
三元肥料效应模型的整合与优化建模策略*
2021-07-22 11:46章明清张立成姚宝全
土壤学报 2021年3期
章明清,李 娟,张立成,姚宝全,张 华
(1. 福建省农业科学院土壤肥料研究所,福州 350013;2. 福建省农田建设与土壤肥料技术推广站,福州 350003)
二次多项式函数是当前常用的计量施肥理论模型[1-6],具有扎实的统计学理论基础和计算简便易行等优点。但在施肥实践中,二元、三元二次多项式肥效模型存在大量的非典型式[7-10],至今仍然困扰着计量施肥的研究和应用。近年的研究显示,二次多项式肥效模型及其他类似的多项式肥效模型存在设定偏误、多重共线性和异方差等问题[2],制约了普通最小二乘(OLS)的建模有效性。为此,针对二次多项式肥效模型设定偏误,作者构建了非结构肥效模型[11-12];针对三元二次多项式肥效模型的多重共线性和异方差危害,分别提出了主成分回归(PCR)[13]和可行广义最小二乘回归(FGLS)[14]的建模技术,显著提升了建模成功率。
迄今在三元肥效模型建模中,除了经典的二次多项式肥效模型OLS建模法外,还有PCR和FGLS建模法,以及三元非结构肥效模型及其非线性最小二乘(NLS)建模法等。那么,针对具体作物的肥效试验结果,该如何选择这些模型和建模法以达到最佳建模效果呢?作者在探讨PCR建模法时,曾发现“OLS建模法结合PCR建模法”的建模策略可使早稻的典型三元二次多项式肥效模型比例明显高于单独使用OLS回归或者PCR回归[13]的建模方法。本文在分析整合各三元肥效模型及其建模法的专业适用性基础上,提出优化建模策略,旨在尽可能提高典型式的比例和田间肥效试验结果的建模成功率。
1 材料与方法
1.1 水稻和露地蔬菜氮磷钾田间肥效试验资料的收集整理
近十年来,福建省完成了众多氮磷钾“3414”设计的田间肥效试验。在汇总这些试验资料时,仅收集整理土肥技术力量较强的或项目负责人有能力严格把关的相关县市完成的试验结果。在此基础上,根据“3414”试验设计中,氮、磷、钾各4个施肥水平及其试验产量分别绘图,若3个图形均大致呈现抛物线型关系,则保留该试验点资料,反之,则弃除该点试验资料。截止2017年底,共收集整理了水稻和露地蔬菜田间试验资料1 122个(表1)。供试土壤包括灰泥田、黄泥田、灰沙田、赤沙土等福建主要耕作土壤类型(土属),供试土壤主要理化性状(表2)采用常规方法测定[15],处理(6)的N2、P2、K2施肥量及其试验产量结果见表2。相关作物田间试验设计、土样采集和测定等,请参照文献[16]。

表1 福建水稻和露地蔬菜“3414”设计试验资料收集情况Table 1 Data collection of the field experiments in paddy fields and open vegetable gardens following the “3414” designing in Fujian Province

表2 水稻和蔬菜供试土壤主要理化性状及其处理(6)施肥量和产量Table 2 Main physical and chemical properties of the tested soils,fertilizer application rates and yields of the 6th treatment
1.2 三元肥效模型的整合
1.2.1 非结构肥效模型 近年的水稻盆栽和田间肥效试验均表明,施用单位养分的稻谷增产量与施肥量之间的关系是典型的指数函数关系[11]。在此基础上,作者构建了一元非结构肥效模型[11]:
式中,Y为作物产量,kg·hm-2;X为施肥量,kg·hm-2;s0为土壤供肥当量,以N、P2O5、K2O养分形态计量,kg·hm-2;c为施肥对产量的效应系数;A表示基础土壤对作物产量的生产能力。式(1)模型克服了一元二次多项式肥效模型的设定偏误以及一次项和二次项回归变量间高度线性相关的问题,具有更高的拟合精度。
在式(1)模型中,当施肥量和土壤供肥当量均为零时,作物产量必等于零。因此,根据植物营养元素功能不可相互替代的原理,三元非结构肥效模型可由三个一元非结构肥效模型相乘导出[12]:
式中,N0、P0、K0分别表示供试土壤的氮、磷、钾供肥当量,kg·hm-2;c1、c2、c3分别表示施用氮、磷、钾养分的增产效应系数;N、P、K分别表示N、P2O5、K2O施肥量,kg·hm-2;其他代数符号的含义与式(1)相同。
数学理论分析表明,式(1)和式(2)模型在一定施肥量范围内存在一个作物产量峰值,该峰值对应的施肥量即为最高产量施肥量。因此,根据微积分原理,令作物产量Y分别对氮、磷、钾施肥量的导数等于零,得到最高产量施肥量的计算式;令作物产量Y分别对氮、磷、钾施肥量的导数等于农产品和肥料价格倒数比,得到经济产量施肥量的计算式[11-12]。
式(1)和式(2)肥效模型均为非线性模型,而且不能直接进行线性化处理,模型参数估计需采用非线性最小二乘法[17]。假设非线性模型为Y=f(X,a),为求得参数a的估计值,可求解最小二乘问题:
其解ˆa作为参数a的估计值。非结构肥效模型的回归显著性检验与二次多项式肥效模型相似,但式(1)模型的回归自由度为2,式(2)模型的回归自由度为6。
1.2.2 多项式肥效模型 传统上,假设施用单位养分的增产量与施肥量之间满足线性关系,导出了一元二次多项式肥效模型[18]。根据数理统计学的线性加和性原理,进一步导出三元二次多项式肥效模型;有的学者根据研究需要,对二次多项式模型进行变形处理,形成了0.5次方和1.5次方多项式肥效模型[18]。显然,这种多项式肥效模型的导出过程,虽然具有统计学理论支持,但缺乏植物营养学专业理论依据。
同理,将三元非结构肥效模型的组成项e-cN-c2P-c3K转化为e-c1N×e-c2P×e-c3K。由于模型参数c1、c2、c3均在10-3级[12],取泰勒级数展开式的前两项,并忽略c1、c2、c3的两两乘积项以及c1c2c3乘积项和NPK三因子交互项等高次项,再令b0=AN0P0K0,b1=A(1-N0c1)P0K0,b2=A(1-P0c2)N0K0,b3=A(1-K0c3)N0P0,b4= -c1P0K0,b5=-c2N0K0,b6= -c3N0P0,b7=(1-N0c1)(1-P0c2)K0,b8=(1-N0c1)( 1-K0c3)P0,b9=(1-P0c2)(1-K0c3)N0。则式(2)模型可转化为:
这就是当前常用的三元二次多项式肥效模型,是三元非结构肥效模型的简化式。但是,这种经过简化导出的二次多项式肥效模型,导致最高施肥量之前和最高施肥量之后的施肥效应是对称关系,不符合生产实际。同时,导致强烈的多重共线性和异方差危害,制约了经典最小二乘法回归建模的有效性。
上述肥效模型整合过程可归纳为图1所示。显然,非结构肥效模型的导出过程具有较强的专业逻辑性,二次方、0.5和1.5次方多项式肥效模型导出过程的专业逻辑性较差。
1.2.3 三元肥效模型的典型性判别 肥效模型典型性涉及边际产量导数法推荐施肥的可靠性。由于农业生产条件的复杂性,根据田间肥效试验结果建立的肥效模型,方程效应曲线或曲面的形状多种多样[7]。在通过统计显著性检验的前提下,三元二次多项式肥效模型存在典型式和3种不同类型的非典型式[9]。若肥效模型同时满足:(1)一次项系数的代数符号为正数,二次项系数的代数符号为负数;(2)肥效模型存在全局最高产量点;(3)边际产量导数法得到的推荐施肥量均落在试验设计施肥量范围内,这种肥效模型符合植物营养学的一般肥效规律,称为典型式,可用边际产量导数法推荐施肥。反之,若3个条件中有任何一个条件不能满足,则分别称为肥效模型系数符号不合理的非典型式、肥效模型无最高产量点的非典型式和肥效模型推荐施肥量外推的非典型式,此时边际产量导数法推荐施肥结果不可靠。如何判断三元二次多项式肥效模型是否存在全局最高产量点?章明清等[9]总结提出了简易方法。
三元非结构肥效模型在通过统计显著性检验的前提下,也可能存在不同类型的模型。(1)若模型参数A、N0、P0、K0、c1、c2、c3均大于零,而且氮磷钾推荐施肥量均落在试验设计施肥量范围内,此类模型满足了植物营养学的一般肥效规律,称为典型式,可用边际产量导数法计算推荐施肥量;(2)若模型系数A、N0、P0、K0、c1、c2、c3有一个或一个以上的系数值为负数,该类模型称为系数符号不合理的非典型式;(3)若模型参数均大于零,但边际产量导数法的推荐施肥量有一个或一个以上落在试验设计施肥量范围外,该类模型称为推荐施肥量外推的非典型式。因非结构肥效模型的数学结构特点,若模型参数均大于零,模型必有全局最高产量点,因而三元非结构肥效模型不存在无最高产量点的非典型式这种类型。
1.3 三元肥效模型建模与推荐施肥量计算的计算机实现
有许多数学软件和统计分析软件均能进行肥效模型的参数估计和显著性检验,本文采用MATLAB R2015b软件进行相关的编程和计算。其中,三元非结构肥效模型的参数估计调用nlinfit功能函数;三元二次多项式肥效模型OLS建模法则调用regress功能函数;三元二次多项式肥效模型的PCR建模法是调用pca功能函数进行主成分分析,然后根据提取的主成分得分矩阵与各处理的试验产量,用regress功能函数进行回归建模;三元二次多项式肥效模型FGLS建模法则调用fgls功能函数进行模型参数估计和统计显著性检验。
上述4种建模法的具体数学原理、计算过程和MATLAB R2015b软件功能函数的使用方法可参阅相关专著[19-21]。
2 结 果
2.1 三元肥效模型不同建模法的拟合效果
针对1 122个水稻和露地蔬菜氮磷钾田间肥效试验结果,分别采用三元二次多项式肥效模型OLS、PCR[13]和FGLS[14]建模法对各个试验点进行回归分析。表3的统计结果表明,OLS建模法的三元典型式比例平均仅占试验点总数的19.8%,而PCR和FGLS建模法则分别提高至34.0%和27.1%。应用三元非结构肥效模型[12]及其NLS建模法,三元典型式平均比例达到试验点总数的41.4%,较三元二次多项式肥效模型的OLS、PCR和FGLS的建模法分别提高21.6、7.4、14.3个百分点。
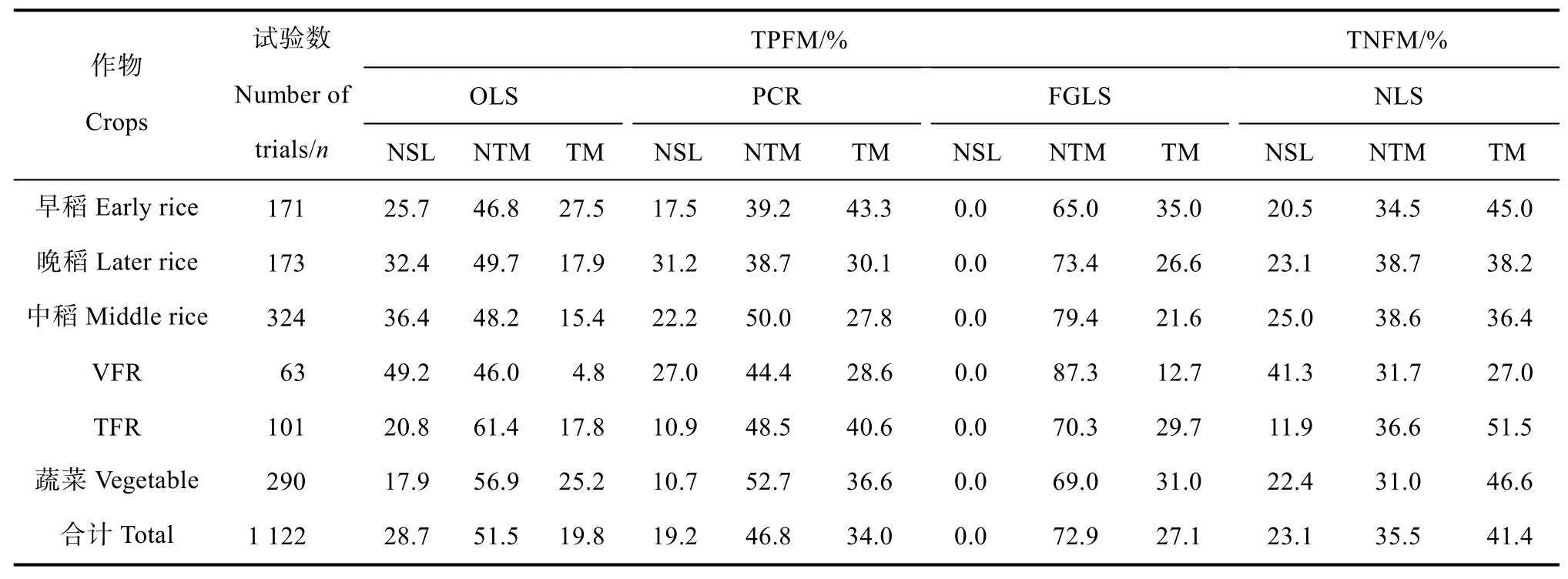
表3 水稻和蔬菜三元肥效模型不同建模法的拟合效果比较Table 3 Comparison of fitting between ternary fertilizer response models using different modeling methods for rice and vegetable
土壤肥力水平对典型三元肥效模型比例有重要影响。菜后稻是蔬菜地的轮作水稻,因土壤肥力水平普遍较高,OLS建模法的典型三元二次多项式肥效模型比例平均低至4.8%,即使采用PCR、FGLS建模法或非结构肥效模型,三元典型式比例也分别仅有28.6%、12.7%和27.0%。
统计结果还显示,二次多项式肥效模型OLS、PCR和FGLS建模法的无最高产量点非典型式的平均比例大致相当;然而,非结构肥效模型由于数学结构特点,无最高产量点的非典型式比例则为零。在未通过统计显著性检验、模型系数不合理、推荐施肥量外推等模型种类方面,不同模型建模法之间的平均比例则差异较大。PCR建模法使未通过显著性检验的模型比例从OLS建模法的28.7%下降至19.2%,而FGLS建模法则下降至零;PCR建模法使二次多项式肥效模型系数符号不合理的非典型式比例从OLS建模法的30.1%下降至16.4%,非结构肥效模型则进一步下降至4.6%,但FGLS建模法则提高至48.3%。PCR建模法使二次多项式肥效模型推荐施肥量外推的非典型式比例从OLS建模法的6.1%提高至14.4%,FGLS建模法则与OLS建模法相当,但非结构肥效模型推荐施肥量外推的非典型式比例平均达30.8%。
由此可见,二次多项式肥效模型经典建模法的成功率明显偏低,克服多重共线性或异方差危害的建模法均有利于提高典型式比例,而同时克服了模型设定偏误和多重共线性危害的非结构肥效模型则较大程度地提高了建模成功率。因此,不同三元肥效模型及其建模法的适用性有明显差别,合理选择肥效模型及其参数估计方法对提高建模成功率具有重要价值。
2.2 供肥当量参数N0、P0和K0与对照区产量的关系
在建模成功率较高的三元非结构肥效模型中,N0、P0和K0分别表示土壤N、P2O5、K2O的供肥当量。为考察模型参数估计值的可靠性,本文对能得到典型三元非结构肥效模型的试验点,根据水稻和露地蔬菜收获时的氮、磷、钾对照区产量,与对应试验点的N0、P0和K0估计值进行线性回归分析。表4的结果表明,除了土壤肥力水平较高的菜后稻的3个回归方程和烟后稻的磷素回归方程外,其他具有10个以上试验点的供试作物,N0、P0和K0估计值与对应作物对照区产量之间均有统计显著水平的线性正相关关系,显示N0、P0和K0估计值较好地反映了稻田和菜地土壤氮磷钾供肥潜力。因此,三元非结构肥效模型不仅具有较高的建模成功率,模型参数N0、P0和K0也具有较明确的物理意义。
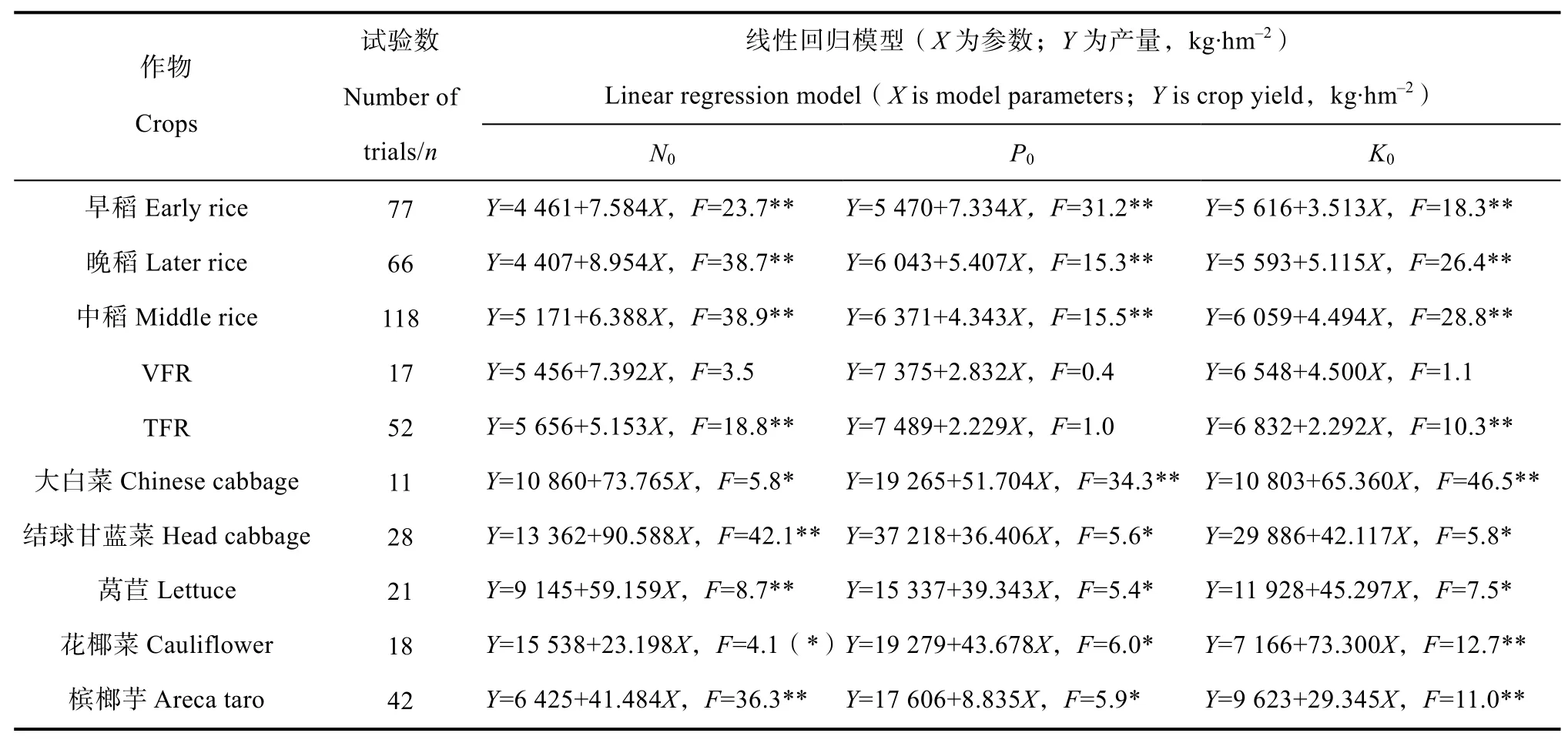
表4 非结构肥效模型参数N0、P0和K0与对照区作物产量的相关性Table 4 Correlation analysis of model parameters of N0,P0 and K0 with crop yields in CK
2.3 三元肥效模型的四步建模法
在上述建模和统计过程中,作者发现三元二次多项式肥效模型能得到典型式的某些试验点资料,并不能保证三元非结构肥效模型也一定能得到典型式,反之亦然。某些田间试验结果可能仅适用于4种建模法中的一种或者几种。从尽可能提高典型肥效模型比例的实用角度出发,考虑到非结构肥效模型具有较高的拟合精度、更宽的适用范围[11-12]和较高的建模成功率(表3),同时较好地克服了二次多项式肥效模型推荐施肥量偏高[1,22]的问题,故将非结构肥效模型作为数据拟合的第一步;OLS建模法是具有最佳统计性能的经典方法,因而将第一步建模不能得到典型式的所有试验点,采用三元二次多项式肥效模型OLS建模法作为数据拟合的第二步;因PCR和FGLS建模法均为有偏估计[20],PCR建模成功率高于FGLS建模法(表3),故将前两步不能得到典型式的余下试验点依次采用PCR和FGLS作为第三步和第四步的数据拟合技术依据。经过计算机多次反复试验比较,这种建模程序具有最佳的建模效果,简称为四步建模法,技术路线见图2。
表5 的拟合结果表明,在1 122个试验资料中,典型三元肥效模型占试验点总数的平均比例达到57.5%,较单独使用三元非结构肥效模型NLS建模法、三元二次多项式肥效模型OLS、PCR、FGLS建模法的典型式比例分别提高了16.1、37.7、23.5、30.4个百分点,大幅度提升了典型三元肥效模型比例和田间肥效试验建模成功率。分析还表明,除了供试土壤肥力普遍较高的菜后稻典型式比例较低外,四步建模法在双季稻、单季稻和露地蔬菜等作物间的典型式比例差异很小,显示该建模程序具有较好的可靠性。
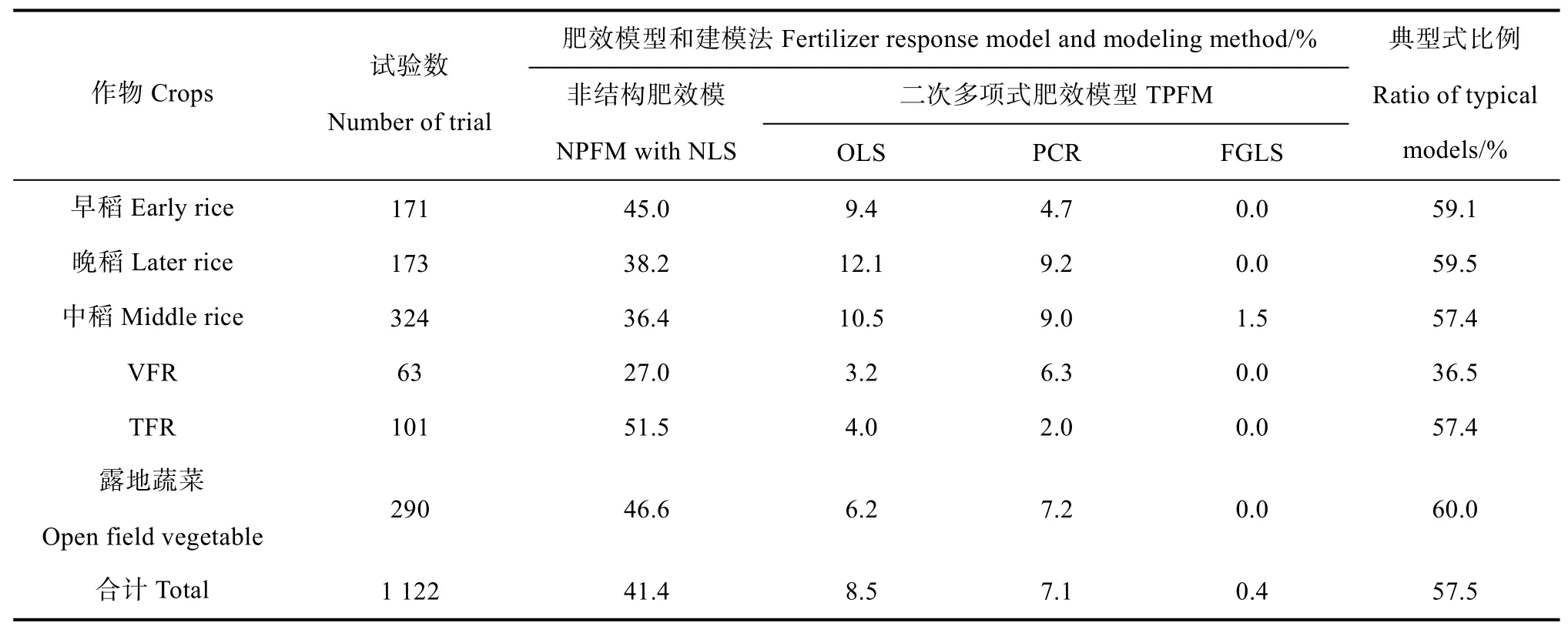
表5 四步建模法对水稻和露地蔬菜典型三元肥效模型比例的影响Table 5 Effect of the four-step modeling method on the proportion of typical ternary fertilizer response models for paddy fields and open vegetable gardens
3 讨 论
3.1 肥效模型不同建模法的适用性
1 122个水稻和露地蔬菜氮磷钾田间肥效试验资料,采用三元非结构肥效模型NLS建模法以及三元二次多项式肥效模型OLS、PCR和FGLS建模法,三元典型式比例平均分别为41.4%、19.8%、34.0%和27.1%,显示不同三元肥效模型及其建模法的建模成功率具有明显的差异。
经典回归分析的OLS建模法具有理想的统计性能,但合理使用必需满足10个基本假设条件[23]。在多项式肥效模型中,误差项方差为常数、自变量之间不存在线性相关和模型被正确设定等三个假设条件通常得不到满足,导致出现了异方差、多重共线性和模型设定偏误等问题,制约了OLS有效性和统计检验可靠性[2],成为当前二元、三元二次多项式肥效模型出现大量非典型式的主要技术原因。为提高建模精度和模型预测可靠性,PCR技术在土壤学中已得到普遍应用[24-26]。该法通过从试验设计矩阵中提取互不相关的主成分,利用主成分得分值和试验产量建立肥效模型,消除了多项式模型多重共线性危害,对提高肥效建模成功率具有重要作用[13]。FGLS建模法是消除异方差危害的有效方法,但在土壤学中的应用还较少[27]。在三元二次多项式肥效模型中,约有25%的肥效模型存在显著水平的异方差[14],导致建模结果发生异常。FGLS建模法是利用加权方法消除异方差,然后采用OLS法进行参数估计。因此,OLS建模法具有优良统计性能,但受到诸多假设条件限制;PCR和FGLS建模法分别单独克服多重共线性和异方差危害,且均属于有偏估计[20]。
事实上,三元二次多项式肥效模型同时存在模型设定偏误、多重共线性、异方差等问题,只有同时消除或缓解这些已知问题的危害,才能在较大程度上提高典型式比例。非结构肥效模型假设施用单位养分的增产量与施肥量之间满足指数函数关系,克服了模型设定偏误;该模型是非线性模型,且不能直接线性化处理,克服了多重共线性危害。非结构肥效模型同时较好地克服了多项式肥效模型的这些已知问题,是建模成功率得到较大提升(表3)的重要原因。
3.2 三元肥效模型的优化建模策略
在表3的建模过程中,作者发现某些田间试验结果要得到典型肥效模型,仅能适用上述4种建模法中的一种或者几种,其余的方法达不到预期目的,原因是作物产量具有随机性。三元二次多项式肥效模型和三元非结构肥效模型的数学形式不同,方程误差项对回归建模的影响程度不同。这种状况就可能出现三元二次多项式肥效模型能得到典型式的某些试验点,三元非结构肥效模型不能保证均得到典型式的结果,反之亦然。
可惜的是,什么样的试验资料会造成模型设定偏误或者多重共线性或者异方差对建模结果产生严重影响,目前在统计学上并无明确的答案[28]。考虑到农业生产条件的复杂性和多样性,反映到作物施肥效应曲线或曲面也必然具有多样性,期望通过一种模型或建模法来反映或概括这种多样性是不现实的。因此,多种肥效模型及其建模法的综合应用有其合理性。由于三元非结构肥效模型具有最高的建模成功率(表3),OLS建模法具有优良的统计性能,PCR和FGLS能分别消除多重共线性和异方差危害。因此,从得到尽可能高的典型式比例的实用角度出发,多种模型或建模法综合应用的四步建模法是一种现实可行的建模策略。根据该建模策略得到的推荐施肥量,在已完成的234个水稻和14个露地蔬菜大田示范中[29-30],与习惯施肥相比,不同稻作间平均增产稻谷4.0%~12.5%,净增收为875~2 616 yuan·hm-2;不同蔬菜种类间平均增产6.8%~10.6%,净增收达692~3 834 yuan·hm-2。结果显示,四步建模法得到的推荐施肥量具有较好的可靠性。
3.3 计量施肥模型构建的若干思考
肥效模型是实现计量施肥的主要技术手段。但在模型构建研究中,普遍存在一个认识误区,即:施肥模型应包含尽可能多的变量,除施肥量外,还应包括气候条件、土壤条件、作物品种、田间管理措施等,否则模型就不完善。实际上,计量模型考虑的变量过多,必然导致各变量之间提供的信息出现重叠,造成计量不准或出现异常,就如统计学上的多重共线性等问题一样。影响施肥量的各种因素间大多数情况下是非线性关系,如何削弱或消除这种变量信息重叠对计量准确性的影响,目前尚无成熟和方便的方法可用。同时,作为研究对象的农作物具有生命特征,施肥量或其他变量与产量的关系是满足统计学规律的随机关系,既使将上述变量因子全部考虑进去也不可能变为确定性关系。可以说,产生上述认识误区的根源在于,研究者大多习惯于用确定性关系的经典思维模式来考虑和评价具有随机性质的施肥模型,而对现代统计思维模式的应用尚重视不够。
作者认为,计量施肥模型至少可分为计量施肥基础理论模型和区域推荐施肥应用模型两个层次,前者是后者的基础。基础理论模型的研究重点应在于探讨如何建立普遍适用的作物施肥效应模型,甚至包括养分损失的施肥效应模型。这种模型应该简洁美观,既要满足专业要求,又要符合统计学理论,就像理论生态学的逻辑斯蒂(Logistic)模型一样[31]。因此,考虑的变量指标仅需要抓住那些具有共性特点的因子就可以了,例如,施肥量和土壤肥力等变量因子。
区域推荐施肥应用模型应在基础理论模型的基础上,结合服务区域的农业生产条件和区域特点,构建适合当地生产实际的区域推荐施肥系统。由于考虑变量太多会造成难以对模型进行精确的参数估计和施肥计量的问题,区域推荐施肥模型宜采用分区模式。例如,当区域小至县域甚至村域,因为降水量、气温和作物管理水平等变量在区域内很可能无显著差异,在构建区域推荐施肥模型时就可以不考虑了。因此,既使在应用层面上,评价区域推荐施肥模型的合理性和可靠性,关键也在于该计量模型是否抓住了服务区域内具有显著水平差异的那些变量,并将这些变量纳入考虑中,而不是全部变量。
基于上述思考,三元非结构肥效模型和三元二次多项式肥效模型均应属于计量施肥的基础理论模型范畴,可为区域推荐施肥提供基础模型依据;三元非结构肥效模型的土壤供肥当量参数N0、P0、K0,与相应氮、磷、钾对照区作物产量具有显著水平的线性正相关(表4),为将“测土”与肥效模型紧密结合提供了一条可能途径。
4 结 论
非结构肥效模型具有较强的专业逻辑性,其简化式即为二次多项式肥效模型。四步建模法是提高典型三元肥效模型比例的优化建模策略。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
现代农村科技(2022年9期)2022-08-16
现代农业(2022年3期)2022-07-05
广西植物(2021年1期)2021-03-24
科学与财富(2021年3期)2021-03-08
现代临床医学(2021年1期)2021-01-26
科学与财富(2020年33期)2020-03-10
中学生数理化·中考版(2019年11期)2019-09-10
农民致富之友(2019年4期)2019-03-13
现代商贸工业(2019年5期)2019-02-18
