
基于多传感器融合的复杂越野环境人员识别方法
2021-06-16 04:23刘英哲范晶晶李志鹏郭建英
汽车工程学报 2021年3期
刘英哲,范晶晶,李志鹏,郭建英
(1.北方工业大学 城市道路交通智能控制技术北京重点实验室,北京 100144;2.中国北方发动机研究所,天津 300405;3.顺德中专学校,广东,佛山 528300)
军用无人车辆的一大应用场景就是班组伴随、跟随士兵,减轻班组成员的负荷,可以从整体上提升班组的战斗能力。实时、准确并且可靠地检测出车辆周边的人员,是班组伴随自动驾驶实现的前提,行之有效的人员检测技术能够帮助班组伴随无人驾驶车辆实现自动跟随功能。
由于激光雷达和摄像头原理不同,受环境影响的特点也不尽相同,采用单一传感器对人员进行检测,难以适应复杂的环境,所以大都采用多传感器融合的方式。在激光雷达和摄像头融合领域,PREMEBIDA等[1-6]通过不同方法配置的图像数据和激光雷达点云数据训练得到自适应人员检测器。PONZ等[7-14]通过联合概率数据关联方法对激光雷达、摄像头以及惯性传感器等的静态信息和在线信息进行数据关联,以达到检测人员的目的。在毫米波雷达和摄像头融合领域,徐伟等[15-16]基于图像的HOG特征和SVM分类方法以及毫米波雷达的快速容差中频匹配算法,设计了多传感器融合的行人识别算法,但由于HOG特征本身的局限性,行人识别率相对较低。
本文针对自动驾驶车辆对于复杂环境下人员识别的需求,将摄像头和激光雷达作为感知设备,针对激光雷达采用基于KDTree加速的欧式聚类方法,针对摄像头设计改进YOLO v3深度学习网络架构,最后设计空间融合识别算法,旨在增加人员识别的准确率。通过理论计算和理论分析,结合本文所设计的微型履带式车辆验证平台,在复杂环境下进行多工况实车试验。试验结果表明,所设计的多传感器融合人员识别算法能够准确识别环境中的人员目标,在复杂环境下识别率良好。
1 系统构成
复杂环境下融合激光雷达与摄像头的人员识别系统,如图1所示。
图1中,通过以太网接口和激光雷达驱动程序获得激光雷达三维点云数据,随后应用基于KDTree的欧式聚类算法对激光雷达三维点云数据进行欧式分割和聚类[17],得到若干个人员候选点云区域。通过像素坐标系到世界坐标系的映射关系和激光雷达坐标系到世界坐标系的映射关系,可得到激光雷达坐标系到像素坐标系的映射关系,结合空间尺度融合算法将若干个人员候选点云区域分别映射到像素坐标系,并通过改进残差模块的YOLO v3深度学习网络架构识别出真正包含人员的区域,并通过矩形框的形式给出各个人员在像素坐标系下的具体坐标位置,最后通过人员身份判别准则判定环境中人员是否存在、数量和位置等相关信息。
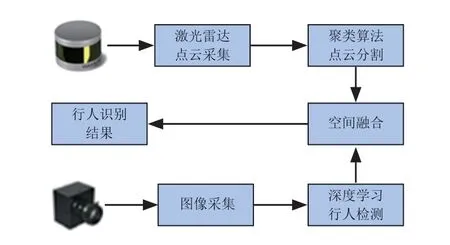
图1 融合激光雷达与摄像头的人员识别系统
2 方法设计
2.1 改进残差模块的YOLO v3深度学习架构
为了进一步提升YOLO v3深度学习网络在复杂环境背景下对目标物体的识别性能,结合当前深度学习领域的热点研究成果,本文提出了一种改进残差模块的YOLO v3深度学习网络结构,如图2所示。
图2中,改进残差模块的YOLO v3深度学习网络结构与原始YOLO v3深度学习网络结构的差别主要体现在残差模块Residual Block的设计上。原始YOLO v3深度学习网络中,残差模块RB的输入经过两个CBL模块处理后的信号再与RB模块的输入作相加的操作,得到的结果便是RB模块的输出。改进残差模块的YOLO v3深度学习网络中,在原始YOLO v3网络RB输出的基础上增加了全局池化层、两个全连接层、Sigmoid激活函数层和乘法层。具体来说,原始YOLO v3网络RB输出,经过全局池化层、全连接层、全连接层和Sigmoid激活函数层操作后,再与原始YOLO v3网络RB输出的结果相乘,得到改进后的残差模块输出。图3中,3个输出通道y1、y2和y3的深度均为255,这是针对COCO数据集时的结果。改进残差模块的YOLO v3深度学习网络中,针对每一个网格单元进行预测时都会得到3个矩形框,每个矩形框有左上角横坐标、左上角纵坐标、宽度、高度和置信度等5个参数,同时由于COCO数据集有80种目标类型,因此,每个矩形框还必须包含这80种目标的概率,因此,输出通道y1、y2和y3的深度为3×(5+80)=255。对于包含n种目标类型的任意数据集来说,输出通道y1、y2和y3的深度dep可由式(1)来进行计算。


图2 改进残差模块的YOLO v3网络结构
与原始YOLO v3网络相比,改进残差模块的YOLO v3网络在深度上明显更胜一筹,增加了(1+2+8+8+4)=23个全局池化层,增加了2 ×(1+2+8+8+4)=46个全连接层,增加了(1+2+8+8+4)=23个Sigmoid激活函数层,增加了(1+2+8+8+4)=23个乘法层,所有网络层数等于255+23+46+23+23=370个。相比于原始YOLO v3网络,网络层数增加了(370-255)/255=45.1%,网络层数量提升效果明显。
改进残差模块的YOLO v3网络层数量分布见表1。
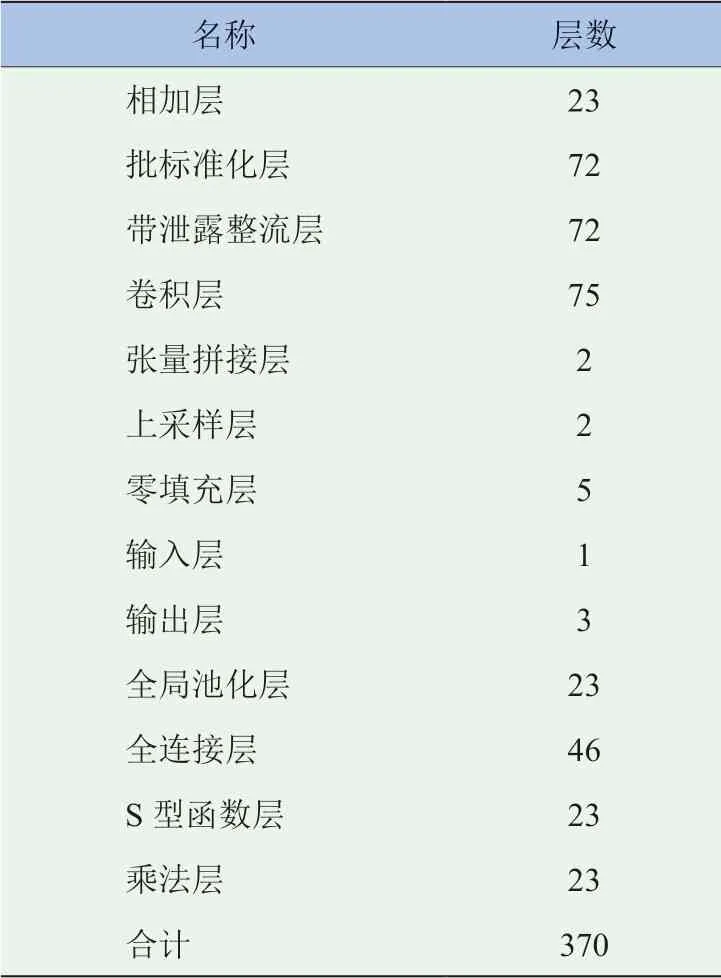
表1 改进残差模块的YOLO v3网络层数量分布
2.2 空间尺度融合
假定激光雷达相对于世界坐标系的俯仰角为θL,激光雷达相对于世界坐标系的方向角为φL,激光雷达相对于世界坐标系的侧倾角为ψL,激光雷达相对于世界坐标系原点的高度为hL,激光雷达相对于世界坐标系原点的横向距离为dL,激光雷达相对于世界坐标系原点的纵向距离为lL。激光雷达坐标系和世界坐标系的位置关系如图3所示。
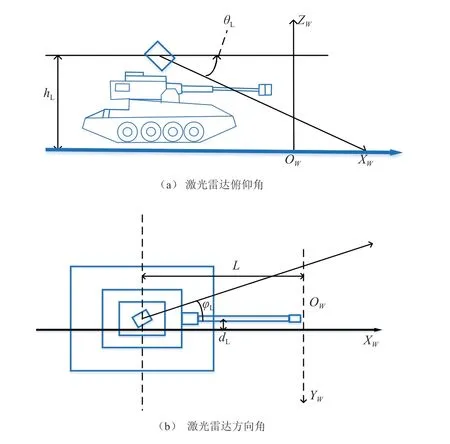
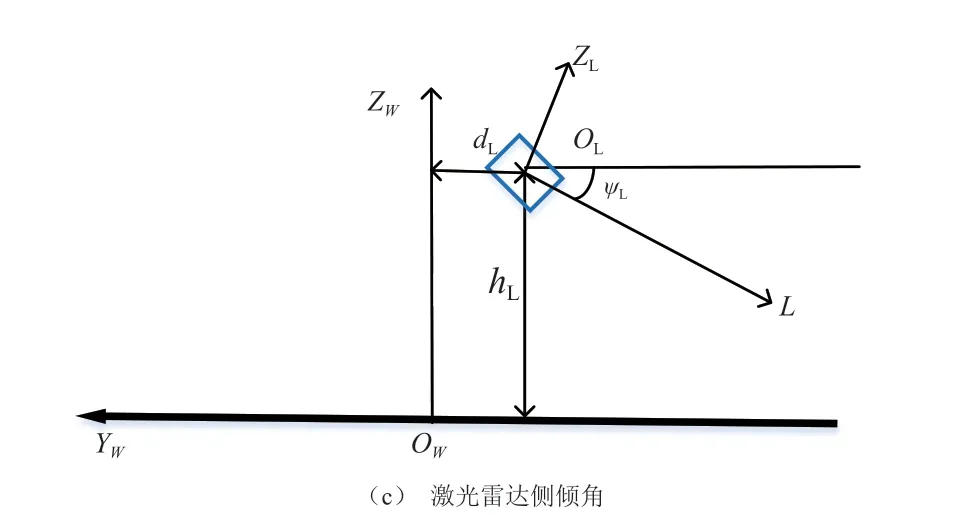
图3 激光雷达和世界坐标系的位置关系
根据激光雷达坐标系和世界坐标系之间的旋转和平移关系可得世界坐标系到激光雷达坐标系的映射关系,如式(2)所示。
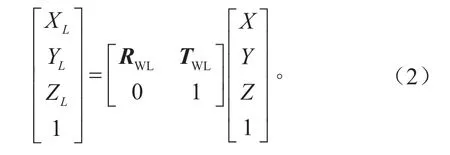
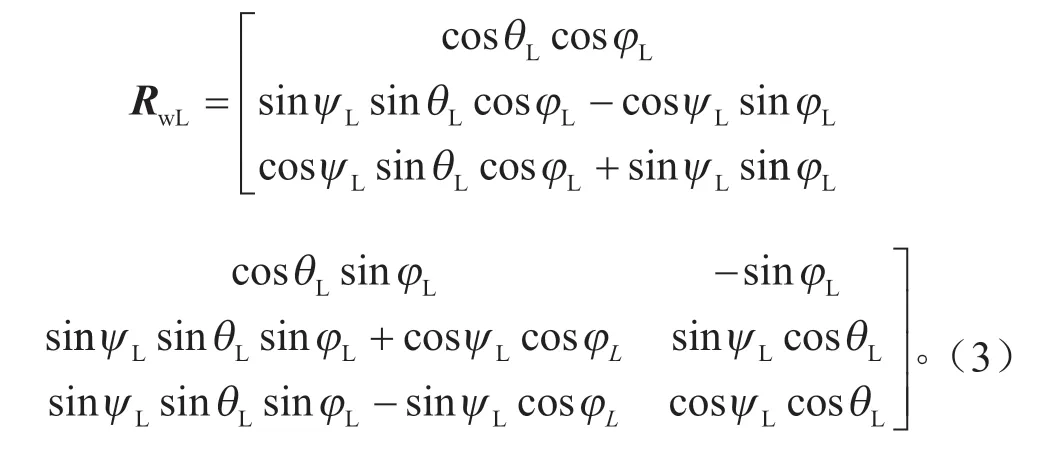
TwL的表达式为:

假定摄像机相对于世界坐标系的俯仰角为θ,摄像机相对于世界坐标系的方向角为φ,摄像机相对于世界坐标系的侧倾角为ψ,摄像机相对于世界坐标系原点的高度为h,摄像机相对于世界坐标系原点的横向距离为d,摄像机相对于世界坐标系原点的纵向距离为l。根据摄像机坐标系和世界坐标系之间的旋转和平移关系以及像素坐标系与相机坐标系之间的映射关系,可得世界坐标系到像素坐标系的映射关系,如式(5)所示。
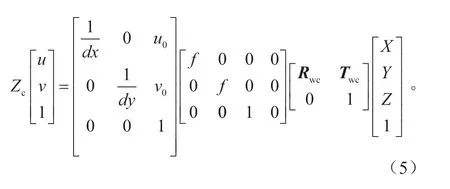
式中:Zc为三维坐标系压缩至二维像素坐标系的变换因子;(u,v)为像素坐标系下的坐标;f为相机的焦距;dx为每个像素在图像坐标系u坐标轴方向上的尺寸;dy为每个像素在图像坐标系v坐标轴方向上的尺寸。世界坐标系到相机坐标系的旋转矩阵Rwc的表达式为:
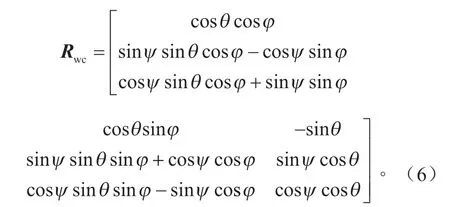
世界坐标系到相机坐标系的平移矩阵Twc的表达式为:
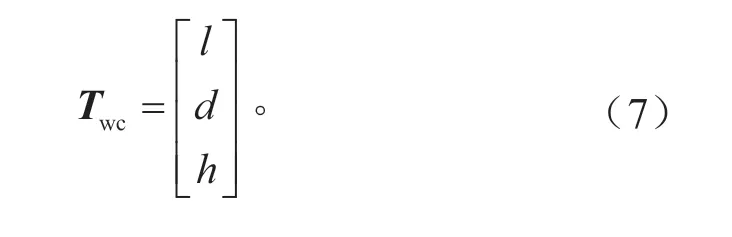
结合上文推导的世界坐标系到像素坐标系的映射关系以及世界坐标系到激光雷达坐标系的映射关系,可得激光雷达坐标系到像素坐标系的转换关系,如式(8)所示。根据式(8),可以完成激光雷达和摄像头在空间尺度上的融合。
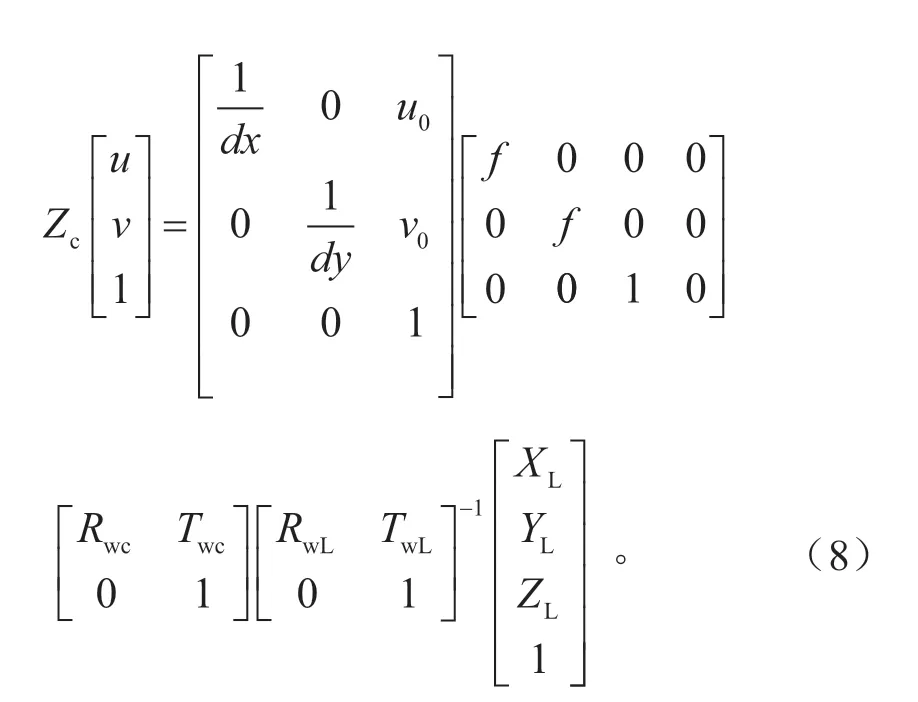
3 试验验证
为了验证所设计的基于摄像头图像的深度学习网络结构以及激光雷达和摄像头融合算法在复杂环境下对于人员识别的效果,搭建了如图4所示的履带式车辆验证平台。

图4 履带式车辆验证平台
图4中,摄像头遵循标准UVC协议(USB Video Class Protocol),其技术参数见表2。
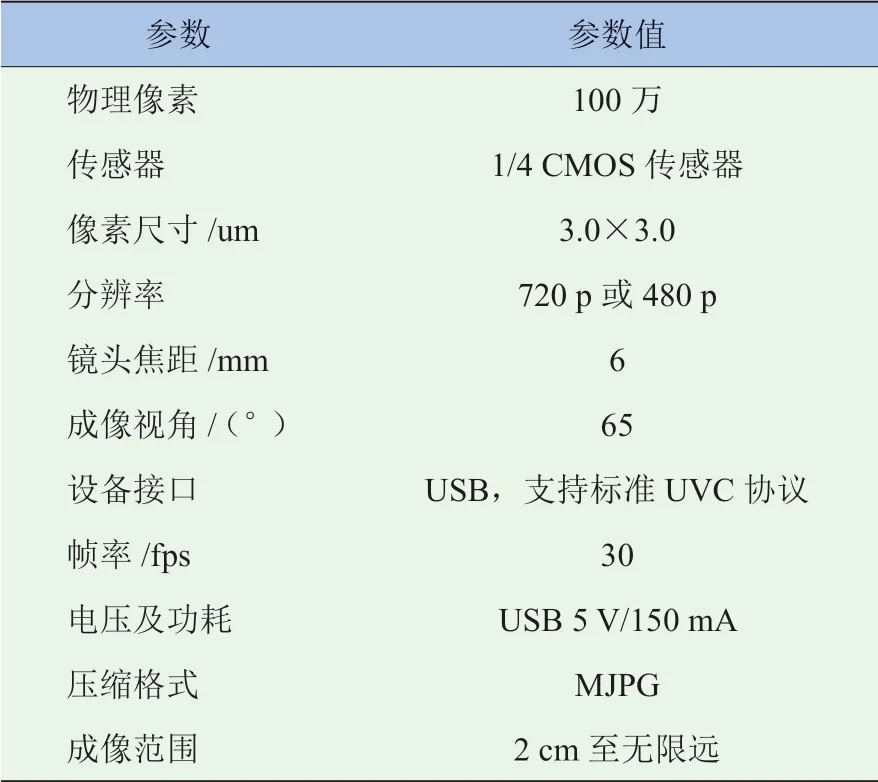
表2 摄像头技术参数
试验环境选择为非结构化道路的复杂野外环境,该环境中包含有凹凸不平的草地、数目众多且与人员高度相近的树木、高压线塔以及高度不等的建筑物等,将试验工况划分为单人工况和双人工况。针对所设计的单人工况和双人工况分别进行实车试验,可以得到各种工况下传感器融合的识别结果。
3.1 单人识别工况
单人工况融合识别结果如图5所示。由图5可知,摄像头的图像标注结果中,红色矩形框除了标注了目标的类型为person,目标类型为person的概率为1.00,目标与试验车辆前部的距离为10.3 m以外,还有一个LC的标签。LC是LiDAR Confirmed的缩写,代表红色矩形框内的人员目标已经得到了激光雷达的确认,说明激光雷达和摄像头的融合是有效果的。具体融合准则的运行和判断是在后台的终端中完成的,具体计算过程如下:
(1)激光雷达测量距离与摄像头测量距离之间的误差为:|9.88-10.3|/9.88=4.25%,在误差容许范围之内。(2)摄像头给出目标为person的置信度为1.00,该置信度已经达到最大值,符合设计要求。(3)激光雷达三维点云数据中人员目标的高宽比计算值为1.21,摄像头识别到的人员目标矩形框的高宽比为(384-154)/(319-237)=2.8,二者的计算值均在合理范围之内,符合设计要求。(4)激光雷达识别到的人员点云映射到像素坐标系后,得到的矩形框与摄像头识别到的人员矩形框交并比的计算值为95.4%,达到了95%以上,符合设计要求。

图5 单人工况融合识别结果
3.2 双人识别工况
双人工况融合识别结果如图6所示。由图6可知,摄像头的图像识别结果中,红色矩形框除了标注了两个目标的类型均为person,两个目标为person的概率均为1.00,左侧人员目标与试验车辆前部的距离为8.3 m,右侧人员目标与试验车辆前部的距离为8.5 m以外,在两个人员目标上均有LC的标签,代表两个红色矩形框内的人员目标都已经得到了激光雷达的确认,说明激光雷达和摄像头的融合是有效果的。具体融合准则的运行和判断是在后台的终端中完成的,过程如下:
(1)激光雷达测量距离与摄像头测量距离之间的误差为:左侧人员目标|7.89-8.3|/7.89=5.20%,右侧人员目标|8.07-8.5|/8.07=5.33%,两个误差均在容许的范围之内,符合设计要求。
(2)摄像头给出两个人员目标为person的置信度均为1.00,该置信度已经达到最大值,符合设计要求。
(3)激光雷达三维点云数据中左侧人员目标的高宽比计算值为1.48,摄像头识别到的左侧人员目标矩形框的高宽比为(447-123)/(268-147)=2.68,二者的计算值均在合理范围之内;激光雷达三维点云数据中右侧人员目标的高宽比计算值为1.78,摄像头识别到的右侧人员目标矩形框的高宽比为(400-118)/(587-482)=2.69,二者的计算值均在合理范围之内。总之,两个人员目标在激光雷达和摄像头下的高宽比均符合设计要求。
(4)激光雷达识别到的左侧人员点云映射到像素坐标系后,得到的矩形框与摄像头识别到的左侧人员矩形框交并比的计算值为95.6%,激光雷达识别到的右侧人员点云映射到像素坐标系后,得到的矩形框与摄像头识别到的右侧人员矩形框交并比的计算值为96.3%,均达到了95%以上,符合设计要求。
综上所述,双人工况下,激光雷达和摄像头识别到的两个人员目标均通过了所设计的空间融合准则,可以认定摄像头和激光雷达识别到的左侧人员是同一个人员目标,摄像头和激光雷达识别到的右侧人员是同一个人员目标。

图6 双人工况融合识别结果
3.3 单人跟随识别工况
在上述野外环境中,跟随单人行驶,车辆和引导员之间的距离控制在5~10 m,车辆行驶约50 m,平均行驶速度约4 km/h,得到跟随工况识别的统计结果见表3。

表3 单人跟随工况识别统计结果
在该工况下,人员没有出现未识别情况,在统计结果中,摄像头和激光雷达识别距离平均误差为8.2%,高宽比平均误差为5%,交并比的统计平均值为93.2%,该结果能够满足人员跟随系统的设计要求。
4 结论
本文针对复杂环境下人员识别系统开发中所存在的一些难以解决的问题,首先建立了多传感器融合体系架构,重点研究了基于图像的深度学习人员识别方法以及激光雷达和视觉融合算法等方法,并在搭建履带式越野车辆试验平台的基础上,选择合适的试验环境并设计合理的试验工况进行试验验证,验证了所设计的算法在复杂环境下的有效性,并得到以下结论:
(1)设计的改进残差模块的YOLO v3深度学习网络架构可以在越野环境中识别人员,对人员的识别效果达到了设计的要求。
(2)激光雷达和摄像头融合算法实现了在空间尺度上的融合,融合效果达到了设计要求。
本研究仅融合了激光雷达与摄像头,随着车载传感器数量的逐渐增加,后期有关多传感器融合的研究会逐步扩展到毫米波雷达、红外相机以及惯性导航系统等,试验环境的复杂度以及试验工况的种类也有待进一步扩展和加强,自适应阈值算法对于识别效果的提升也有待进一步验证。
猜你喜欢
心理学报(2022年9期)2022-09-06
成都信息工程大学学报(2022年2期)2022-06-14
农业工程学报(2022年4期)2022-04-24
心理学报(2022年4期)2022-04-12
导航定位学报(2022年2期)2022-04-11
北京大学学报(自然科学版)(2022年1期)2022-02-21
汽车观察(2021年8期)2021-09-01
科技研究·理论版(2021年20期)2021-04-20
语数外学习·高中版中旬(2021年11期)2021-02-14
计算机与网络(2020年19期)2020-12-04
