
基于共有文本特征词跨类联合分类的电力文本分类算法研究
2021-06-16 09:36王琼杨波陈佐虎
电子技术与软件工程 2021年7期
王琼 杨波 陈佐虎
(1.国网甘肃省电力公司信息通信公司 甘肃省兰州市 730050 2.甘肃同兴智能科技发展有限责任公司 甘肃省兰州市 730030)
1 引言
电力公司各部门长期积累大量垂直型文档数据[1],但是少有人关注随着数据量的增加随之而带来的管理问题[2]。文本数据缺乏分类标准与依据、分类不合理、自动分类智能化程度不高,这些都为电力企业的文档资料管理工作带来了巨大挑战[3]。网络大数据信息挖掘、自然语言处理、信息检索等各类技术的多融合应用能很好地解决信息过载时代的亟待解决的开放域与垂直域中的文本数据管理问题。文本分类技术作为这些领域的技术基石和先期任务,为了适应文本管理过程中需要处理的内容、类型各异的数据对象,相关技术在近年来得到了快速发展和广泛关注[4-6]。传统的文本分类是由专家或专业人士等大规模人工干预的条件下进行的标签注释和手工分类的工作。人工分类方法费时费力,且易受个体理解的影响,无法保证分类的统一标准。相对于人工方法,自动分类方法可以有效地减少分类工作的繁杂性,且大幅度提高了信息处理的效率。然而,随着数字化企业技术的发展,公司文本数据以指数级增长,这给文本智能分类技术带来了巨大挑战[7-8]。
2 电力文本管理现状分析
近年来,随着现代电力系统的日益发展,贯通全电网数据通信机制、智能化管理、数据应用超市的上线和运行的过程中,电力数据出现了井喷式增长的现象。而长期积累的电力运维历史数据与日益新增的运维数据、业务数据已成为电网企业业务运行的关键保障之一,同时也是电网企业实现数据二次利用、基于数据的知识挖掘并以此为依据,实施业务和管理机制做深化改进的宝贵数据资产。当前理论成熟且满足工业生产需求的自然语言处理手段、人工智能学习模型等技术及方法已在各个行业和领域得到了快速发展,这为实现垂直领域下的专业性文本管理提供了良好的先决条件和可实现性。结合电力行业的业务发展和生产需求,本文将从数据和方法两个维度入手,就电力文本分类任务目前主要存在的困难展开分析和讨论,获得了以下结论:
2.1 分类数据缺乏
目前,已被应用于日常生产中的纷繁多样的文本分类方法的训练过程大多还是依赖于大规模的经过人工或半人工标签化处理的训练数据集,并且分类文本的训练数据体量与模型分类器的优劣程度呈正相关性。然而,电力工业安全作为国家安全的重要组成部分之一,电力企业对于文本数据的管理制度以及保密要求非常严格,所以造成公开披露的有效数据样本少之又少,而训练样本的匮乏恰恰是亟需解决的“瓶颈问题”,这为电力文本分类技术研究带来了巨大的挑战以及更高的要求。
2.2 电力文本特点
在经过了对相关的公开电力资料的收集、查阅、了解、分析和归纳后,我们发现相对于开放性领域的文本,属于垂直领域内的专业性电力文本具有其独有的行业文本专业性特征。
(1)电力专业性,电力文本涉及大量电力相关以及工程相关的专业性词汇,如果不进行模型训练或是词典扩充,那么大量的专业性词汇是无法被准确且无遗漏地识别并被表示为文本特征的。
(2)语言学弱显性,电力行业高效快速的行业特点,使得在电力文本书写阶段中,更多考虑内容传达准确性和有效性时,而相对忽略了语言学规则。因此在某些情况下,无法采用一些基于语法或是上下文的常规分类方法进行文本类型识别处理。
(3)电力文本形式多样性。电力企业内部信息传达过程中,为了实现快速且精准的信息交互,结构化数据与非结构化数据混合使用是电力文本的常见现象。这种无确定形式表达且缺乏机器可理解语言的现象为自动化文本特征抽取与分类提出了更高的要求。
(4)电力文本分类偏重性。电力设备的日志在电力文本中的占比较大。然而这类文本由于本身是由设备或者系统自动生成的原因造成缺陷性文本的数目庞大。比如文本中常常会出现设备编号确实、位置信息和时间空白等各类问题。在文本分类过程中,基于历史数据,模拟有效且仿真的关键特征数据,用于实现缺陷数据的补全和填白,也是文本分类任务中必须克服的困难。
(5)设备运行负载安全及成本。文本分类技术在电力行业的应用过程中必须按照电网工业生产和安全标准提出的要求,并且以绿色环保、可持续发展为行业要求,需要尽量减少能源消耗,二氧化碳排放量、生产成本。
3 联合特征分类方法
如何使用少量的计算资源、设备资源和存储资源实现快速准确的自动化文本分类。经过排序、过滤、筛选后的文本关键词常被考虑作为对文本进行分类的重要依据,即文本的类别特征。常规手段是将抽取得到的文本实体与在文本中实体出现的对应频率进行结合并存储,做降序排序后,筛选得到文本对应的关键词集合,并以此作为类别划分和识别的重要依据,从而实现文本分类目标。
在分析了大量的电力行业文本后,就电力企业中常涉及的业务多分类问题,计划以bag of words 词袋模型为基础,并且假设文本中任意词与词之间存在独立性。经过对比实验验证之后,将引入机器学习方法中的朴素贝叶斯和非线性核支持向量机(SVM)。朴素贝叶斯法根据条件概率分布进行了独立性假设,极大程度减少参数数量,即

其中,x(j)为样本x 的第j 个特征。
朴素贝叶斯法是基于样本类条件概率形成的学习模型。朴素贝叶斯分类器计算并排序所得的后验概率,并最大化求得的概率结果及其对应的所属类别。因此,分类学习模型可表示为:

由于上式分母的取值不依赖于样本的类属yj,上式经简化后为:

图1:分类词特征联合构建及文本分类流程
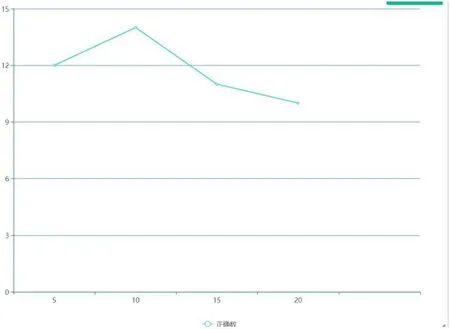
图2:模拟测试

非线性核的支持向量机则是通过核函数,将特征向量映射到更高维的空间中,使得原本线性不可分的数据经过映射后,在空间中实现线性可分。使用该方法,,旨在扩大特征显著性,将类别之间本不明显的特征清晰化,从而便于模型分类器判断文本的所属业务类型。假设原始向量为x,映射之后的向量为z,得到的映射为:

用核函数对两个特征向量的内积进行变换得到向量进行映射并做内积计算后:

4 分类词联合构建及分类算法
基于共有文本特征词跨类联合的电力文本分类算法主要分为电力文本分类数据库构建和文本分类两个阶段。电力文本分类数据库构建包含使用Jieba 分词器对数据集进行分词、统计各个类别的词频表、分类词汇去重、类别词交叉组合、获取前K 个特征关键词;文本分类包含原始文本数据分词、计算分类词频、文档分类。具体流程如图1 所示。
过程描述如下:第一步:使用jieba 分词工具对已标注类别的电力文本数据进行分词处理,实现词块划分。
第二步:对各个类别下的文本数据分别进行词频统计,并进行降序排序,每个类别得到对应的词频表,作为分类语料库。
第三步:去重。对第二步中各个类别下的分类语料库进行去重处理,减少重复词汇及其词频对后续工作的影响。
第四步:对各个类别的分类语料库进行跨类别横向遍历统计,并对所属多类别的词组进行重组和搭配,生成二元组或三元组搭配的关键词组。
第五步:筛选出分类语料库中前k%的关键词作为各个类别对应的类别特征,并以此作为电力文本分类的标准。
第六步:将所得重组后的类别语料库和经过训练的分类器应用于测试文本中,计第七步:根据在测试文本上的表现,计算测试文本词频表与类别语料库的命中率。并对类别语料库做校验和调整。
第八步:根据机器学习模型评估标准,计算并比较分类器在测试文本上的表现性。
上述流程整体可从两方面描述:
第一方面:电力文本分类数据库构建
遍历所有分类,使用jieba 分词工具对该类数据集进行分词,得到该类词频数据,剔除词语所属分类数为3 以上的词语。遍历分类词频数据,如果该词所属分类数量为1,则将其加入该分类所属语料库;如果该词所属分类数量为2,则往后搜寻同样分类数量的词语且分类交集为该分类的词语,将保存至对应分类语料库,并在其余分类语料库检索并删除该词。
第二方面:文档分词和分类
应用jieba 分词对测试文档做分词,获取测试词频数据。遍历词频数据,如果该词属于Sub 分类特征语料库,则增加Sub 分类命中率,统计各个分类命中率,选取命中率最大的分类为该文本分类。
5 模拟测试
分别选取已获得的词频表中的前5%、前10%、前15%、前20%的关键词进行筛选作为类别语料库,做横向对比测试验证,即对参数K 进行实验测试。实验结果表明,当K 选取5%的筛选值时,会导致类别特征数较低,在分类时大部分词语没有命中分类语料库导致正确数较低;当K 选取20%的筛选值时,词频表中绝大多数的词都会被收录到特征语料库。因此,在筛选分类时,可能会出现某一个类别的分类词特征较多的情况,而其余分类词频数较低的情况,由此会导致该特征明显词被误筛,从而影响特征语料库的整体质量,最后直接影响分类器的正确率。实验结果表明,K 选取10%平均值较好的权衡了各个步骤的影响,从而提高了预测准确性。模拟测试如图2 所示。
6 展望
针对电力文本的特点,虽然通过提出基于共有文本特征词跨类联合实现电力文本分类有效缓解了跨类共享分类特征词导致分类冲突的难题,但是必须进一步提高文本分类自动化、智能化和准确性程度。下一步,必须进一步提升电力文本分类的样本数量,尤其是增加文本特征词稀缺类别样本数量,减少各个文本类别分类特征词分布不均,完善和提升电力文本分类语料库。
猜你喜欢
园林科技(2021年3期)2022-01-19
校园英语·月末(2021年13期)2021-03-15
新校长(2016年8期)2016-01-10
读者·校园版(2015年7期)2015-05-14
深圳大学学报(理工版)(2015年5期)2015-02-28
商事法论集(2014年1期)2014-06-27
图书馆论坛(2014年8期)2014-03-11
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
外语学刊(2011年3期)2011-01-22
