
基于WGAN的音频关键词识别研究
2021-08-27 06:42李全兵田艳梅詹茂豪余秦勇
计算机技术与发展 2021年8期
李全兵,文 钊,田艳梅,詹茂豪,余秦勇,杨 辉
(1.中国电子科技网络信息安全有限公司,四川 成都 610041;2.提升政府治理能力大数据应用技术国家工程实验室,贵州 贵阳 550022;3.中电科大数据研究院有限公司,贵州 贵阳 550022;4.电子科技大学 信息与软件工程学院,四川 成都 610054)
0 引 言
随着互联网技术的发展,语音逐渐成为人们在日常共享信息和交流的主要方式,例如在QQ、微信等社交网站上与朋友聊天,以前人们以文字、图片来传递信息,如今主要通过语音和视频来交流信息,这样既方便又快捷。语音关键词检测(spoken keyword detection,SKD)是指从连续语音流中识别或检测出一个或多个特定关键词。迄今为止,已有大量文献对语音关键词识别做了研究,总的来说语音关键词识别方法主要分为以下几种:
(1)基于模板匹配的关键词识别[1]。该方法的思想是通过比对模板特征与待识别语音特征的相似性来实现关键词识别。query-by-example(QBE)是模板匹配中主要的检测技术,利用滑动匹配的思想检测关键词。模板特征可用高斯混合模型、隐马尔可夫模型、人工神经网络、梅尔频率系数和线性预测系数等表示。Zhang Y等人用高斯后验概率作为模板特征,并结合动态时间规整算法(dynamic time wrapping,DTW)的变体segmental DTW实现语音关键词的检出[2]。文献[3-4]结合self-organizing map和高斯后验概率特征,利用sub-sequence DTW实现关键词的检测。Dhananjay等人[5]利用CNN强大的特征提取能力,将CNN引用到模板匹配算法中,使得准确率有了显著提升。由文献[6]可知,DTW算法的时间和空间复杂度均为O(n2),因此n的长度不能太长,也就是在连续语音中使用此方法,识别速度也相对较慢。
(2)基于大词汇量连续语音识别(large vocabulary continuous speech recognition,LVCSR)[7]的关键词识别方法。这种需要将语音信号解码成词序列或音素网格[8-9],然后在此基础上搜索关键词,搜索方法有两种:基于混淆网络(confusion network,CN)和基于状态转换器(finite state transducer,FST)。在文献[10]中,Chiu等人提出将FST和CN组合在一起进行关键词检测,实验表明组合后的搜索方法优于任何单一的搜索策略[9]。针对集外词(out of vocabulary,OOV)[11]问题,Chen等人利用G2P(grapheme-to-phoneme)方法和代理关键词的概念有效地解决了OOV问题[12]。在文献[13]中,侯一民等人介绍了几种具有代表性的深度学习模型,并对其在语音识别中的应用进行了简单的说明。语音识别的声学模型除了可以使用DNN-HMM模型外[14],还可以使用其他的神经网络,比如循环神经网络(recurrent neural network,RNN)[15]和DNN-RNN[16]。文献[17]中,作者将自编码器深度学习神经网络应用于语音识别中,实现了语音孤立词的识别。文献[18]中,针对低资源情形下,语音识别系统性能不佳的问题,提出了一种基于i-vector特征的LSTM递归神经网络语音识别系统。
(3)端到端的语音关键词识别。基于端到端的关键词检测系统通常包括三个部分:特征提取模块、神经网络模块和输出后验得分的计算模块[19-21]。在识别阶段,关键词检测系统首先提取语音特征,之后将特征送入训练好的神经网络模型中,输出各个关键词和非关键词的后验概率,最后对后验概率以一定的窗长进行平滑,平滑后的后验得分如果超过预先设定的阈值或者选取平滑后多个关键词中最大的后验得分,就认为识别出了某个关键词。这种基于端到端的关键词检测系统,主要应用于语音唤醒任务中,在连续语音中不适用。
启发于端到端的语音关键词识别,该文将生成式对抗网络应用于连续语音关键词识别中,特定为小众且无文字的语言设计一种基于音频的关键词识别方法,并为GAN设计一个定位关键词的目标函数,以此追踪定位出关键词的具体位置。
1 生成式对抗网络简介
1.1 原始对抗网络
生成式对抗网络(GAN)是Goodfellow等[22]在2014年提出的一种生成式模型,其优化过程是一个极小极大博弈(minimax game)问题,优化目标是达到纳什均衡[23],得到全局最优解。GAN由一个生成器G和一个判别器D构成,G获取真实样本数据的概率分布生成新的数据,D作为分类器,对输入数据进行分类。
目前,GAN被广泛应用到图像和视觉领域,已经可以生成数字、人脸,构成各种逼真的室内外场景,根据轮廓图恢复图像,从低分辨率图像生成高分辨率图像等[24],GAN也已经开始被应用到语音和自然语言处理[25-26]问题的研究中。
GAN的判别器的损失函数如公式(1)所示:
LD=Ex[log(D(x))]+Ez[log(1-D(G(z)))]
(1)
生成器的损失函数表达式如公式(2)所示:
LG=Ez[log(1-D(G(z)))]
(2)
1.2 Wasserstein对抗网络
Arjovsky等[27]从理论上阐述了原始GAN存在训练不稳定、梯度消失等问题。由于Wasserstein距离相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题,可以提供有意义的梯度。因此,Arjovsky等人用Wasserstein距离代替原始GAN目标函数中的KL散度、JS散度。WGAN的目标函数由Wasserstein距离产生,Wasserstein距离定义如式(3)所示:
(3)

LWG=-Ex~pg[fw(x)]
(4)
判别器的损失函数如式(5)所示:
LWD=Ex~pg[fw(x)]-Ex~pr[fw(x)]
(5)
式(4)和式(5)中的fw(x)表示判别器。
经过生成式对抗网络的简单介绍,在语音关键词识别任务中,该文采用WGAN来实现关键词的识别。
2 WGAN识别关键词的基本思想和方法
由于端到端的关键词识别算法包括特征提取模块、神经网络模块和输出后验得分的计算模块,因此,该文使用WGAN识别语音关键词也由三个模块组成,即:特征提取模块、WGAN神经网络模块和关键词识别模块,基本思想如图1所示。
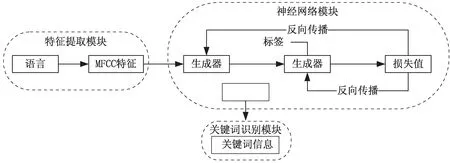
图1 WGAN识别关键词过程
在识别阶段,首先提取语音特征,之后将特征送入训练好的WGAN模型中,输出经过处理后的各个帧属于关键词特征的后验概率,最后依据生成序列分析语音中是否存在关键词。
特征提取模块,该文使用梅尔频率系数作为语音信号的特征,主要从定位损失函数、模型训练和关键词识别等方面来介绍WGAN识别关键词的基本思想和方法。
2.1 定位损失函数
由于所设计的方法需要获取关键词的位置信息,因此需要为WGAN制定一个目标定位损失函数。在这之前需要了解标签和生成序列这两个名称。文中的标签是按照以下步骤制作的:

(2)将关键词区间对应的帧全记为1,表示该区域存在关键词特征,其余区间的帧记为0,最终得到大小为1×M的标签。
(3)由于语音信号时长T大小不一,使得M也不同,最终导致标签大小不一致。为了解决这个问题,获取所有语音的标签,从中选出最长的标签作为标杆,将其余标签序列的末尾填充0至与标杆一致。
生成序列是WGAN的生成器G输出的序列经过以下步骤处理得到的:
(1)假设G的输出值为y={y1,y2,…,yM},其中yi表示第i帧特征是关键词特征的概率。
(2)若yi≥0.5时,则yi置为1,否则将yi置为0,这样就得到了只有值为0和1且大小为1×M的生成序列。
为了更形象地描述标签和生成序列,如有以下生成序列:{000000011111101010110000},则标签序列为{000001111111111100000000},可以看出标签中包含关键词特征的帧区间全部为1,不含关键词的区间全为0。在生成序列中关键词所在区域,除了1之外,还有少数的0,因此为了使得生成序列更加真实,该文为G定义了一个定位损失函数,如下:
(6)
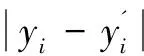
综上,在语音关键词识别任务中WGAN的G的损失函数如式(7)所示:
(7)
由于判别器D的作用仍是分类,所以在语音关键词检测任务中,D的损失函数不变。
2.2 模型训练
音频关键词识别算法中,生成式对抗网络的G和D的结构与LeNet[28]类似,在语音关键词识别任务中,WGAN的G有10个卷积层,用以充分获取关键词特征,G的结构与LeNet最大的区别是前者不含全连接层和Sigmoid层,G经过最后一层卷积层的输出值是大小为1×M矩阵,在将其传入D之前需要做一个简单的变换,即使其变成大小不变的向量。D包含7个卷积层、3个全连接层,不包含Sigmoid层。文中每层卷积层经过了卷积、池化、BatchNorm、ReLu和Dropout操作。
WGAN的训练过程如图2所示。
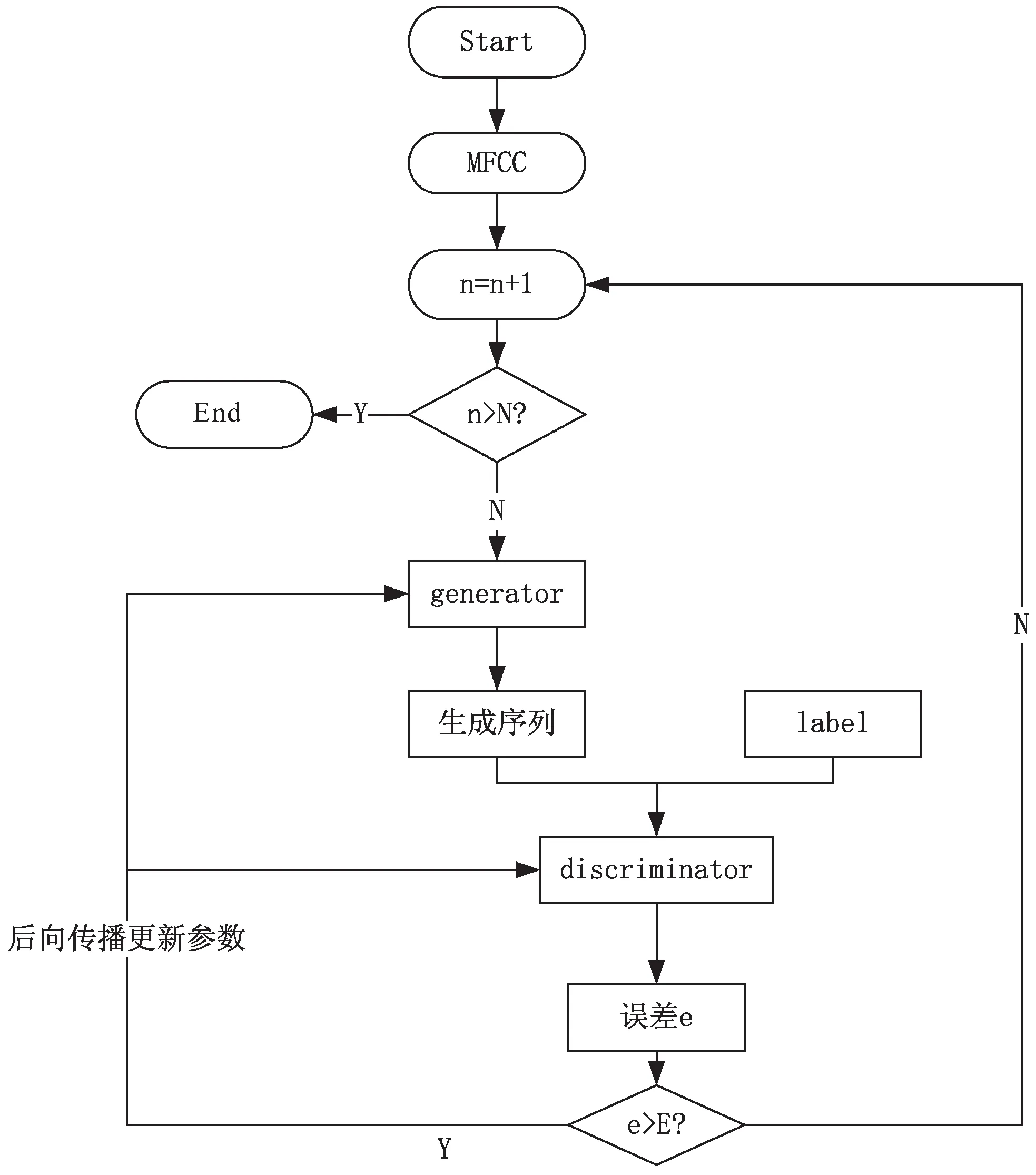
图2 音频关键词识别训练流程
训练模型的时候需要预先设置网络训练步数N,若训练步数达到N则训练结束,否则继续训练。在训练网络的过程中,通过前向传播获得误差并判断误差是否小于阈值E,若误差超过阈值则依据误差反向传播更新G和D的参数,直至误差小于E后进行下一步训练。由于一个良好的D不仅可以监督G生成效果更好的生成序列,还能加快模型的训练速度。因此在训练WGAN时,一般先训练D,当D的参数更新若干次之后,将D的参数固定,之后才开始训练G。G和D的参数更新通过反向传播算法实现。
2.3 关键词识别
基于音频的关键词识别算法的模型训练好之后,就可检测音频中是否存在关键词,若生成序列中有连续的若干个值为1(如:{0000011111100000000100101}),则定义它为一个连通区域为{111111}。
若生成序列中存在连通区域,还不能判断语音中有关键词,此时还需要判断连通区域的长度是否超过阈值Th。若生成序列中存在连通区域长度大于Th的情况,则视为语音中是存在关键词的,否则认定语音中不存在关键词。假设生成序列为y={y1,…,yi,…,yj,…,yM},其中y1~yi-1的值为0,yi~yj的值为1,且j-i≥Th,yj+1~yM的值为0,根据生成序列与音频之间的对应关系,把连通区域映射到音频,从而得到关键词在语音中的定位结果,关键词在语音中的确切位置如公式(8)所示:
(8)
对于阈值Th的大小要依据关键词的情况而定,比如设定的关键词语音平均持续时长为1秒,那么阈值Th应设置在4~10这个范围内(因为1秒的音频数据可生成大约10帧长度为22维的特征)。若语音信号的语速较快,则阈值Th的值可设置一个较小的值(0~4之间的任意一个值),否则Th的值应大于4。
3 数据集及环境配置
3.1 数据集
文中自行建立了语料库,所包含的语言有普通话、四川话和粤语。共设定10个中文关键词,分别为:一带一路、互联网时代、民族尊严、一国两制、人民代表大会、国家主席、中华人民共和国、体制改革、环境治理、自然灾害。语音来源包括录音及网络广播两种方式。在安静环境下录音,拟定包含关键词的语句内容,每个关键词涉及的语句内容有10条,分别用普通话、四川话和粤语朗诵若干次。参与录音的人数为30人,其中男生20人,女生10人,年龄分布均在18岁到26岁之间,这50个志愿者均会四川话和粤语。从网络上下载的广播,有的片段有关键词,有的片段没有关键词,两者之间的比例为8∶2。
根据上述方法得到语音的均为WAV格式,单声道,采样频率16 kHz。文中设置的每个关键词发音时长平均在1~2秒内,含关键词语音(句子)长度均为5~15秒。语音中含有普通话、四川话和粤语三种关键词语音文件。普通话、四川话和粤语分别包含5 600条人工采集数据和4 400条网络语音数据作为训练集,各类别的方言语音分别使用400条人工采集数据和200条网络语音数据作为测试集。
这些关键词都是一些名词。在获得音频之后,根据2.1小节中的标签制作方法制作标签,并以与音频对应的名称单独保存在一个文件夹内。
3.2 实验环境配置
文中使用Python的深度学习库Tensorflow编程实现WGAN,经过一系列实验,WGAN的一些超参数设置如下:学习速率为0.000 3,Dropout正则化的保留概率keep-prob设置为0.5,优化算法使用RMSProb。实验的硬件配置为:Intel core CPU @ 2.6 GHz+Nvidia GeForce GTX 1080 Ti (11 GB) 以及32 GB RAM,软件环境为:Ubuntu 16.04及Python3.5.0。
4 实验与结果
4.1 评价指标
文中采用准确率、召回率、错误接受率和错误拒绝率[29]作为评估关键词识别的性能指标。TP表示本属于正例的样本被正确预测为正例的样本数,FN表示正例被错误判别为负例的样本数,TN表示负例被正确判断为负例的样本数,FP表示负例被错误判断为正例的样本数。
准确率,衡量某一检索任务判断正确的概率,其定义如公式(9)所示:
(9)
召回率,表示所有正例中被判断为正例的概率,其定义如式(10)所示:
(10)
错误接受率,表示不包含关键词的样本中,错误检测出有关键词样本所占比例,其定义如公式(11)所示:
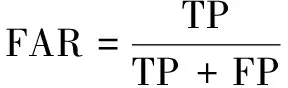
(11)
错误拒绝率,表示在有关键词的语音样本中,没有检测到管检测的语音样本所占比例,其表达式如公式(12)所示:
(12)
4.2 实验结果评估
WGAN模型在自制的语料库上进行训练。图3展示了G和D的损失值随着训练步数的变化情况,图中是每隔50步统计一次数据得到的值。
分析图3知道,WGAN模型的生成器大概在2.5w步时得到了收敛,继续训练生成器,它的损失值有所波动,但不影响总体变化趋势。判别器直到3w步左右收敛,继续训练网络损失值也无明显变化,因此文中将训练到3w步时得到的模型作为最优模型。
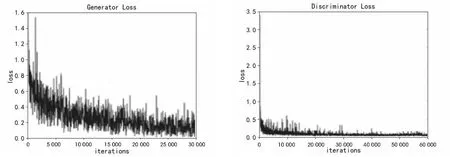
(a)生成器损失值变化情况 (b)判别器损失值变化情况
为了设置合适的阈值Th,观察Th的值在0~10之间,模型识别关键词的准确率的变化情况,在普通话这个数据集上的实验结果如图4所示。
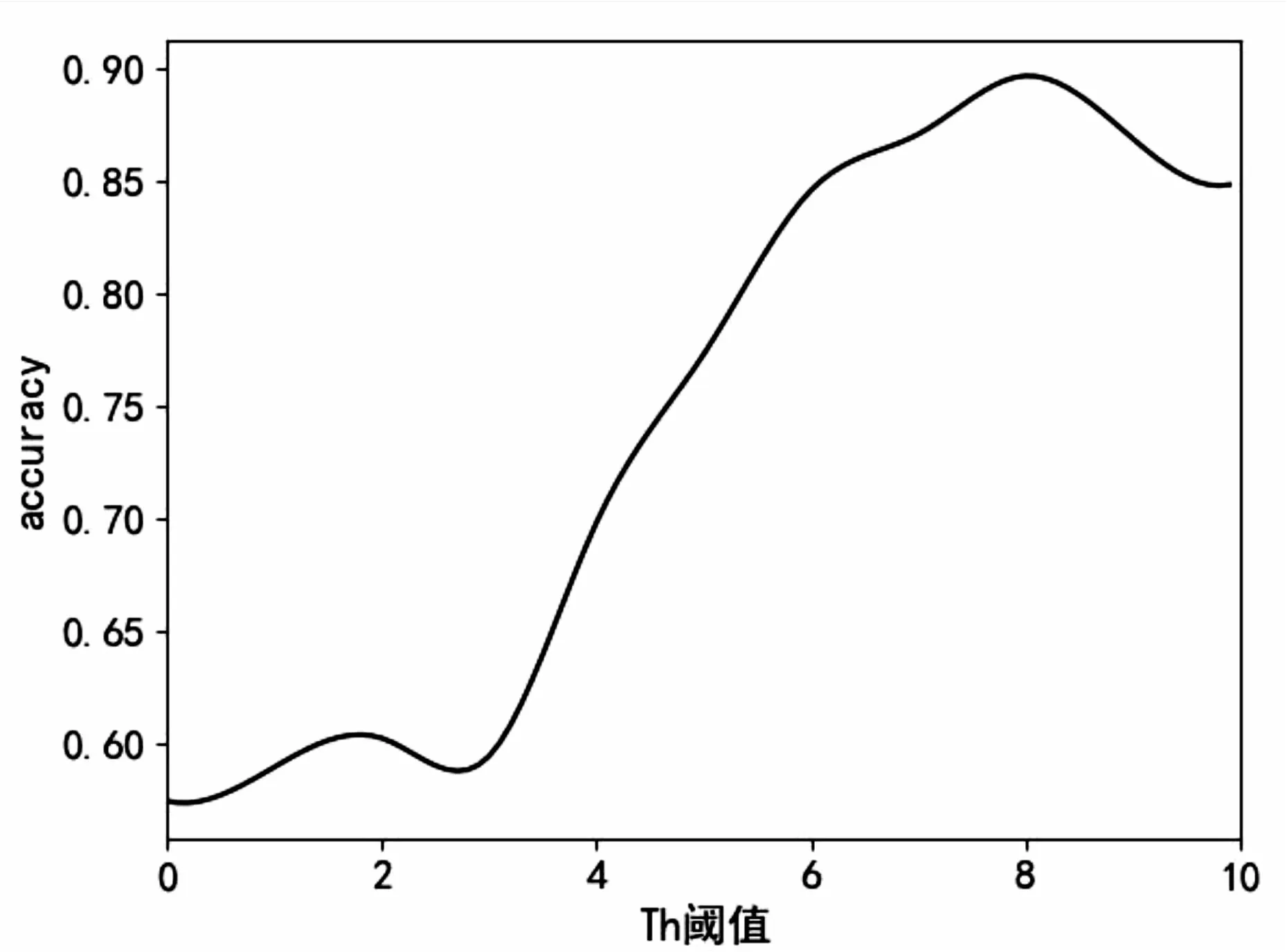
图4 准确率与Th值之间的关系
从图4分析可知,当Th的值设置过低时(0~4),准确率低于0.7,当Th的值逐渐增加时,accuracy也在逐渐上升,直到Th的值为8时达到了顶点,Th再继续增大,准确率反而降低。因此,文中将连通区域的阈值Th设置为8。
此模型是用普通话、四川话和粤语三种语言的音频训练得到的,因此,它在这三种语言的测试集上进行验证,其结果如表1所示。
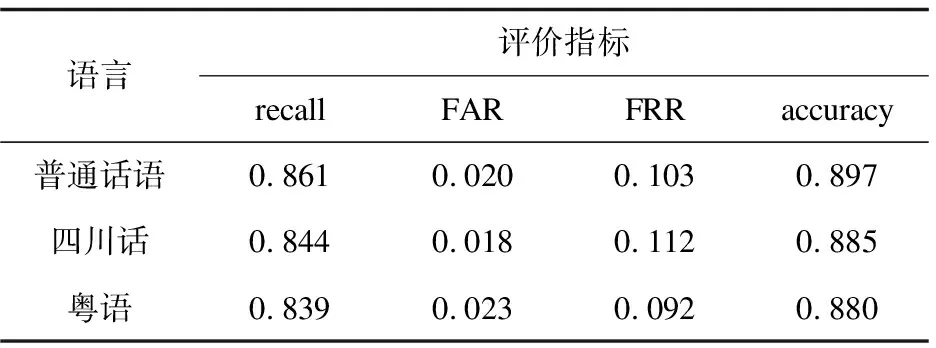
表1 三种语言的测试结果
根据表1的结果表明,WGAN可以识别四川话和粤语这两种方言,并且识别准确率和召回率均到达了80%,说明WGAN是有能力识别连续语音中的关键词的,并且可以识别四川话和粤语这两门方言中是否存在关键词。
此外,文中还提到WGAN模型可以准确获取关键词的时间信息,因此,含关键词的语句内容为“随着社会的快速发展,我国已进入了互联网时代”,其中“互联网时代”为关键词,WGAN检测该段语句内容的语音得到的结果为:关键词在音频中开始出现时间和结束时间分别为8.5秒和9.8秒。
从上述实验结果可知,生成式对抗网络不仅能识别语音中的关键词,还可以定位出关键词在语音中的具体位置。
与模板匹配算法的对比见表2。
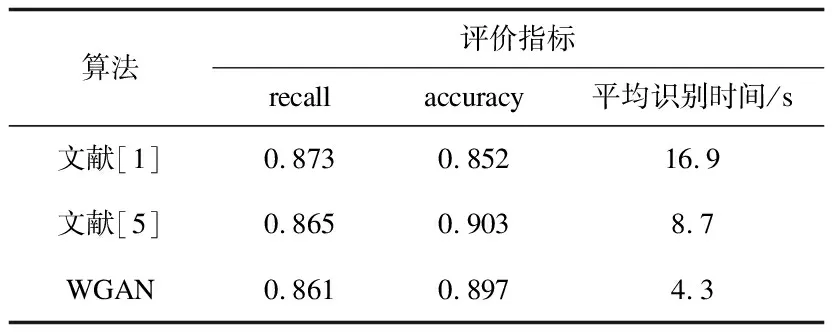
表2 与模板匹配算法对比结果
据表2的结果分析,文献[1]中的快速模板匹配的准确率略低于WGAN模型,WGAN识别关键词的速度比它快了将近4倍。虽然文献[5]中的模板匹配方法准确率是三个方法中最好的,但是其花费的时间却是文中所提方法的2倍。这就表明,基于WGAN的音频关键词识别方法识别速度比模板匹配快。
接下来,与文献[14]中的基于DNN-HMM的识别方法进行比较,其实验结果如表3所示。
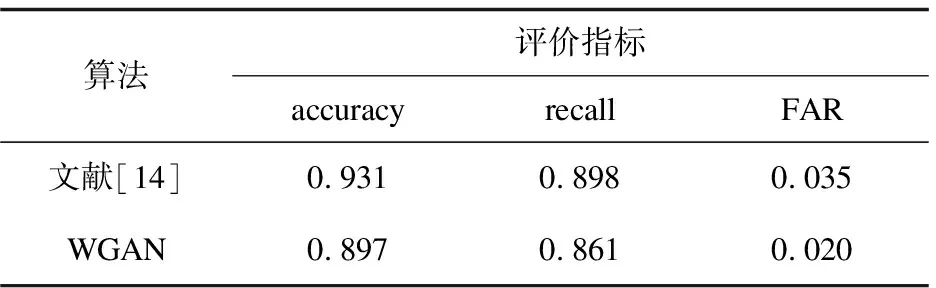
表3 与语音识别算法对比结果
通过实验对比可以看到,基于语音识别的关键词识别方法的准确率可高达0.931,但仅仅比所研究的方法高了0.034,而WGAN识别关键词的错误接受率FAR却比语音识别低了0.015,因此可得出这样的结论:WGAN识别关键词的性能与基于DNN-HMM的语音识别的性能相差无几。
此外,本小节还做了一组鲁棒性实验,以验证所提方法的抗噪能力。对普通话这个数据集的测试集加入信噪比(signal-to-noise ratio,SNR)分别为20 dB、15 dB、10 dB和5 dB的高斯白噪声,查看模型在不同强度的噪声情形下识别关键词的能力,实验结果如图5所示。
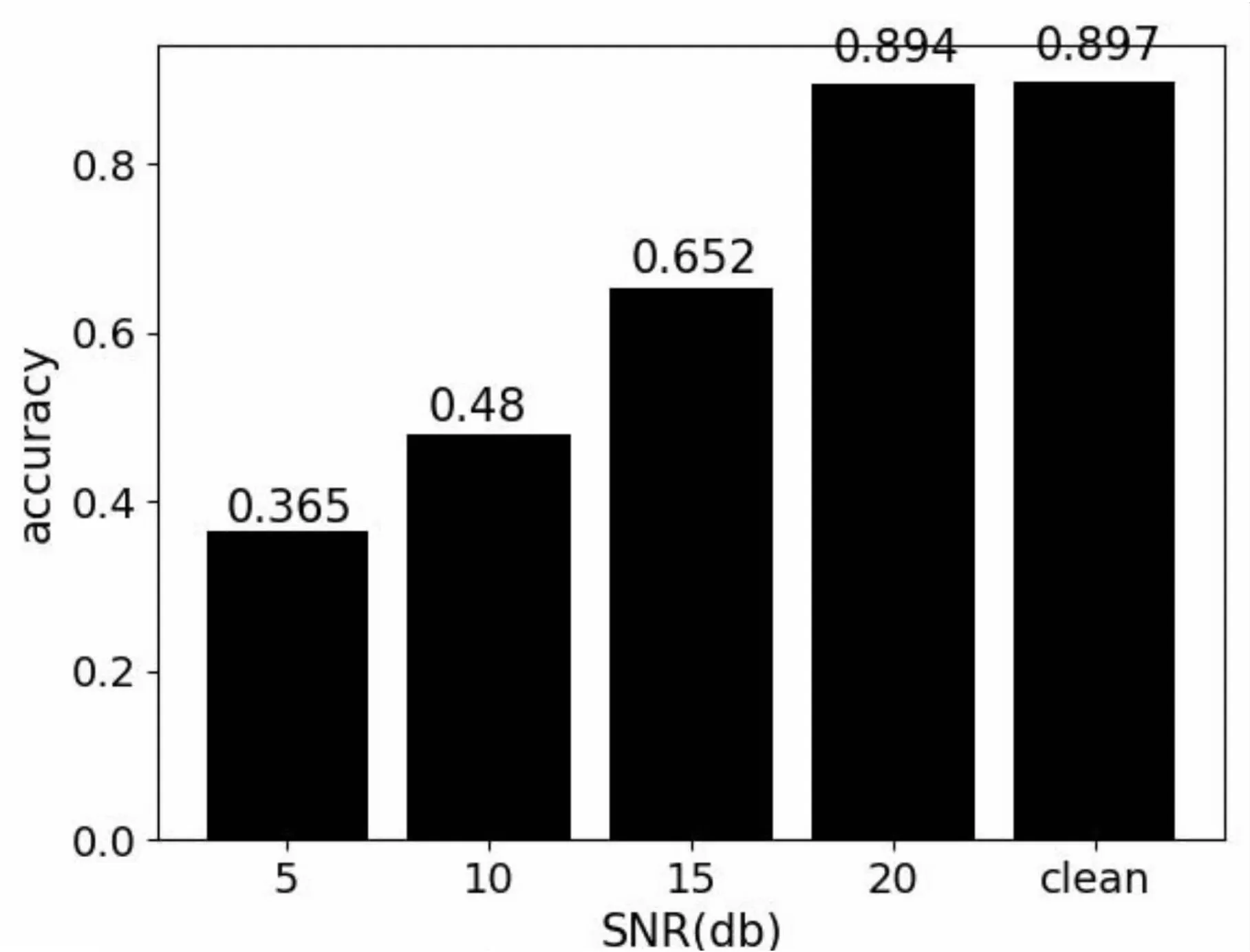
图5 模型准确率与噪声之间的关系
可以看到,在噪声不大的情况下,WGAN识别关键词的准确率基本上与安静环境下相差不大,但当噪声的信噪比变为15 dB时,准确率严重下降,当SNR为5 dB时,准确率低至0.365。这个表明,基于WGAN的音频关键词识别方法具有微弱的鲁棒性。
5 结束语
通过分析基于语音识别的关键词识别技术,发现该方法的工作量大,对无文字语言的关键词识别不适用,并且无法获得关键词的具体位置。针对这些问题,提出了一种基于WGAN的音频关键词检测方法,利用WGAN的生成器生成定位关键词的掩码序列,用于分析音频中有无关键词以及关键词的位置信息。在包含普通话、四川话和粤语的混合数据集上训练了WGAN模型,从准确率、召回率、错误接受率和错误拒绝率分析了所提方法的性能。虽然模板匹配算法也能识别出无文字语言的关键词,但是其识别速度低于文中所提方法。另外,WGAN识别关键词的性能与基于DNN-HMM的语音关键词识别方法相差不大。这就说明基于WGAN的音频关键词识别方法可作为无文字语言关键词识别方法的一种替代方法。由于所研究的方法可以获得关键词的位置信息,因此,文中所提方法在隐私保护等领域具有应用前景。由于基于WGAN的音频关键词识别方法抗噪能力低,下一步的工作将研究如何提升模型的鲁棒性。
猜你喜欢
英语学习(2022年9期)2022-10-25
英语学习(2022年8期)2022-08-26
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
家庭影院技术(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
环球人文地理(2021年11期)2021-01-02
故事会(2009年12期)2018-09-03
中文信息(2016年8期)2016-11-22
