
基于深度学习的仪表目标检测算法
2021-07-08 03:11孙顺远
仪表技术与传感器 2021年6期
孙顺远,杨 挺
(1.江南大学轻工过程先进控制教育部重点实验室,江苏无锡 214122;2.江南大学物联网工程学院,江苏无锡 214122)
0 引言
嵌入式仪表能够测量、计算各种物理参数。随着仪表的广泛使用,使得人工读数的成本不断增加。使用更高效的方式进行仪表检测成为新的研究热点,其中基于图像的仪表检测得到了广泛的关注。由于工业环境的复杂性,在雨、雾、强光等干扰严重的环境中使用传统的图像处理往往难以应对。而基于深度学习的目标检测算法通过训练极端环境下的图像,能够很好地解决此类问题。
针对仪表自动检测问题,国内外学者提出了多种检测策略。邢浩强等[1]通过构建9层卷积神经网络提取仪表特征以解决仪表目标的定位。徐发兵等[2]在YOLO9000[3]模型的基础上添加滤波器和批量标准化,并且对于锚框尺寸的选取采用k-means聚类的方式,加快包围框(Bounding box)的回归。司朋伟等[4]利用Faster RCNN[5]网络生成候选集,再将其中位于高置信度的目标区域经过筛选建立特征模板,实现对仪表类型的识别与定位。文献[6-7]利用形态学方式,增强目标区域特征以进行定位。
由于仪表体积普遍较小,在检测时往往会出现漏检的现象。因此,加强对于小目标的检测至关重要。YOLOv3[8]使用了复杂的DarkNet-53来提取特征,并且加入特征金字塔网络 (FPN),提升了小物体的检测精度。DSSD[9]利用反卷积来提取更多上下文信息。DSOD[10]中将基础网络由VGG-16变为DenseNet[11],使得模型可以从零开始训练并收敛。FSSD[12]借鉴了特征金字塔网络的思路,将网络较低层的特征引入到较高层当中,提升了小物体的检测精度。RSSD[13]中增加池化和反卷积,提升了特征金字塔中各个分支的通道数。
对于仪表读数识别问题,陈刚等[14]将数码字符切割后进行七段特征检测,以进行仪表数码的快速识别。刘晶[15]利用连通域的方式实现对图像区域的定位分割,采用OAO分类将其拓展到多分类以实现数字识别。
在仪表定位和类型判别中,为加快模型运行速度,提高算法准确率,不仅要降低计算量,还要改进优化策略。本文主要的改进如下:(1)将ResNet-50[16]作为基础网络,不仅降低了模型的大小和计算复杂度,而且可以充分提取图片的特征。(2)加入特征金字塔网络结构,将底层中的细节信息与高层中的语义信息进行结合。(3)使用GIoU[17](generalized intersection over union)作为评判预测框与真实框的距离指标,并将其作为损失函数,使得包围框(Bounding Box)的回归更高效。
在使用目标检测算法确定数字式仪表位置后,通过构建4层卷积神经网络提取数字特征。在数字识别时,先对仪表图像进行预处理,滤除表盘周围的文字和噪声,再对其进行二值化、轮廓检测、提取数字区域,最后利用网络读取示数。
1 仪表位置检测
1.1 SSD算法
SSD(single shot multibox detector)网络结构由基础网络VGG16增加6个卷积层和检测网络2部分组成,分别用于特征提取和多尺度的预测。网络结构如图1所示。
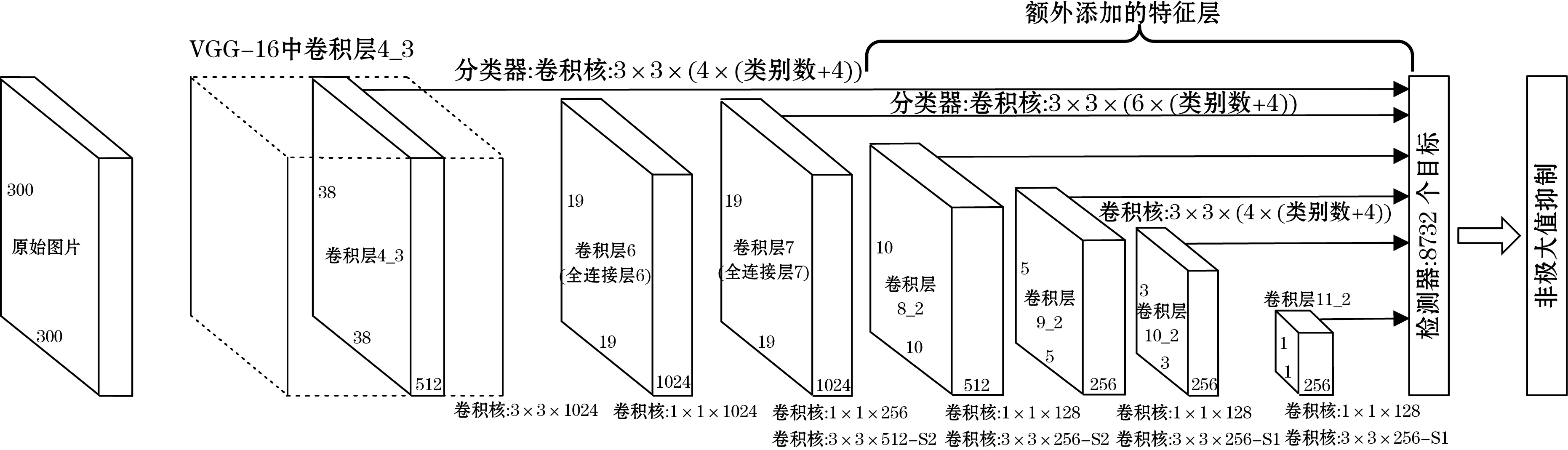
图1 SSD算法框架图
SSD中引入预选框(default box),抽取网络中的6张特征图,并以每个点为中心,生成一系列同心的预选框。再将中心点的坐标乘上步长,将其映射到原始图片。其中第1、5和6张特征图上生成4个预选框,其余特征图上生成6个预选框,一共生成8 732个预选框。
SSD的损失函数与其他目标检测算法相似,整个损失函数分为2部分:预选框与真实框的类别损失(confidence loss)以及定位损失(localization loss),公式如下所示:
(1)
式中:Lconf(x,c)为类别损失值;Lloc(x,l,g)为定位损失值;N指用于前景分类的默认框;α为定位损失占总损失值的权重。
在测试阶段,SSD网络预测出预选框的偏移量,通过解码求出预测框的位置。将置信度超过阈值的预测框筛选出来,并对其进行非极大值抑制(NMS),最终得出检测结果。
1.2 改进的SSD算法
1.2.1 基础网络改进
为了在不降低模型运行速率的前提下提高准确率,需要选择模型复杂度不高的基础网络。因此,在PyTorch框架下对VGGNet、GoogLeNet、ShuttleNet、MobileNet、Inception和ResNet进行测试,运行环境为NVIDIA GTX 1080,测试集为ImageNet2012,批量大小为32,结果如表1所示。
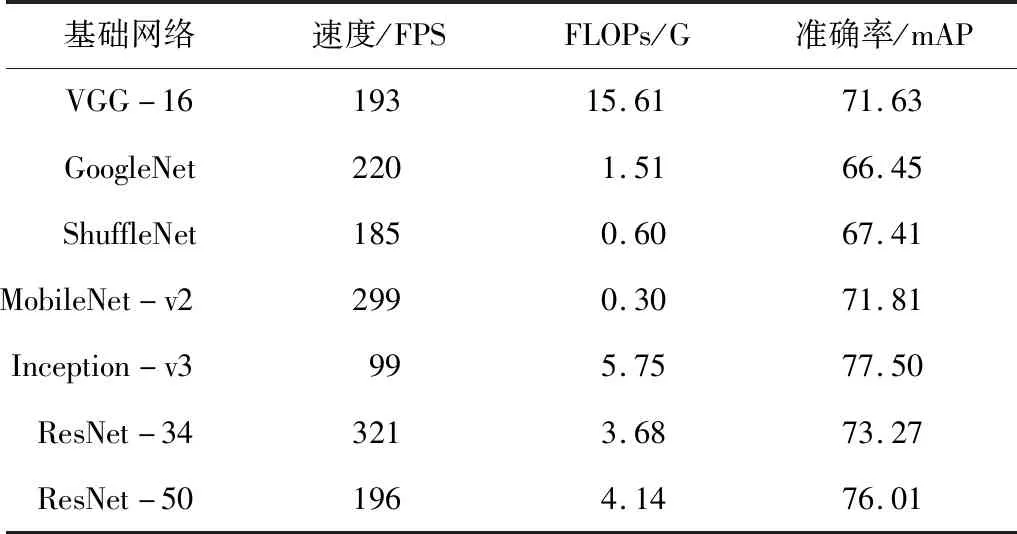
表1 分类网络在ImageNet2012下的对比
其中FLOPs代表了网络需要的浮点计算数,其数值越大代表着网络的复杂度越高,往往运行的速度会变慢,占用的内存变大。从表1中可知原本的基础网络VGG-16计算量大,精度不高,而GoogleNet、ShuffleNet 和MobileNet-v2 虽然计算量小了,但是精度没有提升。使用Inception-v3后,精度得到了提升,但是速度变慢很多。
最后,为了在保证速度的前提下,提高网络的精度,本文选取ResNet-50作为基础网络。
1.2.2 特征金字塔网络
对于卷积神经网络,不同深度对应不同层的语义信息。底层分辨率较高,感受视野小,学到的主要是细节信息,高层分辨率低,感受视野大,主要是语义信息。SSD算法虽然复用了不同层上的特征图,但是并没有将底层和高层的特征融合,这导致了极大的语义间隔,其网络结构如图2(a)所示。
特征金字塔原理:先从下采样中抽取一部分特征图,并对其进行上采样,构建自顶向下的通道,再将上采样的特征图与原特征图进行融合,最后利用融合的特征图进行预测,其网络结构如图2(b)所示。使用特征金字塔网络,将细节信息和语义信息进行融合,可以进一步提高分类和定位的准确率。

图2 特征提取方法的对比
1.2.3 定位损失函数改进
IoU是目标检测中的重要概念,在基于锚框的检测框架中,它不仅可以用来确定正负样本,而且可以用来判断预测框与真实框之间的距离。在SSD的位置回归任务中,判断预测框与真实框之间距离最恰当的指标就是IoU,但是采用Smooth L1 loss的回归损失函数却不适合,如图3所示,在Smooth L1 loss和Smooth L2 loss损失值相同的情况下,位置回归的效果却相差甚远。

图3 位置回归中不同评价指标的值
然而直接使用IoU作为损失函数会出现2个问题:(1)当预测框与真实框交集为0时,根据定义得IoU=0,此时梯度为0,无法回传训练。(2)IoU不能正确反映2个框是如何重叠的。如图4所示,此时IoU的值都是0.33,但是它们的回归效果是不一样的,左侧的效果最好,右侧的效果最差。
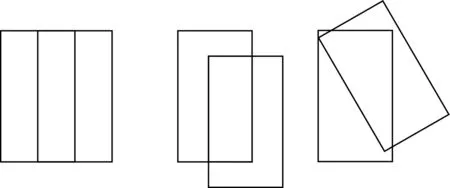
图4 相同IoU值下的回归效果
考虑到使用IoU作为损失函数导致的问题,本文采用GIoU作为指标。IoU和GIoU具体表达式如下:
(2)
GIoU=IoU-|C(A∪B)|/|C|
(3)
GIoU作为损失函数时,计算公式如下所示:
LGIoU=1-GIoU
(4)
式中:A为预测框的面积;B为真实框的面积;C为能同时包围2个框的最小区域的面积。
GIoU与IoU相比主要优势为:IoU的取值范围是[0,1],而GIoU取值范围为[-1,1]。当预测框与真实框重合的时候取到1,当两者之间不相交且距离无限远时取最小值-1。IoU只关注重叠区域,而GIoU不仅关注重叠区域,还关注其余非重叠区域,因此GIoU能够更好的衡量2个框之间距离。
2 数字仪表读数
在进行数字检测前,首先训练模型,训练集为0~9的图片共50张,像素均为28×28,部分数据集如图5所示,构建4层卷积网络如表2所示,最后经过2次全连接层,输出为10×1的向量。采用AdamOptimizer优化方法,一共迭代500次。
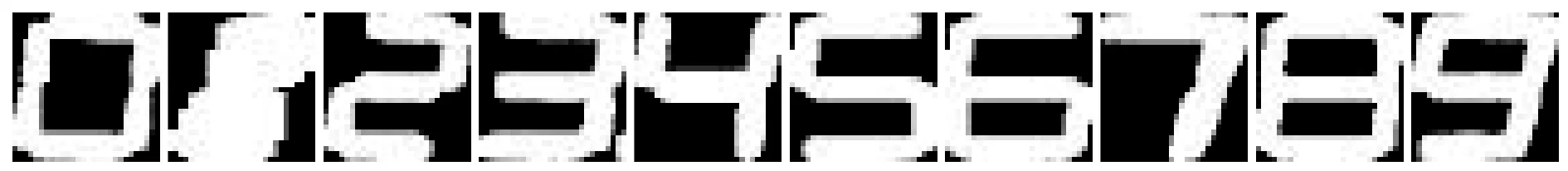
图5 训练集部分数据

表2 特征提取卷积层参数
训练结束后,对图像进行预处理。先将图像变为灰度图,再进行二值化,接着对其进行开运算,以消除数码管之间的间隙。最后加载权重读取仪表示数。运行结果如图6所示。

图6 数字仪表检测
3 实验结果分析
3.1 实验环境和数据集
本文实验在Ubuntu 16.04 LTS、CUDA10.0、cuDNN7.5、NVIDIA GeForce GTX 1080的系统下进行,深度学习框架是PyTorch 1.1.0,环境语言为python3.6。使用VOC数据格式对800张仪表图像进行标注并训练,在200张仪表图像上进行测试。使用小批量随机梯度下降(SGD)进行训练,动量设置为0.9,初始学习率为0.001,权重衰减率为0.000 5,最小批量是16。当迭代次数到达6 000、8 000、10 000时学习率降为先前的1/10,一共训练200个epoch。
3.2 实验结果与性能分析
在目标检测中,常使用平均精度(mAP)作为评价不同算法精度的指标。其主要由查准率和查全率组成,公式分别为:
(5)
(6)
式中:precision为模型预测为正例中真正例的比率,即预测的准确性;recall为所有正例中被正确预测出的比率;TP为真正例,指模型正确预测出物体;FP为假正例,指模型预测错误,预测出不存在的物体;FN为假反例,指模型漏检,没有预测出物体。
在一个类别中对预测结果排序,可以得到一条查准率-查全率(precision-recall)曲线,曲线下的面积即为AP值,对所有类别的AP值求平均,可得mAP值。实验结果如表3所示。

表3 不同算法在测试集下的结果
由表3可知,在分辨率为300×300情况下,改进后的SSD与改进前相比mAP提升了4.6%,运行速度也稍有提升。图7为使用改进SSD算法后在测试集上的检测图,在保证速度的前提下,能更精确的识别目标。

图7 仪表定位检测
在200张仪表图像中数字共有763个,利用本文算法对其进行数字检测,得到98.3%识别率,检测效果如图8所示。

图8 仪表读数
4 结束语
本文提出了基于SSD的改进算法,将基础网络由VGG-16变为ResNet50,在保证速度的前提下提取图片中更多特征信息。加入特征金字塔结构,将图片中的语义信息与细节信息进行融合,提高了模型对于小目标的检测精度。最后,引入GIoU这一评估指标,不仅关注预测框与真实框的重叠区域,还关注非重叠区域,使用GIoU Loss作为损失函数使得位置回归更加准确。在表盘数字检测中,利用卷积神经网络充分提取数字特征。实验结果表明,本文提出的算法在NVIDIA GeForce GTX 1080环境、仪表测试集上达到78.9 mAP,数字识别率达到98.3%,此算法检测效果好。后续将继续简化模型,提升算法的运行速度与检测精度,以应对更为复杂的场景。
猜你喜欢
建筑与预算(2022年5期)2022-06-09
建筑与预算(2022年2期)2022-03-08
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
汽车维护与修理(2016年10期)2016-07-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
