
面向LVC训练的蓝方虚拟实体近距空战决策建模
2021-05-31 13:49董志明郭齐胜
系统工程与电子技术 2021年6期
高 昂, 董志明,*, 李 亮, 段 莉, 郭齐胜
(1. 陆军装甲兵学院演训中心, 北京 100072; 2. 中国人民解放军61516部队, 北京 100076)
0 引 言
真实-虚拟-构造(live-virtual-constructive, LVC)源自美军训练模拟领域专业术语,特指实物模拟系统、虚拟模拟系统和推演模拟系统集成形成的综合模拟训练系统环境,提供了一种可扩展、高保真、多领域仿真能力,解决了目前实装训练面临的经费、地域、演习频率、实时评估限制等难题[1]。目前,LVC战术对抗训练中,虚拟实体主要通过对人类作战行为建模,对仿真战场环境中的事件和状态作出机动、射击等决策,与人在环的模拟器交互,构建完善的装备对抗体系。其决策模型直接影响人员和装备在环境中的状态和所能反馈信息的种类和质量,进而对训练效果产生影响。临近空间是未来实现空天进攻突袭的新战场,近距空战是未来战争主要样式之一,也是军事训练的重要课题[2]。目前,世界主流战机的高空最大速度为2~2.2马赫,即飞行员需要以约2 450~2 695 km/h的速度在高空中飞行。兼顾到战机的机动性、导弹武器的发射以及规避对方的攻击,实际近距空战中,战机速度大多都是在0.8~0.9马赫高亚音速区。瞬息万变的近距空战态势,使得飞行员需要综合运用身体、技能和直觉操纵高速战机完成所有动作,一个细小的失误将带来高昂的代价,每个瞬间的决断都至关重要。因此,针对具体训练需求设计虚拟实体决策模型,对提升训练效果具有重要意义。
1 需求分析及相关工作
LVC近距离空战对抗训练如图1所示。红蓝双方战机分别由操作模拟器的飞行员与虚拟实体所控制,同在一个虚拟作战空间中。虚拟实体作为LVC训练系统中的重要组成元素,主要通过提供“真实的战斗行动”与操作模拟器的训练人员交互。如果虚拟实体蓝方能够学习到作战对手红方的主要作战特点,那么蓝方在一定程度上便成为了红方的“化身”,主要体现为:① 虚拟实体拥有了红方的作战能力水平,不同对手会有作战能力水平的差别,战机性能相同的情况下,作战能力强的对手能够准确判断态势,抓住战机,迅速机动至最佳位置,作战能力弱的对手则容易被动挨打。② 虚拟实体拥有了红方的作战风格,不同对手即使作战能力水平相同,作战风格也会存在较大差异,例如相同态势下的攻击行为,有些对手擅长紧盯对方6点钟方向,达到射程便开火,有些则擅长迅速爬升战机,从对方头顶、背部发起攻击。由于近距空战高动态、强对抗的特点,每个战术动作的实施都直接影响整个空战进程。军事训练遵循由易到难,由简到繁的循序渐进原则,具有特定作战特点的决策模型可达到按需训练,循序渐进提升训练效果等目的。例如,根据某特级战机飞行员red_1的对抗训练数据,学习出具有red_1作战特点的虚拟实体blue_1。那么,便会有任意多的特级战机飞行员blue_1分别作为任意多红方训练人员red的“陪练”在任意时间、任意地域对抗。根据红方训练人员red_2在时间T的对抗训练数据,学习出具有T时间段red_2作战特点的蓝方虚拟实体blue_2_T。那么,训练人员red_2便可以和从前的“自己”blue_2_T对抗来检验这段时间的训练效果。
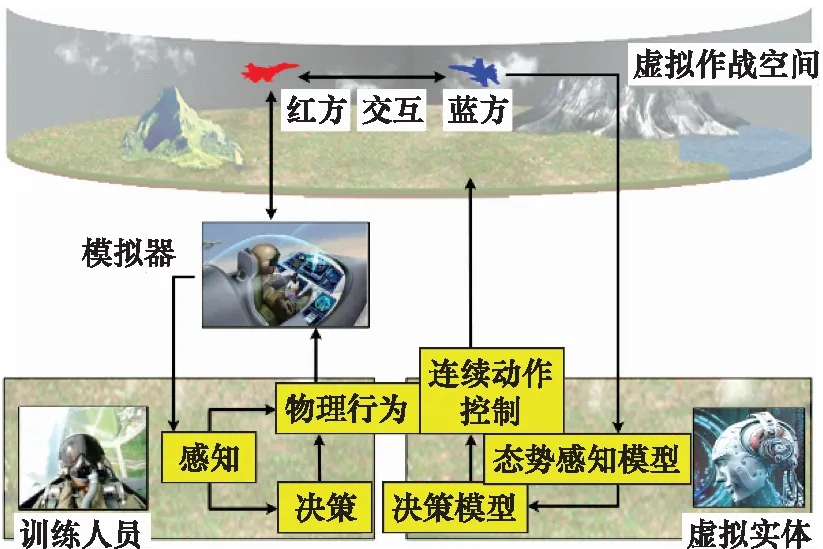
图1 人机近距空战对抗示意图Fig.1 Schematic diagram of close-range air combat between man and machine
空战智能决策方法的适用性随所研究虚拟实体的数量、属性(同构/异构)、任务、作战场景的不同而有所区别。按虚拟实体数量,将空战智能决策分为战斗级、分队级、集群级3个层面[3-8]。空战决策方法可归纳4大类:基于知识、推理、规划方法,基于问题求解方法,基于不确定知识推理方法,基于自主学习方法,如图2所示。
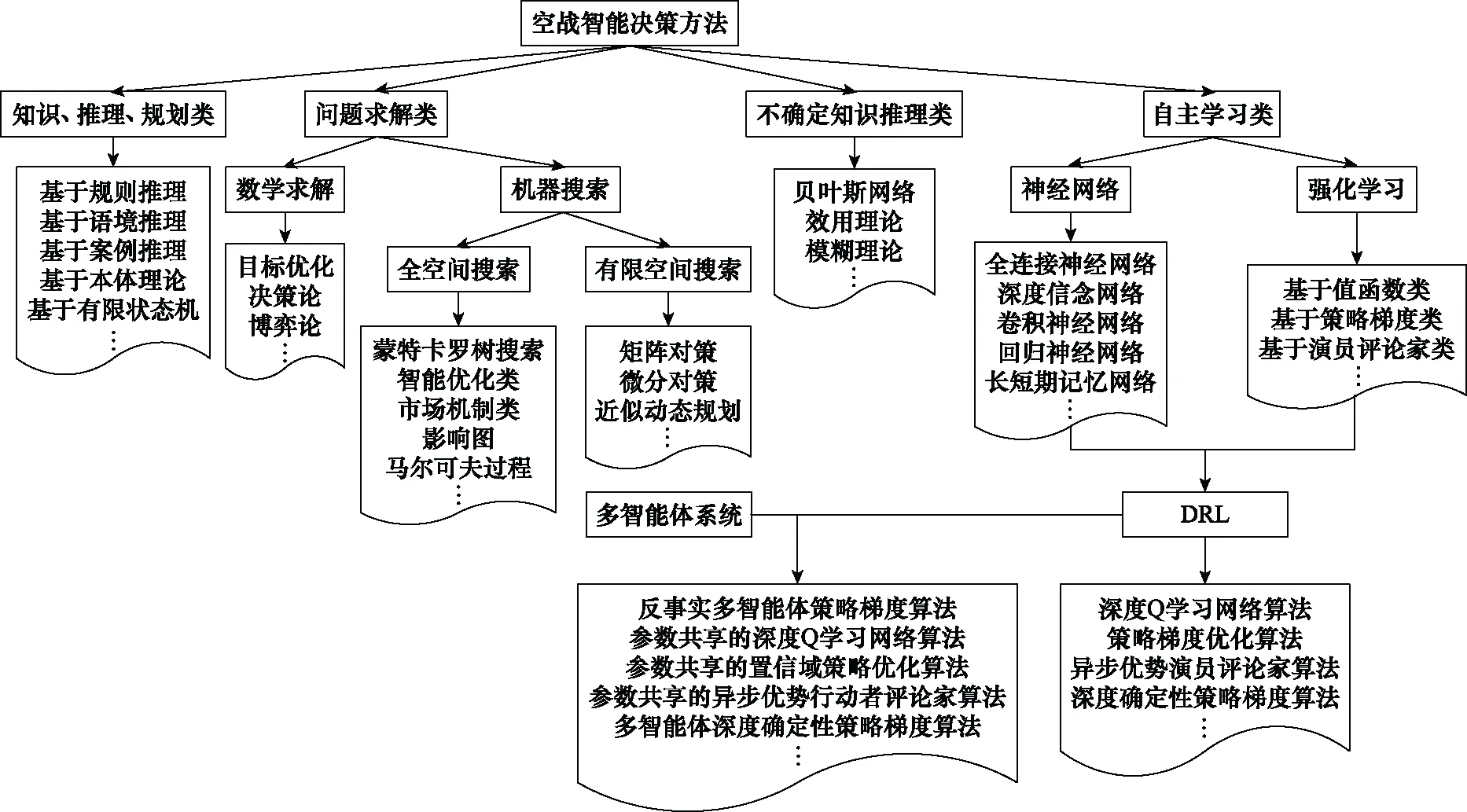
图2 空战智能决策方法分类Fig.2 Classification of air combat intelligent decision methods
近年来,国内外学者对基于自主学习、智能优化类方法的空战研究较多[8-13]。基于自主学习方法的空战研究集中在战斗级虚拟实体近距空战机动决策[13-19]。仿生优化类方法集中在分队级中距空战火力决策[20-25]。另外,战斗级虚拟实体近距空战机动决策还有基于博弈论[26]、近似动态规划[27]、数学求解[28]、贝叶斯[29-30]、模糊理论与其他方法结合[31-32]等方法。自主学习方法的研究热点又集中在深度强化学习(deep reinforcement learning, DRL)方面。DRL遵循马尔可夫决策过程(Markov decision process, MDP)或马尔可夫博弈过程(Markov game process, MGP),是使用MDP或MGP框架来形式化智能体与环境交互,并从与环境交互的经验中学习最优策略,从而最大化智能体累积期望奖励的一类方法,为空战决策建模提供了一种新途径。相关空战文献研究均是针对空战对手求解最优对抗策略,取得了较大进展,具有重要的军事意义。
本文试图构建适用于特定训练人员实际训练需求的蓝方虚拟实体决策模型,所建模型具有“虚拟陪练”的作用,没有从求解对手最优对抗策略的角度开展问题研究。目前,智能优化方法主要包括:遗传算法(genetic algorithm, GA)、人工免疫系统(artificial immune system, AIS)、模拟退火算法(simulated annealing algorithm, SA)、多目标进化算法(multi objective evolutionary algorithm, MOEA)等进化算法;粒子群优化(particle swarm optimization, PSO)、蚁群优化(ant colony optimization, ACO)、人工蜂群算法(artificial bee colony algorithm, ABC)等群体智能算法(swarm intelligence algorithm, SIA)。这类方法可以在解空间内搜索全局最优解,并且可以对多个目标函数同时进行优化,输出一组非支配的帕累托解集,有效地求解多目标问题,具有良好的全局优化性和鲁棒性。由于智能优化类方法可以通过适应度函数来定义所求解问题的目标,进而寻找满意解,而不仅是局限于求解空战对手的最优策略问题,同时考虑到神经网络较强的拟合能力,本文将智能优化方法与神经网络结合,根据具体训练需求,构建适应度函数,通过神经网络实现端到端感知决策,从智能优化理论的角度对神经网络的权值空间和结构空间进行定义,最终实现能够满足适应度函数的神经网络端到端感知决策,即实现满足特定训练人员训练需求的蓝方战机近距空战决策。
2 模型构建与求解
蓝方虚拟实体决策模型构建思路如图3所示。虚拟实体由一个权值可以被智能优化算法优化的神经网络控制,将影响战斗结果的关键飞行状态数据X={x1,x2,…,xn}作为神经网络的输入,战机的动作空间A={a1,a2,…,am}分布作为神经网络的输出,实现虚拟实体端对端的感知与决策控制。将神经网络权值矩阵W控制的虚拟实体建模为智能优化算法群体中的个体,并初始化为规模为M的群体。针对决策建模需求,构造智能优化算法适应度函数,通过统计固定时间内对抗双方的战斗得分,保留得分差距小的个体,淘汰比分差距大的个体,并通过虚拟实体神经网络权值的不断迭代寻优,最终达到与训练人员作战能力、作战风格相当的水平,成为该训练人员的“化身”。

图3 决策模型构建示意图Fig.3 Schematic diagram of decision model construction
2.1 关键飞行状态
图4展示了1对1红蓝近距空战场景,假定战机t时刻以固定速度在x-y平面上机动,蓝方虚拟实体的目标是学习一种策略来控制战机机动并保持对对手的位置优势,进而在射程内发起攻击。
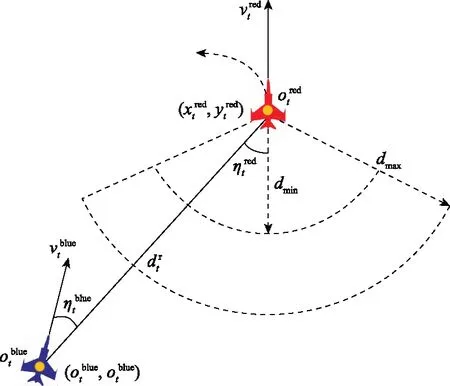
图4 飞行运动示意图Fig.4 Flight motion diagram
将优势位置[33]定义为
(1)

2.2 飞行动作空间
分析战机的运动模型,设计战机飞行动作空间,飞行器的运动方程为
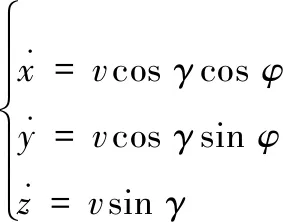
(2)
式中,(x,y,z)表示战机的坐标;v,γ,φ分别表示战机的速度、航迹角、偏航角。飞机的动力学方程为
(3)
式中,m,g,L,D,T,α,φ分别表示战机的质量、重力加速度、升力、牵引阻力、推力、攻击角度、倾斜角。实际近距空战中,战机的速度是一个在高亚音速区连续变化的值,本文在不影响验证方法有效性的条件下,将问题简化为战机在水平面上以固定速度v飞行,v∈[980 km/h,1 102.5 km/k],战机运动方程简化为
(4)
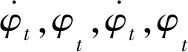
2.3 适应度函数
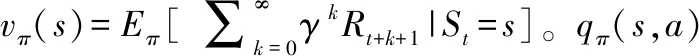
图5为决策模型求解示意图,将智能优化算法中个体q建模为权值矩阵为由Wq的神经网络控制的蓝方虚拟实体,假设q在T时间内与训练人员red进行了K场战斗。
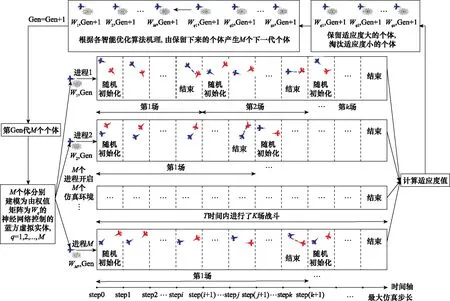
图5 决策模型求解示意图Fig.5 Schematic diagram of decision making model solution
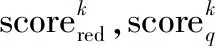
k=1,2,…,K
(5)
红蓝战机采用空空导弹攻击对方,导弹数量为1枚,每场战斗中,红蓝双方个体胜负的评判标准为

(6)
当出现一方胜利或判断为平局时,战斗结束。
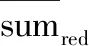
(7)
(8)

(9)
定义适应度函数为
(10)
3 基于遗传神经网络的模型构建与求解示例
示例设计思路是使战机飞行员red_x在每次训练过程中与特定虚拟实体blue_x对抗。blue_x在对抗过程中利用对抗数据优化自身的神经网络权值,并在每次训练完毕保存最新神经网络模型π。当red_x再次进行对抗训练时,blue_x首先在初始化时加载模型π,并在此基础上继续优化模型。虽然随着训练时间的增加,red_x的战技水平在提升,但算法控制的blue_x提升速度要远超过red_x,最终通过迭代进化与red_x的作战水平和作战风格相当。此时,其他飞行员red_y与blue_x对抗,就相当于和战机飞行员red_x对抗。考虑到LVC训练系统在建设过程中以及真实对抗数据的敏感性,本文采用具有学习能力的遗传神经网络代替真实飞行员red_x,分析训练迭代过程中blue_x的适应度函数变化、每代击毁对手所用平均时间变化、每代优化所用时间变化、虚拟实体胜率变化以及对比分析模型收敛后red_x和blue_x在L次对抗过程中的飞行动作序列相似度,验证蓝方虚拟实体学习效果的有效性。
3.1 构建与求解
本节采用经典GA作为优化神经网络权值的算法,给出蓝方战机决策模型及其求解示例,如图6所示。
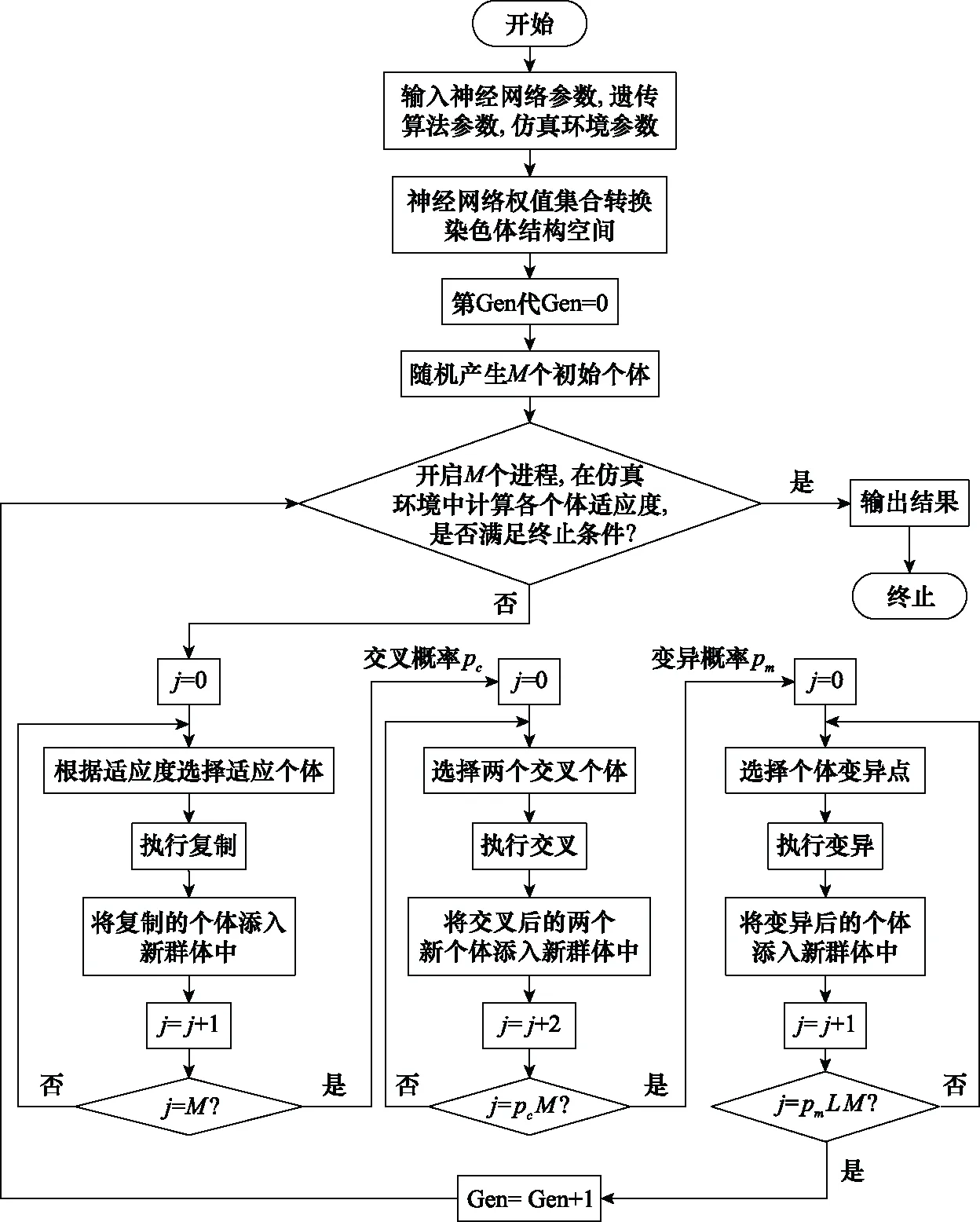
图6 基于遗传神经网络的蓝方战机决策模型构建与求解示例Fig.6 Construction and solution example of blue fighter decision making model based on genetic neural network
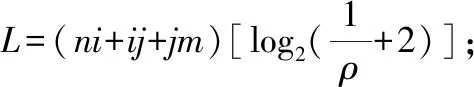
输出最优神经网络权值。
步骤 1将神经网络权值W转换为染色体结构空间。
步骤 2Gen=0,随机产生M个初始个体Wq,q=1,2,…,M。
步骤 3开启M个进程,进程q运行个体Wq,如果f(Wq)>M,解码,输出最优神经网络权值,结束寻优;否则,进入步骤4。
步骤 4选择操作,根据适应度,按照一定的规则,从第Gen代群体中选择出下一代优良的个体遗传到Gen+1代群体中:
步骤 4.1j=0;
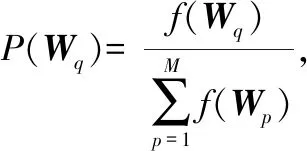
步骤 4.3执行复制;
步骤 4.4将复制的个体添入新群体中;
步骤 4.5j=j+1;
步骤 4.6如果j=M,执行步骤5;否则执行步骤4.2;
步骤 5交叉操作,将第Gen代群体内的各个个体随机搭配成对,对每一对个体,以交叉概率pc遵循某一规则交换其部分染色体:
步骤 5.1j=0;
步骤 5.2选择两个交叉个体;
步骤 5.3执行交叉;
步骤 5.4将交叉后的两个新个体添入新群体中;
步骤 5.5j=j+2;
步骤 5.6如果j=pcM执行步骤6;否则执行步骤5.2。
步骤 6变异操作,对第Gen代群体的每一个个体,以变异概率pm改变某一个或某一些染色体基因座上基因值为其他的等位基因:
步骤 6.1j=0;
步骤 6.2选择基因变异点;
步骤 6.3执行变异;
步骤 6.4将变异后的两个新个体添入新群体中;
步骤 6.5j=j+1;
步骤 6.6如果j=pmLM,产生下一代群体,执行步骤3;否则执行步骤6.2。
3.2 结果分析
图7为适应度函数变化曲线,随着迭代次数的增加,曲线趋于平稳,说明蓝方虚拟实体与红方的战斗得分差值在减小。
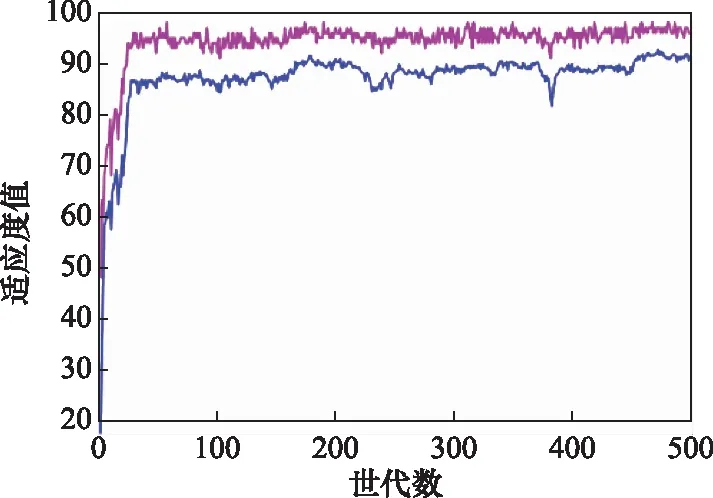
图7 适应度函数变化曲线Fig.7 Variation curve of fitness function
统计虚拟实体每训练N轮的标准偏差为
i∈(episode,episode+N-1)
(11)

图8(a)为蓝方虚拟实体每代击毁对手所用的平均时间步长变化曲线,计算公式为
(12)
可以看出,曲线随着世代数的增长,呈快速下降趋势,并逐渐趋于平稳。这说明蓝方虚拟实体的作战能力在增加。图8(b)为每代优先所用时间变化曲线,计算公式为
(13)
可以看出,由于蓝方虚拟实体作战能力的增加,使得每代击毁对手所用的平均时间步长减少,导致每代寻优所用时间减少,图8(a)和图8(b)相互印证。虽然图8(b)曲线呈现快速下降,并逐渐趋于平稳的趋势,但是大致在460代时出现了峰值。结合图5决策模型求解示意图以及式(11)可知,导致上述现象的可能原因有:群体交叉、变异产生新的少数个体延长了一代的整体优化时间;红蓝双方在每场战斗开始时,位置随机初始化,并在格斗过程中相互追逐、纠缠,空战态势的不确定性导致整体优化时间的波动。
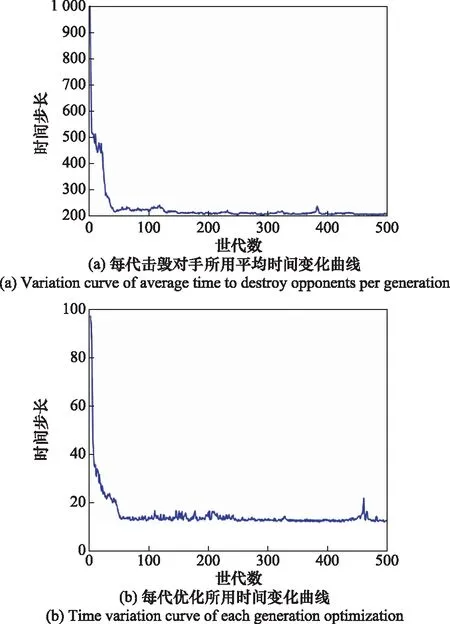
图8 时间变化统计(以步长为单位)Fig.8 Time change statistics (in steps)
图9为蓝方虚拟实体的胜率随世代数的变化曲线,计算公式为

图9 虚拟实体胜率曲线Fig.9 Winning rate curve of virtual entity
(14)
如果个体q胜利,则countq=1;否则,countq=0。可以看出,蓝方虚拟实体的胜率在50%上下波动,结合图7分析可知,虽然蓝方虚拟实体的作战能力在增加,但是胜率并没有增加,这说明红蓝对抗双方均在学习如何作战,用神经网络模拟的人类飞行员与真实飞行员的差别在于神经网络的学习速度远高于人类。
图10 红蓝方飞行动作序列获取示意图Fig.10 Schematic diagram of flight action sequence acquisition of red and blue
为进一步验证蓝方战机可实现通过与对手对抗来学习对手作战特点的能力,定义B和R的相似度D计算公式为
(15)
式中,len(B)和len(R)分别表示序列B和序列R的长度;min(len(B),len(R))分别表示序列B和序列R长度的最小值;MCOSS(B,R)为B和R的最长公共作战行动子序列(maximum common operational sub-sequence,MCOSS)。值得注意的是,子序列是有序的,但不一定是连续的。用动态规划方法计算MCOSS(B,R)为
MCOSS(B,R)=

(16)
式中,序列B=(b1,b2,…,bT),R=(r1,r2,…,rT)中,head(B)表示b1,rest(B)表示(b2,b3,…,bT),head(R)表示r1,rest(R)表示(r2,r3,…,rT),ε为判断阈值。使用极坐标(ρ,θ)表示战机的位置,ρ和θ分别表示战机质心的极径和极角。战机的飞行动作序列可进一步用(ρ,θ,φ,f)四元组表示,f表示是否开火(f=1开火,f=0未开火),即bi=(ρi,θi,φi,fi),rj=(ρj,θj,φj,fj),只有当bi-rj<ε时,才认为元素bi=rj,ε=(Δρ,Δθ,Δφ,Δf),即
1对1近距空战是双方战机相互抢占优势位置,摆脱劣势位置,并在构成开火条件时,先对方命中目标的过程。一方战机位置的优势与劣势是相对于对方战机的距离、角度来说的。因此,战机在追逐,盘旋格斗过程中,作战能力水平相当的双方战机,会在作战行动序列上呈现一定的相似性。采集L=10场战斗的红蓝战机飞行动作序列B和R,设置战机位置误差Δρ=100 m,Δθ=10°,根据格斗导弹构成开火条件的离轴角范围,设置Δφ=30°,Δf=0.5来判断战机的射击动作是否相同。使用式(14)对飞行动作序列相似度进行统计,如表1所示,飞行动作序列平均相似度为0.68,该值会随Δρ,Δθ,Δφ的设定而有所变化。算法试图从近距空战的制胜原理出发,将关键飞行状态作为输入,目标函数仅是淘汰比分差距大的个体,保留比分差距小的个体,并没有淘汰作战行动序列相似度低的个体,保留作战行动序列相似度高的个体。这是因为战机的优势、劣势位置并不是单一的,对战双方的策略也不是单一的,这也在一定程度上避免了神经网络的过拟合。战斗得分小于某一阈值,可以认为战机的作战能力是相当的。在此基础上,飞行动作序列平均相似度超过0.5,可以说明作战能力水平相当的双方战机,作战行动序列会在空战过程中呈现一定的相似性。图11为红蓝双方飞行动作序列轨迹的极轴-偏航角坐标可视化表示。其中,红色轨迹为红方战机的飞行动作序列,蓝色轨迹为蓝方战机的飞行动作序列。从图11中可以看出,红蓝双方的飞行运动轨迹具有一定的相似性,与式(14)的计算结果相互印证,进一步说明了蓝方战机可实现通过对抗数据来学习对手作战特点的功能。

表1 飞行动作序列相似度统计
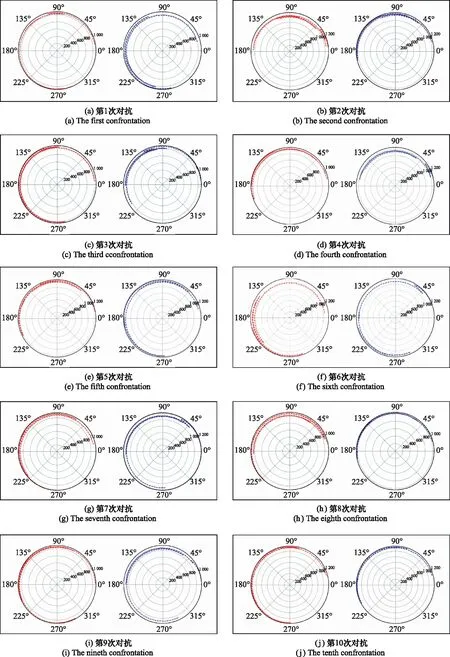
图11 红蓝双方飞行动作序列图Fig.11 Sequence diagram of actions for red and blue flight
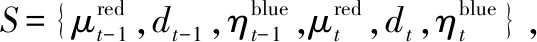
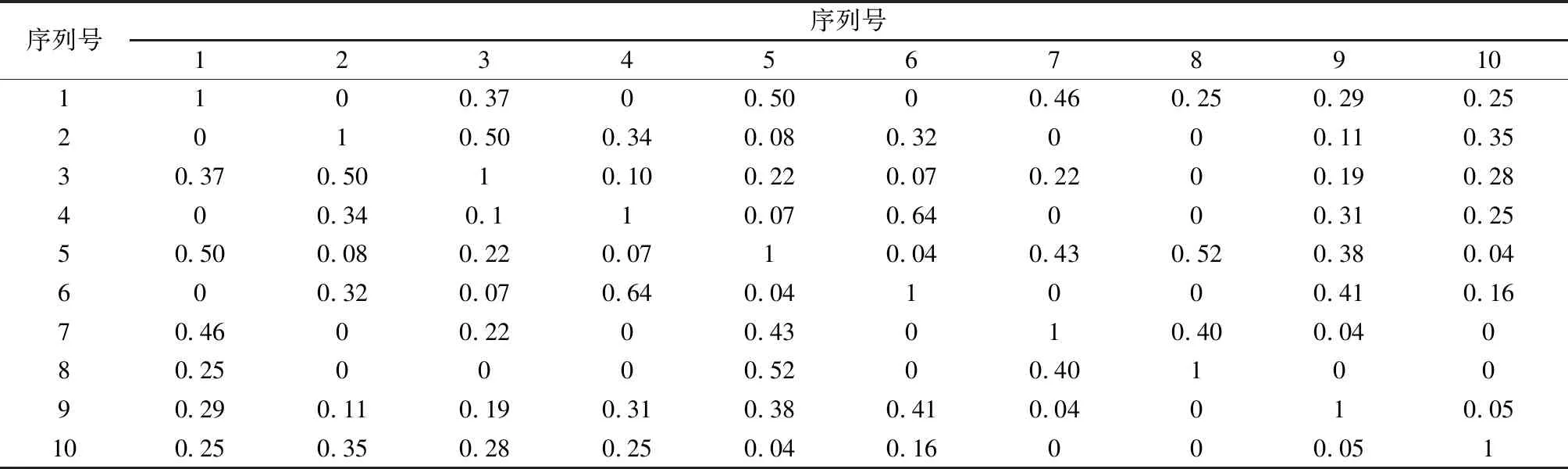
表2 红方作战行动序列相似度矩阵

表3 蓝方作战行动序列相似度矩阵
(17)
可以看出,红、蓝方作战行动序列间的平均差异度分别为0.19和0.21,数值均较小,说明各方策略差异均较大,具有多样性。
4 结 论
本文针对LVC近距离空战对抗训练对蓝方虚拟实体决策建模需求,提出基于智能优化算法的神经网络进化方法构建决策模型,通过实验数据分析,蓝方虚拟实体可实现通过与对手对抗来学习对手作战特点的功能。这使得蓝方虚拟实体通过加载训练好的模型可满足任意多红方训练人员在任意时间、任意地域与“特定作战对手的化身”或者“以前的自己”展开对抗训练,从而达到提升训练水平、降低训练成本的目的,同时为智能蓝军建设提供了有效技术支撑。所提方法对目前智能优化类算法及其改进类型,以及不同结构的神经网络具有通用性。
本文不足之处在于由于目前不具备人类飞行员与虚拟实体对抗的条件,所以暂且使用了具有学习能力的神经网络来模拟红方训练人员,下一步会将方法应用于实际LVC训练系统中,从实际应用角度进行综合验证和分析。
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26
小学科学(学生版)(2021年10期)2021-11-05
小哥白尼(军事科学)(2020年9期)2021-01-18
小哥白尼(军事科学)(2020年1期)2020-06-16
小哥白尼(军事科学)(2018年6期)2018-09-10
军营文化天地(2017年6期)2017-06-28
民间故事选刊·上(2017年5期)2017-05-17
小小说月刊(2015年5期)2016-01-22
微型小说选刊(2015年3期)2015-11-18
百科探秘·航空航天(2015年10期)2015-11-07
