
网站内容自动摘要方法及其在高校年鉴编制中的应用
2021-11-01 06:29马玉庆刘一翔张根熹万宇明
微型电脑应用 2021年10期
马玉庆, 刘一翔, 张根熹, 万宇明
(上海交通大学 电子信息与电气工程学院, 上海 200240)
0 引言
年鉴是特定年份特定区域或领域所发生的重要事件的记录。年鉴的编制既是对事件的记录与整理,也是对特定范围内工作的汇总总结。对管理者进一步决策,起到辅助支持作用。高校年鉴编制对各院系围绕教学、科研所开展活动及所取得的成果进行分类汇总,一般有院系行政管理人员完成。由于高校教学与科研工作具备专业化、创新性强的特点,办公室行政人员在进行年鉴编制时存在如下挑战。
(1) 教学科研与行政管理人员由于专业隔阂原因,造成年鉴编制人员进行年鉴材料内容筛选、分类困难。高校教学科研活动一般与所在院系专业相关程度高,年鉴材料中涉及到大量专业相关学术内容,年鉴编写行政人员在进行内容筛选时,较难对其成果的专业水平进行准确评价,教学与科研交叉融合进一步造成年鉴编制内容分类甄别困难。
(2) 实验室与行政管理分离造成年鉴编制内容收集困难。高校年鉴编写主要是对教学、科研基层组织,例如实验室或授课教师重要活动或成果的记录。由于实验室科研以及教学管理活动与行政管理常常是部门分离的,并且,教师和实验室科研人员在年鉴材料收集方面积极性偏低,因此通过人工方式进行年鉴材料收集是一个耗费人力时间的过程。
针对不同类型年鉴编写,相关学者分别围绕方法创新、制度建设等方面展开研究。罗洁琼等[1]认为年鉴条目是年鉴编写的关键部分,提出可以从年鉴条目材料收集的覆盖性、年鉴条目标题的准确性,以及年鉴条目内容的质量3个方面,提高年鉴编写水平。孙永华等[2]从年鉴框架结构设计出发,结合区域发展中高新区现代工业与科技领域、外向型经济、旅游经济等特色,认为突出区域特色,推动创新编写,是提高区域年鉴编写水平的关键。针对高校年鉴编写,罗应梅等[3]认为完善年鉴编写制度与流程、加强年鉴编写人员培训是持续推进年鉴编写工作健康发展的基础,同时认为互联网和数字化技术会成为年鉴传播的趋势之一。
自动摘要技术是基于计算机的自然语言理解的重要内容,在行政档案、企业知识管理等领域有较多应用。姜志祥等[4]生成式摘要方法中存在的问题,提出并设计了基于自注意力与指针网络的自动摘要模型,通过基于深度学习的语义处理技术,提升自动摘要算法的准确度。从年鉴词条生成角度,由于深度学习对于训练数据有一定的数量要求,因此存在工程应用的难度。章成志等[5]对书评内容进行摘要,利用词向量以及近邻传播聚类等方法构建图书属性词集,在此基础上利用TextRank算法生成图书内容摘要[6]。该研究表明自动摘要技术可以对文本内容进行分析,并区分文本内容的类别,例如属于书评内容还是属于书籍内容,从而对文本内容进行分别处理。在年鉴生成过程中,对于年鉴资料的分类是抽取年鉴词条的依据,本文在年鉴自动生成研究中借鉴了相关聚类方法的应用。同时,由于信息化的普及,年鉴资料的来源主要来自于企业网站等平台,网页内容自动抽取有较多研究与应用,例如王雪梅等[7]利用标签和分块特征进行新闻网页内容抽取,以进行新闻网页内容分析。在年鉴生成方法中,利用企业网站内容分析可以提高年鉴资料的收集效率。
基于以上分析,本文利用网页内容管理、图像分类标注与文本自动摘要方法对互联网内容进行自动分析,研究行政档案自动摘要与应用系统设计。课题利用网络爬虫技术进行网站数据抓取,利用专家经验构建领域词库与概念关系,形成内容评价指标体系,在此基础上进行分词以及权重计算,根据权重结果判定事件的重要程度。通过原型系统的设计实现以及学院网站分析结果,验证了本项目所设计方法的可用性。
1 年鉴条目及自动抽取方法设计
高校行政年鉴条目内容主要涵盖年度科研、教学活动等活动中重要事件。一般地,高校年鉴由学校和院系不同级别行政管理人员协同完成。年鉴整体架构和类目等,由学校统一制定,各院系在统一年鉴架构的指导下,进行年度重要事件材料收集,以形成条目和大事记内容[8]。
条目和大事记内容的编写是一个繁琐的过程,需要对年度发生的各类事件进行整体梳理、归类和重要性评估。为了提升年鉴条目信息收集的效率,本文以条目生成为例,研究提出基于网络爬虫的网站新闻内容自动抽取与分析方法,以生成年鉴条目推荐列表,其抽取分析过程如图1所示。
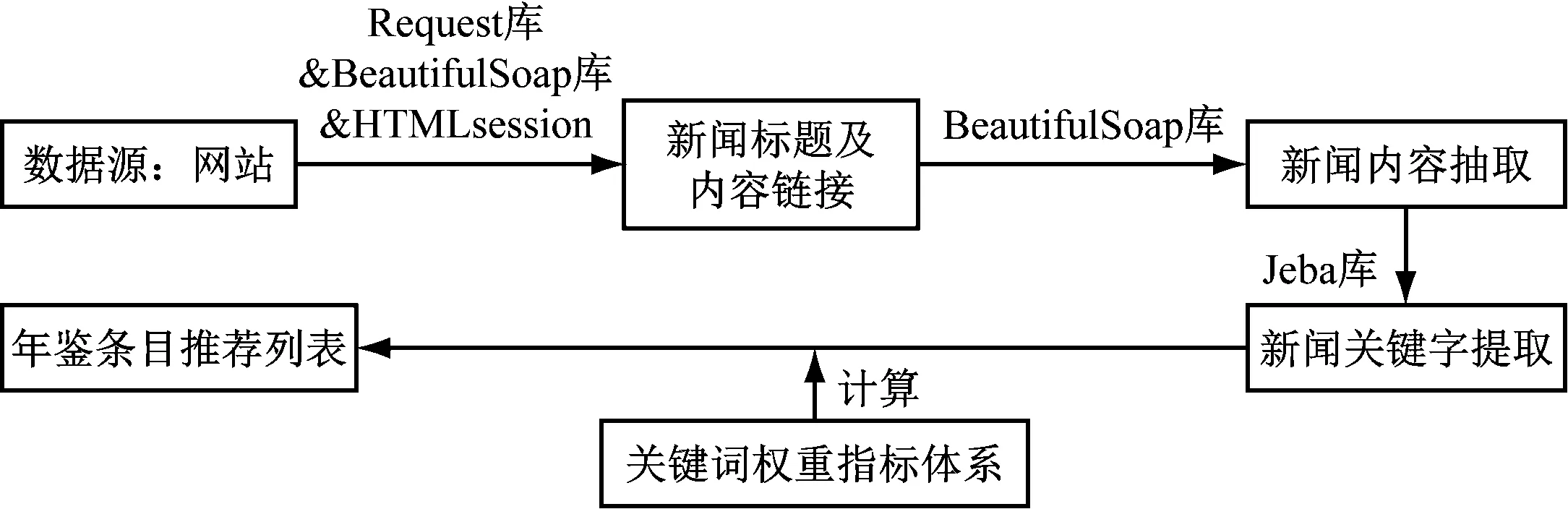
图1 面向网站新闻的年鉴条目自动抽取方法
由图1可知,年鉴条目自动抽取方法主要包括3个部分,即网站结构抽取、新闻内容抽取以及条目推荐。
网站结构抽取部分,由于年鉴条目和大事记主要收集本行政单位年度发生的重要活动,因此网站分析目标主要是本部门的官网或公众号,网站结构相对固定、可根据网站开发文档获知。
新闻内容抽取部分,则需较大的灵活性,本文主要借助自动摘要研究中较成熟的分词工具,进行新闻内容关键字的抽取。虽然从生成条目的角度,单纯的关键字并不能完全反映条目或大事记的全部内容,但是从新闻所反映的活动事件重要性评价角度,关键字是较重要的评价依据。
条目推荐部分的主要目的是通过对新闻内容的评估,挑选出可能列为年鉴条目的新闻材料。如何进行新闻内容重要程度评价是关键。本文借助领域知识图谱思想,设计了关键词关联与权重指标体系,构建结合领域关键词层次及权重分配的内容评价方法。
2 关键词权重指标体系构建
在年鉴条目的自动生成过程中,除了内容自动摘要外,从年鉴角度对新闻内容进行重要性评估是条目自动生成的关键。在新闻内容重要性评估方面,领域专业人员一般需要将先验知识与后验统计结果两方面相融合。因此,本文借鉴知识图谱概念,设计了领域关键词权重指标体系,将领域专业知识与关键词统计结果相结合,计算所分析新闻的活动重要程度,以判断是否列入条目推荐列表。
关键词权重指标体系元模型及指标体系示例如图2所示。
图2中,左侧虚线框内为指标体系的元模型。指标体系中包含3类元素:指标项、属性项和关键词。

图2 关键词权重指标体系元模型及指标体系示例
条目=(指标项1,指标项2,……,指标项n);
指标项={指标项|<属性项,权重>};
属性项={<属性项,权重>|<关键词,权重>}
其中,年鉴条目是由若干并列的指标项组成,它们彼此独立,按时间构成大事记的基础。指标项间由于是各自独立的,因此不区分权重。
3 年鉴条目自动抽取原型系统设计
首先,首先使用Request库,通过网站URL地址、page=
urllib.request.urlopen(url)、contents = page.read()和soup = BeautifulSoup(contents,"html.parser")建立soup对象。
然后,在Web中找到新闻内容的存放位置(p),使用Soup对象的find_all功能,提取内容并写入分析文件txt中。其代码片段如图3所示。

图3 获取新闻内容代码片段
图3所示的伪代码以utf-8的编码格式打开txt文档,遍历HTML页面中p标签内的文字,并将其写入1.txt。
对于存储在文件1.txt中的新闻内容,本文采用Jieba库来获取特定新闻的关键词,伪代码如图4所示。

图4 新闻关键词提取伪代码片段
图4伪代码片段中,首先是读取出目标txt文档中的文本,并用Jieba库中的Lcut函数处理得到处理成关键词的对象文本,并对关键词进行遍历筛选,最后返回出频率最高的前len(cha)个关键词。
5 总结
年鉴编写是行政办公室的重要职能工作之一。但是,也是一项耗费时间人力的任务。对于高校年鉴编写还存在专业壁垒,具有一定的挑战性。本文研究了网页内容抽取方法,设计了年鉴词条评价模型,并进行了关键词体系构建;设计了年鉴词条自动抽取方法,并进行了原型设计验证。该方法对于提升年鉴编写效率有一定借鉴作用。
猜你喜欢
江苏地方志(2021年1期)2021-03-25
史志学刊(2020年3期)2020-11-26
中国交通信息化(2019年10期)2019-11-16
中国交通信息化(2019年12期)2019-08-13
神州·下旬刊(2019年1期)2019-02-11
中国神经再生研究(英文版)(2017年10期)2017-11-08
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
植物营养与肥料学报(2011年4期)2011-10-26
中国土地科学(2011年2期)2011-03-20
