
ERNIE-CNN文本分类模型
2021-05-07 10:39齐佳琪迟呈英战学刚
辽宁科技大学学报 2021年1期
齐佳琪,迟呈英,战学刚
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
文本分类(Text classification),作为自然语言处理(Natural language processing,NLP)和机器学习(Machine learning)领域最受关注的应用之一,是处理海量信息的有力手段[1]。它是指用电脑对文本集或实体按照一定的分类体系或标准进行自动分类标记[2]。文本分类是一个监督式学习过程,需要一个给定的分类体系和一组带标签的文本,在此基础上建立文本特征和文本类别之间的关系模型,利用资源构造分类器,将待分类文本在不同的、事先定义的类别中进行类别判断。
根据文本不同,分类系统可以分为中文文本和英文文本。英文文本可以根据空格进行切分,不需要另外的分词处理。中文文本是一连串的汉字连接构成句子,基本语素是词而不是字,需要对其进行分词处理。分词处理采用词向量技术实现。然而,由于中文本身的特点在分词过程中容易出现错误传播,并且随着传播的进行错误会逐渐加剧,影响文本分类效果。
文本作为非结构化字符数据,要实现计算机识别,就需要把文本转换成为计算机可以识别的数字。1989年,Hinton[3]提出了分布式表示(Distributed representation)概念,Mikolov[4]等提出了词向量算法,然后逐步采用Word2vec系列的分布式表示方法。2018年Devlin等提出了预训练模型(Bidirectional encoder representations from transformers,BERT)[5],在多个典型的自然语言处理任务中取得了出色的成就,使模型的效果大大提升,推动了自然语言处理的发展。2019年Sun等提出了知识增强的语义表示模型(Enhanced representation from knowledge integration,ERNIE)[6],通过对词、实体等语义信息遮盖,使模型获取完整的语义特征,ERNIE语义模型采用了词的处理,使得中文文本语义更加完整。
近年来,随着深度学习在工程技术中的大量应用和所展现出来的优势,越来越多的研究人员采用深度学习的方法进行文本信息分类的研究。经典的深度学习神经网络有卷积神经网络(Convolutional neural networks,CNN)和循环神经网络(Recurrent neural network,RNN)。韩众和等[7]将CNN与极速学习机(Extreme learning machine,ELM)结合在一起,提出了CNN-ELM混合模型,在多数数据集上取得了很高的分类精度。杨东等[8]提出了一种新奇的混合模型,将CNN融入到加入注意力机制的门控单元卷积网络(Gated re-current unit,GRU)中,突出关键词,并将特征提取进行优化也取得了不错的效果。郑诚等[9]使用CNN与密集连接循环门控单元卷积网络(Densely connected Bi-directional gated recurrent unit,DC_BiGRU)相融合,在执行文本分类任务比单一的CNN模型效果要好。杨锐等[10]利用Doc2Vec提取主题信息并融合CNN网络模型,与其他分类模型作对比F1值均有提升。闫琰[11]在以关键字表示词向量的基础上,融入了深度信念网络(Deep belief network,DBN)和深度玻尔兹曼机网络(Deep boltzmann machine,DBM),提出了一种全新的HDBN(Hybrid deep belief network)模型。姜大鹏[12]引用分布式表达词向量方法对文本进行分类处理,并且证明了该方法的有效性。借鉴刘凯洋[13]结合Bert词向量与CNN相融合的方法,本文提出将ERNIE与CNN相结合的ERNIE-CNN文本分类模型,对中文实体进行词向量表示,提高中文文本分类的性能,为其他文本分类模型的研究提供参考价值。
1 ERNIE-CNN模型
ERNIE最初应用到机器翻译领域,以注意力机制为基础,利用Transformer的多层self-attention双向建模能力进行文本向量化表示。ERNIE与普通词向量模型不同,ERNIE在结构上主要是采用Transformer的编码器Encoder,生成词向量表示,从而存取输入文本的上下文信息。同时通过随机屏蔽(MASK)15%的字或者词进行知识整合保存到文本表示中。MASK机制使用中文实体进行掩码,对训练数据中结构和信息的统一建模,大大地增强了语义表示能力。ERNIE模型的结构如图1所示。
第一个输入是特殊的分类任务CLS。ERINE将一序列的words输入到编码器中。每层都使用self-attention和feed-word network,然后把结果传入到下一个Encoder。假设输入词序列为wi-(n-1),…,wi-1,那么ERNIE的作用就是将词序列wi-(n-1),…,wi-1中的每个词向量按顺序进行拼接,x为ERNIE作为输入层最后得到的结果,本文中n=768。
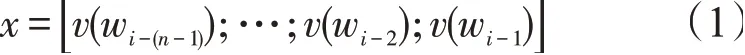
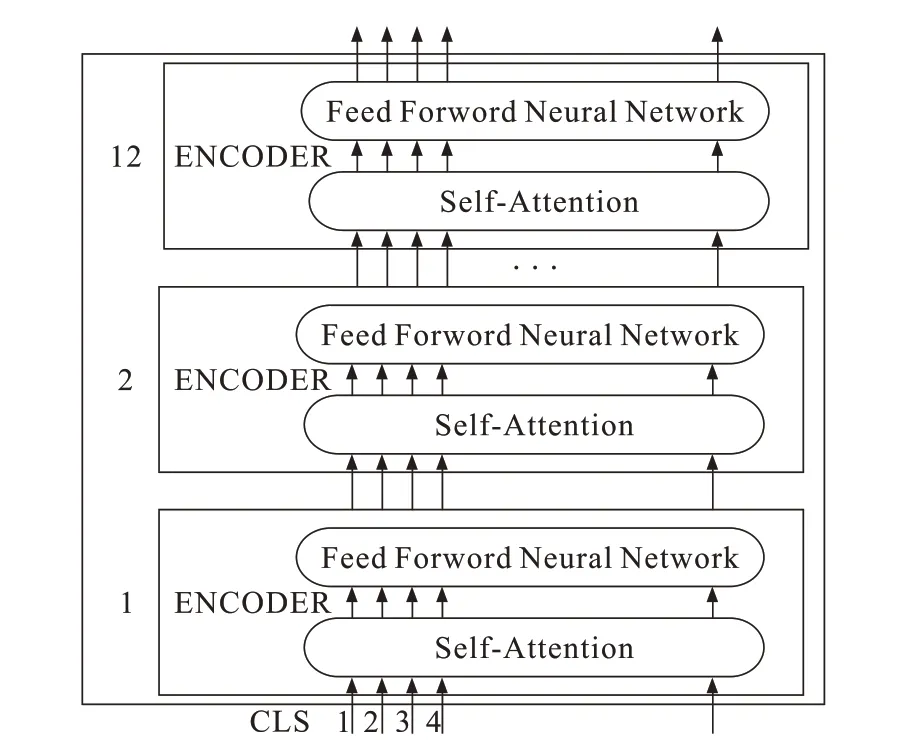
图1 ERNIE结构图Fig.1 ERNIEframework map
Encoder结构如图2所示。Encoder由6个相同的层(sub-layer)组成,每个sub-layer都由multihead、self-attention mechanism和fully connected feed-forward network组成,并且都加入了residual connection和normalisation。sub-layer的输出表示为

式中:Q表示查询矩阵;K表示键矩阵;V表示值矩阵。WiQ代表Q进行线性变换的矩阵;WiK代表K进行线性变换的矩阵;WiV代表V进行线性变换的矩阵;h表示头的数量,每个头能抓捕到一个文本序列中的子空间信息。

图2 Encoder结构图Fig.2 Encoder framework map
multi-head attention通过h个不同的线性变换对矩阵Q,K,V进行投影,Q,K,V三者数值相同,最后将不同的attention结果拼接起来得到融合词向量矩阵。将执行h次self-attention之后的结果进行拼接处理,通过W0得出最后的self-attention结果。
CNN在自然语言处理领域是一种效果极好且容易实现的网络结构。文本分类的关键是准确提炼文本或文档的主旨,就是抽取文本或文档的关键词作为特征,然后基于这些特征去训练分类器从而达到分类的效果。CNN通过设置不同大小的卷积核,提取不同的局部特征,使得提取到的特征向量具有多样性且具有代表性。CNN模型架构如图3所示。

图3 CNN模型架构Fig.3 CNNframework map
设输入的句子矩阵为n×160,其中n为句子中字词的个数,160是本文设定的一个向量维度,将其输入给卷积的filter层,实验过程中卷积的窗口设定分别为2×160、3×160、4×160三种卷积核,经过filter层后的句子矩阵满足以下关系

式中:N代表卷积后特征矩阵的大小;W代表卷积前句子矩阵的大小;F代表卷积核的大小;P代表填充值的大小;S代表卷积过程中的步长大小。

本文选取卷积的步长为1,卷积式式中:K为被卷积矩阵;I为卷积核;S为卷积出来的结果;(m,n)为卷积运算的输入坐标;(i,j)为得到的特征映射坐标。
通过卷积获得特征之后,使用池化函数对卷积操作得到的特征映射结果进行处理。池化函数会将平面内某一位置及其相邻位置的特征值featuremap进行采样分析统计汇总,并将汇总结果作为这一位置在该平面内的值。本文采用最大池化函数计算该位置及其相邻矩形区域内的最大值并作为该位置的值,分别通过Dropout函数操作和Softmax层进行分类处理,得到输入样例所属类别的概率分布情况。
ERNIE-CNN模型的结构如图4所示。模型主要分为七层。第一层是输入层,向模型中输入训练数据。这里输入数据是THUCNews开源数据集。第二层是ERNIE层,将输入的训练数据进行文本表示,将每一个文本转化为对应的词向量。文本表示是文本分类中的重要工作,直接影响整个文本分类任务的性能。第三层是CNN层,对文本特征进行有力提取。第四层是池化层,选用KMaxPooling,从CNN提取的特征中选出K个最大的特征值,即K个对分类来说最重要的信息。第五层是全连接层,防止从CNN层抽取的文本特征升维,防止因维度大使模型复杂度太高,进而导致模型泛化性能差。第六层是分类器层,运用softmax分类器把文本分到所属类别。第七层是输出层,把分类结果输出。

图4 ERNIE-CNN模型架构Fig.4 ERNIE-CNN framework map
模型超参数是在参数空间中搜索最佳值。超参数的选择和设定可以直接影响分类模型的精度。参考文献中使用的超参数值,本文经过反复试验最终确定超参数的最佳值,如表1所示。

表1 模型参数Tab.1 Parameters of model
2 实验结果评价和对比
2.1 数据集介绍
本文选用THUCNews开源数据集做对比实验,其中18万条作为训练集,1万条作为测试集,1万条作为验证集。每个数据集下含有10种分类,分别为财经、房产、家居、教育、科技、时尚、时政、体育、游戏和军事。THUCNews开源数据集样例如表2所示。

表2 清华大学THUCNews数据集样例Tab.2 Samples of THUCNews treebank datasets
2.2 实验环境
所有实验均采用同一个系统环境,系统参数如表3所示。

表3 实验环境Tab.3 Experimental environment
2.3 评价指标
本文中实验的评价指标是准确率Accuracy、精确率Precision、召回率Recall和F1值。
准确率的定义式
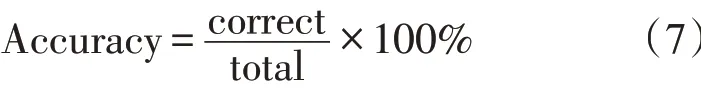

精确率的定义式

召回率的定义式
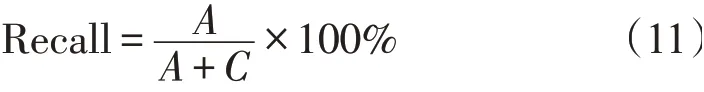
F1的定义式

式中:correct是样本分类的正确率;total是分类样本的总数;A为判别属于该文档且真正属于该文档的样本数量;B为判别属于该文档但真正不属于该文档的样本数量;C为判别不属于该文档但真正属于该文档的样本数量;D为既判别不属于该文档也真正不属于该文档的样本数量。
2.4 实验结果对比
将ERNIE-CNN模型与模型Word2Vec-CNN、BERT-CNN模型对比分析。三种模型实验得出的准确率结果分别为90.55%、90.88%、93.95%。
ERNIE-CNN模型的准确率最高。主要是因为ERNIE可以对训练数据中的结构和信息进行建模,大大地提高了一般语义表征能力。
Word2Vec-CNN、BERT-CNN、ERNIE-CNN模型在THUCNews开源数据集不同类别上精确率、召回率和F1值如表4所示。总体来说,使用ERNIE-CNN模型训练的数据集在精确率、召回率、F1都高出Word2Vec-CNN和BERT-CNN模型。如在财经方面,ERNIE-CNN比Word2Vec-CNN在准确率上高出1.11%,在召回率上高出3.5%,在F1值上高出2.32%;比BERT-CNN在准确率上高出4.94%,在召回率上高出3.6%,在F1值上高出4.27%。在所有类别中,ERNIE-CNN模型在体育方面的精确率、召回率和F1值最高,在科技方面精确率、召回率和F1值最低。这表明ERNIE-CNN模型对体育方面实体的敏感度更高。

表4 不同类别数据集的结果,%Tab.4 Resultsof different dataset categories,%
3 结论
本文提出将ERNIE与CNN相结合的ERNIECNN模型应用于文本分类任务中,在THUCNews数据集上,准确率达到了93.95%,比Word2Vec-CNN高出3.4%,比BERT-CNN高出3.07%,并且在10个类别中精确率、召回率、F1值指标都很高。实验表明,在文本分类任务中,ERNIE词向量技术可以学到更多的先验知识,缓解在中文分词过程中存在的错误传播问题。实验结果证明了ERNIECNN模型的有效性和优越性。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
电脑爱好者(2021年9期)2021-05-12
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
电脑爱好者(2017年7期)2017-05-06
