
基于机器学习的文本半自动类别标注方法
2021-04-26 08:20宫衍圣蔡科平王志强李鑫鑫靖稳峰
工程数学学报 2021年6期
宫衍圣, 蔡科平, 王志强, 李鑫鑫, 靖稳峰
(1. 中铁第一勘察设计院集团有限公司,西安 710043; 2. 西安工业大学,西安 710021;3. 国网浙江省电力公司信息与通信分公司,杭州 310007;4. 西安交通大学数学与统计学院,西安 710049)
0 引言
数据标注是监督学习的一个重要环节。它是指对采集到的图像、语音、文本等数据对象进行不同类别的标识,为数据分析或人工智能算法提供训练数据。常见的数据标注任务包括类别标注、区域标注、描点标注等。类别标注是指从给定的标签集中选择合适的标签分配给数据对象,通俗地说就是对所给定的图像、语音或文本数据指定一个类别标签,达到与其他数据区分的目的。
人工标注是进行数据标注的基本方法,标注人员需要熟悉领域专业知识才能实现正确标注。此种标注方法需要耗费大量的人力、财力,其效率低下。随着机器学习技术的发展,使用机器学习辅助的半自动化数据标注方法不断发展,成为大数据背景下更加常用的数据标注方法[1]。
本文提出了一种对数据科学与人工智能领域的文章进行半自动化标注的方法。首先应用爬虫程序获取了42034 篇数据科学与人工智能类的科技论文摘要数据,然后通过“构建领域语料库–单词向量化–文本向量化–文本聚类–提取当前类中关键主题特征词–对主题词进行人工归纳得到当前类标签–训练文本分类模型–应用训练好的模型进行文章标注”。该方法大大提高了文章类别标注效率,可作为论文推荐系统的基本技术。新方法具有很好的迁移性能,可适用于多种自然语言处理任务中不同领域的文本信息类别标注。
1 文本自动化标注模型构建
1.1 文本向量表示
文本向量化是自然语言处理最基本的工作。文本向量化之前,需要获取每个单词的向量表示。本文基于爬虫程序获取的数据科学与人工智能类文章摘要构建领域语料库,在此语料库上使用Word2vec[2]、Paragraph2vec[3]和TF-IDF(Term Trequency-Inverse Document Frequency)等方法得到单词的向量表示。
首先,从数据科学与人工智能类会议和期刊上通过网络爬虫技术获取到42 034 篇论文的标题和摘要作为原始数据,然后对这些数据进行预处理,预处理过程包含大小写转换、去标点符号、去停用词、词干化等;接着,通过预处理之后的数据构建了针对数据科学与人工智能这一特定领域的语料库;最后,将经过预处理之后的文本使用词嵌入技术得到32 266 个单词的词向量表示,每个单词用一个200 维的实数向量表示。
TF-IDF 词向量表示方法包含词频TF 与逆文档频率IDF 两部分,它认为一个单词对于文本分类的重要性正比于其在单个文本中的频数,反比于其在全部文档中的频数[4]。单词w的词频和逆文档频率分别记为TFw和IDFw,其计算公式如下

在文本向量化阶段,将TF-IDFw作为w的权重,对当前论文中所有Word2vec 加权求和,从而获取单词的向量表示,通过这样的方法使得论文中不同重要程度的单词发挥不同的作用,具体实现步骤如下。
设语料库中的论文数据集合为{t1,t2,··· ,tM},词汇表(字典)矩阵为D=[w1,w2,··· ,wN],其中wi是第i个单词的Word2vec 向量
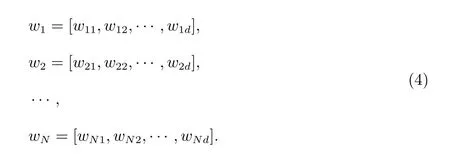

1.2 文本聚类
文本聚类是实现文本自动化标注的基础,本文使用K-means 算法完成文本聚类。Kmeans 的聚类个数K值需事先确定,本文使用Robert 等人提出的Gap statistic 方法[5]选取最佳聚类簇数。K-means[6]初始聚类中心的选取使用K-means++算法[7]。本文使用Tadeusz Calinski 提出的CH 指标[8]衡量最终的文本聚类效果。
1.3 基于L1-LR 模型的类别主题词分析
类别主题词是能够表示文章类别的关键词。为了得到每一类论文的类别主题词,本文采用带有L1正则化的Logistic Regression 二分类模型–L1-LR 提取类别主题词。
定义二元Logistic Regression 函数[9]

本文使用坐标轴下降法进行求解[9],具体求解步骤如下。
算法1L1-LR 二分类模型求解

输入:M 个数据点xi =(xi1,xi2,··· ,xin), i=1,2,··· ,M,每个数据有n 个特征输出:每个特征的权重参数绝对值|θi|排序步骤1:随机初始化参数向量为θ(0);步骤2:对于第k(k ≥1)轮迭代,依次求θ(k)i , i=1,2,··· ,n,有θ(k)1 =argmin ),θ1 J(θ1,θ(k-1)2,··· ,θ(k-1)n θ(k)2 =argmin ),θ2 J(θ(k)1 ,θ2,θ(k-1)3,··· ,θ(k-1)n··· ,θ(k)n =argmin J(θ(k)θn 1 ,θ(k)2 ,··· ,θ(k)n-1,θn);步骤3:检查θ(k)向量和θ(k-1)向量在各个方向上的收敛情况,如果θ(k)和θ(k-1)在所有的方向上都满足收敛条件,那么θ(k)为最终结果,否则继续转入步骤2,开始第k+1 轮迭代。
2 文本自动类别标注方法
在上述工作的基础上,本文提出一种有效的文本类别自动标注方法,详细步骤如下。算法2 基于机器学习的文本自动类别标注

输入:通过网络爬虫获取的M 篇数据科学与人工智能领域相关论文摘要X ={x1,x2,··· ,xM}输出:所有论文数据最终的类别划分信息,包括类别数、每篇论文所属类别
步骤1:对原始数据预处理,得到数据科学与人工智能领域语料库,取出语料库中频数最高的2000 个单词构成词典D;
步骤2:在语料库上训练Word2vec 或Paragraph2vec 词嵌入模型,将每个单词表示成一个d维的实数向量,d一般取值200;
步骤3:选择以下一种方式得到文本向量化表示矩阵T:
1) 文本中所有单词的Word2vec 向量累加;
2) TF-IDF 矩阵×Word2vec 矩阵;
3) 文本中所有单词的Paragraph2vec 向量累加;
4) TF-IDF 矩阵×Paragraph2vec 矩阵;步骤4:文本聚类:
1) 将T输入Gap statiatic 算法中得到最佳聚类簇数K;
2) 将T和K输入K-means 算法中完成聚类,其中初始质心的选取使用Kmeans++方法优化;
3) 使用CH 指标衡量聚类效果;步骤5:类别主题分析:1) 构建K个二分类数据集。数据集i:属于第i类的样本标记为正样本,其余K-1 类样本标记为负样本;
2) 使用SMOTE 算法[10]均衡正负类样本数据量;
3) 对数据集i,用L1-LR 二分类模型提取类别特征词;步骤6:对K个L1-LR 二分类模型中模型变量对应的权重绝对值排序,在词典D中选取绝对值最大的若干系数所对应的单词作为主题词,最后根据这些主题词归纳得得到K个类论文的标签。
3 实验过程与结果分析
3.1 文本聚类实验结果
1) Gap statistic
由于K-means 算法具有随机性,每次运行Gap statistic 方法选出的最佳聚类簇数K可能不一样,故将上文提到的4 种不同的文本表示方式作为聚类的输入矩阵,分别通过Gap statistic 方法得到的最佳K值为20。
2) 文本向量化方式
本文对表1 中所列的4 种文本向量化的速度以及聚类效果进行了对比,从实验结果中可以看出,单独使用词嵌入向量累加来表示文本的方式CH 指标虽略高于词嵌入与TF-IDF 值加权求和的文本向量化方式,但在生成文本向量时,却要付出高于700 多倍的时间。因此,本文综合考虑聚类效果CH 指标值与生成文本向量表示的时间,最终选用Word2vec 词嵌入与TF-IDF 值加权求和的方式进行文本表示。
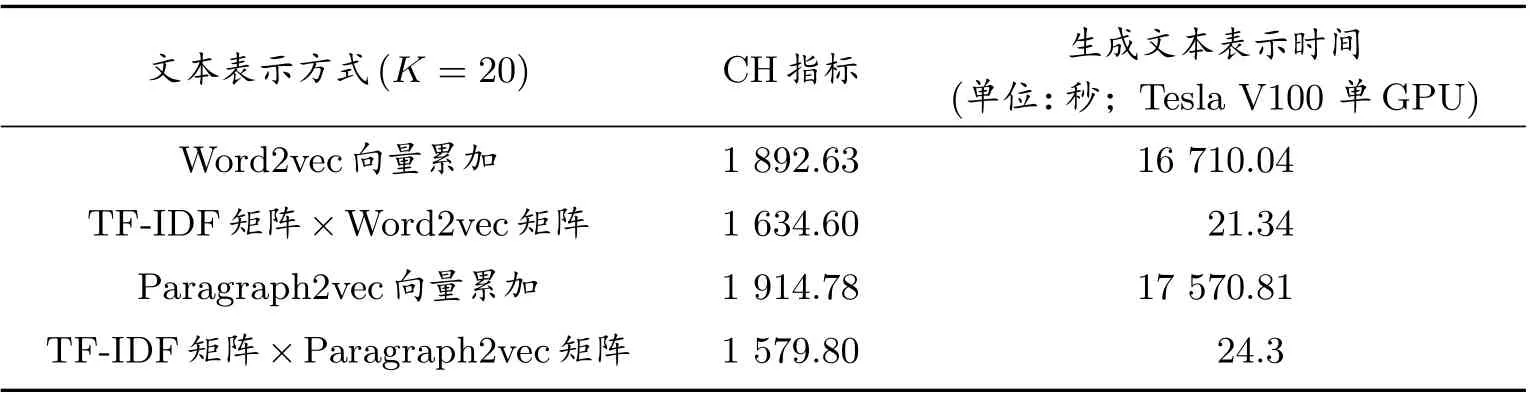
表1 不同的文本表示方法实验结果对比
对算法进行时间复杂度分析,解释文本向量化方式速度上的差异。已知字典D大小为N,文本集合T长度为M,文本平均长度为L,词嵌入维度为d,词嵌入矩阵W ∈RN×d,TF-IDF 稀疏矩阵F ∈RM×N,F的稀疏度为a=F中0 元个数/F中所有元素个数,a ∈[0,1],使用TF-IDF 值与Word2vec 词嵌入向量加权求和的方式对文本进行向量表示,只需将稀疏矩阵F与矩阵W相乘即可实现,此方法的时间复杂度为O1=O(M×N+a×M×N×d);而使用词嵌入向量累加的方式,对一个论文数据中的所有单词,需遍历词嵌入矩阵找到其向量表示,再累加,所需时间复杂度为O2=O(L×M×N×d)≫O1,这也从理论上验证了实验结果的准确性。
3) 文本聚类结果展示
表2 和表3 中分别展示了第0 类、第3 类中的部分文本标题,可以看到,通过本文提出的文本聚类算法,聚出来的文本几乎均属于同一类,对这些标题进行归纳,可以大致确定第0 类为强化学习、Q 学习相关类,第3 类为NLP(文本分类、机器翻译、情感分析等)类,第9 类为CT/MRI 等医学影像分析,对于剩下的类采取同样方式进行归纳,这里不再一一列举,之后再将这些结果与L1正则化结果对比分析,归纳出每一类论文的类别标签。

表2 第0 类部分论文标题

表3 第3 类部分论文标题

续表
3.2 类别主题分析结果
1)L1-LR 二分类模型结果
图1 至图3 分别展示了使用SMOTE、Borderline-SMOTE 和ADASYN 方法的L1-LR 二分类模型在验证集上的accuracy、precision、recall 和f1-score 结果值,可以看出:

图1 基于SMOTE 上采样的L1-LR 二分类结果

图2 基于Borderline-SMOTE 上采样的L1-LR 二分类结果

图3 基于ADASYN 上采样的L1-LR 二分类结果
(a) 三种采样方式得到的结果基本一致;
(b) 20 个二分类任务的accuracy、precision、recall 和f1-score 值均高于0.94,训练的二分类模型在验证集上表现良好,无欠拟合或过拟合现象;
(c) 通过训练好的L1-LR 二分类模型进行特征词筛选完全可行。
2) 类别特征词提取结果
每个二分类模型训练完成后,会返回字典中所有单词对应的L1权重值,将权重绝对值较大的特征词挑选出来,随机选取了其中6 类的结果展示在表4 中。这些特征词对于所属的二分类任务发挥了重要作用,说明可以用于区分当前类与非当前类,或者可以作为当前类的主题词,或者可以作为其他类的主题词,因此L1正则化特征词选择结果可以用于辅助论文数据类别标注工作。

表4 L1 正则化特征词提取结果展示
同时,本文在此部分做了对照实验,使用经典TextRank 关键词提取算法[11],对每一类中心的文本提取关键词,作为这一类的主题词,提取出来的关键词见表5 所示。
从表5 中可以看出,TextRank 算法提取出的关键词会将诸如data、model、method、result 等不具备明显类别区分意义的词汇筛选出来,原因在于使用此方法时,每一类中只用到了类中心一篇论文数据的信息,不具备说服力,效果自然很差。而表4 中L1正则化方法提取出来的绝大多数单词,具备明显的类别含义,可以作为类别的主题词,因此本文最终选取L1-LR 模型提取类别特征词。

表5 TextRank 关键词算法提取结果
3.3 论文类别标注结果
综合考虑文本聚类以及类别主题分析的实验结果,本文实现了数据科学与人工智能类论文的类别标注,详细结果展示在表6 中。

表6 论文类别标注结果
3.4 应用–数据科学与人工智能论文推荐系统
本文提出了一种基于机器学习方法的半自动论文类别标注算法,对42 034 篇数据科学与人工智能类的科技论文进行了类别标注。为验证标注结果的有效性,同时也为了将本文所做工作应用到实际问题中,在得到了所有论文的类别之后,将其按一定比例划分为训练集与验证集,构建文本分类器,并提出了一种基于文本分类的推荐算法,将其应用到数据科学与人工智能类科技论文推荐系统中。首先,通过分类器得到新论文的主题标签;之后计算用户输入的查询关键词与论文类别之间的相似度完成论文的推荐,按相似度值排序,为用户推荐最新发表的TOP20 篇论文。
使用BERT(Bidirectional Encoder Representations from Transformers)算法[12]构建文本分类器,得到了在验证集上准确率最高的模型,部分结果展示在表7 中。

表7 文本分类实验结果对比
对于BERT 模型中词库文件这一参数,在训练模型时分别加载了BERT 源码自带的vocab.txt 文件;将语料库中词频大于0.01,小于0.7 的单词选出来共1 349 个构成本文专用词库my vocab.txt 文件;本文构建的领域语料库中所有单词构成的词库myall vocab.txt 文件这三个txt 文件来对比实验结果。
从表7 展示的文本分类实验结果中,可以得到以下结论:
1) 在训练BERT 文本分类模型时,使用本文构建的专用词库或领域语料库比使用BERT 自带的词汇表文件在验证集上的表现更好;
2) 将本文得到的论文类别标注结果经过BERT 算法之后,通过一定的调参可以在验证集上得到较高的准确率,能够得到一个效果很好的文本分类器,可以实现基于文本分类的科技论文推荐,这也证明了本文提出的论文半自动类别标注算法具有有效性与实践应用意义。
4 结论
本文提出了一种结合机器学习算法与人工辅助工作的半自动文本类别标注方法,并以42 034 篇数据科学与人工智能类的科技论文作为实验数据,验证了半自动类别标注方法的有效性与实际意义。本文提出的半自动文本类别标注方法在保证标注结果准确性的前提上,大大提高了工作效率;且论文类别标注结果构建了一个数据科学与人工智能领域论文分类的数据集,为相关方向的研究者提供了便利。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
新校长(2016年8期)2016-01-10
新高考·高二数学(2015年11期)2015-12-23
电子设计工程(2015年6期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
