
改进深度学习的车牌字符识别技术
2021-06-16 10:17郑祥盘王兆权宋国进
福州大学学报(自然科学版) 2021年3期
郑祥盘, 王兆权, 宋国进
(1. 闽江学院福建省先进运动控制重点实验室, 福建 福州 350108;2. 福州大学机械工程及自动化学院, 福建 福州 350108)
0 引言
随着经济的发展, 汽车逐渐普及到人们的日常工作生活当中. 根据公安部统计, 截至2019年全国汽车保有量约为2.6亿辆, 且呈现逐年剧增的趋势. 人们在享受车辆带来的交通出行便利时, 也面临着诸如车辆违法停放、 交通肇事逃逸、 车辆追踪等问题, 而这些都离不开对车牌字符的识别.
国内外学者对车牌识别技术进行了大量的研究. 文献[1]对低分辨率车牌图像提出应用模板匹配和光学字符识别方法, 通过扫描车牌区域检测出最大稳定极值区域来分割车牌中的字符区域, 实现96.2%的正确识别. 文献[2]为了减少光照的影响, 把RGB空间上的场景图像转化成HSV空间的3个分量值, 通过色彩空间变换等手段分别获得车牌区域和去除伪车牌区域, 定位成功率达到97.58%; 文献[3]提出基于深度定位和故障识别的无分割无标注车牌识别方法, 并通过实验解决重影、 非均匀光照等带噪声车牌图像识别问题. 文献[4]提出在HSV空间中使用最大类间方差算法来对车牌图像进行二值化, 然后结合特殊间隔位置和投影法来精确分割字符, 应用卷积神经网络算法实现对车牌字符识别率达97.8%, 解决低清晰度车牌字符的分割和识别问题; 针对远距离、 变光照的复杂应用场景, 文献[5]提出基于最大极值稳定区域和笔画宽度变换的车牌检测识别方法, 定位准确率达94. 86%, 识别准确率达96. 14%; 文献[6]提出深度卷积神经网络提取图像特征的方法解决传统人工提取特征难的问题, 自学习提取出目标对象的深层特征和可区分性特征, 加快目标检测的精度和效率.
近年来, 深度学习在计算机视觉、 语音处理以及医疗等领域得到广泛应用, 已成为计算机模式识别领域研究的热门, 利用深度学习算法可提升车牌识别的识别率, 对提升车牌识别系统的鲁棒性和效率具有重要的意义[7]. 为此, 在前人研究车牌识别方法基础上, 提出采用Haar级联检测结合深度学习算法的卷积神经网络(convolutional neural network, CNN)车牌字符识别方法, 即使在角度倾斜、 光照变化等环境条件下, 也能提高识别车牌字符的稳定性和准确性.
1 车牌识别的总体思路及识别算法
1.1 车牌识别流程

图1 车牌识别流程图Fig.1 Flow chart of license plate detection
应用Haar级联检测结合深度学习方法对车牌的识别方法流程如图1所示. 首先通过Jaar级联分类器锁定并提取出车牌的位置, 将车牌图像依次进行重新定义大小、 灰度化、 阈值化等预处理; 再经过腐蚀膨胀操作后, 通过轮廓分析提取车牌中的七个字符图像; 最后将获取到的字符信息传入经过大量数据训练后的CNN卷积网络中, 得到车牌字符检测的结果.
1.2 Haar级联检测车牌位置
利用车牌本身所具有矩形特性, 对待检图像中的子区域进行筛选, 提取出所要的车牌图像区域. Haar特征主要分为: 边缘特征、 线性特征、 中心特征和对角线特征. 在通过大量的数据集训练出的Haar模型中, 通过级联多类不同的基础特征, 能够很好地筛选出图像的目标区域[8]. 为此, 通过级联多个弱分类器能够极大地提升车牌边框区域的检索精度. 本研究通过收集2 000张只包含车牌区域的图像, 以及6 000张不包含车牌的图像建立Haar级联分类器的训练集. 将训练集中的车牌图像长宽重新定义为3∶1的比例大小, 以及定义检测窗口的最小长宽尺寸为8, 24 px. 经过16轮迭代, 生成Haar级联分类器模型. Haar级联分类器模型所寻找出的车牌位置效果如图2所示.

(a) 车牌图像一

(b) 车牌图像二

(c) 车牌图像三

(d) 车牌图像四
1.3 基于深度学习的字符提取
车牌图像预处理是提高车牌识别系统后续环节运算效率和识别精度的关键, 特别是对车牌字符定位和提取非常重要. 合理的图像预处理方法不仅能够提高图像对比度、 清除噪声, 还有助于去除多余干扰、 背景等信息[7-8]. 为了更便捷、 准确地提取车牌字符信息, 首先对车牌图像进行灰度处理操作, 以此降低像素差异及浮点运算对处理效率的影响; 接着利用图像中物体与背景之间的灰度差异, 对图像进行阈值化处理, 从图像中分割出所需要部分. 应用均值自适应的二值分割法对图像做阈值处理, 以此解决因光线问题所造成的图像亮度不均问题. 取边长为15矩形像素的平均像素值块作为图像的局部阈值, 通过遍历方式依次沿长宽方向对图像进行局部阈值化处理, 阈值化处理后的车牌图像如图3所示. 图中只有黑与白两种颜色像素, 方便后续的图像处理.

(a) 车牌一图像二值化

(b) 车牌二图像二值化

(c) 车牌三图像二值化

(d) 车牌四图像二值化
为了减少一些无关像素点对字符提取的干扰, 通过图像腐蚀去除车牌图像的外围边框. 通过卷积方式让卷积核在目标图像上进行滑移操作, 计算卷积核所覆盖的图像像素最小值, 并把这个最小值给指定的中心像素点, 车牌外围的边框区域在二值图像中显示为白色, 见图4中所示外围的一圈虚线, 为此定义一个宽度为1、 长度为3的卷积核. 应用下式及上述定义的卷积核可对图像进行卷积计算.

(1)
其中: (i,j)为原图像第i行、 第j列的像素.当卷积核中心点位于(i,j)位置时, 计算卷积核覆盖下图像像素的乘积及对应第i列j-1行、j+1行、j行三个像素的乘积.
由于虚线宽度在二值图像中所占的像素宽度很小, 而字符区域在二值图像中所对应的长度和宽度远大于车牌边框的宽度, 所以二值图像在经过一次腐蚀操作后可将车牌边框的白色区域去除, 去除车牌边框后的图像如图4所示.

(a) 车牌二值腐蚀图像一
(b) 车牌二值腐蚀图像二

(c) 车牌二值腐蚀图像三

(d) 车牌二值腐蚀图像四
经过腐蚀后的二值图像难免会丢失一些原有的像素信息. 为此, 在腐蚀操作后加上膨胀处理以便后期更好地找到字符图像信息. 此时, 定义一个长度为3、 宽度为3的卷积核, 令其在二值图像滑移的过程中, 计算卷积核所覆盖下像素的图像像素最大值, 并将其最大值赋值给中心像素点, 从而扩大二值图像中白色区域的大小. 应用下式计算出(i,j)像素及周围8个像素的和bi, j, 当bi, j大于0, 则bi, j等于255; 若bi, j等于0, 则bi, j等于0.

(2)
进一步通过指定轮廓面积、 轮廓弧长, 筛除干扰信息像素点, 将车牌字符用外接矩形框出, 处理结果如图5所示.

(a) 车牌一字符提取图像

(b) 车牌二字符提取图像

(c) 车牌三字符提取图像

(d) 车牌四字符提取图像
由于神经网络训练的样本预留了较大的背景信息, 为了保证后续输入图片格式的一致性, 在此约定字符外接矩形的长度应大于矩形宽度. 由于数字“1”外接矩形的高度要远大于宽度, 因此将“1”的外接矩形沿x轴向左移动高度的一半距离, 重新调整矩形宽度为高度的大小. 最后, 把7个字符信息大小定义为CNN卷积神经网络所要求的维度24 px×24 px.
1.4 CNN模型的搭建
数据集的数量与质量决定了后续建立的神经网络模型预测准确性. 为此, 在初始阶段数据集的准备显得尤为重要. 根据检测需求, 数据集包含了大陆31个省级行政区域的简称数据、 0到9的数字数据以及包含A到Z的字母数据. 每个独立字符视为一个样本, 每份样本都含有1 000张训练集图片. 将31个省级行政区域的字符数据集单独训练出一个神经网络模型用来测试车牌中的省级行政区域字符; 将10个数字和24字母一起训练成另一个神经网络模型, 用来测试车牌中的后6个字符. 把每份训练集的图片重新定义大小, 在省级行政区域神经网络中通过分别访问31个文件夹读取每张字符图片, 将训练图片转换成TFrecord格式, 在读取每张图片的同时, 将其对应的文件夹位置信息写入TFrecord格式的label列表中, 制作label信息.
图6为所搭建的CNN神经网络模型. 从图中可以看出, CNN网络包含2个卷积层C1与C2、 2个池化层P1与P2、 1个扁平层、 4个全连接层. 卷积层中包含多个滤波器, 卷积后采用relu激活函数增加卷积神经网络的非线性, 使模型能够更好地拟合数据, 可以更好地解决较为复杂的问题. 在池化层采用max-pooling操作来减小图像的特征维度. 通过扁平化操作, 将图像样本化为一维向量, 连接4个全连接层, 最后通过Softmax函数输出.

图6 CNN网络结构图Fig.6 Structure chart of CNN neural network
1.5 神经网络参数设计
1) 卷积核. 相比传统的神经网络, CNN卷积神经网络通过在传统神经网络的基础上增加卷积核来对图像进行特征提取, 以便达到更好的图像识别效果. 为此本研究采用指定大小的卷积核, 通过滑移指定步长的方式在原图进行卷积操作[9].

(3)
上式为卷积后图像维度的变化信息, 其中Ilength为输入图像的长宽大小,Olength为输出的图像大小,F为卷积核的大小,S为滑移的步长.
在C1层中, 采用3×3大小的单通道的卷积核, 滑移步长为1个大小的距离, 使用32个卷积核在24 px×24 px大小的图像上进行卷积, 得到的输出图像的维度信息为24 px×24 px×32 px. 在C2层中, 增加卷积核的数量到64个, 经过C2层后图像的输出维度变成12 px×12 px×64 px.
2) 激活函数. 在神经网络中, 激活函数的作用是能够给神经网络加入一些非线性因素, 使得神经网络可以更好地解决较为复杂的问题[10]. 常用的激活函数有sigmoid和relu两种, 两者比较, relu激活函数能够大幅提高运算效率; 另一方面在输入信号较强时, 仍然能够保留信号之间的差别. relu激活函数的表达式为:
f(x)=max{x,0}
(4)
其中:x为上层神经节点的输出, 保留卷积输出后大于0的值这样就造成网络的稀疏性, 并且减少参数的相互依存关系, 可缓解过拟合问题的发生. 将卷积后的值代入relu函数得到以下公式:
f(xw+b)=max{xw+b,0}
(5)
其中:w为卷积核的权重参数,b为偏置参数.
3) 池化层. 指定N×N滑移窗口, 通过滑移的方式求出该窗口在原图区域的平均值或最大值, 用来提取卷积后的特征值, 并降低数据的特征维度信息. 采用max-pooling的方式进行池化操作用来减小特征图像维度[11], 在经过P1、 P2层池化后, 图像维度大小变为12 px×12 px×32 px.
4) 全连接层操作.下式为全连接层的表达式, 其中yi为第i层神经网络的输出,wi, j为第i层第j个节点的权重参数,bi为偏置参数.

(6)
在神经网络结构图F1为全连接层, 其节点数为4 096个; F2、 F3、 F4层采用与F1层相同的激活函数, F2的节点数为4 096个; F3的节点数位2 068个; F4的节点数为31个, 表示省级行政区域字符数量. 在检测字母和数字字符卷积网络中输出节点的数量大小亦为31个.
5) Softmax函数输出. 把神经网络的输出变成概率分布, 从而可通过交叉熵来计算预测概率分布与真实类别概率分布之间的距离[12]. 但在此之前需要对数据进行归一化, 采用下式Softmax函数进行归一化.

(7)

将Softmax函数输出规划成概率分布式:
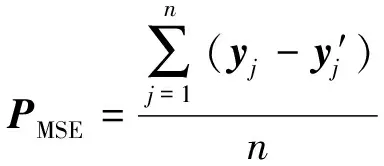
(8)

2 CNN神经网络测试实验
通过Window10平台, 借助Opencv库提取出车牌字符图片进行Python编程, 训练两个不同的神经网络来分别识别31个省级行政区域的车牌字符信息及字母、 数字信息. 将TFrecord数据集分批传入训练网络, 通过设置训练次数为1 000轮. 对每训练50轮所得到的网络参数进行测试, 保留测试准确率达到0.97的神经网络参数. 在所得到的多个神经网络模型中进行对比, 选取效果较好的模型做为车牌的检测模型.
把车牌图片输入到CNN网络模型中, 在不同的倾斜角度环境下得到对应的检测结果见图7所示. 系统成功识别了所输入的不同省级行政区域车牌图像, 在训练集中模型的识别准确率达到99%; 接着通过连续测试200张不同环境下的车辆图像, 其中能够被完全识别包括角度倾斜环境中的字符图像具有197张, 正确识别率达98.5%以上, 满足交通道路管理中的车辆违法停放等车牌识别的实际需求.
车辆行驶移动过程中, 车牌字符识别容易受到光照变化、 雨雾天气等影响. 为了验证上述算法在复杂环境下的检测效果, 设置60~90 lx光度环境变化的车牌识别结果, 见图8所示. 雨雾天气中分别为高度模糊、 中度模糊、 轻度模糊环境下的车牌识别, 结果见图9所示.
从图8~9的实验结果可看出, 与传统的识别方法如模板匹配、 图像直方图等比较[3-7], 本研究采用改进深度学习算法的识别方法能够解决数据预处理及字符提取阶段提取字符精度不够等问题, 具有更加有效的容错性和鲁棒性. 传统识别方法遇到车牌歪曲的情况, 其检测精度往往会大幅度降低, 为此在识别前需要进行矫正处理导致检测效率降低[5-8]. 在角度倾斜、 光照变化、 雨雾天气等复杂环境下的车牌识别实验中(图7~9), CNN神经网络算法只要在训练阶段数据的歪曲或模糊字符足够丰富, 即便在字符歪曲、 模糊等复杂条件下也能够被很好地迅速识别.
上述实验结果表明, 本研究的CNN神经网络算法能够降低目标漏检率, 该算法在不同的测试集上准确率和实时性都较高, 能够提高检测目标的精确率, 使得训练出来的模型对目标大小具有一定的鲁棒性; 该方法识别车牌字符正确率较高, 在光照变化和雨雾天气等复杂条件下的准确性和稳定性较好, 能够有效降低车标识别的错误率.

图7 角度倾斜环境的车牌测试结果Fig.7 License plate test results by angle tilt environment

图8 光线不足环境的车牌识别结果Fig.8 License plate test results by low light environment

图9 雨雾天气环境的车牌识别结果Fig.9 License plate test results by rainy and foggy weather
3 结语
针对传统车牌字符检测方法效率低、 准确性不够等问题, 提出一种基于改进深度学习的车牌字符图像识别方法. 采用Haar级联分类器提取图片中车牌的位置, 并应用图像预处理提取出车牌字符图像, 所提方法能有效地将车牌字符提取出来; 再通过收集字符数据, 对CNN神经网络进行训练, 使用训练后得到的模型对角度倾斜、 光照变化和雨雾天气等噪声污染车牌字符图片进行识别. 经过测试, 验证了该方法能够在角度倾斜、 光照变化等环境条件下有效降低车牌识别的错误率, 提高识别车牌字符的稳定性和鲁棒性.
猜你喜欢
核安全(2022年3期)2022-06-29
电子制作(2019年12期)2019-07-16
—— “T”级联
同位素(2019年1期)2019-03-14
电子产品世界(2018年1期)2018-09-21
新教育时代·教师版(2018年19期)2018-07-21
计算机技术与发展(2017年12期)2017-12-20
小猕猴智力画刊(2017年5期)2017-05-25
计算机应用(2016年10期)2017-05-12
电子制作(2017年22期)2017-02-02
系统工程与电子技术(2016年2期)2016-04-16
