
基于相似度的铁路沿线测风站布局优化策略
2021-10-19 03:19袁诗云叶小岭叶星瑜
重庆理工大学学报(自然科学) 2021年9期
袁诗云,叶小岭,b,熊 雄,陈 昕,叶星瑜,李 伟
(南京信息工程大学 a.自动化学院;b.气象灾害预报预警与评估协同创新中心,南京 210044)
近年来,随着国家经济的飞速提升和铁路运输等交通网络的迅速发展,我国已成为世界高速铁路第一大国[1]。高速列车车速快,发生事故时人员伤亡惨重,为了最大限度地保障列车运行安全[2],铁路部门在铁路沿线设置了气象观测站点。当前铁路沿线气象观测站点的布局规划单一,缺乏对地形及相关气象要素的思考。各气象要素中,大风是影响铁路安全运行的主要气象灾害之一[3]。目前,铁路沿线风速观测点均为等间距布站,布站方式既造成大风速段风况的监测不够全面,又造成小风速段监测数据过于冗余,缺乏针对性。最合适且经济实用的测风站点布局应能通过最少的站点数目来准确监测该段区域的风速特征[4]。因此,需要设计铁路沿线测风站点布局以达成合理的站点布置,使大风段和小风段区域各自有合适的站点数目来监测气象信息。
Drozdov[5]于1946年提出气象要素的线性内插标准误差只与该要素的结构函数有关,使结构函数被广泛地应用于气象站点布局中。1986—2000年,国内诸多学者釆用相关函数法、结构函数法、最优插值法分别对我国江淮平原、四川盆地等地区进行合理气象站网的布局[6]。2012年,胡婷等[7]基于美国的USCRN布局理论针对我国气候站网进行分析,推算出能反映我国整体气候站网所需的最少站点数目,为我国气象站网的布局提供了重要参考。然而,现有的站点布局方法都是均匀布站且只适用于整片区域的气象站网布局,无法应用于沿线的布站。本文中针对沿线的非均匀布站情况提出了一种新的方案。
相似离度由值相似与形相似两部分构成,它既可以表征风速数值变化之间的相似程度,又可以反映风速变化趋势的相似性[8]。相似离度现多应用于气象要素的预报[9-10]。杰卡德相似系数在1912年被首次提出,用于分析高山区的区系分布[11],现多用于度量有限样本间的相似性与差异性。当前,尚未有学者将相似性度量方法用于铁路沿线站点布局优化的研究。
为此,针对铁路沿线站点布局的不足,提出了一种基于相似性度量的相似度布站函数。首先,依据铁路沿线等间距布站的模拟站点数据,筛选出对铁路运行存在影响的风速数据,对各站点之间分别进行相似性度量。之后,根据站点地形将铁路沿线划分为多块区域,在仅保留风险测风点的情况下,对各区域选定合适的相似度阈值,采用提出的相似度布站函数进行站点的增减。使测风站点的位置更能代表高铁沿线风分布的特性,将存在缺陷的等间距布站改良为非均匀布站,从而更加准确地监测高铁沿线的风况。
1 数据选取
江苏省地处长江三角洲,东南地区濒临海洋,夏季常有台风过境,风速较大;西北部地区冬季常受北方冷空气影响,风速较大[12-13]。原始数据来源于国家气象局地面气象站数据集,包括气温、气压、降水、风速、风向等7个气象要素,数据的完整率在 98%以上,经过基本的质量控制,去除了粗大误差。本文中提取2018年京沪高铁江苏段铁路沿线附近90 km半径范围内43个气象站点的 5 min瞬时风速数据。
2 方法分析
2.1 克里金插值
克里金插值法被称为空间自协方差的最佳插值法,是地统计学的主要内容之一[14-15],建立在空间结构分析和变异函数的基础上进行估值[16]。
在众多克里金插值法中,普通克里金法的应用最为广泛,其公式定义为:
(1)
其中:z(x0)为未知站点的插值估计值;xi为区域上的一系列观测站点;z(xi)为相应站点的测量值;λi为已知站点的权重值。λi需满足以下条件来达到线性无偏差估计条件:
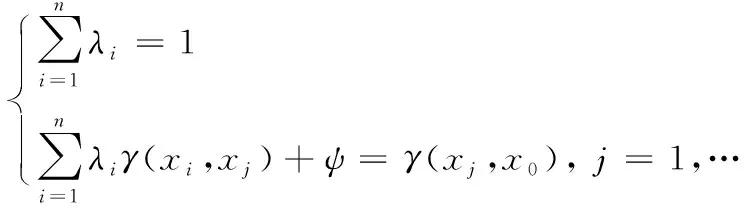
(2)
式中:γ(xi,xj)表示Z在采样点xi和xj之间的半方差;γ(xj,x0)表示Z在采样点xj和x0之间的半方差;ψ表示极小化处理时的拉格朗日乘数。
权重系数为一组最佳系数,通过变异函数求取,变异函数表示的是半方差γ(h)和点对应空间距离的关系,分别表示为:
E[Z(x)-Z(x+h)]=0
(3)
E{[ε′(x)-ε′(x+h)]2}=2γ(h)=min
(4)
式(3)表示任意距离为h的两点之间差值的数学期望为0。式(4)表示任意距离为h的两点之间差值的方差最小。
半方差γ(h)表示为:
(5)
式中:h为步长;γ(h)为变量Z以h的半方差;n为被h分割实验数据的数目。
2.2 相似离度
相似离度既能够衡量值相似又能表征形相似,是一种较为全面的相似性判据,以此度量风速序列之间的相似性,用符号C(X,Y)表示。相似离度定义为:
(6)
其中:
(7)
(8)
Hxy(k)=Hx(k)-Hy(k)
(9)
(10)
式中:x、y分别代表选取的2个样本序号;C(X,Y)表示这2个样本之间的相似离度,其值越小则这2个样本相似度越高;Rxy表示2个样本中各个因子之间的差值Hxy(k)对Exy的离散程度,称之为形系数,它准确地反映了2个样本之间的形相似程度。当Hxy(k)与Exy的差值越大,离散程度越大,2个样本的曲线形状越不相似。Dxy为海明距离对样本容量n求平均值,反映了2个样本之间数值本身的差异程度,称为值系数;α与β分别是对形系数Rxy和值系数Dxy的相似加权系数,α与β相加需为1。本文中其值均取0.5[17-18]。
2.3 杰卡德相似系数
杰卡德相似系数是衡量2个集合相似度的一种指标。集合A与B交集中元素的个数占A与B并集中元素个数的比例称为这2个集合的杰卡德系数,杰卡德值越大说明2个集合相似度越高。杰卡德相似系数用符号J(A,B)表示,其表达式为:
(11)
3 基于相似性度量的沿线相似度优化布站方案
3.1 相似性度量
大风对客运专线高速列车安全运行有影响。《地面气象观测规范》规定,瞬时风速≥17.0 m/s的风记为大风。马淑红等[19]研究瞬时风速对高速列车安全运行的影响时提出高速列车经过特殊的路段,如路堤、特大桥梁、峡谷等特殊路段时,瞬时风速增加1.23~1.70倍,因此当高铁沿线瞬时风速大于10 m/s时,会对高铁运行产生影响。
针对研究区域的站点,分别定义单站点风速数据和多站点风速数据。单站点风速数据定义:筛选出每个站点瞬时风速大于10 m/s的数据;多站点风速数据定义:所有站点中任意选取两站点,筛选同一时刻存在风速大于10 m/s的数据。
将相似离度与杰卡德相似系数相结合,进行布站合理阈值选择。设定x为相似离度,y为杰卡德相似系数,对于任意相比较的2个站点间的相似离度与杰卡德相似系数分别用x1与x2、y1与y2表示。将铁路沿线划分为多块区域,并区分出风速平缓区及大风多发区。对于所有沿线区域,两两相邻站点间相似度高且总是x
(x1-x2)2+(y1-y2)2代表2个站点相似离度与杰卡德相似系数差值的平方和,差值越大则2个站点的相似性差异越大。对于风速平缓区,在满足相似度站点添加条件后,由于小风区域段对铁路安全运行影响较小,因此应在站点相似性差异最大处新增站点。此时在合理阈值范围内,相似离度最大且杰卡德相似系数最小,则(x1-x2)2+(y1-y2)2最大。对于大风多发区,大风区域段对铁路安全运行影响严重,在满足相似度站点添加条件后,应在站点相似性差异最小处新增站点。此时在合理阈值范围内,相似离度最小且杰卡德相似系数最大,则(x1-x2)2+(y1-y2)2最小。
针对风速平缓区域提出小风段站点相似度布站函数公式f(x)添加站点,其公式如下:
(12)
f(x)求出的相似性差异最大值所处的区间,即为此段区域所需新增站点的具体位置。
针对大风多发区域添加站点提出大风段站点相似度布站函数公式g(x),其公式如下:
(13)
新增站点的具体区域位置为g(x)求出的相似性差异最小值所处的区间。
3.2 沿线优化布站方案
基于相似离度与杰卡德相似系数提出布站相似度函数来优化铁路沿线站点布局,布站设计流程见图1。
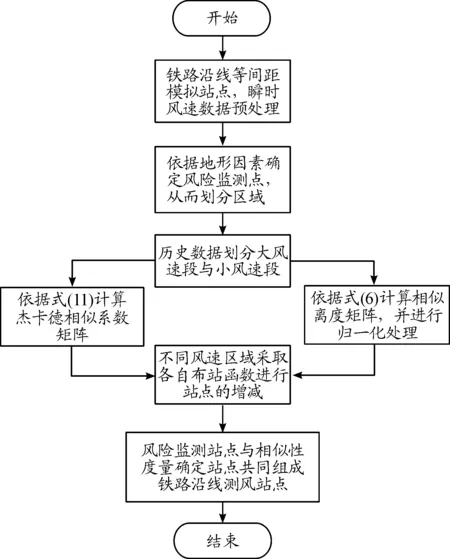
图1 布站设计流程框图
其步骤如下:
步骤1铁路沿线等间距模拟站点,通过克里金插值得到沿线模拟站点的瞬时风速数据,筛选出单站点风速数据与多站点风速数据;
步骤2依据地形因素确定风险监测点位置,以此为基础,通过历史风速数据划分出大风区域段与小风区域段;

步骤4利用杰卡德相似系数矩阵与相似离度矩阵,针对不同风速区域段采取相对应的相似度布站函数(12)或(13),确定各区域站点的增减;
步骤5风险监测点与依据相似度函数确立的站点共同组成铁路沿线测风站,实现布局的优化。
4 结果分析
4.1 模拟站点
以京沪高铁江苏省铁路沿线作为研究区域,在铁路沿线两边界点之间,按照每10 km一个站点共划分出31个等间距模拟站点。依据沿线附近半径90 km范围内43个站点的风速数据,通过克里金插值得出31个模拟站点的5min瞬时风速数据。站点分布如图2所示。
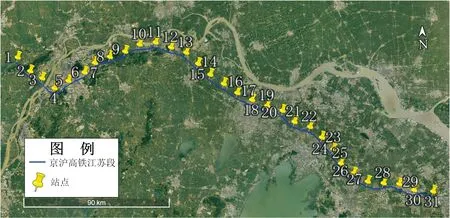
图2 站点分布图
设定31个模拟站点为江苏省铁路沿线的原始站点。在此基础上,根据站点间的相似度关系进行站点的增减来实现布局优化。
4.2 布站区域划分
铁路沿线在桥梁、湖泊、隧道、峡谷、高山等路段存在特殊的风环境,这些路段大风与强风日数最多,列车发生事故的可能性远高于其余地区[20]。观察江苏省铁路沿线31个站点地形,其中站点3靠近大胜关大桥,站点4毗邻大胜关大桥与长江,站点7位于湖泊与隧道口之间,站点9设立在海拔高87 m的高山上,站点25濒临湖泊,站点27与28紧靠阳澄湖边。因此,上述站点为地理风险点,即必布站点。铁路沿线依据站点地形因素可划分为5部分:①站点4~7;②站点7~9;③站点9~25;④站点25~27;⑤站点28~31。
利用京沪高铁沿线江苏段1980—2017年的风速数据,针对大于10 m/s的日数进行空间插值分析,结果如图3所示。通过图3可以看出,划分得出的5块区域中第3段区域为小风速段区域,其余皆为大风速段区域。

图3 风速区域分布图
4.3 各区域站点布局
由风险监测点可知第1个必设站点为站点3,接下来分区域优化布站。
区域1:此区域相似度矩阵不满足相似度站点添加条件,因此无需新增站点,仅保留风险站点4与7。
区域2:同理于区域1,保留风险站点7与9。
区域3:此区域满足相似度站点添加条件,需要新增站点。区域3为小风段区域,采用布站式(12)。基于相似离度与杰卡德系数的区域3相似度函数数据见表1、2。首先,以站点9为起始站点,剩余站点作为比较站点,采用相似度函数确定新增站点位置。由表1看出最大值出现在站点11-12,因此在站点11与12间需新增站点11-12。站点9作为起始站点求相似度已出现下一必设站点11-12。接下来,则以站点12为起始站点求取下一部分的站点位置,且此时满足相似度站点添加条件。由表2可看出,最大值出现在站点13与14之间,因此新增站点13-14。依次类推,接下来分别以站点14与站点20为起始站点,新增站点分别是站点19-20与站点22-23。站点23作为起始站点时不满足相似度站点添加条件,则区域3优化布站完成。综上,区域3依据布站相似度函数确立的站点为:站点9,站点11-12,站点13-14,站点19-20,站点22-23,站点25。
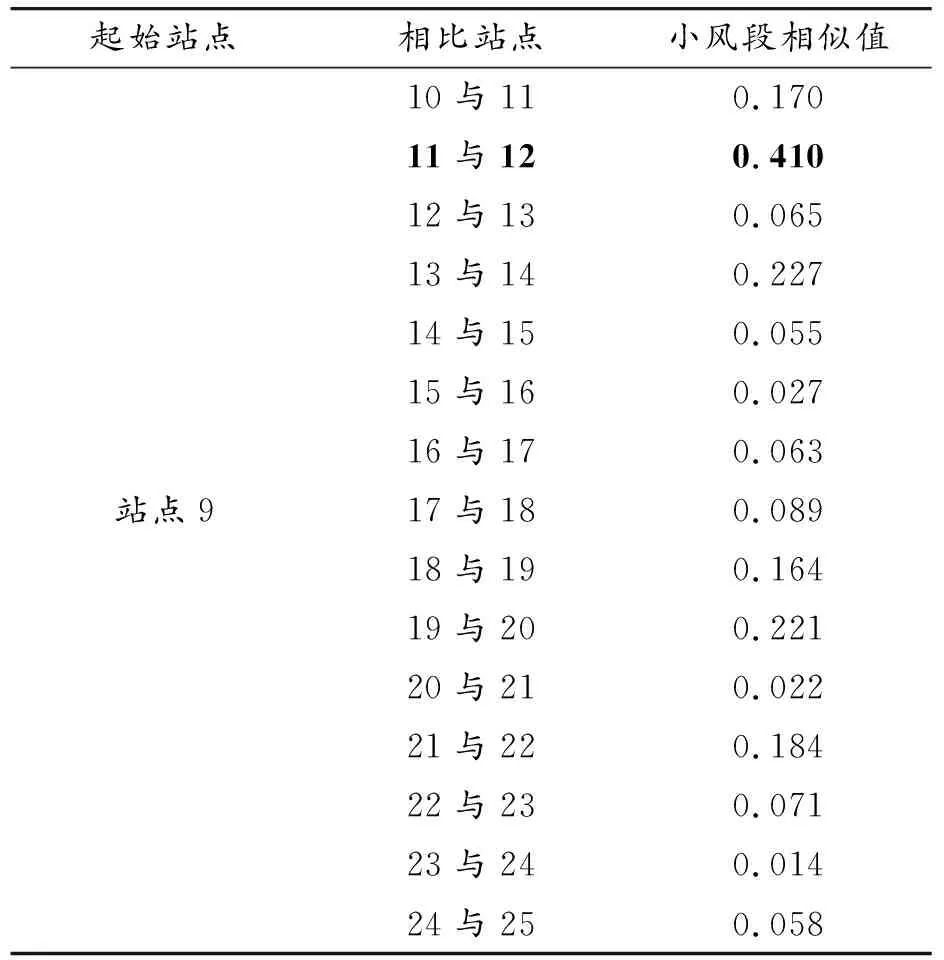
表1 站点9相似度函数数据

表2 站点12、14与20相似度函数数据
区域4:同理于区域1,只保留风险站点25与27。
区域5:此区域满足相似度站点添加条件,区域5为大风段区域,采取布站式(13)。由表3看出最小值出现在站点30~31,从而在站点30与31间新增站点30-31。区域5根据相似度函数确立的站点为:站点28、站点30~31。
站点28作为起始站点与其余站点的相似度函数数据如表3所示。

表3 区域5相似度函数数据
综上所述,依据相似性度量确立的京沪高铁江苏段铁路沿线的站点为:站点3、站点4、站点7、站点9、站点11-12、站点13-14、站点19-20、站点22-23、站点25、站点27、站点28与站点30-31。优化后的沿线布站图如图4所示。由图4可见,整条铁路沿线站点呈现出大风段站点相对密集、小风段站点相对稀疏的布局特点。
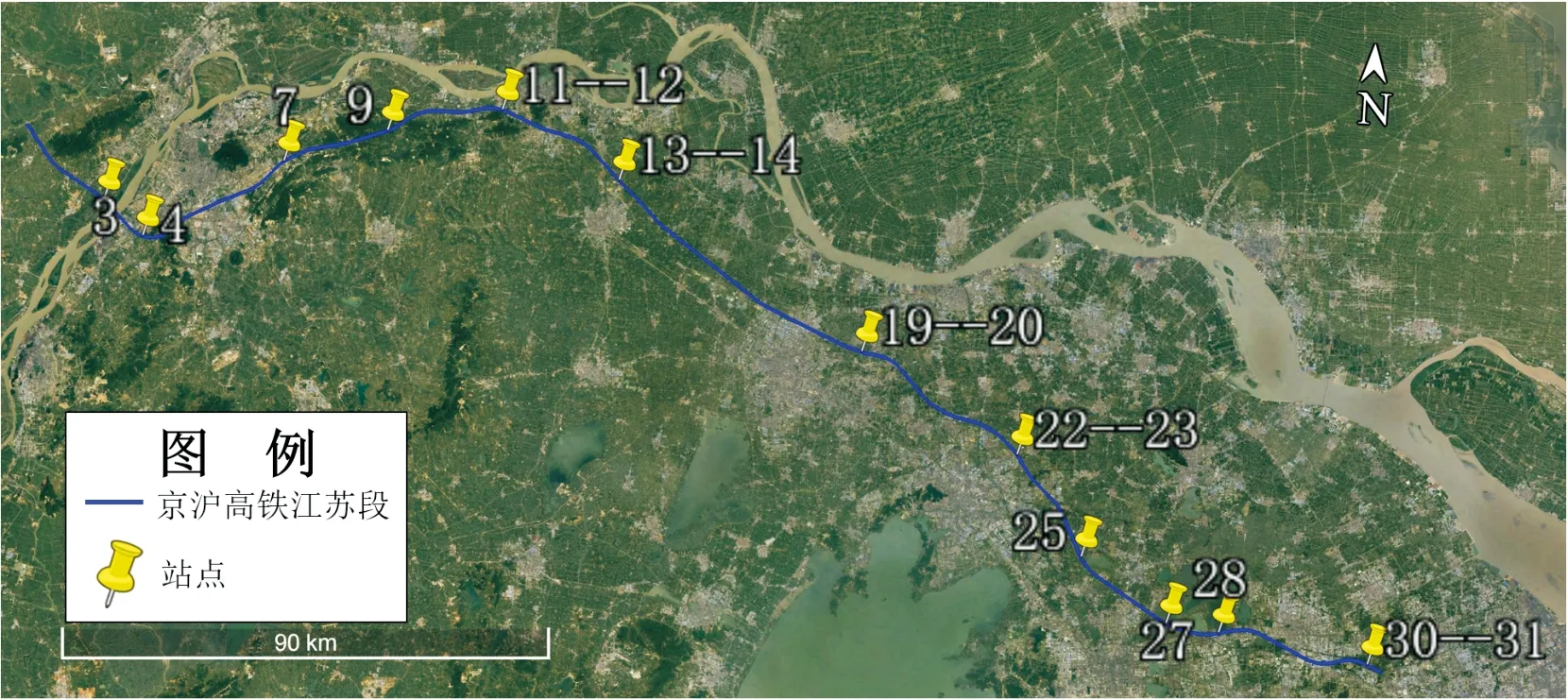
图4 优化站点分布图
4.4 站点布局合理性检验
4.4.1风速特征检验
对于依据相似性度量优化后的京沪高铁江苏段铁路沿线的站点布局,优化后站点需替代原始站点监测出各区域风速特征。
表4为计算出的区域风速平均误差。由表4数据可见,各区域平均误差极小,即优化后站点测量的风速能代表各区域特征,依据相似性度量设定的站点布局是合理的。

表4 风速平均误差
4.4.2合理阈值检验
依据铁路沿线43个站点的数据,利用克里金插值计算布站后新增站点的风速数据,而后将新增站点数据代入31个模拟站点区域中,计算此时的相似度矩阵。依据上述区域划分,绘制包含新增站点的相似度曲线。
由图5可知,加入新站点后,各段区域相似离度曲线与杰卡德相似系数曲线交点皆是相似度新增站点,可见相似度布站函数是在合适的相似度阈值处增设站点,新增站点位置合理。
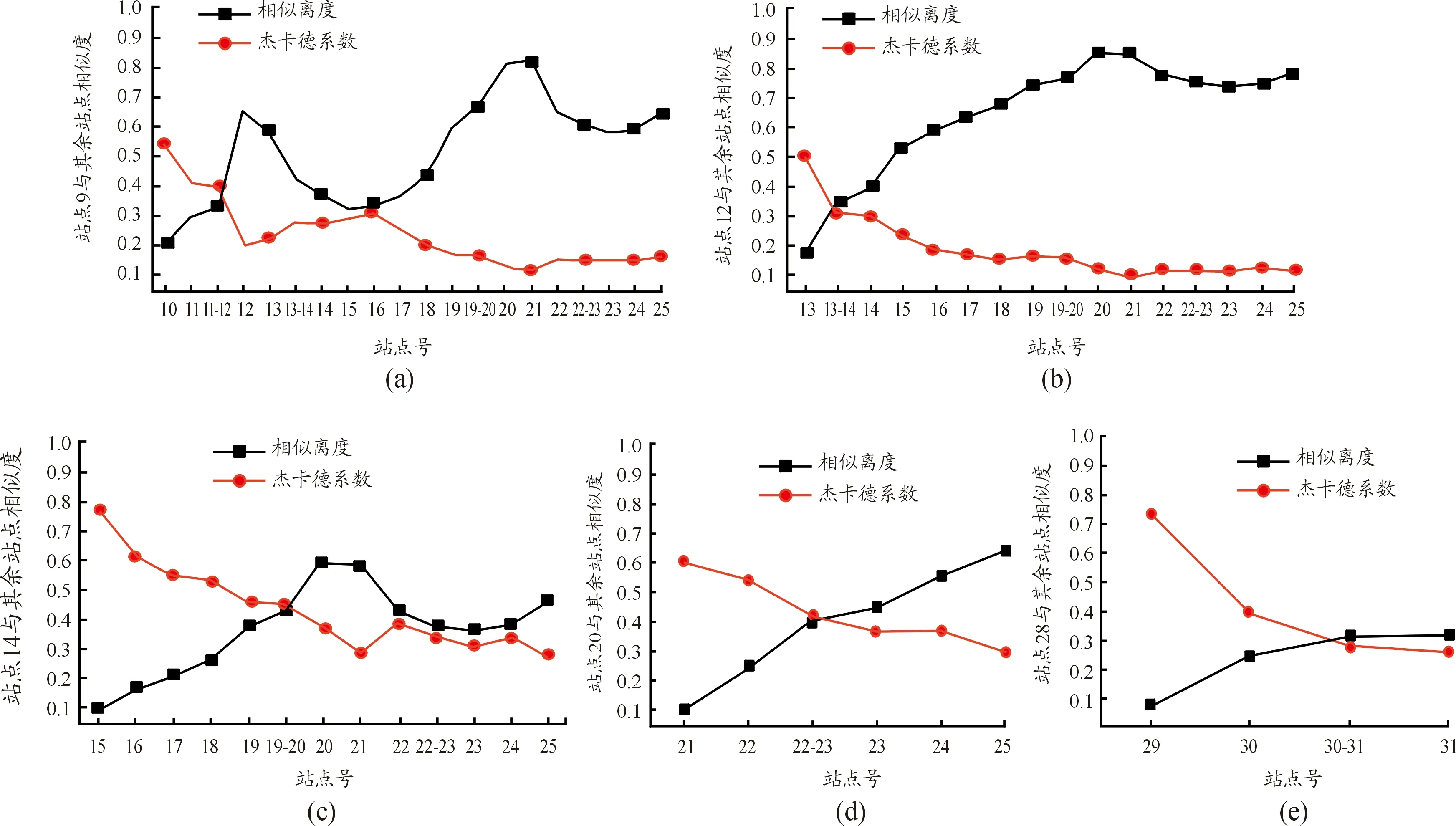
(a)~(d)区域3;(e)区域5
5 结论
1) 对于铁路沿线的风险监测点,主要考虑该点的地形因素,对该风险点的瞬时风速,均应确保存在测风站点;
2) 对于铁路沿线布站,依据地形因素划分区域,采取分段的形式,有针对性地一一分析处理,使站点布局更加合理;
3) 采取站点间相似度关系解决等间距布站存在的问题,能在保证监测到完善风速数据的前提下节约布站和监测成本。针对江苏省铁路沿线的实例研究表明,此方法效果较好,布设的12个站点代表了原31个模拟站点的监测风况,能为未来沿线站点布局提供借鉴。
猜你喜欢
农业灾害研究(2022年9期)2022-11-19
农业技术与装备(2022年5期)2022-07-25
现代英语(2021年18期)2021-11-22
现代农业科技(2018年11期)2018-08-14
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
椰城(2016年2期)2016-09-21
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
故事会(2016年6期)2016-03-23
中外文摘(2015年3期)2015-11-22
