 Schematic diagram of oversampling data image generated by GAN
表3为分类实验的总体精度和各个类别的分类精度。可知,本文所提的数据处理:欠采样、基于StyleGAN2的过采样方法和基于不平衡样本的迁移学习(Base_Under_Over_Gant)的方法对解决类间不平衡问题有效。由表3可知,虽然Base方法的整体精度和非灾害天气这一类别的分类性能达到了最优,但是对于西风急流、热带气旋、锋面和温带气旋这4个类别的数据,他们的分类精度还非常低。这4个类别的原始数据量较少,但是能准确地识别它们对于实际应用场景非常有意义。上述实验结果进一步说明了长尾数据的分布对于CNN的特征提取有一定的影响,在分类的时候会更加关注数量多的类别,因而数量多的类别(非灾害天气)能取得较好的提取特征,进而忽略了其他数量较少类别的特征的学习,由此对数据量较大的类别(非灾害天气)进行处理就非常有必要。对于阈值大于N=3 826的类别进行了随机丢弃的欠采样处理,从表3中可以看出,Base_under与最开始的Base相比,虽然损失了非灾害天气这一类别的精度,但是其他各个类别的精度都得到了一定的提升,与此同时,Base方法中对数量较多的非灾害天气这一类别的特征有较好的学习,故而把Base方法训练的结果迁移学习到进行调整的Base_under模型,得到了新的模型Base_under_t,发现部分类别的精度会得到一定的提升。故而提升少数类别的数量,可以帮助CNN均衡的提取各个类别的特征。将欠采样和过采样相结合的同时,再加上迁移学习,这给训练一个更好的分类器提供了思路。用GAN对于少数样本的数据进行过采样,从表3中可以看出,Base_under_gan和Base_under_over 2个模型相比,Base_under_gan的总精度和绝大部分类别的分类精度基本高于Base_under_over。这说明用GAN生成图像的过采样方法比简单的复制粘贴过采样的方法能取得更好的分类效果。最后,本文所提出的Base_over_gan_t模型基本在所有类别都取得了相对较高的精度。在降雪类别的数据上虽然没有取得最高的分类精度,但是也取得了相对不错的精度。究其原因是在对数据进行了欠采样和过采样处理之后的数据各个类别的分布比例虽然达到了一定的均衡,但是降雪(如图2(d)所示)这一类别相较于其他类别的数量占比较大,故而分类器在该类别的特征提取上能够取得较优的性能。表3中数据部分加粗的是各个类别取得的最高精度。
图7(a)~图7(h)分别对应非灾害天气、西风急流、热带气旋、降雪、锋面、温带气旋、Microaverage和Macro-average在各个不同模型下的ROC曲线图,图中的Model 1~7分别对应表2中的各个方法。表3中本文所提Base_under_gan_t方法,相比于其他的方法,整体的性能达到了最佳,对应的ROC曲线的顶角靠近左上角,对应的AUC与其他方法相比达到了最高:非灾害天气(0.83)、西风急流(0.85)、热带气旋(0.85)、降雪(0.94)、锋面(0.73)和温带气旋(0.83)。
之后对生成对抗网络进行数据扩充的倍数k对各个类别分类精度的影响进行了进一步的探究,实验结果如图8所示。图8(a)为基于GAN的数据过采样之外不采用迁移学习进行模型训练的分类性能情况;图8(b)为同时采用基于GAN的数据过采样和迁移学习进行模型训练之后的分类性能情况。k=0.5、1、1.5、2、2.5、3、3.5、4、4.5、5、5.5,训练数据集对应的IR分别为4.5、3.35、2.70、2.25、1.93、1.69、1.50、1.35、1.23、1.13、1.04,相应的各类别的数据分布情况如图9所示。从图8中可以看出,无论是否采用迁移学习,随着值的增大,总精度基本稳定在0.75。而其他各个数据类别的分类精度会呈现先升高,然后稳定在一定数值之后再下降的趋势,当值介于1~2之间的时候整体的分类器的性能都取得较为均衡的结果,称之为最佳取值范围。总体上当处于最佳取值范围时,采用迁移学习之后的总精度和各个类别的分类精度都有一定的提升。而随着k的增加,IR趋近于1的时候,对不均衡分布数据训练出来的模型进行迁移学习的分类器的性能提升并没有明显效果。这主要是因为样本增加的数量远大于该类别原始数据的数量,通过GAN进行数据的过采样会导致分类器在特征学习过程中受到生成数据中噪声的影响,进而影响特征学习效果。

表3 各个模型的总精度和分类精度的统计Tabel 3 Statistics of total accuracy of each model and accur acy of each category(Accuracy)

图7 各个模型中各个类别对应的ROC曲线Fig.7 ROC curve corresponding to each category in each model
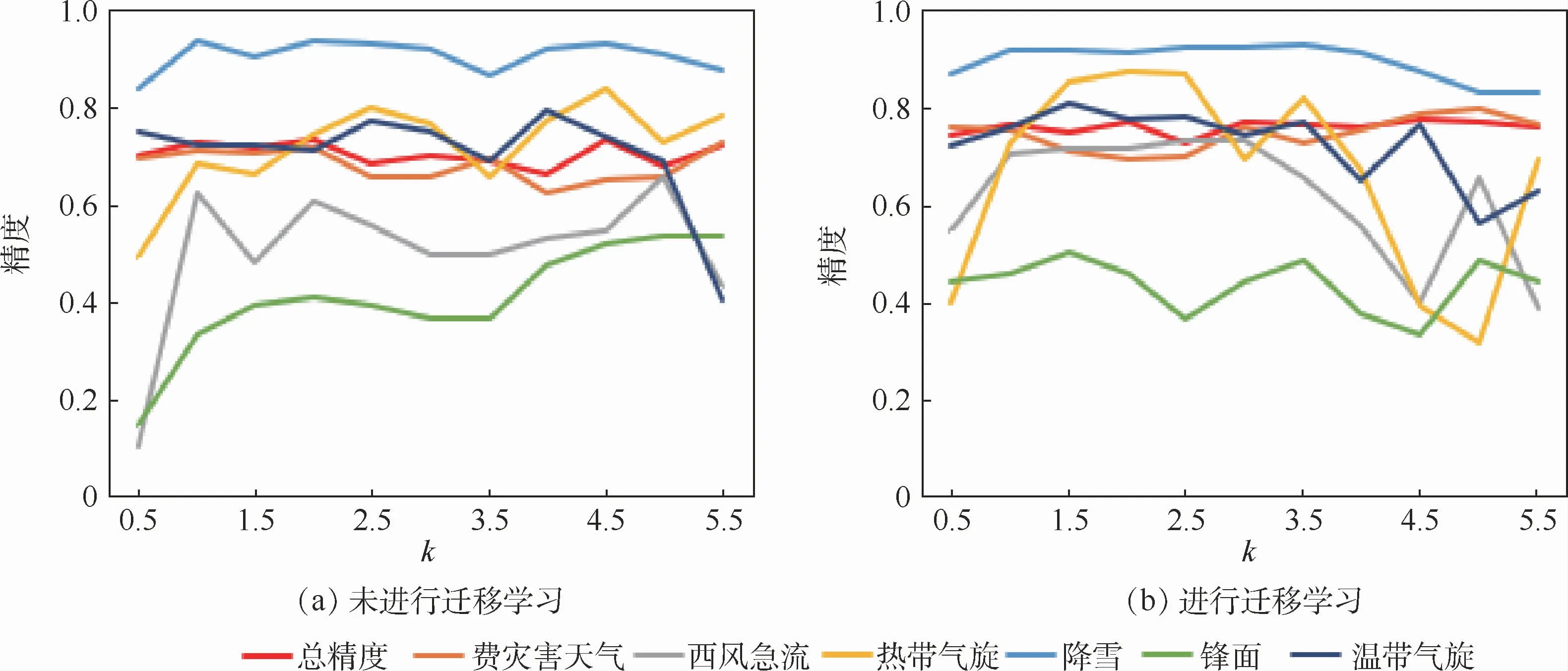
图8 参数k对分类性能的影响Fig.8 Influence of parameter k on classification performance
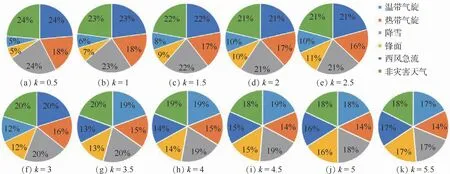
图9 不同k对应的数据分布Fig.9 Data points corresponding to different k
4 结 论
1)本文提出了一个结合生成对抗网络和迁移学习处理灾害天气气象卫星云图中的长尾数据分类的框架。该框架分为数据均衡化处理模块和数据分类2个模块。数据均衡化处理模块采用GAN对少样本的数据类别进行过采样,然后将过采样和欠采样相结合实现原始数据均衡化处理。
2)通过上述过程,GAN可根据数据的分布情况生成新的过采样数据,进而能够给CNN中的特征提取提供更加优质的图片信息;在图片分类模块中,采用对原始不均衡数据集训练得到的模型进行迁移学习,用所得的模型对图片进行分类的方法。
3)在自建的大规模卫星云图数据上的多方面实验证明,所提框架中的基于GAN的数据过采样和基于迁移学习的模型训练方法可以较好地解决卫星云图中的数据不平衡问题。所提框架在传递数量较多的数据类别特征信息的同时又可对数量较少的数据类别提取较好的特征,故而在提升少量样本类别分类精度的同时,也尽可能地保证大量样本的分类精度。为之后解决类间不平横的长尾数据分布提供了一个可以借鉴的解决思路。与此同时,虽然其他各个类别分类的精度都得到了可观的提升,但是数据分类的总体精度和非灾害天气的分类精度有了一定的下降,其中非灾害天气精度下降可能是因为随机欠采样不能充分保留原始数据的多样性(原始灾害天气中并没有进行更加细致的类别划分,从而不能有计划的从各个非灾害天气类别中进行随机欠采样)。这也是之后研究中所需要进一步改进和研究的方向:即在保证各个少量样本类别分类精度得到提升的同时,分类的总体精度也要保证一定的提升。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
导航定位学报(2022年4期)2022-08-15
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
环球时报(2017-08-14)2017-08-14
紫光阁(2016年4期)2016-11-19
智能制造(2015年9期)2015-10-15
小天使·四年级语数英综合(2015年3期)2015-04-20
微型计算机(2009年4期)2009-12-23
青年文摘·上半月(1992年1期)1992-01-01
